
什麼是網頁抓取以及如何操作?
已發表: 2022-06-04目錄
- 什麼是網頁抓取?
- 為什麼需要網頁抓取?
- 網絡抓取如何工作?
- 有哪些網絡抓取最佳實踐?
- 5個最好的網頁抓取工具
- 享受抓取網頁......小心!
如果您目前沒有將網絡抓取作為武器庫的一部分,那麼您肯定會錯過一個在競爭中獲得優勢的巨大機會。
如果你和大多數銷售人員一樣,你總是在尋找競爭優勢。 您想尋找新的潛在客戶,加強與現有客戶的關係,並更好地了解您的整個行業。
網絡抓取可以幫助您完成所有這些事情,甚至更多。 想一想您希望獲得位於某個城市的行業中所有公司的列表的所有時間。 或者,也許您想獲取某個公司的所有聯繫人的列表。
網絡抓取可以幫助您快速輕鬆地獲取該信息。 但它是什麼,它是如何工作的? 在這篇博文中,我們將回答這些問題以及更多問題。 因此,請繼續閱讀以了解有關此強大工具的所有信息!

什麼是網頁抓取?
想像一下,你必須整天看著這樣的東西。 有趣,對吧……?
現在想像一下,如果有一種方法可以在幾秒鐘內對所有這些數據進行分類,從而得出一個有組織的集合。 這基本上就是抓取數據的內容。
簡而言之,網絡抓取是一種從網站中提取數據的方法。 它通常由計算機自動完成,但也可以手動完成。
有幾種不同的方法可以做到這一點,但基本思想是加載一個網頁,然後解析 HTML 代碼以找到您想要的數據。 找到所需數據後,您可以將其保存到文件或數據庫中以備後用。
網絡抓取可用於多種任務,例如從在線商店獲取所有產品名稱和價格的列表,或從網絡論壇中提取數據以查看人們對某個主題的看法。
網頁抓取是免費的嗎?
儘管有一些付費選項,但大多數網絡抓取工具都是免費使用的。 付費選項通常提供更多功能並且更易於使用,但免費選項通常可以很好地完成工作。
小建議
網絡抓取合法嗎?
這是最常見的問題,答案是……視情況而定。 一般來說,從網站上抓取公共數據是完全可以的。 但是,如果您要抓取隱私數據(例如某人的聯繫信息),那麼您可能會遇到一些法律問題。
這是一個常見的問題,答案是……這取決於。 一般來說,從網站上抓取公共數據是完全可以的。 但是,如果您要抓取隱私數據(例如某人的聯繫信息),那麼您可能會遇到一些法律問題。
檢查您正在抓取的網站的服務條款始終是一個好主意,以確保您沒有違反任何規則。
在 LaGrowthMachine,我們使用多種數據源和不同技術開發了自己的抓取方法,這使我們能夠擁有市場上最好的數據豐富功能之一。
我們在線索上恢復多達 28 個不同的數據項(始終遵循對 RGPD 友好的方法),這將允許您根據非常精確的變量進行自動化,並且在您的方法中非常自然。
雖然這種做法不是最近才出現的,但它往往變得更加普遍和廣泛。
它已成為希望將效率和反應性結合起來的成長型營銷人員和中小企業的重要資產。
好的,這就是大驚小怪的原因,但是網絡抓取實際上如何使您的業務受益?
為什麼需要網頁抓取?
最明顯的網絡抓取優勢是它可以為您節省大量時間。
想像一下,如果您每次想要進行市場調查時都必須從網站手動複製和粘貼數據。 這將需要永遠! 但是通過網絡抓取,您可以在幾分鐘內獲得所需的所有數據。
另一個很大的優勢是它可以幫助您獲得難以或不可能以任何其他方式獲得的數據。 例如,如果您想研究一個新市場,網絡抓取可以幫助您快速輕鬆地獲取該市場中所有公司的列表。
此外,網頁抓取可用於各種任務,一些最常見的用途包括:
- 潛在客戶生成:從網站上抓取數據可能是尋找新潛在客戶的好方法。 例如,您可以從企業目錄中抓取數據,以查找您所在行業中位於某個城市的所有公司。
- 市場研究:網絡抓取可用於收集有關某個行業或市場的數據。 然後可以分析這些數據,以幫助您更好地了解整個市場。
- 競爭對手分析:密切關注您的競爭對手在任何業務中都很重要。 通過從他們的網站上抓取數據,您可以更好地了解他們的產品、定價和營銷策略。
更進一步,利用抓取的數據,您可以在 LaGrowthMachine 中設置多渠道活動。
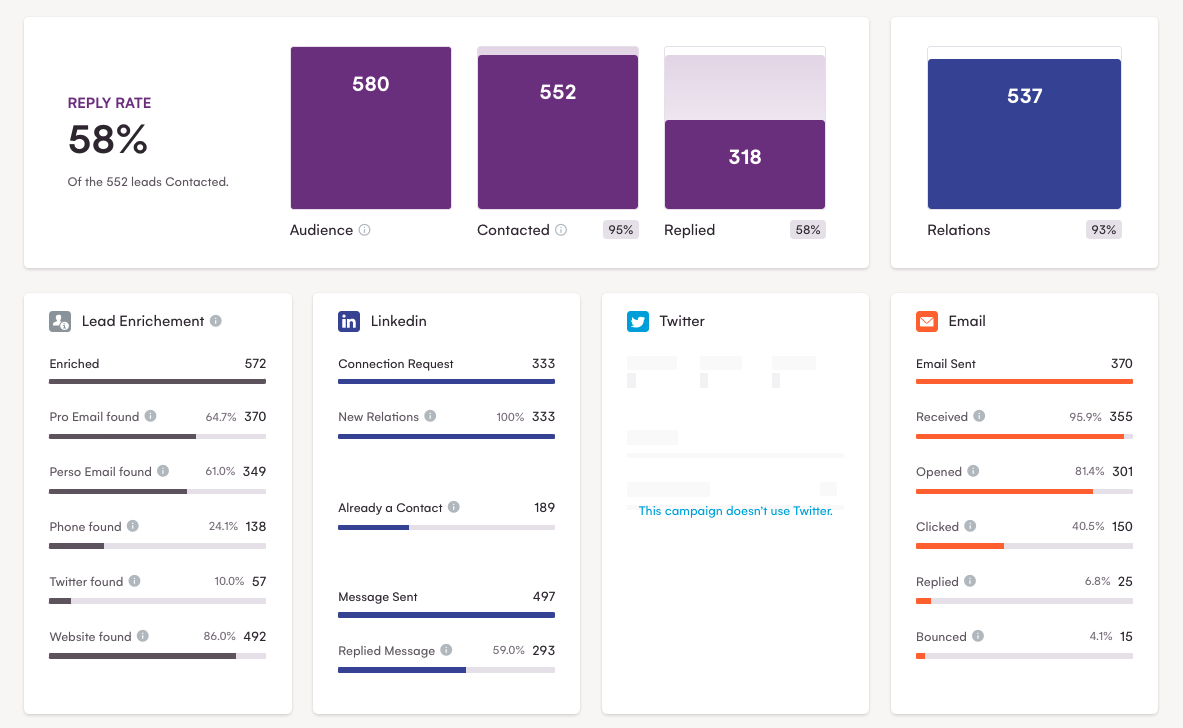
如您所見,這種方法非常成功,回复率幾乎達到了 60%!
現在我們已經向您介紹了網絡抓取並展示了它的一些好處,讓我們來看看它的基本工作原理。
網絡抓取如何工作?
網頁抓取通常由計算機自動完成,但也可以手動完成。
有幾種不同的方法可以做到這一點,但基本思想是加載一個網頁,然後解析 HTML 代碼以找到您想要的數據。 找到所需數據後,您可以將其提取到文件或數據庫中以備後用。
例如,假設您想從在線商店抓取數據以獲取所有產品名稱和價格的列表。
首先,您需要找到並加載要抓取的網頁。
然後,您需要編寫一些代碼來解析網頁的 HTML 代碼並提取您感興趣的數據。
最後,您需要將數據保存到文件或數據庫中。
Web 抓取可以用多種編程語言完成,但最流行的是 Python、Java 和 PHP。
如果您剛剛開始使用網絡抓取,我們建議您使用 ParseHub 或 Scrapy 之類的工具。 這些工具可以輕鬆地從網站上抓取數據,而無需編寫任何代碼。
有哪些網絡抓取最佳實踐?

既然您已經了解了網絡抓取的基礎知識,那麼讓我們來看看一些需要牢記的最佳實踐。
檢查服務條款
正如我們之前提到的,您需要檢查您正在抓取的網站的服務條款。 這將確保您不會違反任何規則,並避免任何潛在的麻煩 - 法律或其他方面 - 在路上。 在抓取他們的網站之前獲得網站所有者的許可也是一個好主意,因為一些網站管理員可能對此不太滿意。
使用正確的工具
有多種不同的網絡抓取工具可供使用,因此選擇適合您需求的工具非常重要。
說到這裡,LaGrowthMachine 就是其中之一!
我們將在本指南的後面部分介紹最佳網絡抓取工具列表,但為了這一點,我們將僅提及一些最受歡迎的工具:
- Scrapy: Scrapy 是一個用 Python 編寫的網頁抓取框架。 它是最流行的工具之一,被谷歌、雅虎和 Facebook 等大牌使用。
- ParseHub: ParseHub 是一個支持多種語言和網絡平台的網絡爬蟲。
- Octoparse: Octoparse 是另一個同時支持靜態和動態網頁的網絡爬蟲。
不要超載服務器
當您從網站上抓取數據時,重要的是不要讓他們的服務器因過多的請求而過載。 這可能會導致您的 IP 地址被網站禁止訪問。 為避免這種情況,請確保將您的請求分開,並且不要一次發出太多請求。

優雅地處理錯誤
您不可避免地會在某些時候遇到錯誤。 無論是關閉的網站還是不符合您預期格式的數據,在處理這些錯誤時保持耐心和溫和的接觸非常重要。 你不想冒險破壞任何東西,因為你太著急了。
定期查看您的數據
定期檢查您的數據很重要。 有時,網頁會發生變化,您提取的數據可能不再準確。 定期查看您的數據將有助於確保您始終獲得準確的信息。
負責任地刮擦
尊重您正在抓取的網站非常重要。 這意味著不要抓取太多數據,不要過於頻繁地抓取,也不要抓取敏感數據。 此外,請確保讓您的抓取工具保持最新狀態,以免無意中破壞您正在抓取的任何網站。
知道何時停止
有時您將無法從網站獲取所需的數據。 發生這種情況時,重要的是要知道何時停止並繼續前進。 不要浪費你的時間來強迫你的網絡爬蟲工作——還有其他網站有你需要的數據。
這些只是執行數據提取時要牢記的一些最佳實踐。 遵循這些準則將有助於確保您獲得積極的體驗並避免任何潛在的問題。
5個最好的網頁抓取工具

正如我們之前提到的,有各種各樣的網絡爬蟲可用,從復雜的框架到簡單的工具。 在本節中,我們將介紹一些最流行的抓取工具。
現在……我們已經提到了 Scrapy 和 ParseHub 等基本工具,所以我們將快速介紹其他一些工具。
Python
Python 是滿足您的網絡抓取需求的最明顯的選擇之一。 它是一種通用的腳本語言,可以很好地用於……數據抓取,以及廣泛的其他任務。
使用 Python 的網頁抓取軟件的主要優點是它相對容易學習和使用。
此外,Python 具有廣泛的庫和模塊,可用於 Web 數據提取,使其成為一個非常強大的工具。
一個缺點是 Python 網絡爬蟲可能會很慢,尤其是當它們試圖爬取大量數據時。
此外,一些網站可能會阻止其訪問,這意味著使用 Python 進行網頁抓取通常比使用其他網頁抓取工具更耗時且困難。
總體而言,使用 Python 進行網絡數據提取既有優點也有缺點,但對於許多希望從網絡上抓取數據的人來說,它仍然是一種流行的選擇。
進口.io

這是一個網絡數據提取工具,可讓您從網站上抓取數據,而無需編寫任何代碼。 它是可用的最用戶友好的網絡抓取工具之一,而且還有一個好處:它非常適合初學者!
它包括很棒的功能,例如:
- 用戶友好的點擊式界面
- 從登錄後抓取數據的能力
- 自動IP輪換以避免被禁止
import.io 之所以如此出色,是因為它可以從網站的多個頁面中抓取數據。 如果您想從具有許多頁面的大型網站中抓取數據,這將非常有用。 但是,這也意味著從包含大量頁面的網站中抓取數據時可能會很慢。
import.io 的另一個優點是它可以從“難以”抓取的網站上抓取數據:這意味著它可以繞過網站用來防止抓取的一些保護機制。 也就是說,當網站更改其保護機制時,您將面臨工具損壞的風險。
總的來說,import.io 是一個從網絡快速收集數據的好工具,但重要的是要意識到它的局限性。
莫曾達

Mozenda 是另一個不需要任何編碼的網絡抓取工具。 它包括網頁渲染、網頁抓取和數據提取等功能。
這是一個很好的解決方案,因為它易於使用並且可以配置為從幾乎任何網站上抓取數據。
使用 Mozenda 的主要優點之一是它非常快速和高效。 它可以非常快速輕鬆地處理大量數據。
此外,它非常人性化。 用戶界面直觀且易於使用。 還有大量在線資源可幫助您開始使用此工具進行網絡抓取。
但是,主要缺點之一是它非常昂貴。 如果您只計劃個人使用網絡抓取,那麼 Mozenda 可能不是您的最佳選擇。
它也不總是完美的。 有時網站可能會更改其結構或設計,這可能會導致您的網頁抓取出現問題。
阿皮菲

作為一個網頁抓取平台,Apify 使您能夠將網站變成結構化數據。 它提供了廣泛的功能,包括抓取動態網頁、創建 API 和抓取整個網站的能力。
雖然 Apify 是一個強大的工具,但它有一些限制:
首先,它不是免費使用的,所以如果你現金短缺,它可能不是你的最佳選擇。 設置和使用也可能具有挑戰性,特別是對於不熟悉網絡抓取的用戶。
儘管如此,這是您可以使用的最具擴展性的網絡爬蟲之一。 該平台可以處理大規模的抓取,非常適合需要大規模收集數據的企業。
儘管如此,這種可擴展性也有一個缺點。 因為 Apify 可以處理如此大規模的抓取,所以它更容易出錯,並且在抓取過程中可能會丟失一些數據。
總而言之,由於其靈活性和功能範圍,Apify 仍然是一個流行的網絡抓取平台。 如果您正在尋找一個易於使用且具有多種功能的網頁抓取平台,Apify 可能是您的不錯選擇。
差異機器人

Diffbot 是一個網頁抓取軟件,它使用人工智能從網頁中提取數據。 它提供了廣泛的功能,包括大規模網絡抓取、抓取網站以及從 JavaScript 網頁中提取數據的能力。
使用 Diffbot 的主要優點是它非常精確。 該工具能夠以高精度提取特定數據,這意味著您在使用該工具時不太可能遇到錯誤。 它還具有從多個頁面抓取數據的能力以及處理 AJAX 請求的能力,這始終是一個優勢。
此外,它非常人性化。 用戶界面直觀且易於使用,並且有大量在線資源可幫助您開始使用 Diffbot 進行網絡抓取。
然而,Diffbot 的最大缺點之一是它非常昂貴,而且它無法從使用 JavaScript 加載內容的站點中抓取數據。
更重要的是,它還需要一個結構良好的網站,才能充分發揮其潛力。 如果沒有,數據抓取過程可能會非常緩慢。
享受抓取網頁......小心!
網絡抓取是從網絡收集數據的好方法。 它快速、高效且相對容易實現。 但是,在開始網絡抓取之前,您需要注意一些事項。
首先,在某些情況下,網絡抓取可能是非法的。 如果您計劃出於商業目的進行網絡抓取,則需要確保您擁有這樣做的合法權利。
其次,網絡抓取可能具有挑戰性。 雖然有許多非常用戶友好且不需要任何編碼的網絡抓取工具可用,但有些網站可能比其他網站更難抓取。
最後,網頁抓取可能很耗時。 如果您計劃對大型網站進行網絡抓取,則可能需要一些時間才能獲取所需的所有數據。
儘管如此,網絡抓取可以成為快速有效地收集數據的好方法。 在開始網絡抓取之前,請確保您了解所涉及的風險。
快樂刮!