
如何將本地 Oracle 數據庫同步到 AWS
已發表: 2023-01-11從第一排觀察企業軟件發展二十年,過去幾年不可否認的趨勢是顯而易見的——將數據庫遷移到雲端。
我已經參與了一些遷移項目,目標是將現有的本地數據庫引入 Amazon Web Services (AWS) 雲數據庫。 雖然從 AWS 文檔材料中,您將了解這有多麼容易,但我在這裡告訴您,執行這樣的計劃並不總是那麼容易,並且在某些情況下可能會失敗。

在這篇文章中,我將介紹以下案例的真實體驗:
- 來源:雖然從理論上講,您的來源是什麼並不重要(您可以對大多數最流行的數據庫使用非常相似的方法),Oracle 多年來一直是大公司的首選數據庫系統,並且這就是我的重點所在。
- 目標:沒有理由在這方面具體。 您可以在 AWS 中選擇任何目標數據庫,該方法仍然適用。
- 模式:您可以進行完全刷新或增量刷新。 批量數據加載(源和目標狀態延遲)或(接近)實時數據加載。 兩者都將在這裡涉及。
- 頻率:您可能需要一次性遷移,然後完全切換到雲,或者需要一些過渡期並讓雙方的數據同時更新,這意味著在內部部署和 AWS 之間建立每日同步。 前者更簡單並且更有意義,但後者更經常被請求並且有更多的斷點。 我將在這裡介紹兩者。
問題描述
要求通常很簡單:
我們想開始在 AWS 內部開發服務,所以請將我們所有的數據複製到“ABC”數據庫中。 快速簡單。 我們現在需要使用 AWS 內部的數據。 稍後,我們將找出要更改數據庫設計的哪些部分以匹配我們的活動。
在繼續之前,有一些事情需要考慮:
- 不要太快陷入“只複製我們擁有的東西,以後再處理”的想法。 我的意思是,是的,這是你能做的最簡單的事情,而且會很快完成,但這有可能造成這樣一個基本的架構問題,如果不對大部分新雲平台進行認真重構,以後將無法修復. 試想一下,雲生態系統與本地生態系統完全不同。 隨著時間的推移,將推出幾項新服務。 自然地,人們將開始以非常不同的方式使用相同的東西。 以 1:1 的方式在雲中復製本地狀態幾乎不是一個好主意。 這可能是您的特定情況,但請務必仔細檢查。
- 用一些有意義的疑問來質疑需求,例如:
- 誰將是使用新平台的典型用戶? 在內部部署時,它可以是交易業務用戶; 在雲中,它可以是數據科學家或數據倉庫分析師,或者數據的主要用戶可能是服務(例如,Databricks、Glue、機器學習模型等)。
- 即使在過渡到雲之後,常規的日常工作是否預計會保留下來? 如果不是,他們將如何改變?
- 您是否計劃隨著時間的推移大幅增長數據? 答案很可能是肯定的,因為這通常是遷移到雲中的最重要的單一原因。 一個新的數據模型應該為此做好準備。
- 期望最終用戶考慮新數據庫將從用戶那裡收到的一些一般的、預期的查詢。 這將定義現有數據模型應更改多少以保持與性能相關。
設置遷移
一旦選擇了目標數據庫並滿意地討論了數據模型,下一步就是熟悉 AWS Schema Conversion Tool。 這個工具可以服務於幾個領域:
- 分析並提取源數據模型。 SCT 將讀取當前本地數據庫中的內容,並將生成一個源數據模型作為開始。
- 根據目標數據庫建議目標數據模型結構。
- 生成目標數據庫部署腳本以安裝目標數據模型(基於工具從源數據庫中發現的內容)。 這將生成部署腳本,執行後,雲中的數據庫將準備好從本地數據庫加載數據。
現在有一些使用模式轉換工具的技巧。
首先,幾乎永遠不會直接使用輸出。 我認為它更像是參考結果,您可以根據您對數據的理解和目的以及數據在雲中的使用方式從中進行調整。
其次,早些時候,這些表可能是由期望快速獲得有關某些具體數據域實體的簡短結果的用戶選擇的。 但是現在,可能會選擇數據用於分析目的。 例如,以前在本地數據庫中運行的數據庫索引現在將毫無用處,並且絕對不會提高與這種新用途相關的數據庫系統的性能。 同樣,您可能希望在目標系統上對數據進行不同的分區,就像之前在源系統上一樣。
此外,最好考慮在遷移過程中進行一些數據轉換,這基本上意味著更改某些表的目標數據模型(以便它們不再是 1:1 副本)。 稍後,需要將轉換規則實施到遷移工具中。
配置遷移工具
如果源數據庫和目標數據庫屬於同一類型(例如,Oracle on-premise vs. AWS 中的 Oracle,PostgreSQL vs. Aurora Postgresql 等),那麼最好使用具體數據庫原生支持的專用遷移工具(例如,數據泵導出和導入、Oracle Goldengate 等)。
然而,在大多數情況下,源數據庫和目標數據庫不兼容,那麼顯而易見的選擇工具將是 AWS Database Migration Service。
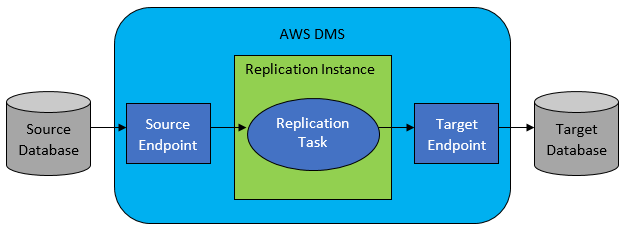
AWS DMS 基本上允許在表級別配置任務列表,這將定義:
- 要連接到的確切源數據庫和表是什麼?
- 將用於獲取目標表數據的語句規範。
- 轉換工具(如果有),定義如何將源數據映射到目標表數據(如果不是 1:1)。
- 將數據加載到的確切目標數據庫和表是什麼?
DMS 任務配置以一些用戶友好的格式(如 JSON)完成。

現在在最簡單的場景中,您需要做的就是在目標數據庫上運行部署腳本並啟動 DMS 任務。 但這遠不止於此。
一次性全量數據遷移

最容易執行的情況是請求將整個數據庫一次移動到目標雲數據庫中。 然後基本上,所有需要做的將如下所示:
- 為每個源表定義 DMS 任務。
- 確保正確指定 DMS 作業的配置。 這意味著設置合理的並行性、緩存變量、DMS 服務器配置、DMS 集群大小等。這通常是最耗時的階段,因為它需要對最佳配置狀態進行大量測試和微調。
- 確保在目標數據庫中以預期的表結構創建(空)每個目標表。
- 安排執行數據遷移的時間窗口。 顯然,在此之前,請確保(通過性能測試)時間窗口足以讓遷移完成。 在遷移過程中,從性能的角度來看,源數據庫可能會受到限制。 此外,預計在遷移運行期間源數據庫不會更改。 否則,一旦遷移完成,遷移的數據可能與存儲在源數據庫中的數據不同。
如果 DMS 的配置做得好,在這種情況下不會發生任何壞事。 每個源表都將被拾取並複製到 AWS 目標數據庫中。 唯一需要關注的是活動的性能,並確保每一步的大小調整都正確,以免由於存儲空間不足而失敗。
增量每日同步

這是事情開始變得複雜的地方。 我的意思是,如果世界是理想的,那麼它可能一直都運轉良好。 但世界從來都不是理想的。
DMS 可以配置為以兩種模式運行:
- 滿載——上面描述和使用的默認模式。 DMS 任務在您啟動它們時或在它們計劃啟動時啟動。 一旦完成,DMS 任務就完成了。
- 更改數據捕獲 (CDC) – 在此模式下,DMS 任務連續運行。 DMS 掃描源數據庫以查找表級別的更改。 如果發生更改,它會立即嘗試根據與更改表相關的 DMS 任務中的配置將更改複製到目標數據庫中。
在選擇 CDC 時,您需要做出另一個選擇——即 CDC 如何從源數據庫中提取增量更改。
#1。 Oracle 重做日誌讀取器
一種選擇是從 Oracle 選擇本機數據庫重做日誌讀取器,CDC 可以利用它來獲取更改的數據,並根據最新的更改,在目標數據庫上複製相同的更改。
如果將 Oracle 作為源處理,這看起來是一個顯而易見的選擇,但有一個問題:Oracle 重做日誌讀取器利用源 Oracle 集群,因此直接影響數據庫中運行的所有其他活動(它實際上直接在數據庫)。
您配置的 DMS 任務越多(或併行的 DMS 集群越多),您可能需要越多地擴大 Oracle 集群——基本上,調整主 Oracle 數據庫集群的垂直擴展。 這肯定會影響解決方案的總成本,如果每日同步將在項目中長期存在,則更是如此。
#2。 AWS DMS 日誌挖掘器
與上面的選項不同,這是針對同一問題的原生 AWS 解決方案。 在這種情況下,DMS 不會影響源 Oracle 數據庫。 相反,它將 Oracle 重做日誌複製到 DMS 集群並在那裡進行所有處理。 雖然它節省了 Oracle 資源,但它是較慢的解決方案,因為涉及更多操作。 而且,正如人們可以很容易地假設的那樣,Oracle 重做日誌的自定義讀取器作為 Oracle 的本地讀取器在其工作中可能更慢。
根據源數據庫的大小和每日更改的數量,在最好的情況下,您可能最終將數據從本地 Oracle 數據庫幾乎實時地增量同步到 AWS 雲數據庫中。
在任何其他情況下,它仍然不會接近實時同步,但您可以嘗試通過調整源和目標集群性能配置和並行性或試驗來盡可能接近可接受的延遲(源和目標之間) DMS 任務的數量及其在 CDC 實例之間的分佈。
您可能想了解 CDC 支持哪些源表更改(例如添加列),因為並非所有可能的更改都受支持。 在某些情況下,唯一的方法是手動更改目標表並從頭開始重新啟動 CDC 任務(在此過程中丟失目標數據庫中的所有現有數據)。
當事情出錯時,無論如何

我通過艱難的方式學到了這一點,但是有一個與 DMS 相關的特定場景很難實現每日復制的承諾。
DMS 只能以某種定義的速度處理重做日誌。 是否有更多 DMS 實例執行您的任務並不重要。 儘管如此,每個 DMS 實例僅以單一定義的速度讀取重做日誌,並且每個實例都必須完整讀取它們。 使用 Oracle 重做日誌或 AWS 日誌挖掘器甚至都沒有關係。 兩者都有這個限制。
如果源數據庫在一天內包含大量更改,而 Oracle 重做日誌每天都變得非常大(例如 500GB+ 大),CDC 將無法正常工作。 複製不會在當天結束前完成。 它會將一些未處理的工作帶到第二天,而要復制的一組新更改已經在等待。 未處理的數據量只會一天比一天增長。
在這種特殊情況下,CDC 不是一個選項(在我們執行了許多性能測試和嘗試之後)。 如何確保至少從當天開始的所有增量更改都將在同一天復制的唯一方法是像這樣處理它:
- 分離不經常使用的非常大的表,每週只複製一次(例如,在周末)。
- 將不太大但仍然很大的表的複製配置為在多個 DMS 任務之間拆分; 一張表最終由 10 個或更多獨立的 DMS 任務並行遷移,確保 DMS 任務之間的數據拆分是不同的(此處涉及自定義編碼)並每天執行。
- 添加更多(在本例中最多 4 個)DMS 實例,並在它們之間平均分配 DMS 任務,這意味著不僅按表的數量而且按大小分配。
基本上,我們使用 DMS 的全負載模式來複製每日數據,因為這是實現至少當天數據複製完成的唯一方法。
這不是一個完美的解決方案,但它仍然存在,即使在多年之後,仍然以同樣的方式工作。 所以,也許畢竟不是那麼糟糕的解決方案。