
機器學習中的支持向量機 (SVM)
已發表: 2023-01-04支持向量機是最流行的機器學習算法之一。 它很高效,可以在有限的數據集上進行訓練。 但它是什麼?
什麼是支持向量機 (SVM)?
支持向量機是一種機器學習算法,它使用監督學習來創建二元分類模型。 那是一口。 本文將解釋 SVM 及其與自然語言處理的關係。 但首先,讓我們分析一下支持向量機的工作原理。
SVM 是如何工作的?
考慮一個簡單的分類問題,其中我們的數據具有兩個特徵 x 和 y,以及一個輸出——紅色或藍色的分類。 我們可以繪製一個如下所示的假想數據集:
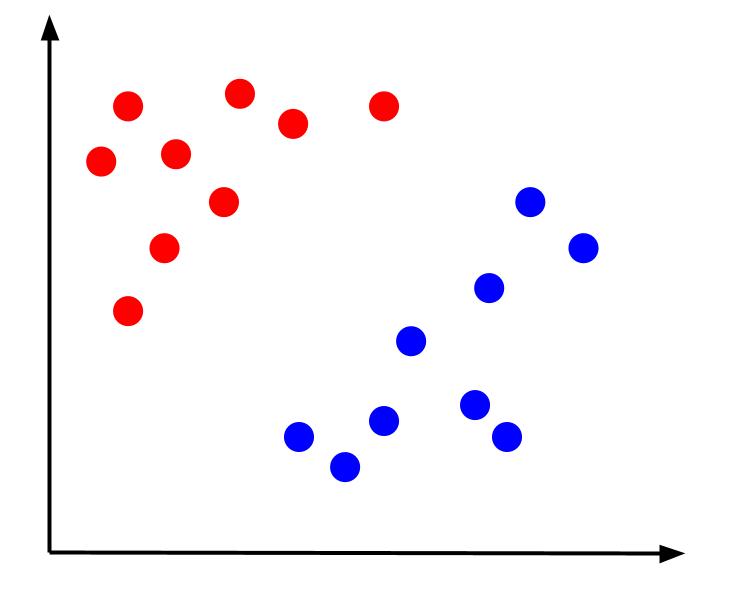
給定這樣的數據,任務就是創建決策邊界。 決策邊界是一條分隔兩類數據點的線。 這是同一個數據集,但有一個決策邊界:
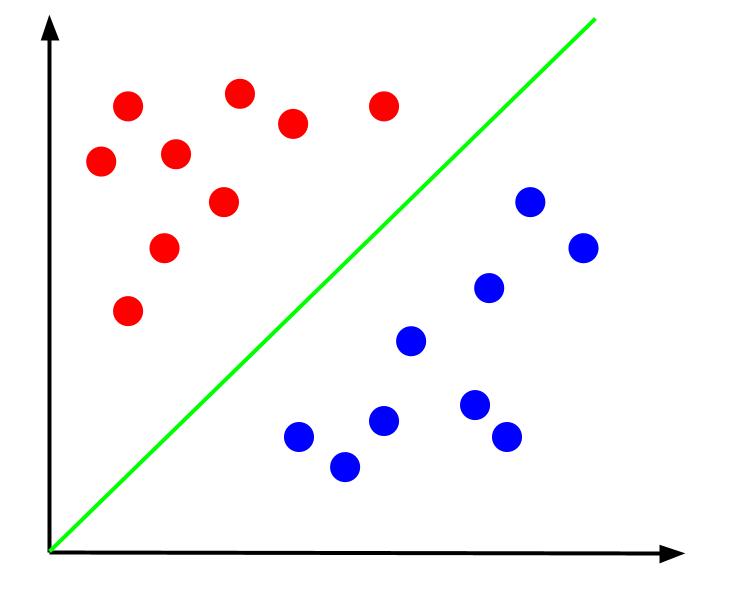
有了這個決策邊界,我們就可以預測數據點屬於哪個類,給定它相對於決策邊界的位置。 支持向量機算法創建將用於對點進行分類的最佳決策邊界。
但是我們所說的最佳決策邊界是什麼意思?
最佳決策邊界可以被認為是最大化其與支持向量之一的距離的邊界。 支持向量是最接近相反類的任一類的數據點。 由於這些數據點與其他類別的距離很近,因此造成錯誤分類的風險最大。
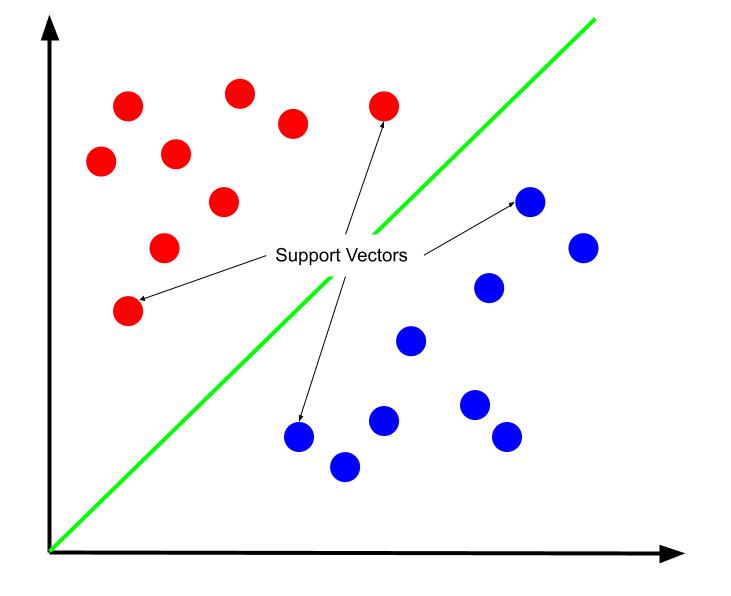
因此,支持向量機的訓練涉及嘗試找到使支持向量之間的邊距最大化的直線。
同樣重要的是要注意,因為決策邊界是相對於支持向量定位的,所以它們是決策邊界位置的唯一決定因素。 因此,其他數據點是多餘的。 因此,訓練只需要支持向量。
在這個例子中,形成的決策邊界是一條直線。 這只是因為數據集只有兩個特徵。 當數據集具有三個特徵時,形成的決策邊界是一個平面而不是一條線。 當它具有四個或更多特徵時,決策邊界稱為超平面。
非線性可分數據
上面的示例考慮了非常簡單的數據,在繪製時可以用線性決策邊界分隔這些數據。 考慮另一種情況,數據繪製如下:
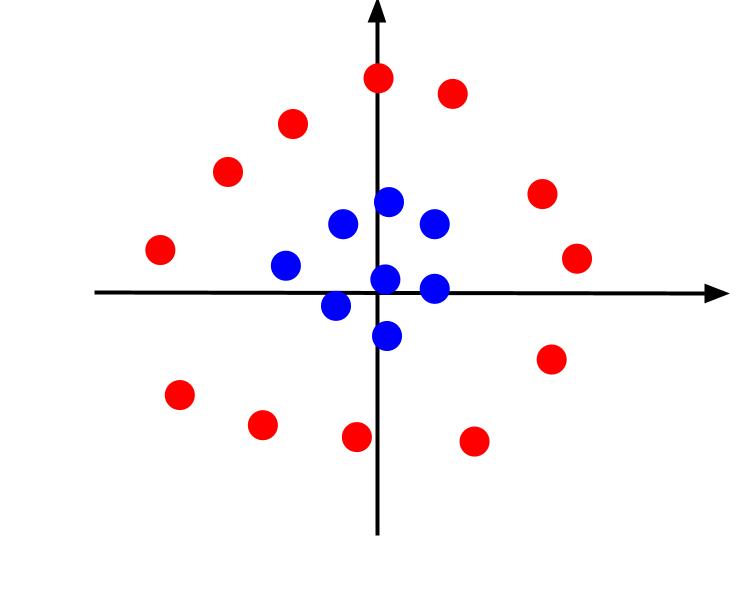
在這種情況下,不可能用線分隔數據。 但是我們可以創建另一個特徵 z。 這個特徵可以用等式定義:z = x^2 + y^2。 我們可以將 z 作為第三個軸添加到平面上,使其成為三維的。
當我們從 x 軸水平而 z 軸垂直的角度查看 3D 圖時,這就是我們得到的視圖,如下所示:
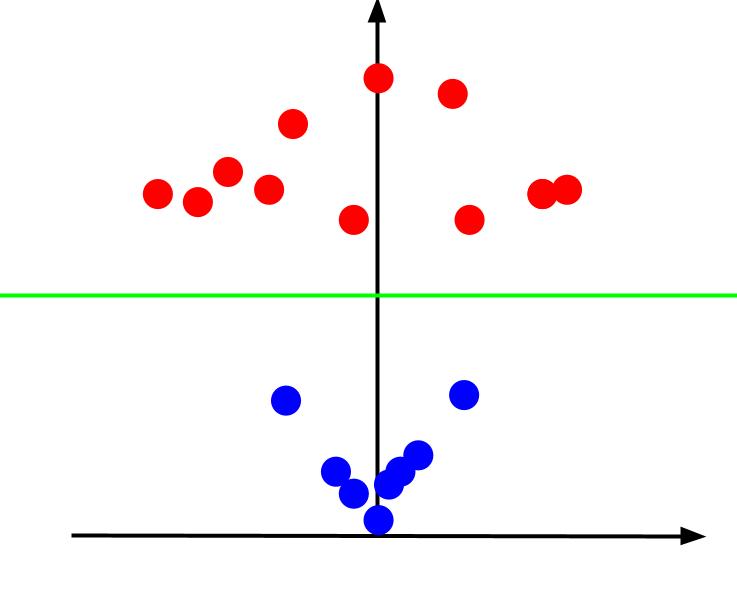
z 值表示相對於舊 XY 平面中的其他點,一個點距原點的距離。 因此,靠近原點的藍點具有較低的 z 值。
雖然離原點較遠的紅點具有較高的 z 值,但根據它們的 z 值繪製它們可以給我們一個清晰的分類,可以通過線性決策邊界劃分,如圖所示。
這是支持向量機中使用的一個強大的想法。 更一般地說,它是將維度映射到更多維度的想法,這樣數據點就可以被線性邊界分開。 負責此的函數是內核函數。 核函數有很多,例如sigmoid、線性、非線性和RBF。
為了更有效地映射這些特徵,SVM 使用了內核技巧。
機器學習中的支持向量機
支持向量機是機器學習中與決策樹和神經網絡等流行算法一起使用的眾多算法之一。 它之所以受到青睞,是因為與其他算法相比,它可以在更少的數據下運行良好。 它通常用於執行以下操作:
- 文本分類:將評論、評論等文本數據分類為一類或多類
- 人臉檢測:分析圖像以檢測人臉來做一些事情,例如為增強現實添加過濾器
- 圖像分類:與其他方法相比,支持向量機可以有效地對圖像進行分類。
文本分類問題
互聯網上充斥著大量的文本數據。 然而,這些數據中的大部分是非結構化和未標記的。 為了更好地使用這些文本數據並更多地理解它,需要進行分類。 文本被分類的時間示例包括:
- 當推文被分類為主題時,人們可以關注他們想要的主題
- 當電子郵件被歸類為社交、促銷或垃圾郵件時
- 當評論在公共論壇中被歸類為仇恨或淫穢時
SVM 如何處理自然語言分類
支持向量機用於將文本分類為屬於特定主題的文本和不屬於該主題的文本。 這是通過首先將文本數據轉換並表示為具有多個特徵的數據集來實現的。
一種方法是為數據集中的每個單詞創建特徵。 然後對於每個文本數據點,您記錄每個單詞出現的次數。 因此,假設數據集中出現了獨特的詞; 您將在數據集中擁有功能。
此外,您將為這些數據點提供分類。 雖然這些分類是用文本標記的,但大多數 SVM 實現都需要數字標籤。
因此,您必須在訓練前將這些標籤轉換為數字。 準備好數據集後,使用這些特徵作為坐標,您就可以使用 SVM 模型對文本進行分類。
在 Python 中創建 SVM
要在 Python 中創建支持向量機 (SVM),您可以使用sklearn.svm庫中的SVC類。 以下是如何使用SVC類在 Python 中構建 SVM 模型的示例:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) 在這個例子中,我們首先從sklearn.svm庫中導入SVC類。 然後,我們加載數據集並將其拆分為訓練集和測試集。
接下來,我們通過實例化SVC對象並將kernel參數指定為“線性”來創建 SVM 模型。 然後,我們使用fit方法在訓練數據上訓練模型,並使用score方法在測試數據上評估模型。 score方法返回模型的準確性,我們將其打印到控制台。
您還可以為SVC對象指定其他參數,例如控制正則化強度的C參數和控制某些內核的內核係數的gamma參數。
支持向量機的好處
以下列出了使用支持向量機 (SVM) 的一些好處:
- 高效:支持向量機的訓練通常是高效的,尤其是當樣本數量很大時。
- 對噪聲具有魯棒性:SVM 對訓練數據中的噪聲具有相對魯棒性,因為它們試圖找到最大邊緣分類器,該分類器對噪聲的敏感度低於其他分類器。
- 內存效率高: SVM 只需要訓練數據的一個子集在任何給定時間都在內存中,這使得它們比其他算法更具內存效率。
- 在高維空間中有效:即使特徵數量超過樣本數量,SVM 仍然可以表現良好。
- 多功能性:支持向量機可用於分類和回歸任務,可以處理各種類型的數據,包括線性和非線性數據。
現在,讓我們探索一些學習支持向量機 (SVM) 的最佳資源。
學習資源
支持向量機簡介
這本關於支持向量機介紹的書全面地、逐步地向你介紹了基於核的學習方法。
| 預習 | 產品 | 評分 | 價格 | |
|---|---|---|---|---|
 | 支持向量機和其他基於內核的學習方法簡介 | 75.00 美元 | 在亞馬遜上購買 |
它為您提供支持向量機理論的堅實基礎。

支持向量機應用
第一本書側重於支持向量機的理論,而這本關於支持向量機應用的書則側重於它們的實際應用。
| 預習 | 產品 | 評分 | 價格 | |
|---|---|---|---|---|
 | 支持向量機應用 | 15.52 美元 | 在亞馬遜上購買 |
它著眼於 SVM 如何用於圖像處理、模式檢測和計算機視覺。
支持向量機(信息科學與統計學)
這本關於支持向量機(信息科學與統計學)的書的目的是概述支持向量機 (SVM) 在各種應用中的有效性背後的原理。
| 預習 | 產品 | 評分 | 價格 | |
|---|---|---|---|---|
 | 支持向量機(信息科學與統計學) | 167.36 美元 | 在亞馬遜上購買 |
作者強調了有助於 SVM 成功的幾個因素,包括它們在有限數量的可調參數下表現良好的能力、它們對各種類型的錯誤和異常的抵抗力,以及與其他方法相比的高效計算性能。
學習內核
《Learning with Kernels》是一本向讀者介紹支持向量機(SVM)和相關核技術的書籍。
| 預習 | 產品 | 評分 | 價格 | |
|---|---|---|---|---|
 | 使用內核學習:支持向量機、正則化、優化等(自適應…… | $80.00 | 在亞馬遜上購買 |
它旨在讓讀者對數學有一個基本的了解,以及他們開始在機器學習中使用核算法所需的知識。 本書旨在提供對 SVM 和內核方法的全面且易於理解的介紹。
使用 Sci-kit Learn 支持向量機
這個由 Coursera 項目網絡提供的帶有 Sci-kit Learn 的在線支持向量機課程教授如何使用流行的機器學習庫 Sci-Kit Learn 實現 SVM 模型。

此外,您還將學習 SVM 背後的理論並確定它們的優勢和局限性。 該課程是初級水平,需要大約 2.5 小時。
Python 中的支持向量機:概念和代碼
這個由 Udemy 提供的關於 Python 支持向量機的付費在線課程有長達 6 小時的視頻教學,並附帶認證。

它涵蓋了 SVM 以及如何在 Python 中可靠地實現它們。 此外,它還涵蓋了支持向量機的商業應用。
機器學習和人工智能:Python 中的支持向量機
在本機器學習和人工智能課程中,您將學習如何將支持向量機 (SVM) 用於各種實際應用,包括圖像識別、垃圾郵件檢測、醫學診斷和回歸分析。

您將使用 Python 編程語言為這些應用程序實施 ML 模型。
最後的話
在本文中,我們簡要了解了支持向量機背後的理論。 我們了解了它們在機器學習和自然語言處理中的應用。
我們還看到了它使用scikit-learn的實現是什麼樣子的。 此外,我們還談到了支持向量機的實際應用和優勢。
雖然本文只是介紹,但其他資源建議進行更詳細的介紹,詳細解釋支持向量機。 鑑於它們的通用性和高效性,SVM 值得理解以成長為數據科學家和 ML 工程師。
接下來,您可以查看頂級機器學習模型。