
異常檢測:防止網絡入侵指南
已發表: 2023-01-09數據是企業和組織不可或缺的一部分,只有在正確構建和有效管理的情況下,它才有價值。
據統計,如今 95% 的企業發現管理和構建非結構化數據是一個問題。
這就是數據挖掘的用武之地。它是從大量非結構化數據中發現、分析和提取有意義的模式和有價值信息的過程。
公司使用軟件識別大量數據中的模式,以更多地了解他們的客戶和目標受眾,並製定業務和營銷策略以提高銷售額和降低成本。
除了這個好處,欺詐和異常檢測是數據挖掘最重要的應用。
本文介紹異常檢測並進一步探討它如何幫助防止數據洩露和網絡入侵以確保數據安全。
什麼是異常檢測及其類型?

雖然數據挖掘涉及查找關聯在一起的模式、相關性和趨勢,但它是查找網絡中異常或離群數據點的好方法。
數據挖掘中的異常是與數據集中的其他數據點不同並且偏離數據集正常行為模式的數據點。
異常可以分為不同的類型和類別,包括:
- 事件的變化:指從以前的正常行為突然或系統的變化。
- 異常值:在數據收集中以非系統方式出現的小異常模式。 這些可以進一步分為全局異常值、上下文異常值和集體異常值。
- 漂移:數據集中逐漸的、無方向的和長期的變化。
因此,異常檢測是一種數據處理技術,對於檢測欺詐交易、處理具有高級不平衡的案例研究以及疾病檢測以構建強大的數據科學模型非常有用。
例如,一家公司可能希望分析其現金流,以發現未知銀行賬戶的異常或重複交易,從而發現欺詐行為並進行進一步調查。
異常檢測的好處
用戶行為異常檢測有助於加強安全系統並使其更加精確和準確。
它分析並理解安全系統提供的各種信息,以識別網絡中的威脅和潛在風險。
以下是公司異常檢測的優勢:
- 實時檢測網絡安全威脅和數據洩露,因為其人工智能 (AI) 算法會不斷掃描您的數據以發現異常行為。
- 與手動異常檢測相比,它可以更快、更輕鬆地跟踪異常活動和模式,從而減少解決威脅所需的勞動力和時間。
- 通過在操作錯誤(例如突然的性能下降)發生之前識別操作錯誤,最大限度地降低操作風險。
- 它通過快速檢測異常來幫助消除重大業務損失,因為如果沒有異常檢測系統,公司可能需要數周和數月的時間來識別潛在威脅。
因此,異常檢測是企業存儲大量客戶和業務數據集以尋找增長機會並消除安全威脅和運營瓶頸的巨大資產。
異常檢測技術
異常檢測使用多種程序和機器學習 (ML) 算法來監控數據和檢測威脅。
以下是主要的異常檢測技術:
#1。 機器學習技術

機器學習技術使用 ML 算法來分析數據和檢測異常。 用於異常檢測的不同類型的機器學習算法包括:
- 聚類算法
- 分類算法
- 深度學習算法
用於異常和威脅檢測的常用 ML 技術包括支持向量機 (SVM)、k 均值聚類和自動編碼器。
#2。 統計技術
統計技術使用統計模型來檢測數據中的異常模式(如特定機器性能的異常波動),以檢測超出預期值範圍的值。
常見的統計異常檢測技術包括假設檢驗、IQR、Z-score、修正 Z-score、密度估計、箱線圖、極值分析和直方圖。
#3。 數據挖掘技術

數據挖掘技術使用數據分類和聚類技術來查找數據集中的異常。 一些常見的數據挖掘異常技術包括譜聚類、基於密度的聚類和主成分分析。
聚類數據挖掘算法用於根據不同數據點的相似性將不同的數據點分組到集群中,以查找數據點和落在這些集群之外的異常。
另一方面,分類算法將數據點分配給特定的預定義類,並檢測不屬於這些類的數據點。
#4。 基於規則的技術
顧名思義,基於規則的異常檢測技術使用一組預先確定的規則來查找數據中的異常。
這些技術的設置相對更容易和更簡單,但可能不夠靈活,並且在適應不斷變化的數據行為和模式方面可能效率不高。
例如,您可以輕鬆地編寫一個基於規則的系統,將超過特定金額的交易標記為欺詐交易。
#5。 領域特定技術
您可以使用特定領域的技術來檢測特定數據系統中的異常。 然而,雖然它們在檢測特定領域的異常方面可能非常有效,但在指定領域之外的其他領域可能效率較低。
例如,使用特定領域的技術,您可以專門設計技術來查找金融交易中的異常情況。 但是,它們可能無法用於發現機器中的異常或性能下降。
異常檢測需要機器學習
機器學習在異常檢測中非常重要且非常有用。
如今,大多數需要異常值檢測的公司和組織都處理大量數據,從文本、客戶信息和交易到圖像和視頻內容等媒體文件。
手動檢查每秒生成的所有銀行交易和數據以驅動有意義的洞察力幾乎是不可能的。 此外,大多數公司在構建非結構化數據和以有意義的方式安排數據以進行數據分析方面面臨挑戰和重大困難。
這就是機器學習 (ML) 等工具和技術在收集、清理、構建、安排、分析和存儲大量非結構化數據方面發揮巨大作用的地方。
機器學習技術和算法處理大型數據集,並提供使用和組合不同技術和算法的靈活性,以提供最佳結果。
此外,機器學習還有助於簡化實際應用程序的異常檢測過程並節省寶貴的資源。
以下是機器學習在異常檢測中的更多好處和重要性:
- 它通過自動識別模式和異常而無需顯式編程,從而使縮放異常檢測變得更加容易。
- 機器學習算法高度適應不斷變化的數據集模式,使它們隨著時間的推移變得高效和穩健。
- 輕鬆處理大型和復雜的數據集,儘管數據集很複雜,但仍能高效地進行異常檢測。
- 通過在異常發生時識別它們來確保及早識別和檢測異常,從而節省時間和資源。
- 與傳統方法相比,基於機器學習的異常檢測系統有助於實現更高水平的異常檢測準確性。
因此,異常檢測與機器學習相結合有助於更快、更早地檢測異常,以防止安全威脅和惡意破壞。
用於異常檢測的機器學習算法
您可以藉助用於分類、聚類或關聯規則學習的不同數據挖掘算法來檢測數據中的異常和異常值。
通常,這些數據挖掘算法分為兩個不同的類別——監督學習算法和非監督學習算法。

監督學習
監督學習是一種常見的學習算法,由支持向量機、邏輯和線性回歸以及多類分類等算法組成。 該算法類型是在標記數據上訓練的,這意味著其訓練數據集既包括正常輸入數據,也包括相應的正確輸出或異常示例,以構建預測模型。
因此,它的目標是根據訓練數據集模式對未見數據和新數據進行輸出預測。 監督學習算法的應用包括圖像和語音識別、預測建模和自然語言處理 (NLP)。
無監督學習
無監督學習 沒有在任何標記數據上訓練。 相反,它在不提供訓練算法指導的情況下發現複雜的過程和底層數據結構,而不是做出具體的預測。
無監督學習算法的應用包括異常檢測、密度估計和數據壓縮。
現在,讓我們探索一些流行的基於機器學習的異常檢測算法。
局部離群因子 (LOF)
Local Outlier Factor 或 LOF 是一種異常檢測算法,它考慮局部數據密度來確定數據點是否異常。
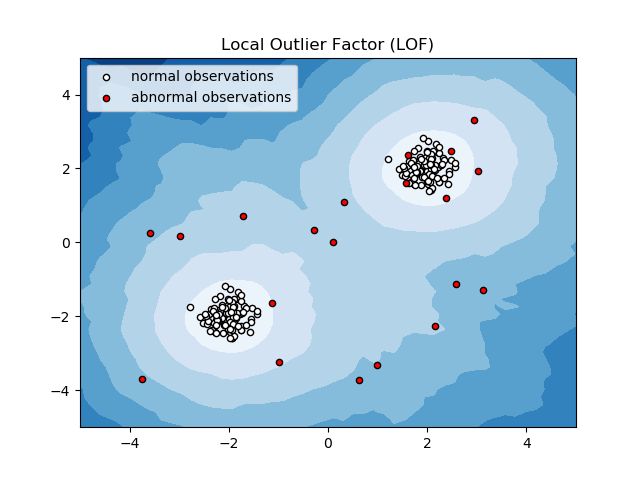
它將一個項目的局部密度與其鄰居的局部密度進行比較,以分析密度相似的區域和密度低於其鄰居的項目——這些區域只不過是異常或異常值。
因此,簡單來說,異常值或異常項周圍的密度與其相鄰項周圍的密度不同。 因此,該算法也稱為基於密度的異常值檢測算法。
K 最近鄰 (K-NN)
K-NN 是最簡單的分類和監督異常檢測算法,易於實現,存儲所有可用的示例和數據,並根據距離度量的相似性對新示例進行分類。
這種分類算法也稱為惰性學習器,因為它只存儲標記的訓練數據——在訓練過程中不做任何其他事情。
當新的未標記訓練數據點到達時,算法會查看 K 最近或最接近的訓練數據點,以使用它們對新的未標記數據點進行分類和確定類別。
K-NN算法使用以下檢測方法來確定最近的數據點:
- 歐幾里得距離,用於衡量連續數據的距離。
- 漢明距離,用於衡量離散數據的兩個文本字符串的接近度或“接近度”。
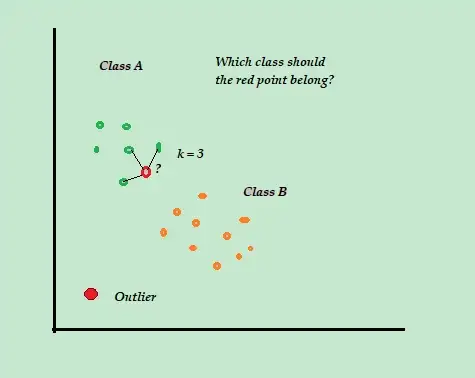
例如,假設您的訓練數據集由兩個類標籤 A 和 B 組成。如果新數據點到達,算法將計算新數據點與數據集中每個數據點之間的距離並選擇點這是最接近新數據點的最大數量。
因此,假設 K=3,並且 3 個數據點中有 2 個標記為 A,則新數據點標記為 A 類。
因此,K-NN 算法在具有頻繁數據更新要求的動態環境中效果最佳。
它是一種流行的異常檢測和文本挖掘算法,在金融和商業領域有應用,可以檢測欺詐交易並提高欺詐檢測率。
支持向量機 (SVM)
支持向量機是一種基於監督機器學習的異常檢測算法,主要用於回歸和分類問題。
它使用多維超平面將數據分為兩組(新的和正常的)。 因此,超平面充當分隔正常數據觀察和新數據的決策邊界。
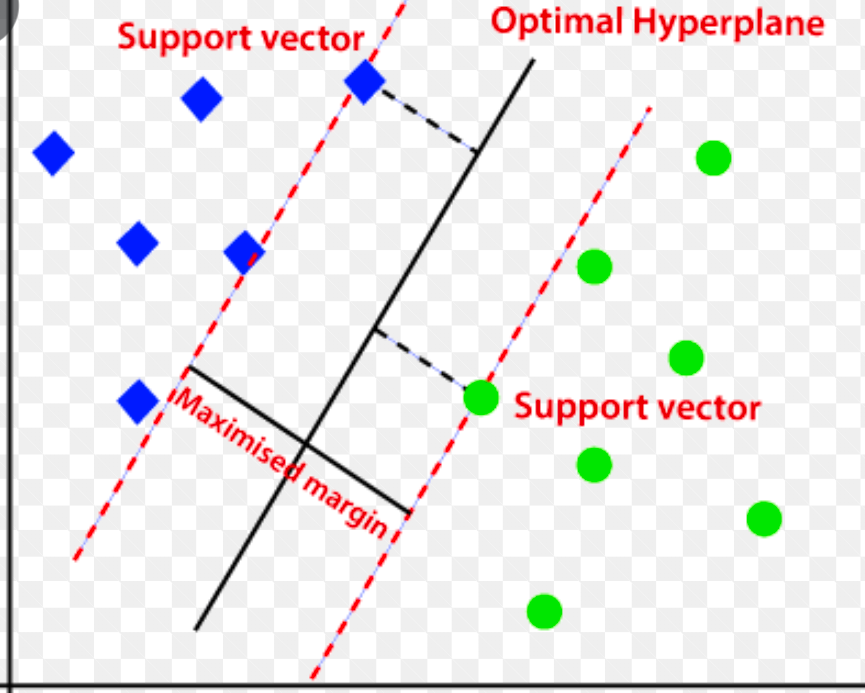
這兩個數據點之間的距離稱為邊距。
由於目標是增加兩點之間的距離,SVM 確定具有最大邊距的最佳或最優超平面,以確保兩個類之間的距離盡可能寬。
關於異常檢測,SVM 從超平面計算新數據點觀察的邊距以對其進行分類。
如果邊距超過設定的閾值,它將新觀察分類為異常。 同時,如果 margin 小於閾值,則將觀察分類為正常。
因此,支持向量機算法在處理高維和復雜數據集方面非常有效。
隔離林
孤立森林是一種基於隨機森林分類器概念的無監督機器學習異常檢測算法。
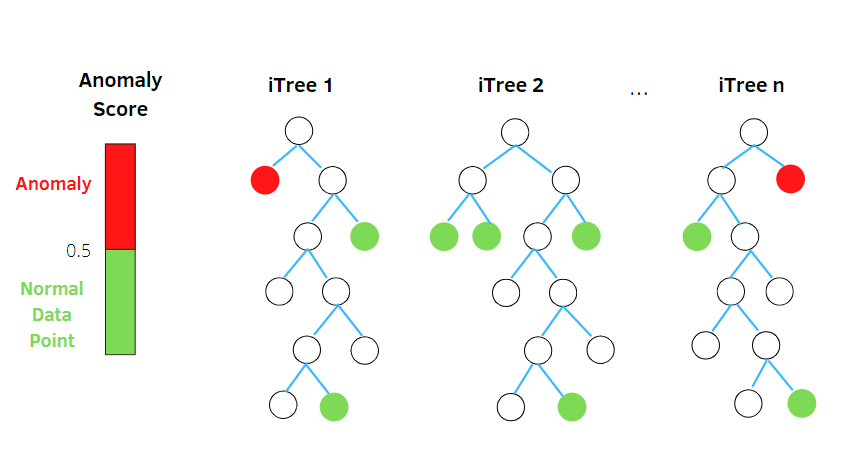
該算法根據隨機屬性以樹結構對數據集中的隨機子採樣數據進行處理。 它構建了幾個決策樹來隔離觀察。 如果它根據其污染率被隔離在較少的樹木中,它就會認為一個特定的觀察結果是異常的。
因此,簡單來說,隔離森林算法將數據點拆分到不同的決策樹中——確保每個觀察值都與另一個觀察值隔離開來。
異常通常遠離數據點集群——與正常數據點相比,更容易識別異常。
隔離森林算法可以輕鬆處理分類數據和數值數據。 因此,它們的訓練速度更快,並且在檢測高維和大型數據集異常方面效率更高。
四分位間距
四分位數間距或 IQR 用於測量統計變異性或統計離散度,以通過將數據集劃分為四分位數來查找數據集中的異常點。
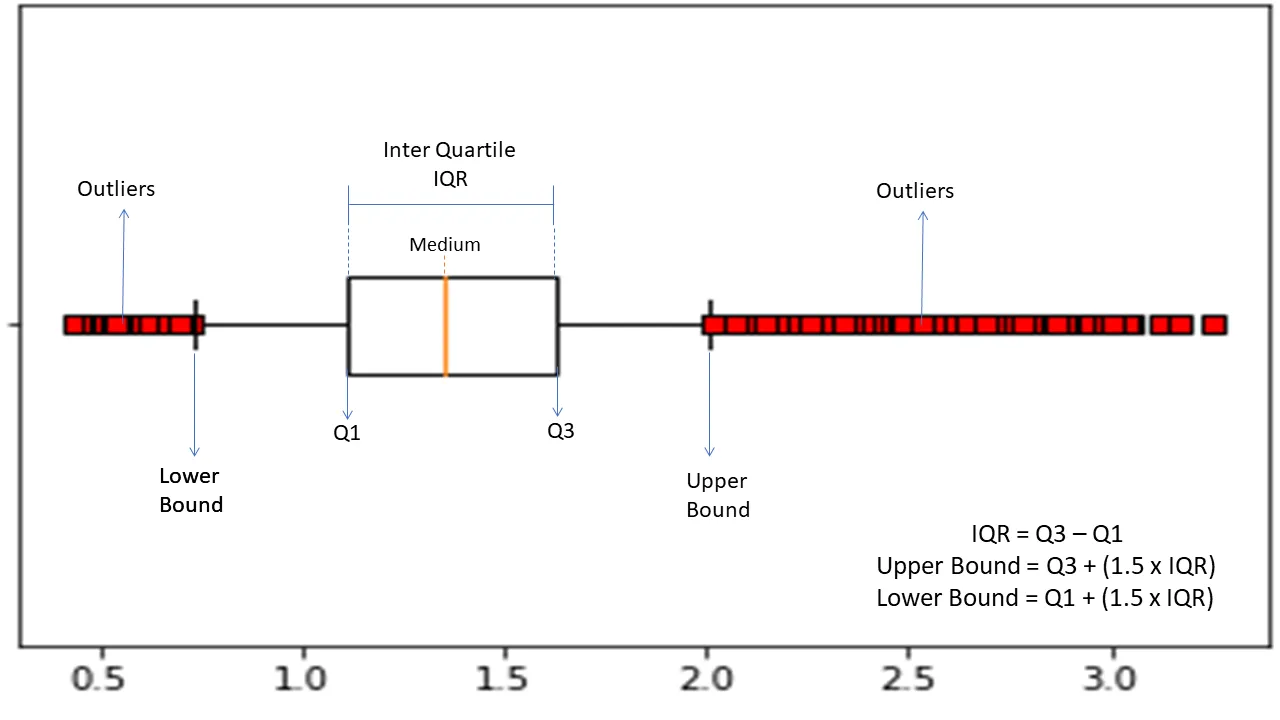
該算法按升序對數據進行排序,並將數據集分成四個相等的部分。 分隔這些部分的值是 Q1、Q2 和 Q3——第一、第二和第三四分位數。
這是這些四分位數的百分位數分佈:
- Q1 表示數據的第 25 個百分位數。
- Q2 表示數據的第 50 個百分位數。
- Q3 表示數據的第 75 個百分位數。
IQR 是第三個(第 75 個)和第一個(第 25 個)百分位數數據集之間的差異,代表數據的 50%。
使用 IQR 進行異常檢測需要您計算數據集的 IQR 並定義數據的下限和上限以發現異常。
- 下邊界:Q1 – 1.5 * IQR
- 上限:Q3 + 1.5 * IQR
通常,落在這些邊界之外的觀測值被認為是異常。
IQR 算法對於數據分佈不均勻且分佈不太清楚的數據集有效。
最後的話
未來幾年,網絡安全風險和數據洩露似乎不會得到遏制——這個高風險行業預計將在 2023 年進一步增長,而僅物聯網網絡攻擊一項預計到 2025 年就會翻一番。
此外,到 2025 年,網絡犯罪將使全球公司和組織每年損失約 10.3 萬億美元。
這就是為什麼對異常檢測技術的需求在當今對於欺詐檢測和防止網絡入侵變得越來越普遍和必要。
本文將幫助您了解數據挖掘中的異常是什麼、不同類型的異常以及使用基於 ML 的異常檢測技術來防止網絡入侵的方法。
接下來,您可以探索機器學習中關於混淆矩陣的一切。