
机器学习中的支持向量机 (SVM)
已发表: 2023-01-04支持向量机是最流行的机器学习算法之一。 它很高效,可以在有限的数据集上进行训练。 但它是什么?
什么是支持向量机 (SVM)?
支持向量机是一种机器学习算法,它使用监督学习来创建二元分类模型。 那是一口。 本文将解释 SVM 及其与自然语言处理的关系。 但首先,让我们分析一下支持向量机的工作原理。
SVM 是如何工作的?
考虑一个简单的分类问题,其中我们的数据具有两个特征 x 和 y,以及一个输出——红色或蓝色的分类。 我们可以绘制一个如下所示的假想数据集:
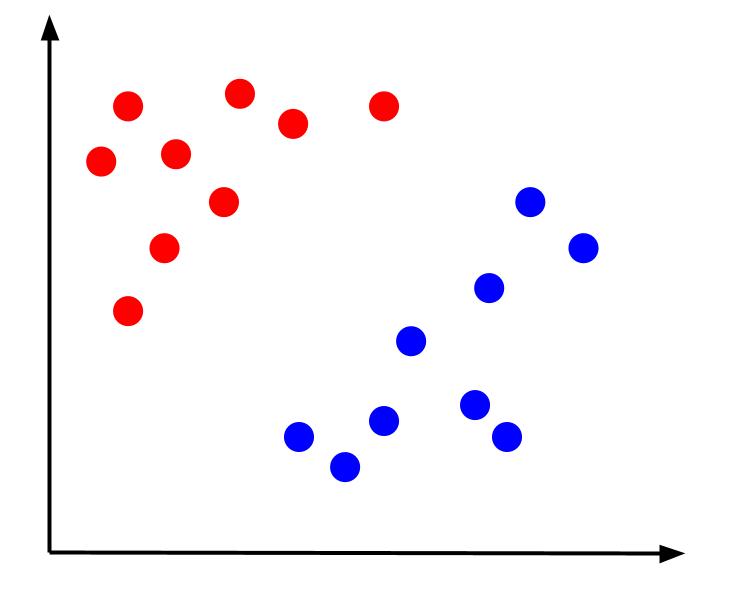
给定这样的数据,任务就是创建决策边界。 决策边界是一条分隔两类数据点的线。 这是同一个数据集,但有一个决策边界:
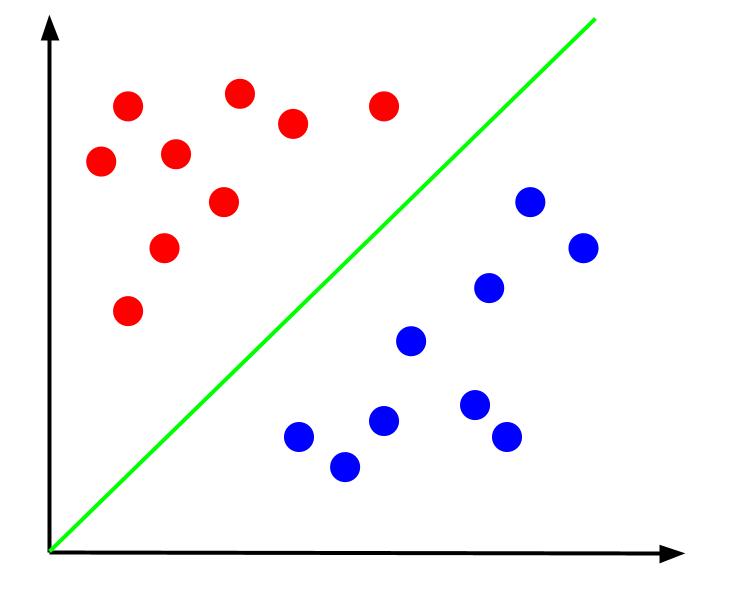
有了这个决策边界,我们就可以预测数据点属于哪个类,给定它相对于决策边界的位置。 支持向量机算法创建将用于对点进行分类的最佳决策边界。
但是我们所说的最佳决策边界是什么意思?
最佳决策边界可以被认为是最大化其与支持向量之一的距离的边界。 支持向量是最接近相反类的任一类的数据点。 由于这些数据点与其他类别的距离很近,因此造成错误分类的风险最大。
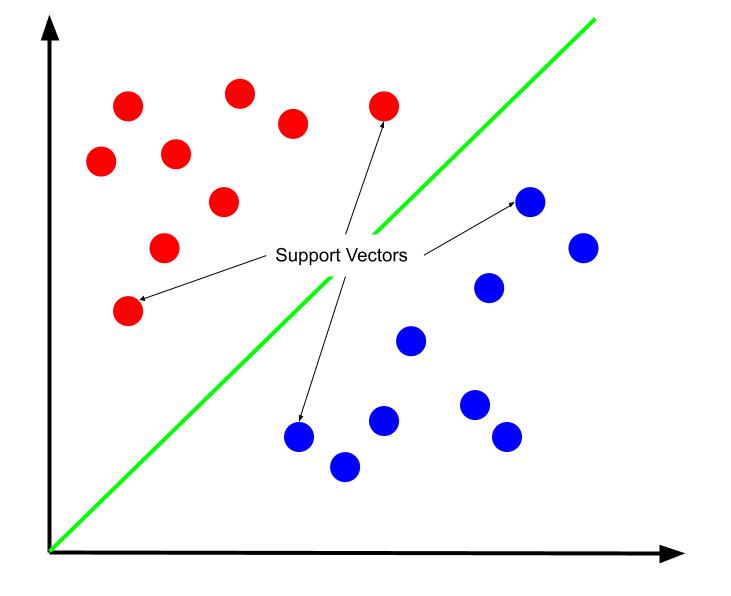
因此,支持向量机的训练涉及尝试找到使支持向量之间的边距最大化的直线。
同样重要的是要注意,因为决策边界是相对于支持向量定位的,所以它们是决策边界位置的唯一决定因素。 因此,其他数据点是多余的。 因此,训练只需要支持向量。
在这个例子中,形成的决策边界是一条直线。 这只是因为数据集只有两个特征。 当数据集具有三个特征时,形成的决策边界是一个平面而不是一条线。 当它具有四个或更多特征时,决策边界称为超平面。
非线性可分数据
上面的示例考虑了非常简单的数据,在绘制时可以用线性决策边界分隔这些数据。 考虑另一种情况,数据绘制如下:
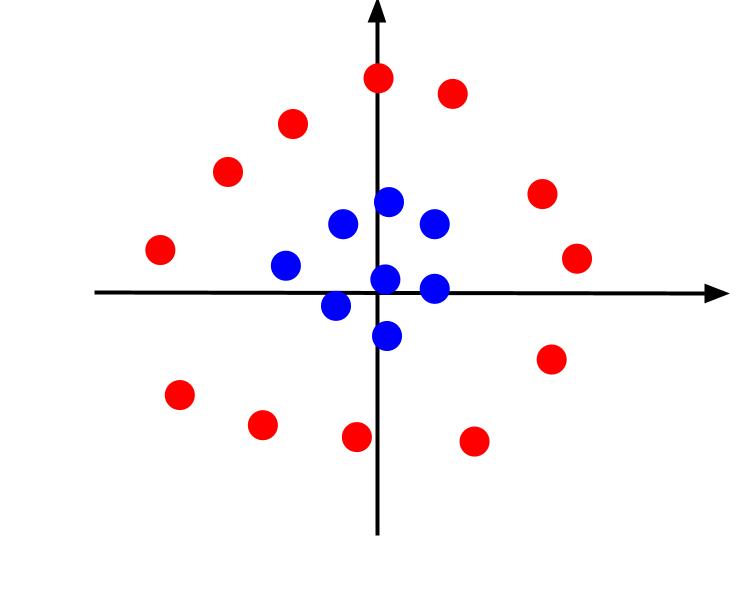
在这种情况下,不可能用线分隔数据。 但是我们可以创建另一个特征 z。 这个特征可以用等式定义:z = x^2 + y^2。 我们可以将 z 作为第三个轴添加到平面上,使其成为三维的。
当我们从 x 轴水平而 z 轴垂直的角度查看 3D 图时,这就是我们得到的视图,如下所示:
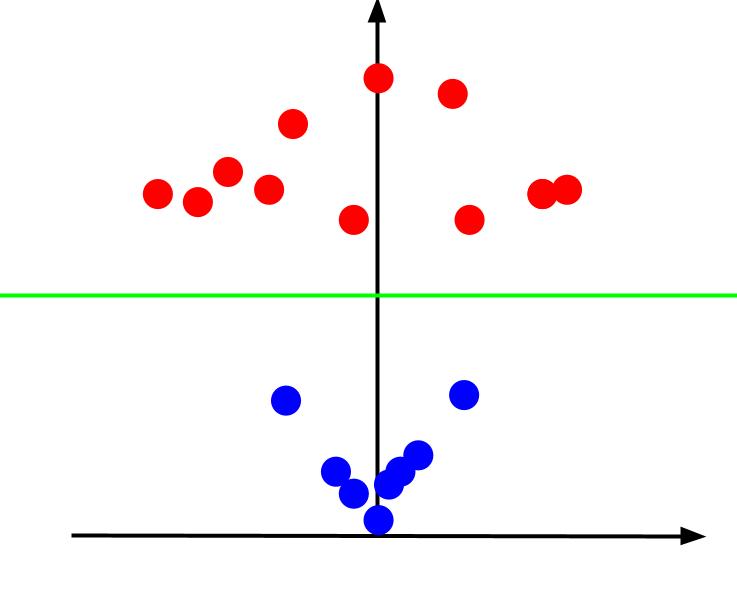
z 值表示相对于旧 XY 平面中的其他点,一个点距原点的距离。 因此,靠近原点的蓝点具有较低的 z 值。
虽然离原点较远的红点具有较高的 z 值,但根据它们的 z 值绘制它们可以给我们一个清晰的分类,可以通过线性决策边界划分,如图所示。
这是支持向量机中使用的一个强大的想法。 更一般地说,它是将维度映射到更多维度的想法,这样数据点就可以被线性边界分开。 负责此的函数是内核函数。 核函数有很多,例如sigmoid、线性、非线性和RBF。
为了更有效地映射这些特征,SVM 使用了内核技巧。
机器学习中的支持向量机
支持向量机是机器学习中与决策树和神经网络等流行算法一起使用的众多算法之一。 它之所以受到青睐,是因为与其他算法相比,它可以在更少的数据下运行良好。 它通常用于执行以下操作:
- 文本分类:将评论、评论等文本数据分类为一类或多类
- 人脸检测:分析图像以检测人脸来做一些事情,例如为增强现实添加过滤器
- 图像分类:与其他方法相比,支持向量机可以有效地对图像进行分类。
文本分类问题
互联网上充斥着大量的文本数据。 然而,这些数据中的大部分是非结构化和未标记的。 为了更好地使用这些文本数据并更多地理解它,需要进行分类。 文本被分类的时间示例包括:
- 当推文被分类为主题时,人们可以关注他们想要的主题
- 当电子邮件被归类为社交、促销或垃圾邮件时
- 当评论在公共论坛中被归类为仇恨或淫秽时
SVM 如何处理自然语言分类
支持向量机用于将文本分类为属于特定主题的文本和不属于该主题的文本。 这是通过首先将文本数据转换并表示为具有多个特征的数据集来实现的。
一种方法是为数据集中的每个单词创建特征。 然后对于每个文本数据点,您记录每个单词出现的次数。 因此,假设数据集中出现了独特的词; 您将在数据集中拥有功能。
此外,您将为这些数据点提供分类。 虽然这些分类是用文本标记的,但大多数 SVM 实现都需要数字标签。
因此,您必须在训练前将这些标签转换为数字。 准备好数据集后,使用这些特征作为坐标,您就可以使用 SVM 模型对文本进行分类。
在 Python 中创建 SVM
要在 Python 中创建支持向量机 (SVM),您可以使用sklearn.svm库中的SVC类。 以下是如何使用SVC类在 Python 中构建 SVM 模型的示例:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) 在这个例子中,我们首先从sklearn.svm库中导入SVC类。 然后,我们加载数据集并将其拆分为训练集和测试集。
接下来,我们通过实例化SVC对象并将kernel参数指定为“线性”来创建 SVM 模型。 然后,我们使用fit方法在训练数据上训练模型,并使用score方法在测试数据上评估模型。 score方法返回模型的准确性,我们将其打印到控制台。
您还可以为SVC对象指定其他参数,例如控制正则化强度的C参数和控制某些内核的内核系数的gamma参数。
支持向量机的好处
以下列出了使用支持向量机 (SVM) 的一些好处:
- 高效:支持向量机的训练通常是高效的,尤其是当样本数量很大时。
- 对噪声具有鲁棒性:SVM 对训练数据中的噪声具有相对鲁棒性,因为它们试图找到最大边缘分类器,该分类器对噪声的敏感度低于其他分类器。
- 内存效率高: SVM 只需要训练数据的一个子集在任何给定时间都在内存中,这使得它们比其他算法更具内存效率。
- 在高维空间中有效:即使特征数量超过样本数量,SVM 仍然可以表现良好。
- 多功能性:支持向量机可用于分类和回归任务,可以处理各种类型的数据,包括线性和非线性数据。
现在,让我们探索一些学习支持向量机 (SVM) 的最佳资源。
学习资源
支持向量机简介
这本关于支持向量机介绍的书全面地、逐步地向你介绍了基于核的学习方法。
| 预习 | 产品 | 评分 | 价格 | |
|---|---|---|---|---|
 | 支持向量机和其他基于内核的学习方法简介 | 75.00 美元 | 在亚马逊上购买 |
它为您提供支持向量机理论的坚实基础。

支持向量机应用
第一本书侧重于支持向量机的理论,而这本关于支持向量机应用的书则侧重于它们的实际应用。
| 预习 | 产品 | 评分 | 价格 | |
|---|---|---|---|---|
 | 支持向量机应用 | 15.52 美元 | 在亚马逊上购买 |
它着眼于 SVM 如何用于图像处理、模式检测和计算机视觉。
支持向量机(信息科学与统计学)
这本关于支持向量机(信息科学与统计学)的书的目的是概述支持向量机 (SVM) 在各种应用中的有效性背后的原理。
| 预习 | 产品 | 评分 | 价格 | |
|---|---|---|---|---|
 | 支持向量机(信息科学与统计学) | 167.36 美元 | 在亚马逊上购买 |
作者强调了有助于 SVM 成功的几个因素,包括它们在有限数量的可调参数下表现良好的能力、它们对各种类型的错误和异常的抵抗力,以及与其他方法相比的高效计算性能。
学习内核
《Learning with Kernels》是一本向读者介绍支持向量机(SVM)和相关核技术的书籍。
| 预习 | 产品 | 评分 | 价格 | |
|---|---|---|---|---|
 | 使用内核学习:支持向量机、正则化、优化等(自适应…… | $80.00 | 在亚马逊上购买 |
它旨在让读者对数学有一个基本的了解,以及他们开始在机器学习中使用核算法所需的知识。 本书旨在提供对 SVM 和内核方法的全面且易于理解的介绍。
使用 Sci-kit Learn 支持向量机
这个由 Coursera 项目网络提供的带有 Sci-kit Learn 的在线支持向量机课程教授如何使用流行的机器学习库 Sci-Kit Learn 实现 SVM 模型。

此外,您还将学习 SVM 背后的理论并确定它们的优势和局限性。 该课程是初级水平,需要大约 2.5 小时。
Python 中的支持向量机:概念和代码
这个由 Udemy 提供的关于 Python 支持向量机的付费在线课程有长达 6 小时的视频教学,并附带认证。

它涵盖了 SVM 以及如何在 Python 中可靠地实现它们。 此外,它还涵盖了支持向量机的商业应用。
机器学习和人工智能:Python 中的支持向量机
在本机器学习和人工智能课程中,您将学习如何将支持向量机 (SVM) 用于各种实际应用,包括图像识别、垃圾邮件检测、医学诊断和回归分析。

您将使用 Python 编程语言为这些应用程序实施 ML 模型。
最后的话
在本文中,我们简要了解了支持向量机背后的理论。 我们了解了它们在机器学习和自然语言处理中的应用。
我们还看到了它使用scikit-learn的实现是什么样子的。 此外,我们还谈到了支持向量机的实际应用和优势。
虽然本文只是介绍,但其他资源建议进行更详细的介绍,详细解释支持向量机。 鉴于它们的通用性和高效性,SVM 值得理解以成长为数据科学家和 ML 工程师。
接下来,您可以查看顶级机器学习模型。