
如何创建 Pandas DataFrame [含示例]
已发表: 2022-12-08学习使用 pandas DataFrames 的基础知识:pandas 中的基本数据结构,一个强大的数据操作库。
如果您想开始使用 Python 进行数据分析,pandas 是您应该首先学习使用的库之一。 从从 CSV 文件和数据库等多个来源导入数据,到处理丢失的数据并对其进行分析以获得洞察力——pandas 可以让您完成上述所有操作。
要开始使用 pandas 分析数据,您应该了解 pandas 中的基本数据结构:数据框。
在本教程中,您将学习 pandas 数据框的基础知识和创建数据框的常用方法。 然后,您将学习如何从数据框中选择行和列以检索数据子集。
对于所有这些以及更多内容,让我们开始吧。
安装和导入 Pandas
pandas是第三方数据分析库,需要先安装。 建议在项目的虚拟环境中安装外部包。
如果你使用 Python 的 Anaconda 发行版,你可以使用conda进行包管理。
conda install pandas您还可以使用 pip 安装 pandas:
pip install pandaspandas 库需要 NumPy 作为依赖项。 因此,如果尚未安装 NumPy,它也会在安装过程中安装。
安装 pandas 后,您可以将其导入到您的工作环境中。 通常,pandas 是在别名pd下导入的:
import pandas as pdPandas 中的 DataFrame 是什么?

pandas 的基本数据结构是数据框。 数据框是带有标签索引和命名列的二维数据数组。 数据框中的每一列称为 pandas series ,共享一个公共索引。
这是我们将在接下来的几分钟内从头开始创建的示例数据框。 此数据框包含有关六个学生在四个星期内花费多少的数据。

学生的名字是行标签。 这些列被命名为“Week1”到“Week4”。 请注意,所有列共享同一组行标签,也称为索引。
如何创建 Pandas 数据框
有几种方法可以创建 pandas 数据框。 在本教程中,我们将讨论以下方法:
- 从 NumPy 数组创建数据框
- 从 Python 字典创建数据框
- 通过读取 CSV 文件创建数据框
来自 NumPy 数组
让我们从 NumPy 数组创建一个数据框。
让我们创建形状为 (6,4) 的数据数组,假设在任何给定的一周内,每个学生的花费都在 0 美元到 100 美元之间。 NumPy 的random模块中的randint()函数返回给定区间[low,high)中的随机整数数组。
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) 要创建 pandas 数据框,您可以使用DataFrame构造函数并将 NumPy 数组作为data参数传入,如下所示:
students_df = pd.DataFrame(data=data) 现在我们可以调用内置的type()函数来检查students_df的类型。 我们看到它是一个DataFrame对象。
type(students_df) # pandas.core.frame.DataFrame print(students_df) 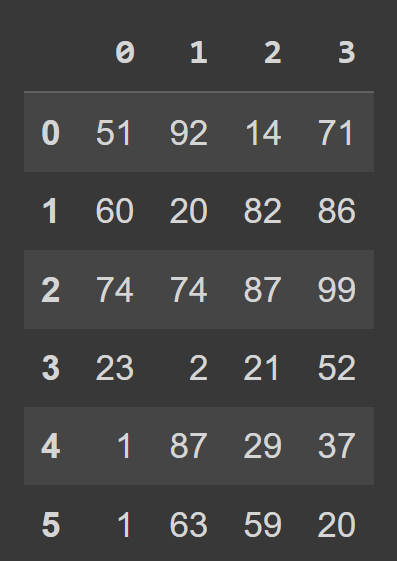
我们看到默认情况下,我们有从 0 到numRows – 1 的范围索引,列标签为 0、1、2、...、 numCols -1。 但是,这会降低可读性。 它将有助于向数据框添加描述性列名和行标签。
让我们创建两个列表:一个用于存储学生姓名,另一个用于存储列标签。
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] 在调用DataFrame的构造函数时,可以将index和columns分别设置为行标签和列标签的列表来使用。
students_df = pd.DataFrame(data = data,index = students,columns = cols) 我们现在有了带有描述性行和列标签的students_df数据框。
print(students_df) 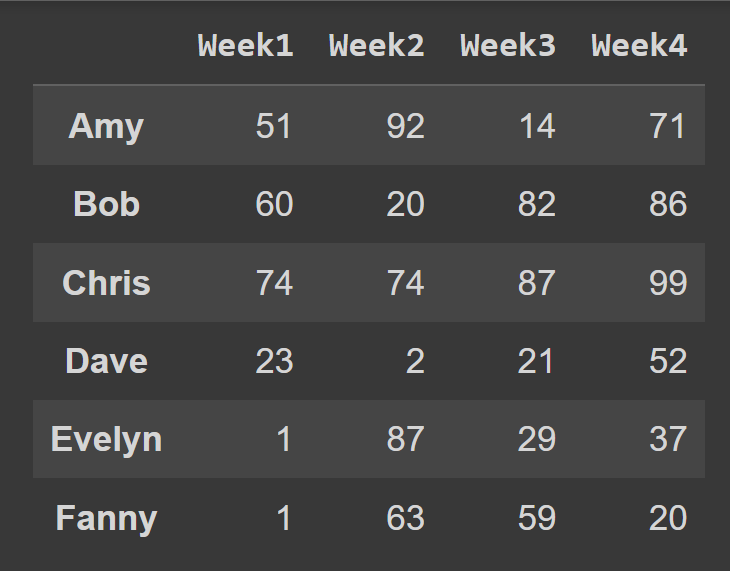
要获取有关数据框的一些基本信息,例如缺失值和数据类型,您可以在数据框对象上调用info()方法。
students_df.info() 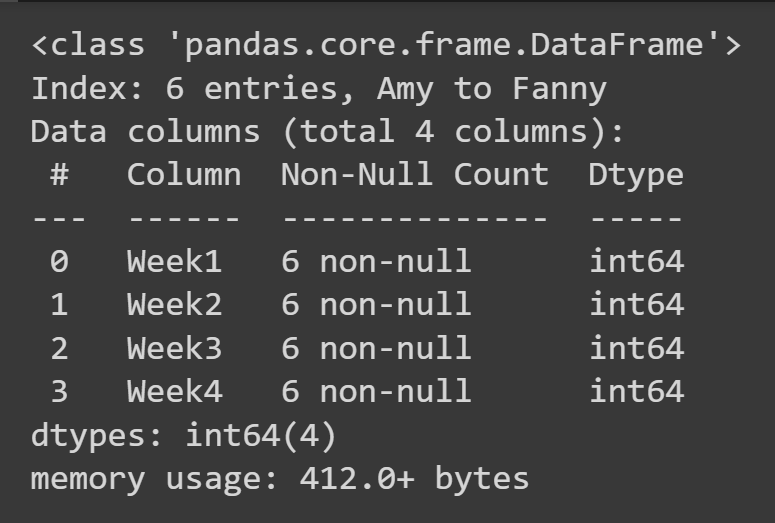
来自 Python 字典
您还可以从 Python 字典创建 pandas 数据框。
这里, data_dict是包含学生数据的字典:
- 学生的名字是关键。
- 每个值都是每个学生从第一周到第四周花费的列表。
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data 要从 Python 字典创建数据框,请使用from_dict ,如下所示。 第一个参数对应于包含数据的字典 ( data_dict )。 默认情况下,键用作数据框的列名。 因为我们想将键设置为行标签,所以设置orient= 'index' 。
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 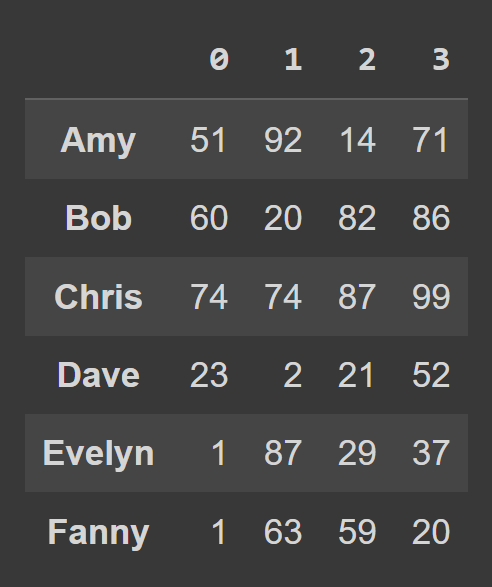
要将列名更改为周数,我们将列设置为cols列表:

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 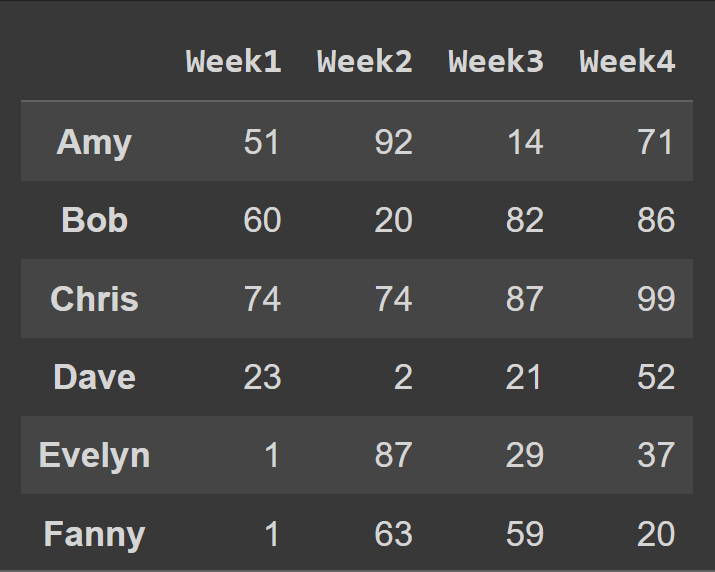
将 CSV 文件读入 Pandas DataFrame
假设学生数据是可用的 CSV 文件。 您可以使用read_csv()函数将文件中的数据读入到 pandas 数据框中。 pd.read_csv('file-path')是通用语法,其中file-path是 CSV 文件的路径。 我们可以将names参数设置为要使用的列名列表。
students_df = pd.read_csv('/content/students.csv',names=cols)现在我们知道如何创建数据框,让我们学习如何选择行和列。
从 Pandas DataFrame 中选择列
您可以使用多种内置方法从数据框中选择行和列。 本教程将介绍从数据框中选择列、行以及行和列的最常用方法。
选择单列
要选择单个列,您可以使用df_name[col_name] ,其中col_name是表示列名称的字符串。
在这里,我们只选择“Week1”列。
week1_df = students_df['Week1'] print(week1_df) 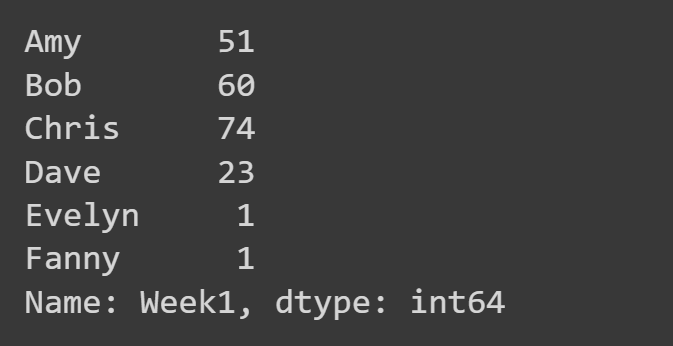
选择多列
要从数据框中选择多列,请传入要选择的所有列名称的列表。
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 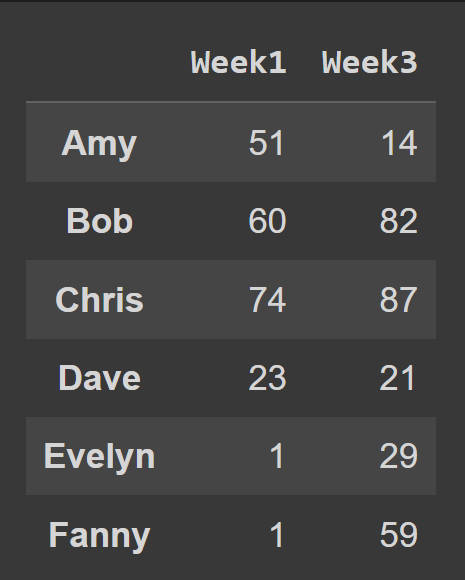
除了这个方法,你还可以使用iloc()和loc()方法来选择列。 稍后我们将编写一个示例。
从 Pandas DataFrame 中选择行

使用 .iloc() 方法
要使用iloc()方法选择行,请将与所有行对应的索引作为列表传入。
在此示例中,我们选择奇数索引处的行。
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 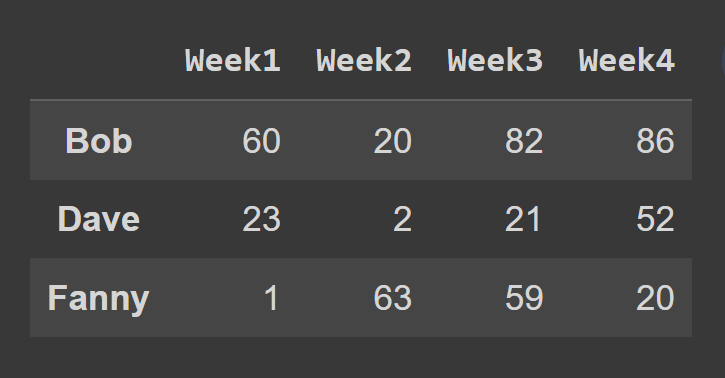
接下来,我们选择包含索引 0 到 2 处的行的数据框子集,默认情况下排除端点 3。
slice1 = students_df.iloc[0:3] print(slice1) 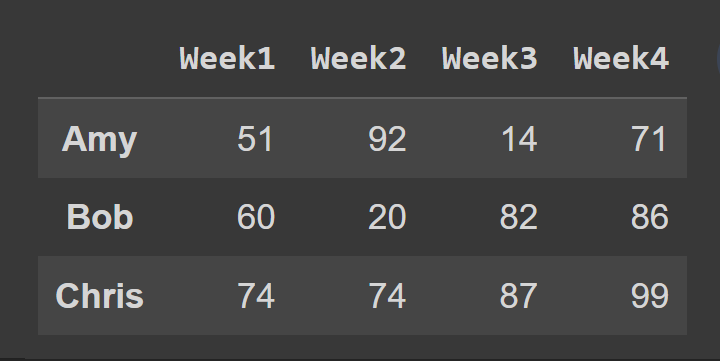
使用 .loc() 方法
要使用loc()方法选择数据框的行,您应该指定与您要选择的行相对应的标签。
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 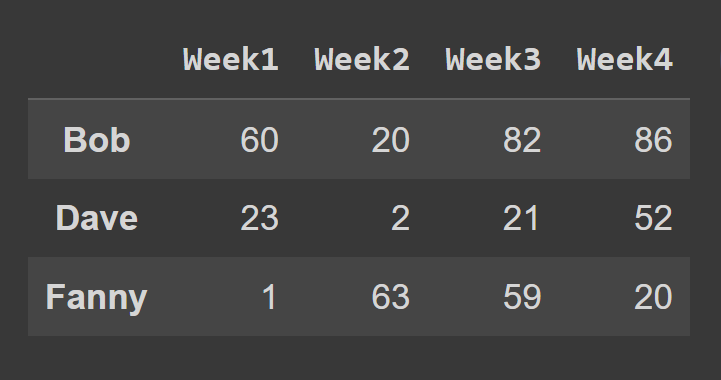
如果使用默认范围 0、1、2 到
numRows-1 对数据框的行进行索引,则使用iloc()和loc()都是等效的。
从 Pandas DataFrame 中选择行和列
到目前为止,您已经学习了如何从 pandas 数据框中选择行或列。 但是,您有时可能需要同时选择行和列的子集。 你是怎么做到的? 您可以使用我们讨论过的iloc()和loc()方法。
例如,在下面的代码片段中,我们选择索引 2 和 3 处的所有行和列。
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 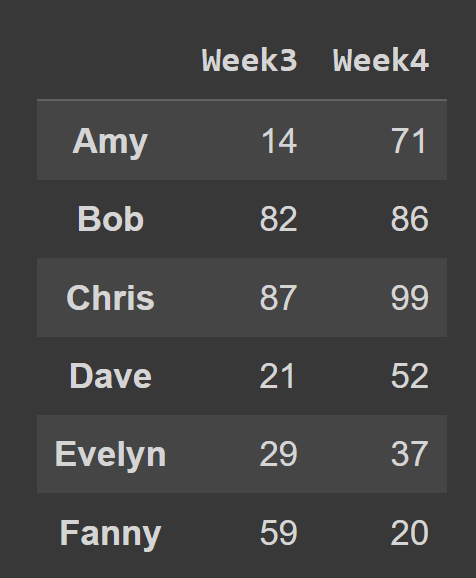
使用start:stop创建一个从start到但不包括stop的切片。 因此,当您同时忽略start和stop值时,当您忽略起始值和终止值时,切片会从开头开始——并延伸到数据框的结尾——选择所有行。
使用loc()方法时,您必须传入要选择的行和列的标签,如下所示:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 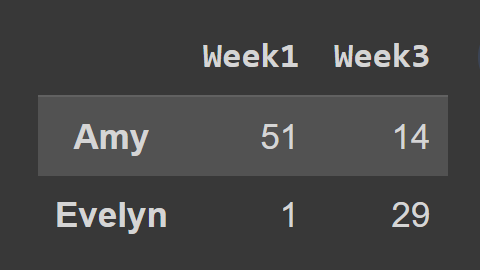
在这里,数据subset_df2包含 Amy 和 Evelyn 在第 1 周和第 3 周的记录。
结论
以下是您在本教程中所学内容的快速回顾:
- 安装 pandas 后,您可以在别名
pd下导入它。 要创建 pandas 数据框对象,可以使用pd.DataFrame(data)构造函数,其中data指的是 N 维数组或包含数据的可迭代对象。 您可以分别通过设置可选的索引和列参数来指定行和索引以及列标签。 - 使用
pd.read_csv(path-to-the-file)将文件的内容读取到数据框中。 - 您可以调用数据框对象的
info()方法来获取有关列、缺失值数量、数据类型和数据框大小的信息。 - 要选择单个列,请使用
df_name[col_name],并选择多个列,特定列,df_name[[col1,col2,...,coln]]。 - 您还可以使用
loc()和iloc()方法选择列和行。 -
iloc()方法接受要选择的行和列的索引(或索引切片),而loc()方法接受行和列标签。
您可以在此 Colab 笔记本中找到本教程中使用的示例。
接下来,查看协作数据科学笔记本列表。