
揭穿网站爬网、索引和 XML 站点地图背后的 3 个常见误区
已发表: 2018-03-07我们中的许多人错误地认为,启动配备 XML 站点地图的网站会自动获取其所有页面的抓取和索引。
在这方面,一些神话和误解逐渐形成。 最常见的是:
- 谷歌会自动抓取所有网站并且速度很快。
- 抓取网站时,Google 会跟踪所有链接并访问其所有页面,并立即将它们全部包含在索引中。
- 添加 XML 站点地图是让所有站点页面都被抓取和索引的最佳方式。
可悲的是,将您的网站纳入 Google 的索引是一项更复杂的任务。 继续阅读以更好地了解抓取和索引过程的工作原理,以及 XML 站点地图在其中扮演的角色。
在我们开始揭穿上述神话之前,让我们学习一些基本的 SEO 概念:
爬行是搜索引擎实现的一种活动,用于跟踪和收集来自整个 Web 的 URL。
索引是爬行之后的过程。 基本上,它是关于解析和存储稍后在为搜索引擎查询提供结果时使用的 Web 数据。 搜索引擎索引是存储所有收集到的 Web 数据以供进一步使用的地方。
抓取排名是 Google 分配给您的网站及其页面的值。 目前尚不清楚搜索引擎如何计算该指标。 谷歌多次确认索引频率与排名无关,因此网站排名权威与其抓取排名没有直接关系。
新闻网站、内容有价值的网站以及定期更新的网站更有可能被定期抓取。
抓取预算是搜索引擎分配给网站的抓取资源的数量。 通常,Google 会根据您的网站 Crawl Rank 计算此金额。
爬网深度是谷歌在浏览网站时向下钻取的程度。
抓取优先级是分配给网站页面的序号,表示其在抓取方面的重要性。
现在,了解了该过程的所有基础知识,让我们了解 XML 站点地图背后的 3 个神话,即爬取和索引编制破灭!
目录
- 误区 1. Google 会自动抓取所有网站,而且速度很快。
- 外卖
- 误区 2. 添加 XML 站点地图是让所有站点页面都被抓取和索引的最佳方式。
- 外卖
- 误区 3. XML 站点地图可以解决所有抓取和索引问题。
- 外卖
误区 1. Google 会自动抓取所有网站,而且速度很快。
谷歌声称,在收集网络数据方面,它是敏捷和灵活的。
但说实话,因为目前网络上有数以万亿计的页面,从技术上讲,搜索引擎无法快速抓取所有页面。
选择要为其分配抓取预算的网站
智能谷歌算法(又名抓取预算)分配搜索引擎资源并决定哪些网站值得抓取,哪些不值得抓取。
通常,Google 会优先考虑符合设定要求的可信网站,并作为定义其他网站如何衡量的基础。
因此,如果您有一个刚出炉的网站,或者一个内容被抓取、重复或稀薄的网站,那么它被正确抓取的机会非常小。
也可能影响分配抓取预算的重要因素是:
- 网站规模,
- 它的总体健康状况(这组指标取决于您在每个页面上可能出现的错误数量),
- 以及入站和内部链接的数量。
要增加获得抓取预算的机会,请确保您的网站满足上述所有 Google 要求,并优化其抓取效率(请参阅本文的下一部分)。
预测爬行时间表
Google 并未公布其抓取 Web URL 的计划。 此外,很难猜测搜索引擎访问某些网站的周期性。
可能对于一个站点,它可能每天至少执行一次爬网,而对于其他一些站点,每月访问一次甚至更少。
- 爬行的周期性取决于:
- 网站内容的质量,
- 网站提供的信息的新颖性和相关性,
- 以及搜索引擎认为网站 URL 的重要性或受欢迎程度。
考虑到这些因素,您可以尝试预测 Google 访问您网站的频率。
外部/内部链接和 XML 站点地图的作用
作为路径,Googlebots 使用链接将网站页面和网站相互连接起来。 因此,搜索引擎可以访问 Web 上存在的数万亿个相互关联的页面。
搜索引擎可以从任何页面开始扫描您的网站,而不必从主页开始。 爬行进入点的选择取决于入站链接的来源。 比如说,你的一些产品页面有很多来自不同网站的链接。 谷歌连接这些点并在第一轮访问这些受欢迎的页面。
XML 站点地图是构建经过深思熟虑的站点结构的绝佳工具。 此外,它还可以使网站爬取过程更具针对性和智能化。
基本上,站点地图是包含所有站点链接的枢纽。 包含在其中的每个链接都可以配备一些额外的信息:最后更新日期、更新频率、它与站点上其他 URL 的关系等。
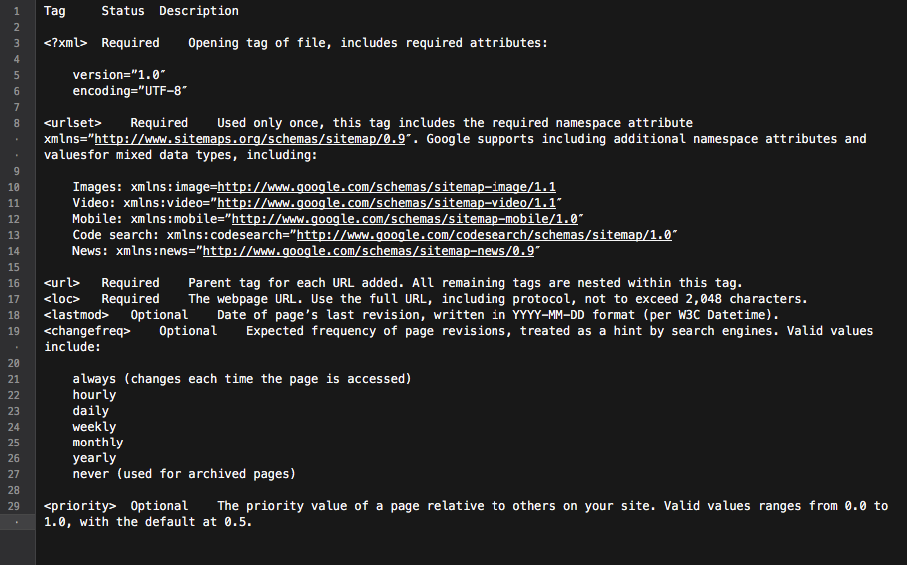 所有这些都为 Googlebots 提供了详细的网站抓取路线图,并使抓取更加知情。 此外,所有主要搜索引擎都会优先考虑站点地图中列出的 URL。
所有这些都为 Googlebots 提供了详细的网站抓取路线图,并使抓取更加知情。 此外,所有主要搜索引擎都会优先考虑站点地图中列出的 URL。
总而言之,要让您的网站页面出现在 Googlebot 的雷达上,您需要建立一个内容丰富的网站并优化其内部链接结构。
外卖
• Google 不会自动抓取您的所有网站。
• 网站爬取的周期取决于网站及其页面的重要性或受欢迎程度。
• 更新内容使 Google 更频繁地访问网站。
• 不符合搜索引擎要求的网站不太可能被正确抓取。
• 没有内部/外部链接的网站和网站页面通常会被搜索引擎机器人忽略。
• 添加 XML 站点地图可以改进网站爬取过程并使其更加智能。
误区 2. 添加 XML 站点地图是让所有站点页面都被抓取和索引的最佳方式。
每个网站所有者都希望 Googlebot 访问所有重要的网站页面(除了那些隐藏在索引中的页面),并立即探索新的和更新的内容。
但是,搜索引擎对网站抓取优先级有自己的看法。
在检查网站及其内容时,Google 使用一组称为抓取预算的算法。 基本上,它允许搜索引擎扫描网站页面,同时精明地使用自己的资源。
检查网站抓取预算
很容易弄清楚您的网站是如何被抓取的,以及您是否有任何抓取预算问题。
你只需要:
- 计算您网站和 XML 站点地图中的页面数,
- 访问 Google Search Console,跳转到 Crawl -> Crawl Stats 部分,查看每天在您的网站上抓取多少页面,
- 将您的网站页面总数除以每天抓取的页面数。
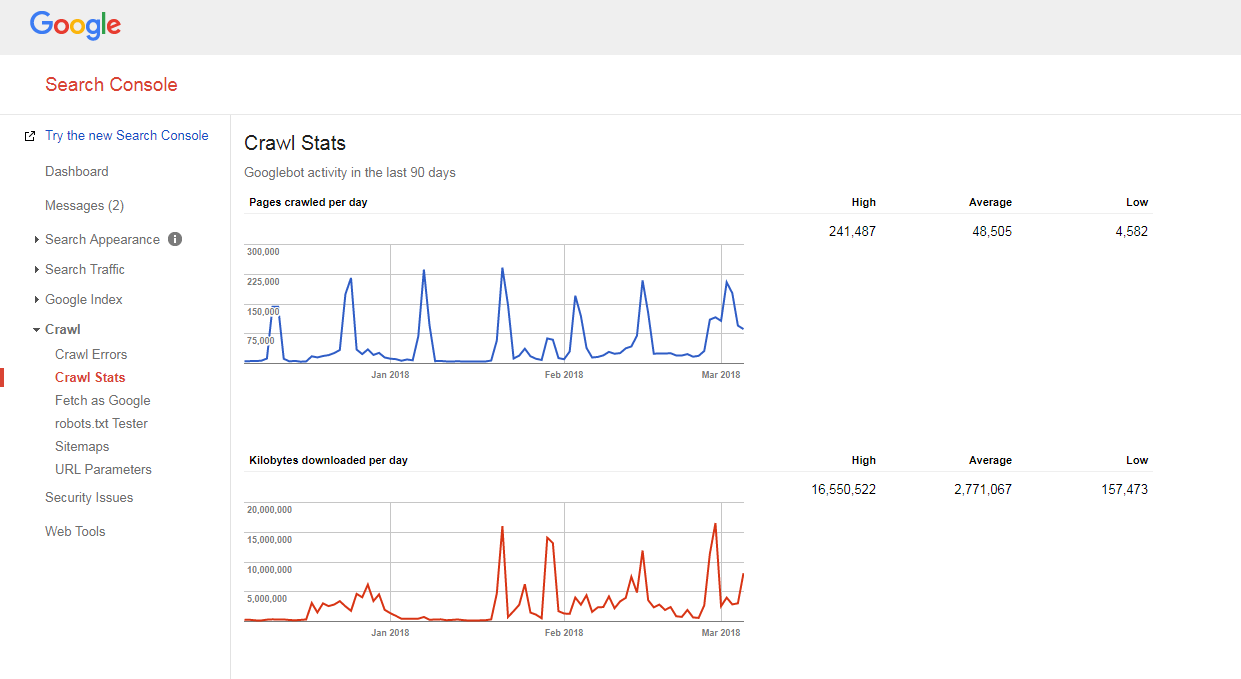 如果您获得的数量大于 10(您网站上的网页数量是 Google 每天抓取的网页数量的 10 倍),我们有一个坏消息要告诉您:您的网站存在抓取问题。
如果您获得的数量大于 10(您网站上的网页数量是 Google 每天抓取的网页数量的 10 倍),我们有一个坏消息要告诉您:您的网站存在抓取问题。
但是在学习如何修复它们之前,您需要了解另一个概念,即……
爬行深度
爬取深度是谷歌不断探索网站到一定程度的程度。
通常,主页被认为是 1 级,点击 1 次的页面是 2 级,依此类推。
深层页面的 Pagerank 较低(或根本没有),并且不太可能被 Googlebot 抓取。 通常,搜索引擎的挖掘深度不会超过 4 级。
在理想情况下,特定页面应该距离主页或主要站点类别 1-4 次点击。 该页面的路径越长,搜索引擎需要分配的资源就越多。
如果在一个网站上,谷歌估计路径太长,它会停止进一步的抓取。
优化爬网深度和预算

为防止 Googlebot 变慢,优化您的网站抓取预算和深度,您需要:
- 修复所有404、JS等页面错误;
过多的页面错误会显着降低 Google 爬虫的速度。 要查找所有主要站点错误,请登录您的 Google(Bing、Yandex)网站管理员工具面板并按照此处给出的所有说明进行操作。
- 优化分页;
如果您的分页列表太长,或者您的分页方案不允许点击列表中的几个页面,搜索引擎爬虫可能会停止挖掘这么多页面。
此外,如果每个此类页面的项目很少,则可以将其视为内容稀薄的页面,并且不会被爬取。
- 检查导航过滤器;
一些导航方案可能带有多个生成新页面的过滤器(例如,通过分层导航过滤的页面)。 尽管此类页面可能具有自然流量潜力,但它们也可能在搜索引擎爬虫上产生不必要的负载。
解决此问题的最佳方法是将系统链接限制到过滤列表。 理想情况下,您应该最多使用 1-2 个过滤器。 例如,如果您的商店有 3 个 LN 过滤器(颜色/尺寸/性别),您应该只允许系统地组合 2 个过滤器(例如,颜色-尺寸、性别-尺寸)。 如果您需要添加更多过滤器的组合,您应该手动添加它们的链接。
- 优化 URL 中的跟踪参数;
各种 URL 跟踪参数(例如 '?source=thispage')可以为爬虫创建陷阱,因为它们会生成大量新 URL。 此问题通常出现在具有“类似产品”或“相关故事”块的页面中,其中这些参数用于跟踪用户的行为。
在这种情况下,为了优化爬取效率,建议在 URL 末尾添加“#”后面的跟踪信息。 这样,这样的 URL 将保持不变。 此外,还可以将带有跟踪参数的 URL 重定向到相同的 URL,但不进行跟踪。
- 删除过多的 301 重定向;
比如说,你有一大块链接到的 URL 没有尾部斜杠。 当搜索引擎机器人访问此类页面时,它会被重定向到带有斜杠的版本。
因此,机器人必须做两倍于它应该做的事情,最终它可以放弃并停止爬行。 为避免这种情况,只要在更改 URL 时尝试更新站点内的所有链接。
抓取优先级
如上所述,谷歌优先抓取网站。 所以难怪它对爬网网站中的页面做同样的事情。
对于大多数网站来说,爬取优先级最高的页面是首页。
但是,如前所述,在某些情况下,这也可能是最受欢迎的类别或访问量最大的产品页面。 要查找 Googlebot 抓取次数较多的网页,只需查看您的服务器日志即可。
尽管 Google 并未正式宣布可能影响网站页面抓取优先级的因素有:
- 包含在 XML 站点地图中(并为最重要的页面添加优先级标签*),
- 入站链接的数量,
- 内部链接的数量,
- 页面受欢迎程度(访问次数),
- 网页排名。
但是,即使您已经为搜索引擎机器人抓取您的网站扫清了道路,他们仍然可能会忽略它。 继续阅读以了解原因。
为了更好地了解抓取优先级,请观看 Gary Illyes 的这个虚拟主题演讲。
谈到 XML 站点地图中的优先级标签,它们可以手动添加,也可以借助站点所基于的平台的内置功能添加。 此外,一些平台支持简化流程的第三方 XML 站点地图扩展/应用程序。
使用 XML 站点地图优先级标记,您可以将以下值分配给不同类别的站点页面:
- 0.0-0.3 到实用页面、过时的内容和任何次要的页面,
- 0.4-0.7 到您的博客文章、常见问题解答和知识页面、次要的类别和子类别页面,以及
- 0.8-1.0 到您的主要网站类别、关键登录页面和主页。
外卖
• Google 对抓取过程的优先级有自己的看法。
• 应该进入搜索引擎索引的页面应该距离主页、主要站点类别或最受欢迎的站点页面 1-4 次点击。
• 为防止Googlebot 变慢并优化您的网站抓取预算和抓取深度,您应该查找并修复404、JS 和其他页面错误,优化网站分页和导航过滤器,去除过多的301 重定向并优化URL 中的跟踪参数。
• 为了提高重要站点页面的抓取优先级,确保它们包含在 XML 站点地图中(带有优先级标签)并与其他站点页面良好链接,具有来自其他相关和权威网站的链接。
误区 3. XML 站点地图可以解决所有抓取和索引问题。
XML 站点地图虽然是一种很好的通信工具,可以提醒 Google 您的站点 URL 和访问它们的方式,但不能保证您的站点会被搜索引擎机器人访问(更不用说将所有站点页面包含到索引中) .
此外,您应该了解站点地图不会帮助您提高网站排名。 即使一个页面被抓取并包含在搜索引擎索引中,它的排名性能也取决于大量其他因素(内部和外部链接、内容、网站质量等)。
但是,如果使用得当,XML 站点地图可以显着提高您的站点抓取效率。 以下是有关如何最大限度地发挥该工具的 SEO 潜力的一些建议。
始终如一
创建站点地图时,请记住它将用作 Google 爬虫的路线图。 因此,重要的是不要通过提供错误的方向来误导搜索引擎。
例如,您可能偶尔会在您的 XML 站点地图中包含一些实用程序页面(联系我们或 TOS 页面、登录页面、恢复丢失的密码页面、共享内容页面等)。
这些页面通常使用 noindex robots 元标记从索引中隐藏或在 robots.txt 文件中被禁止。
因此,将它们包含在 XML 站点地图中只会混淆 Googlebot,这可能会对收集有关您网站的信息的过程产生负面影响。
定期更新
Web 上的大多数网站几乎每天都在变化。 尤其是电子商务网站,其产品和类别经常在网站内外进行洗牌。
为了让 Google 消息灵通,您需要使您的 XML 站点地图保持最新。
某些平台(Magento、Shopify)要么具有允许您定期更新 XML 站点地图的内置功能,要么支持一些能够执行此任务的第三方解决方案。
例如,在 Magento 2 中,您可以设置站点地图更新周期的周期性。 当您在平台的配置设置中定义它时,您会向爬虫发出信号,告知您的网站页面会以特定时间间隔(每小时、每周、每月)更新,并且您的网站需要再次抓取。
单击此处了解更多信息。
但请记住,虽然设置站点地图更新的优先级和频率会有所帮助,但它们可能无法赶上真正的变化,有时也无法提供真实的画面。
这就是为什么要确保您的站点地图反映了最近所做的所有更改。
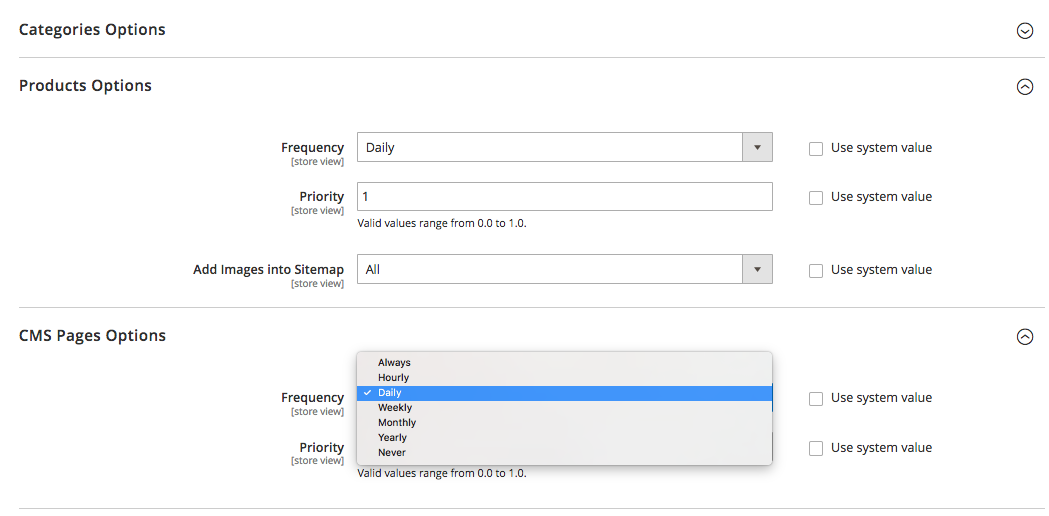 细分网站内容并设置正确的抓取优先级
细分网站内容并设置正确的抓取优先级
谷歌正在努力衡量网站的整体质量,只展示最好和最相关的网站。
但正如经常发生的那样,并非所有网站都是平等的并且能够提供真正的价值。
比如说,一个网站可能有 1000 个页面,其中只有 50 个是“A”级。 其他的要么纯粹是功能性的,要么有过时的内容,要么根本没有内容。
如果谷歌开始探索这样一个网站,它可能会认为它是非常垃圾,因为低价值、垃圾邮件或过时页面的比例很高。
这就是为什么在创建 XML 站点地图时,建议对网站内容进行分段并将搜索引擎机器人仅引导到有价值的站点区域。
您可能还记得,分配给 XML 站点地图中最重要站点页面的优先级标签也可以提供很大帮助。
外卖
• 创建站点地图时,请确保您不包含使用 noindex robots 元标记或在 robots.txt 文件中被禁止的页面隐藏在索引中的页面。
• 更改网站结构和内容后立即更新 XML 站点地图(手动或自动)。
• 细分您的网站内容,以在站点地图中仅包含“A”级页面。
• 设置不同页面类型的抓取优先级。
基本上就是这样。
对这个话题有话要说吗? 请随时在下面的评论部分分享您对抓取、索引或站点地图的看法。