
充分利用 Apache Solr:搜索索引的技术探索
已发表: 2023-02-21搜索功能通过允许用户轻松快速地找到他们正在寻找的内容来增强网站的用户体验。 对于大型网站、电子商务网站和具有动态内容的网站(新闻网站、博客)更是如此。
Apache Solr 是各种规模的网站使用的最流行的搜索平台之一。 它是一个基于 Java 的开源搜索引擎,可让您搜索大量数据,如文章、产品、客户评论等。 在本文中深入了解 Apache Solr。
查看本文以了解如何在 Drupal 中配置 Apache Solr

为什么 Apache Solr 如此受欢迎?
Apache Solr 快速灵活,允许全文搜索、命中突出显示(突出显示匹配的搜索词)、分面搜索(更精细的搜索)、实时索引(允许立即索引新内容)、动态集群(将搜索结果组织成组)、数据库集成、NoSQL 功能(非关系数据库)和丰富的文档处理(索引各种文档格式,如 PDF、MS Office、Open Office)。
关于 Apache Solr 的一些值得了解的事实:
- 它最初由 CNET 网络公司开发。 作为他们网站和文章的搜索引擎。 后来开源了,成为Apache的顶级项目。
- 支持多种编程语言,如 PHP、Java、Python 和 Ruby。 它还为这些语言提供 API。
- 具有对地理空间搜索的内置支持,允许根据其位置搜索内容。 特别适用于房地产网站、旅游网站等网站。
- 通过 API 和插件支持高级搜索功能,例如拼写检查、自动完成和自定义搜索。
- 使用 Lucene 进行索引和搜索。
什么是Lucene
Apache Lucene 是一个开源 Java 搜索库,可让您轻松地向应用程序添加搜索或信息检索。 它用途广泛、功能强大、准确,并且采用高效的搜索算法。
尽管 Lucene 以其全文搜索功能而闻名,但它也可用于文档分类、数据分析和信息检索。 它还支持英语以外的许多语言,如德语、法语、西班牙语、中文、日语等。
什么是索引?
所有搜索引擎都以索引开始。 索引是将原始数据处理成高效的交叉引用查找以促进快速搜索。
搜索引擎不直接索引数据。 文本首先被分解为标记(原子元素)。 搜索是查询搜索索引并检索与查询匹配的文档的过程。
索引的优点
- 快速准确的信息检索(收集、解析和存储)
- 没有索引,搜索引擎需要更多时间来扫描每个文档
索引流程
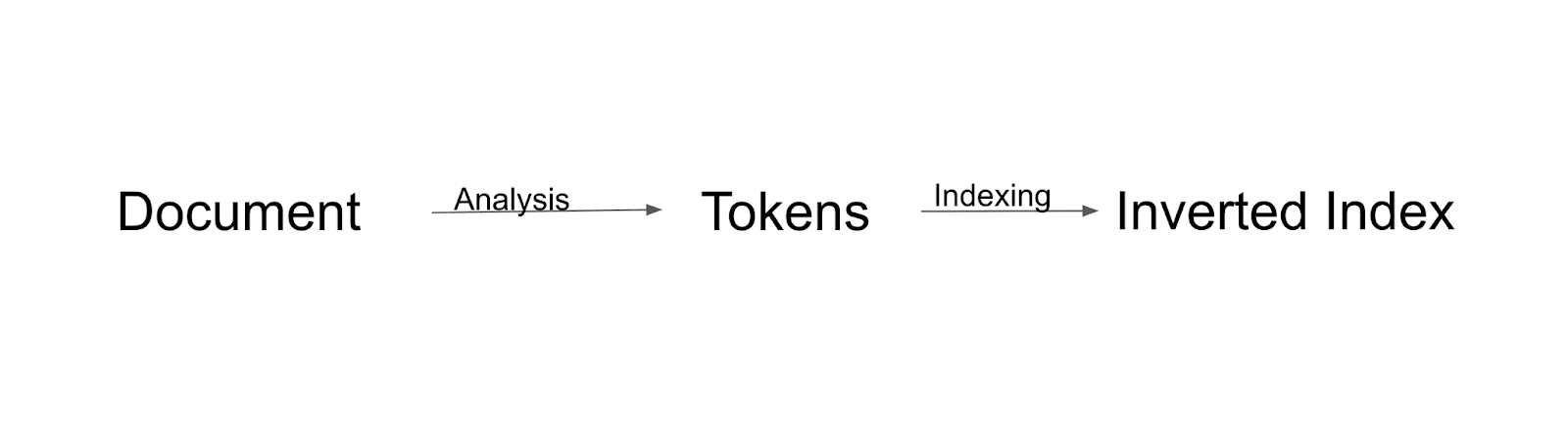
首先,文档将被分析并拆分为标记。 所有这些标记都将被索引到倒排索引。 倒排索引是 Solr 建立索引的一种方式。
倒排索引的工作原理
假设我们有 3 个文档:
- 我爱巧克力(D 1)
- 我点了巧克力蛋糕(D 2)
- 我准备了大香草蛋糕(D 3)
它的标记化方式如下表第 2 列所示。

“巧克力”在 D1 和 D2 有售
“蛋糕”在 D2 和 D3 中可用
“大”在 D3 中可用
“订购”在 D2 中可用
“准备”在 D3 中可用
“香草”在 D3 中可用
你会注意到像“我”、“爱”这样的词没有被标记化。 这些称为停用词,Solr 不会对其编制索引或搜索。
因此,当有人搜索“巧克力蛋糕”一词时,引擎会查看索引。 它不是查找文档,而是首先查看索引以查看单词“Chocolate”和“Cake”属于哪些文档。 这使得仅获取特定文档变得更加容易和快速。 这称为倒排索引。
存储模式
Apache Solr 使用基于文档的存储模式,并将每条数据存储为集合中的单独文档。 这允许高效灵活地存储和检索数据。
在 Drupal 中,每个节点都被视为一个文档。 因此,当您将节点索引到 Apache Solr 时,它被视为文档。 每个文档可以包含多个字段。 Lucene 没有通用的全局模式。 这意味着您可以在 Apache Solr 中的每个文档中索引任何类型的字段。

如何安装 Apache Solr
- 首先,确保您的系统上安装了 Java。
- 接下来,让我们从这里安装 Solr:https://solr.apache.org/downloads.html
- 下载并解压缩 Solr。
- 在 Solr 文件夹上运行此命令。
◦ bin/solr -e 技术产品
这将创建一个用于演示的虚拟核心,它还将启动 Solr 服务器。
- 服务器启动后,转到浏览器并输入“http://localhost:8983/”。
- 确保使用虚拟核心成功安装了 Solr。
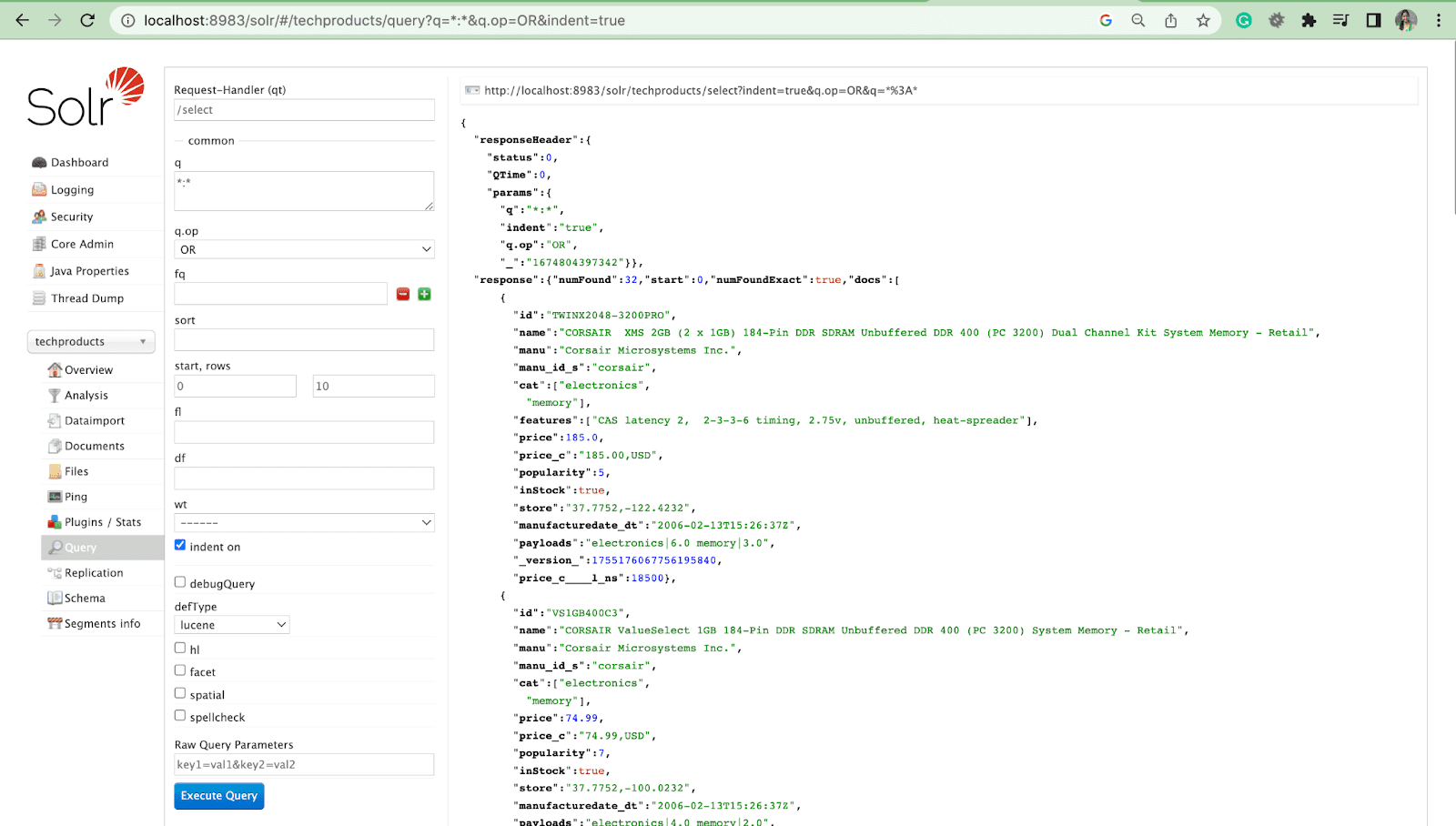
目录结构
安装 Solr 后,您将看到许多文件夹,例如:
Docs - 包含有关 Solr 的文档
Dist - Solr 主 .jar 文件
Contrib - 包含附加插件和 Solr 的特殊功能
Bin - Solr 的脚本
示例- 包含演示 solr 功能
服务器- Solr 的核心。 包含 Solr web 应用程序、日志、Solr 核心
配置文件
要创建核心,我们需要两个强制文件。
- 模式.xml
- Solr配置文件
模式.xml
- 它将包含您计划支持的字段类型以及应如何分析这些类型。
Solr配置文件
- 包含控制 Solr 核心行为的各种设置,如请求处理程序、请求调度程序、查询组件、更新处理程序等。
在 Solr 中查询
现在让我们看看如何在 Solr 管理 UI 中查询 Solr 结果。

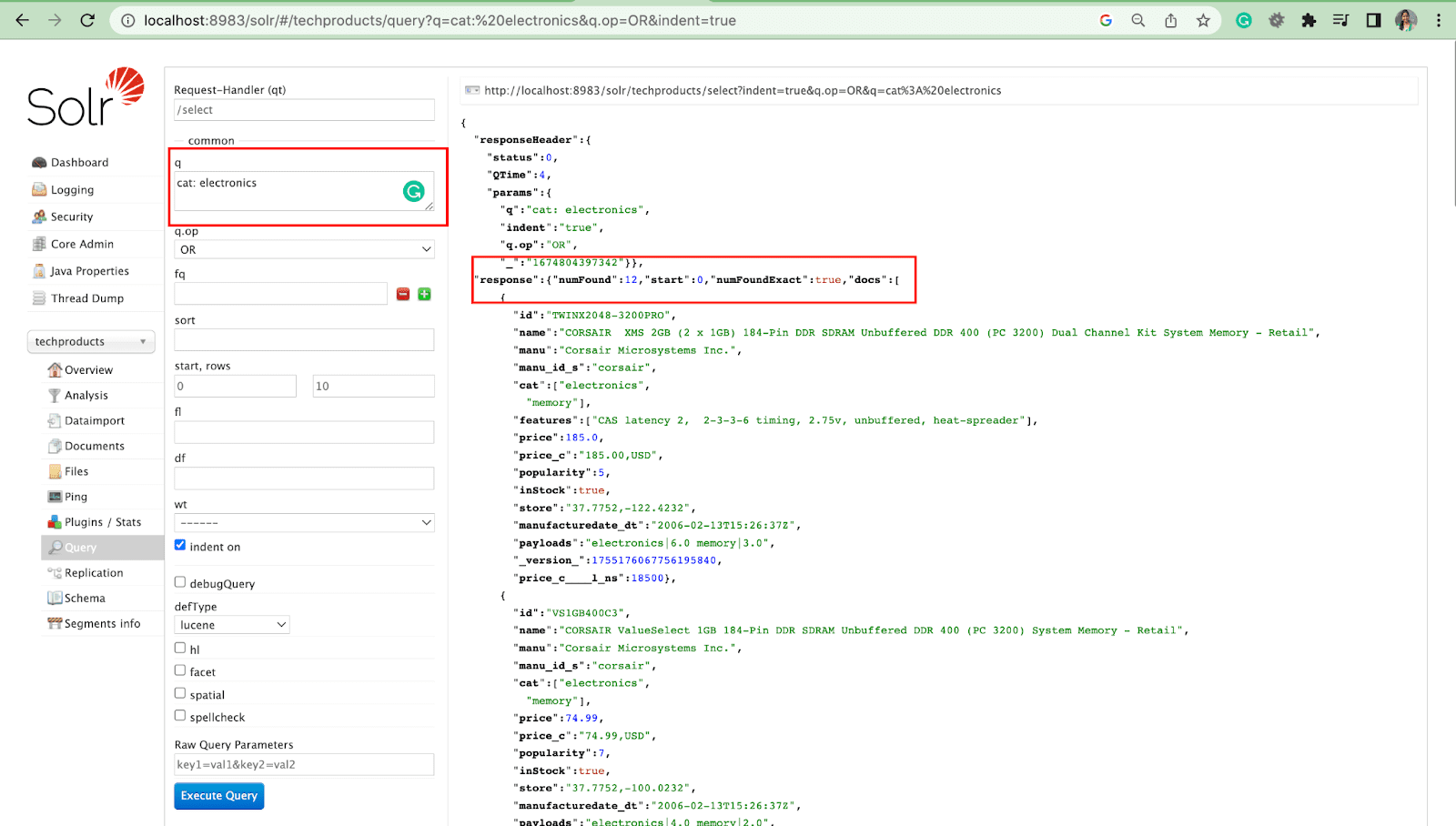
查询参数
- 本地参数是 Solr 请求中特定于查询参数的参数。
例如:猫:电子产品
带操作的查询参数
- 我们可以通过操作查询多个字段。
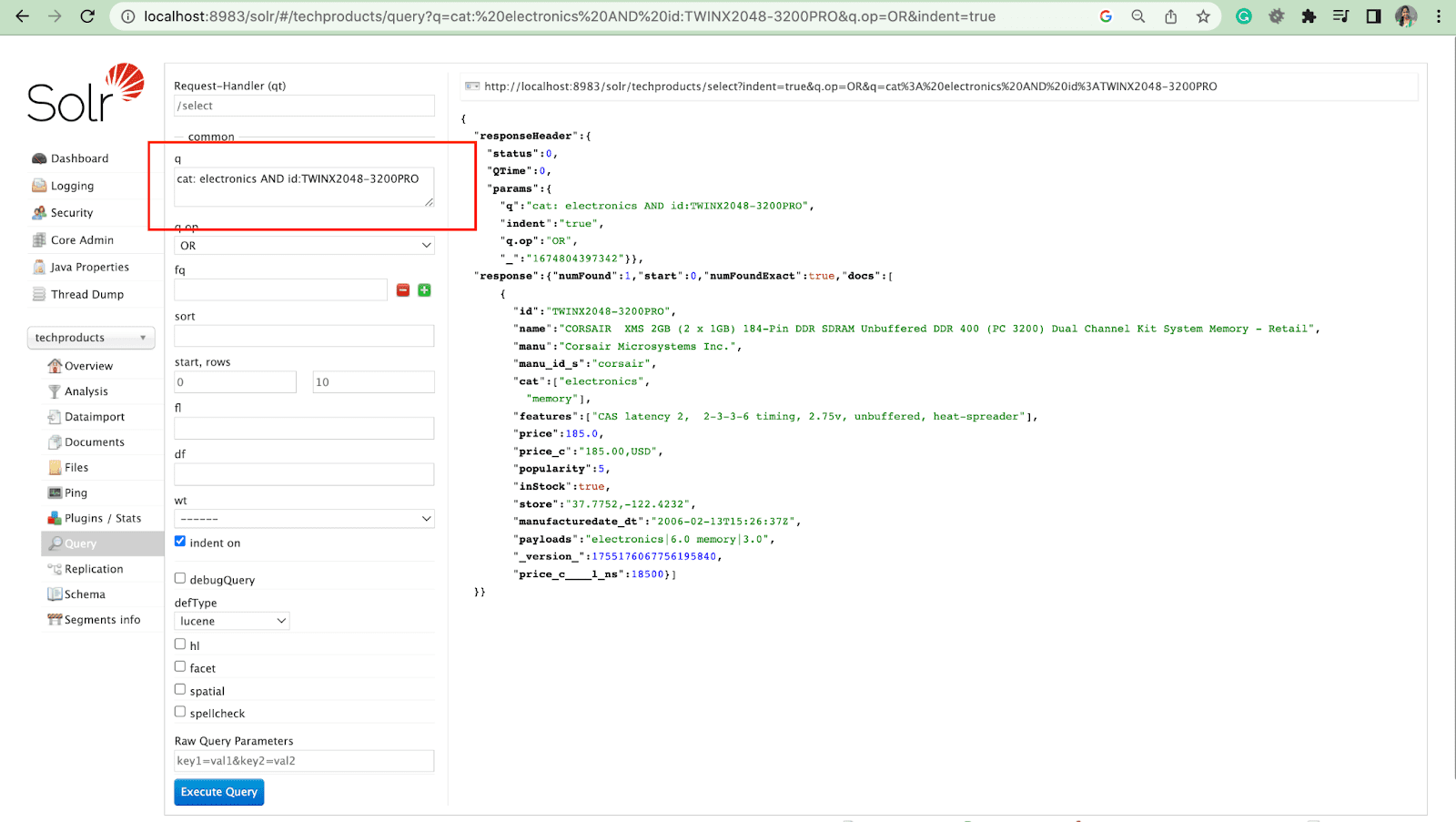
例如:cat: electronics id:TWINX2048-3200PRO with q.op AND
[或者]
cat: electronics 和 id:TWINX2048-3200PRO
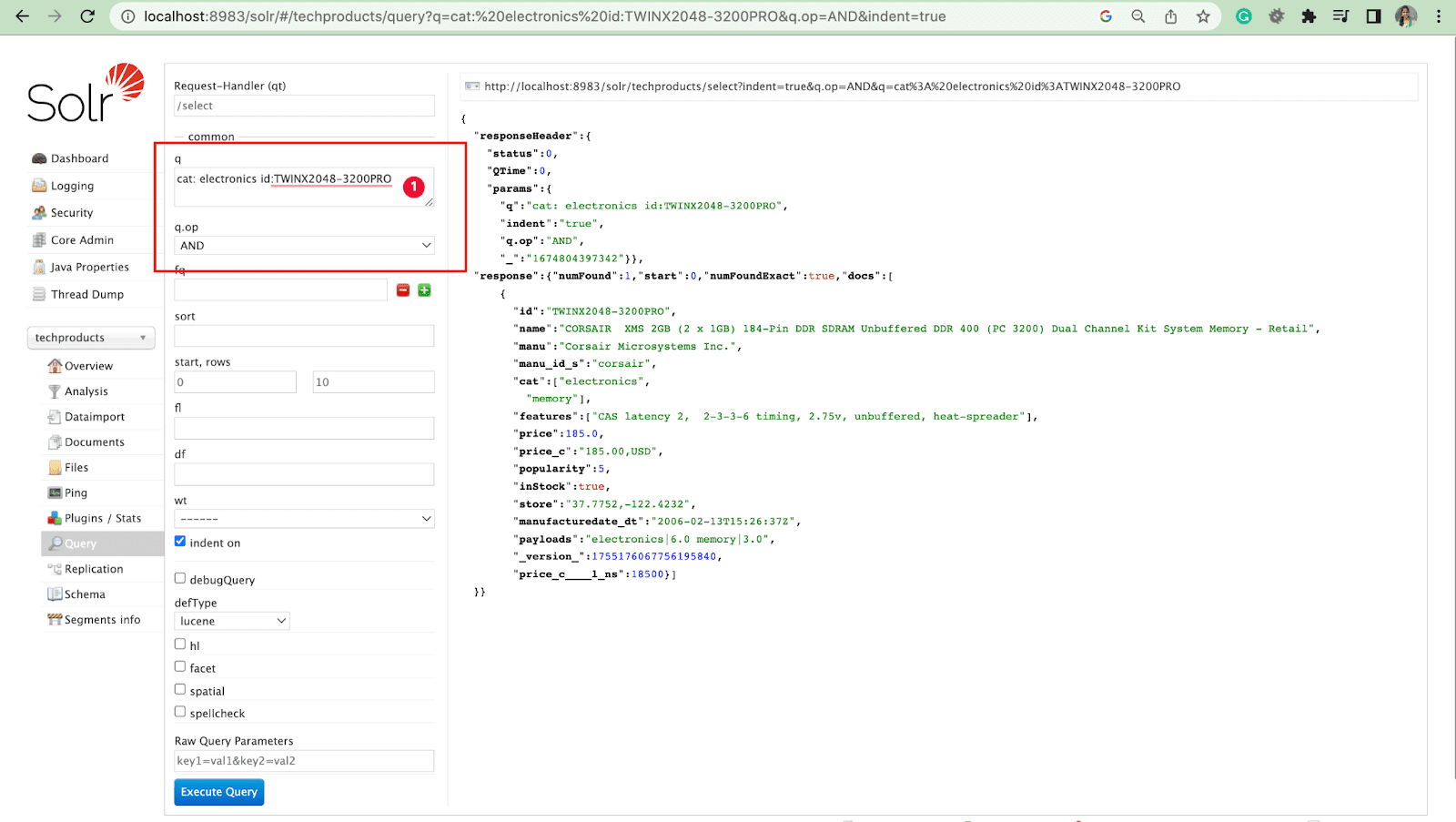
[或者]
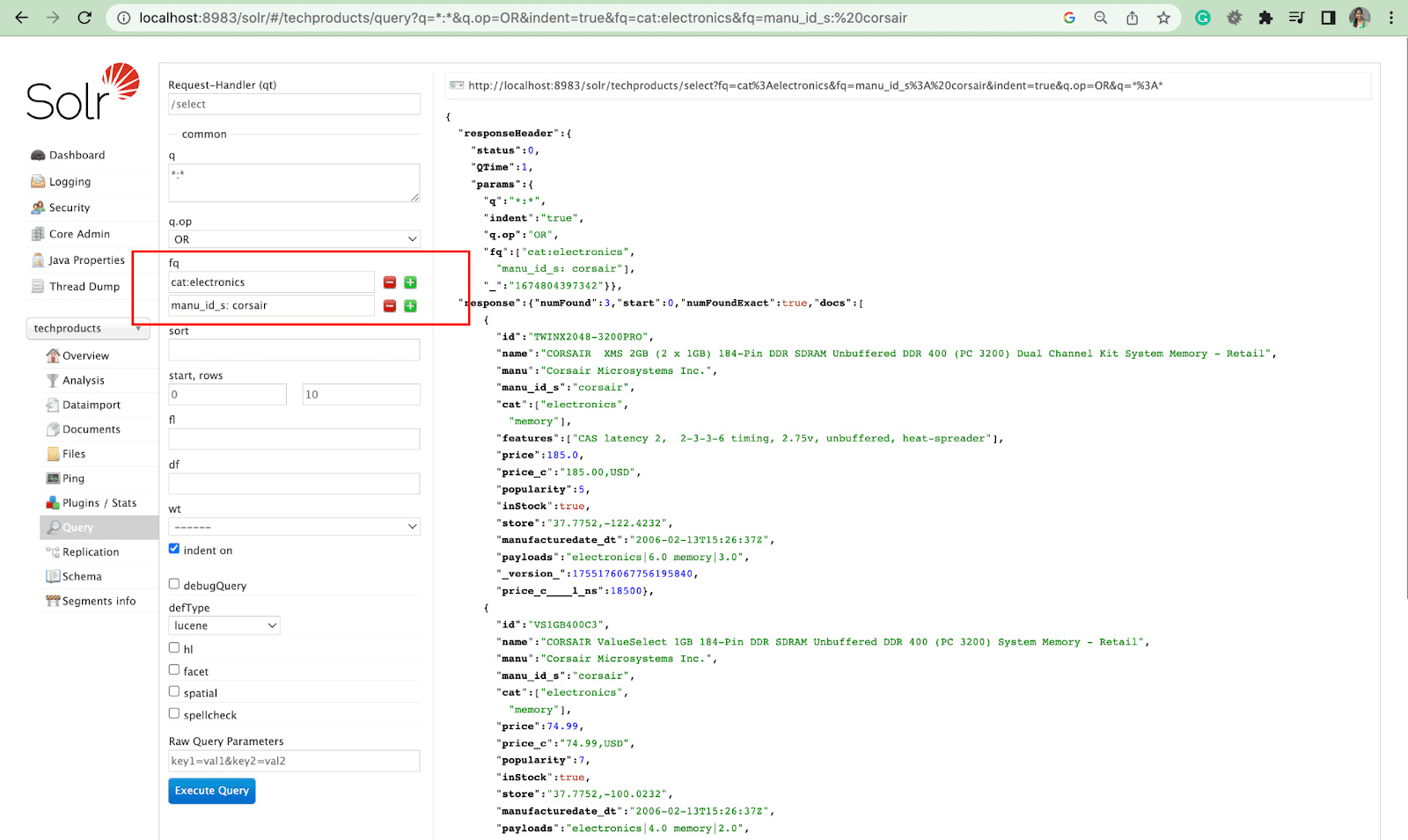
筛选查询
过滤器查询有助于缩小搜索结果的范围。 可以通过 fq 参数指定查询以限制在超集中返回哪些文档,而不影响分数。
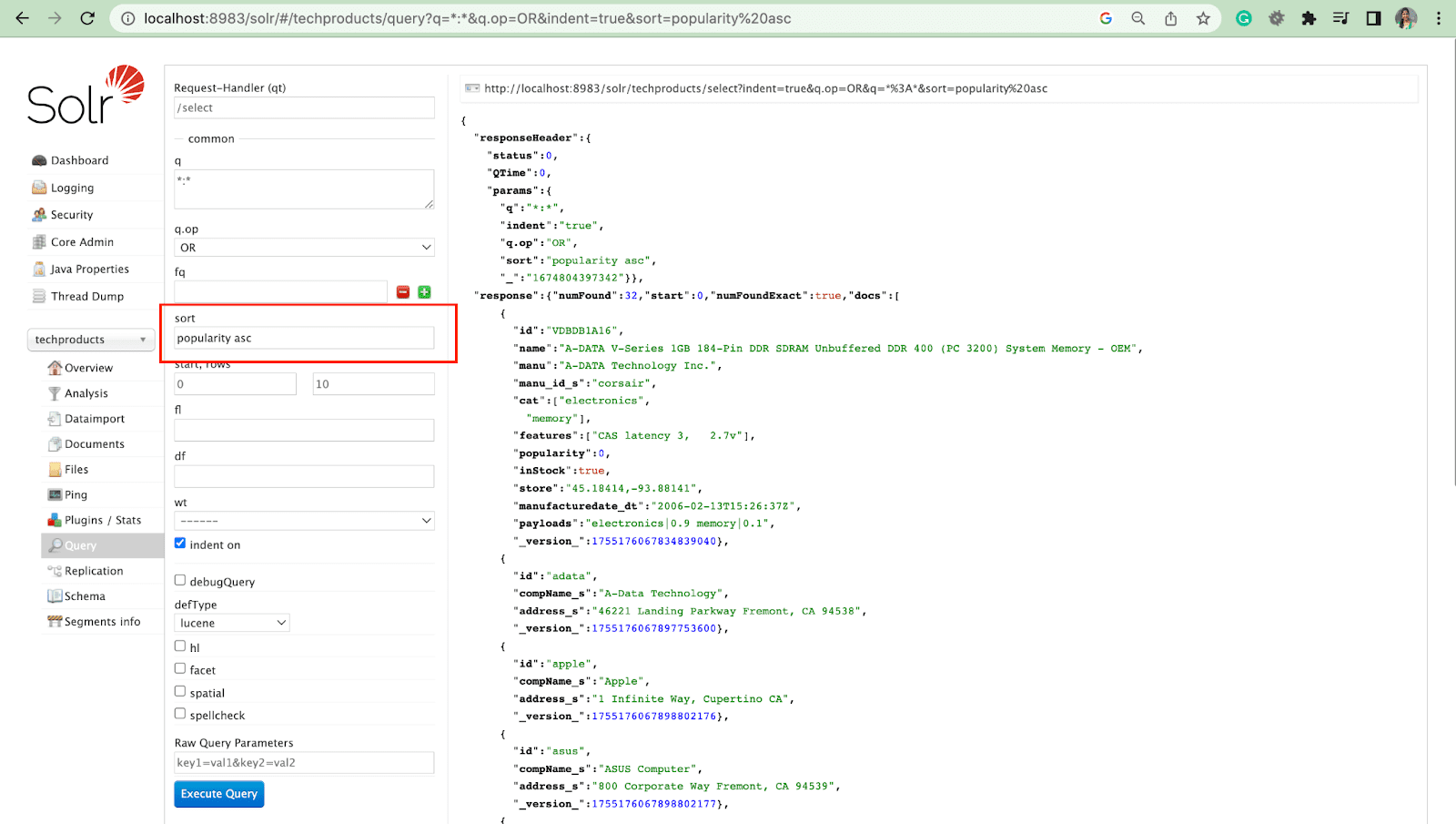
排序参数
sort 参数按升序 (asc) 或降序 (desc) 顺序排列搜索结果。 根据内容,参数可以按数字或字母顺序使用。
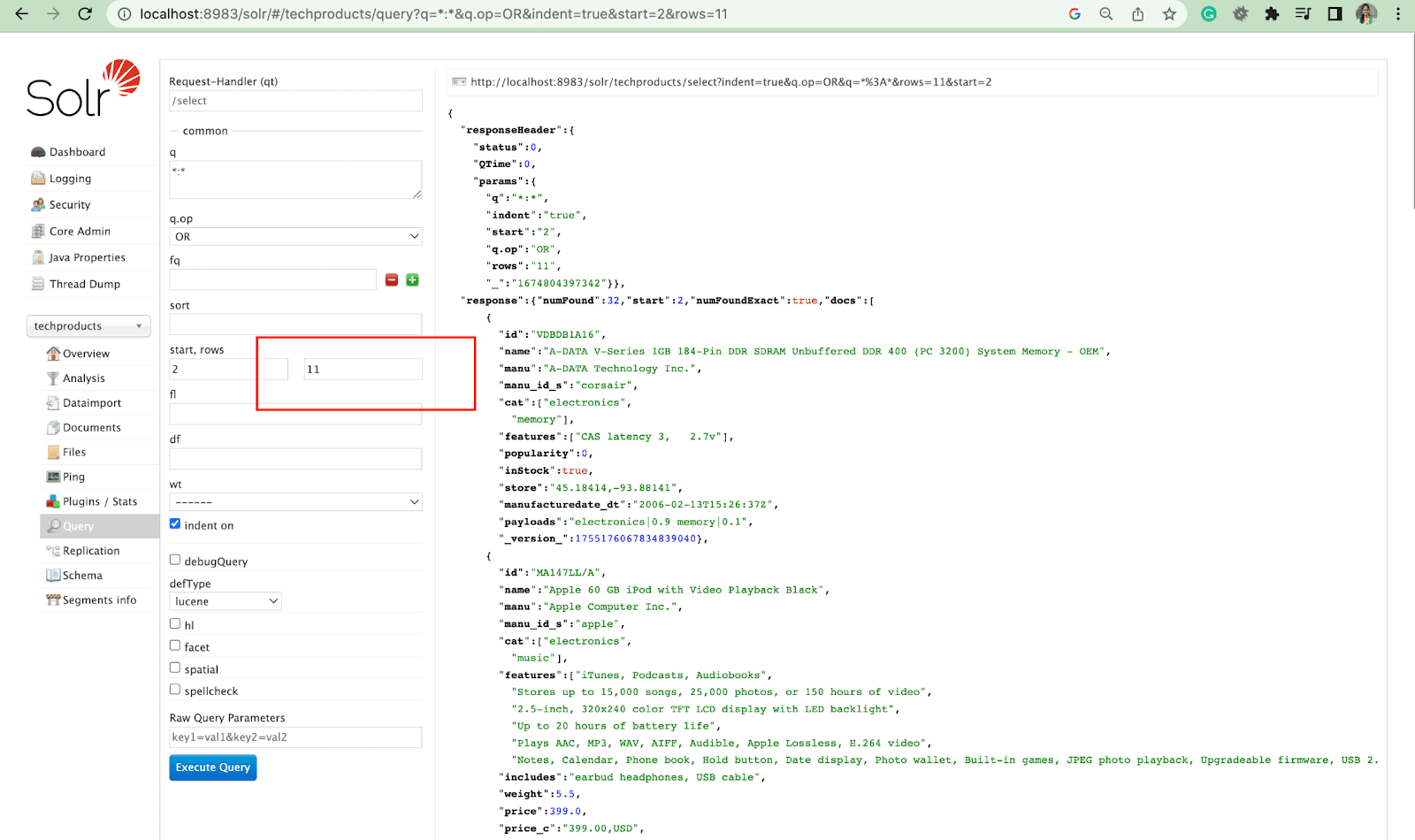
行参数
rows 参数允许您对查询结果进行分页。
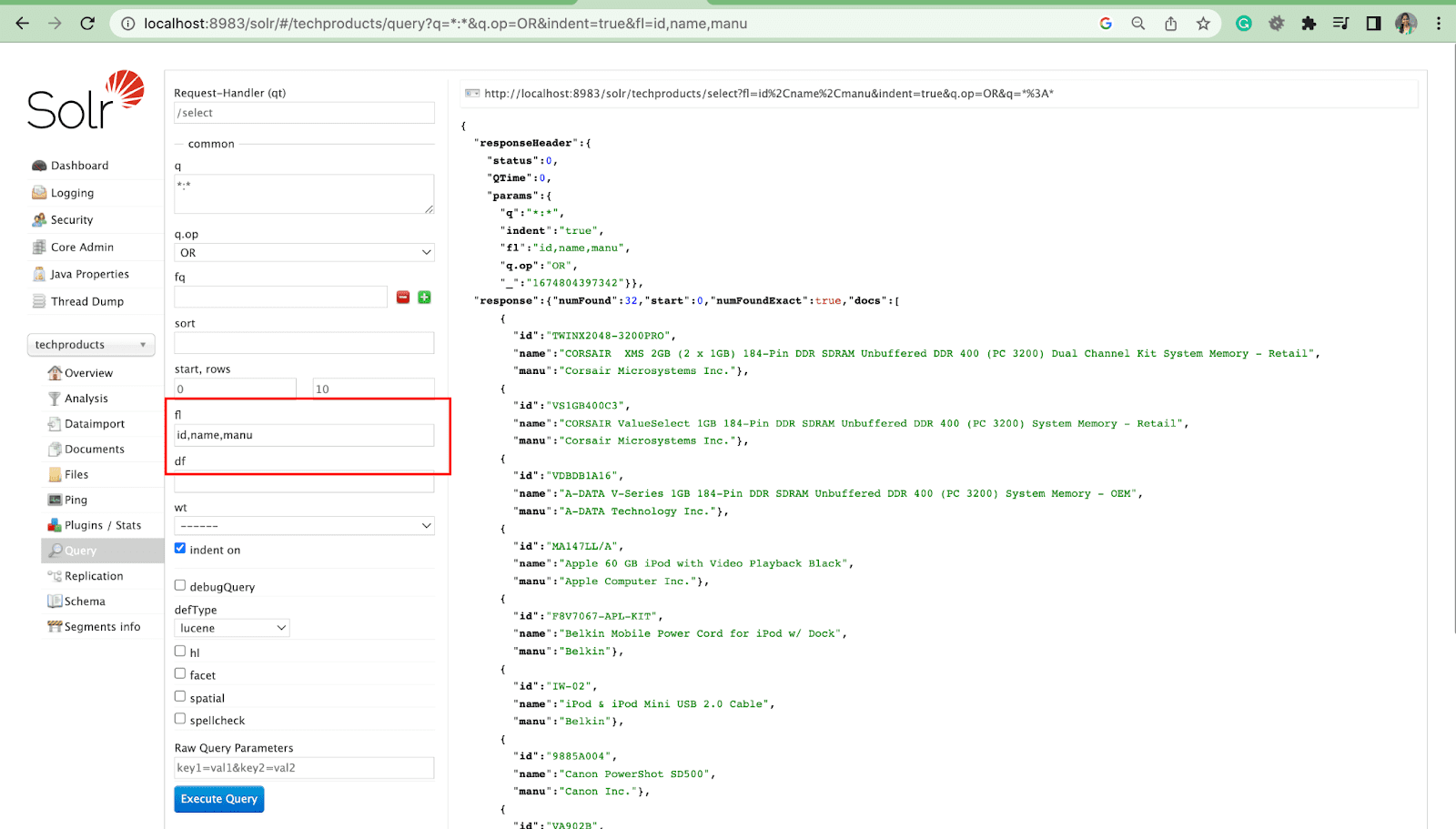
字段列表参数
fl 参数将查询响应中包含的信息限制为指定的字段列表。
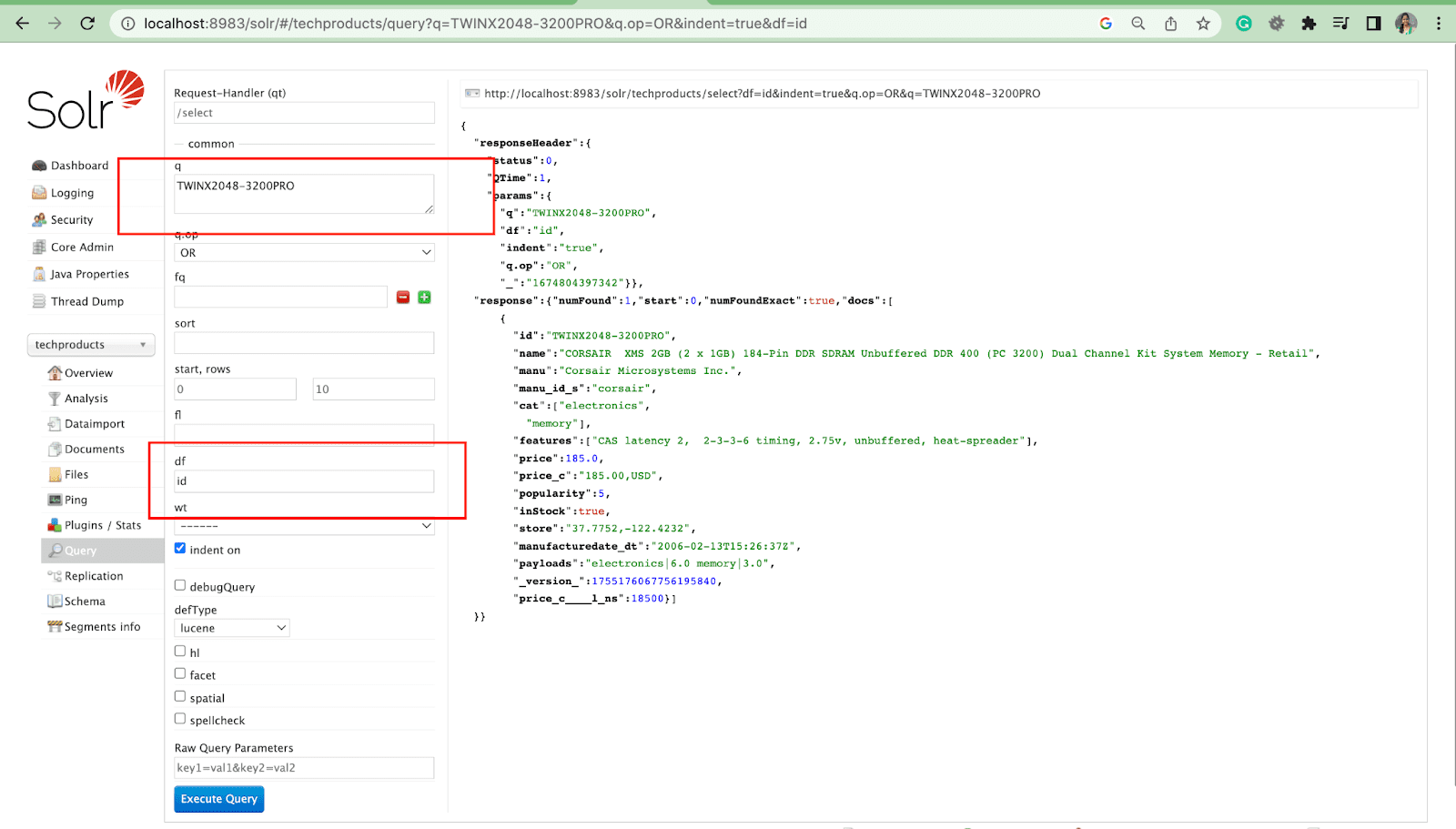
默认字段参数
默认字段参数是查询参数的默认字段。
亮点参数
Solr 中的突出显示功能可以包含与查询匹配的文档片段。
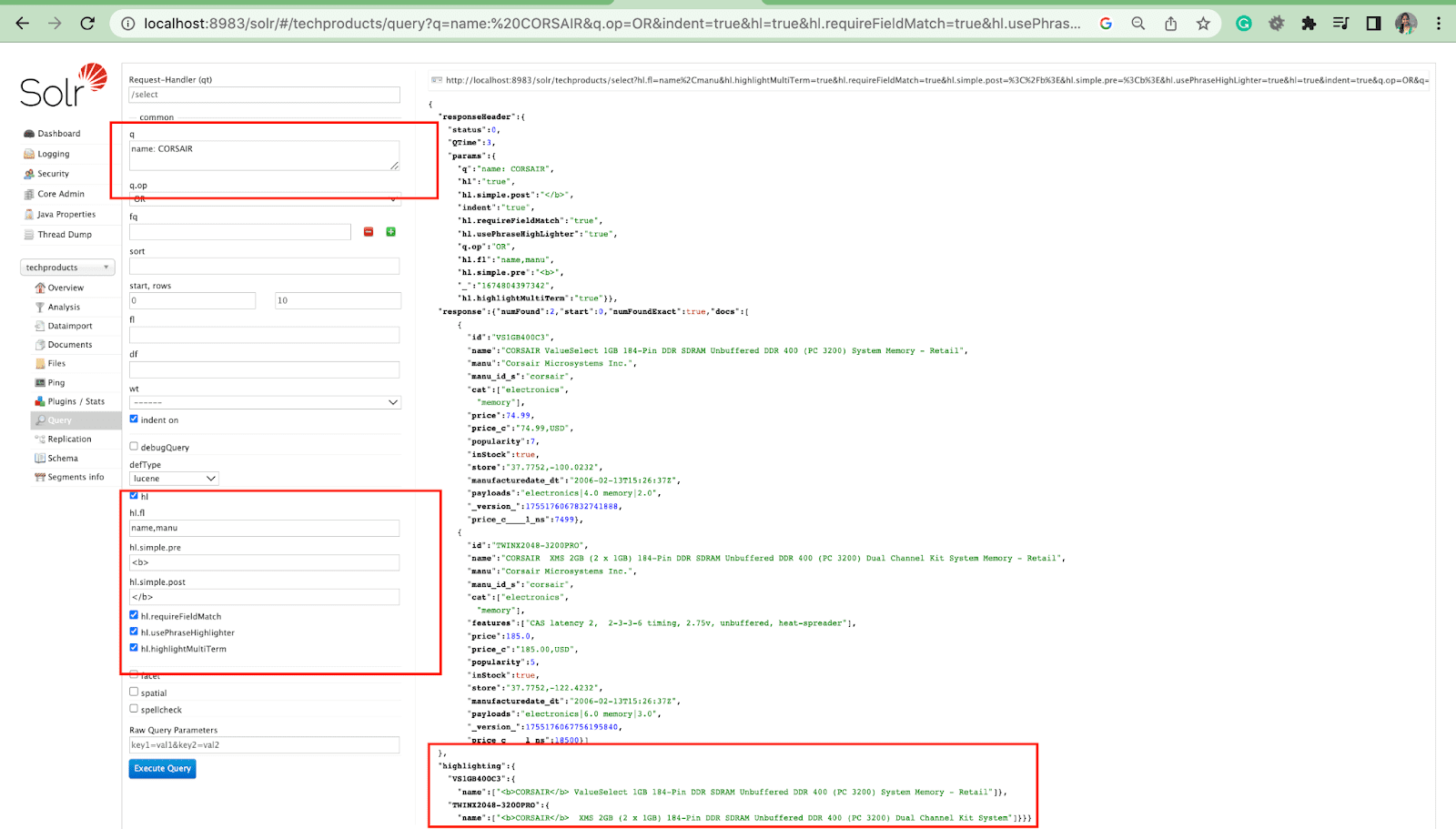
一些最常见的突出显示参数是:
- Hl.fl - 突出显示字段列表。
- Hl.simple.pre - 指定在突出显示的单词之前应使用哪个“标签”。
- Hl.simple.post - 指定在突出显示的术语后应使用哪个“标签”。
- hl.highlightMultiTerm - 如果设置为true ,Solr 将突出显示通配符查询。 如果为false ,它们将不会被突出显示。
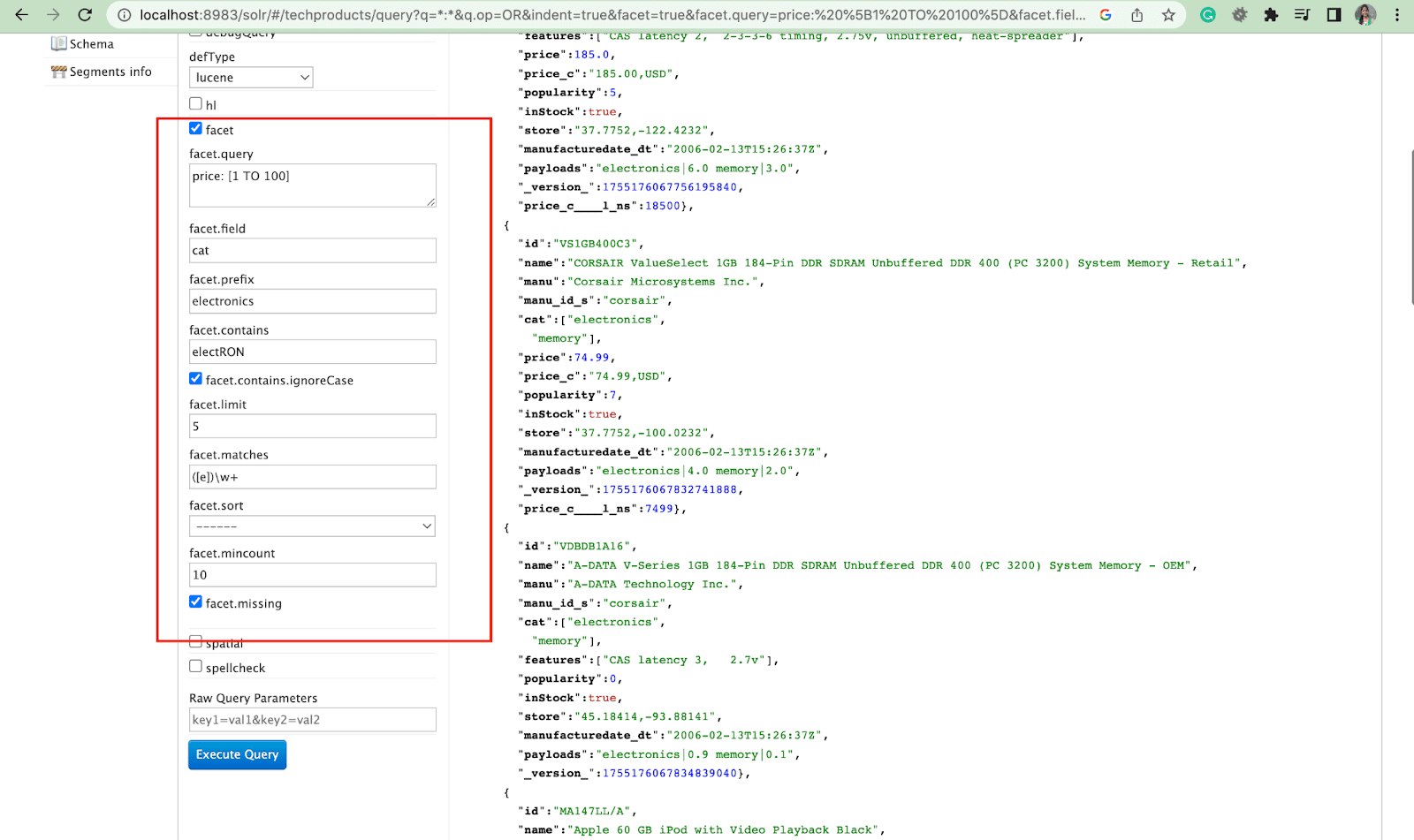
方面:
Facets 使用户能够探索和优化大量搜索结果。 它们在 UI 中显示为复选框、下拉列表或其他控件。 控制方面的两个一般参数是:
- 刻面参数
使用 facet 参数,用户可以根据其搜索索引中一个或多个字段的值生成分面。 在搜索结果中,可以配置 facet 参数来控制 facet 的生成和显示方式。
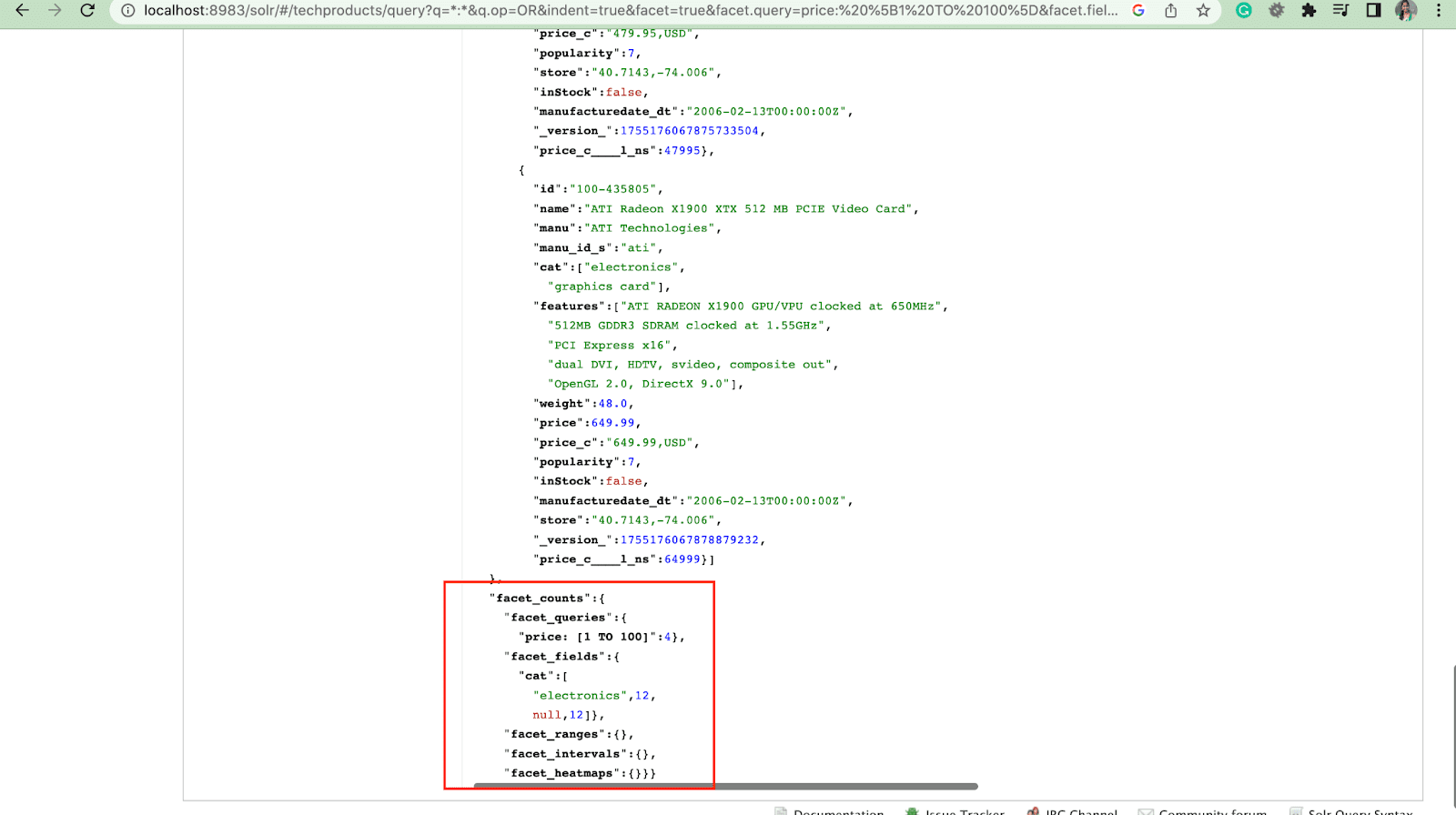
2. Facet.query参数
当用户在他们的 Solr 查询中包含 facet.query 参数时,Solr 将生成一个 facet 计数列表,该列表对应于索引中与每个查询匹配的文档数。 Facet.query 在您想要基于无法使用简单字段值轻松表示的复杂搜索条件生成构面时非常有用。
还有其他几个构面参数,如facet.field (指定应该用于生成构面的字段) 、 facet.limit (每个字段显示的最大构面数) 、 facet.mincount (生成构面所需的最小文档数)要包含在响应中的构面) , facet.sort (指定构面值应显示的顺序) 。
最后的想法
Apache Solr 是一个高度通用的搜索引擎,具有许多有趣的功能,可以根据您的要求进行定制。 Drupal 与 Apache Solr 配合得非常好。 如果您正在寻找 Drupal 专家来为您的新项目配置一个强大的搜索引擎,我们很乐意为您提供帮助!