
Anomali Tespiti: Ağ İzinsiz Girişlerini Önleme Rehberi
Yayınlanan: 2023-01-09Veriler, işletmelerin ve kuruluşların vazgeçilmez bir parçasıdır ve yalnızca doğru bir şekilde yapılandırıldığında ve verimli bir şekilde yönetildiğinde değerlidir.
Bir istatistiğe göre, bugün işletmelerin %95'i yapılandırılmamış verileri yönetmeyi ve yapılandırmayı sorun olarak görüyor.
Veri madenciliği burada devreye giriyor. Büyük yapılandırılmamış veri kümelerinden anlamlı kalıpları ve değerli bilgileri keşfetme, analiz etme ve çıkarma sürecidir.
Şirketler, müşterileri ve hedef kitle hakkında daha fazla bilgi edinmek ve satışları iyileştirmek ve maliyetleri azaltmak için iş ve pazarlama stratejileri geliştirmek üzere büyük veri yığınlarındaki kalıpları belirlemek için yazılım kullanır.
Bu faydanın yanı sıra dolandırıcılık ve anormallik tespiti veri madenciliğinin en önemli uygulamalarındandır.
Bu makalede, anormallik tespiti açıklanmakta ve veri güvenliğini sağlamak için veri ihlallerini ve ağ izinsiz girişlerini önlemeye nasıl yardımcı olabileceği araştırılmaktadır.
Anomali Tespiti ve Çeşitleri Nedir?

Veri madenciliği, birbirine bağlanan kalıpları, korelasyonları ve eğilimleri bulmayı içerirken, ağ içindeki anormallikleri veya aykırı veri noktalarını bulmanın harika bir yoludur.
Veri madenciliğinde anomaliler, veri kümesindeki diğer veri noktalarından farklı olan ve veri kümesinin normal davranış modelinden sapan veri noktalarıdır.
Anormallikler, aşağıdakiler de dahil olmak üzere farklı türlere ve kategorilere ayrılabilir:
- Olaylardaki Değişiklikler: Önceki normal davranıştan kaynaklanan ani veya sistematik değişiklikleri ifade eder.
- Aykırı Değerler: Veri toplamada sistematik olmayan bir şekilde ortaya çıkan küçük anormal kalıplar. Bunlar ayrıca küresel, bağlamsal ve toplu aykırı değerler olarak sınıflandırılabilir.
- Kaymalar: Veri setinde kademeli, yönsüz ve uzun vadeli değişiklik.
Bu nedenle, anormallik tespiti, hileli işlemleri tespit etmek, yüksek sınıf dengesizliği olan vaka çalışmalarını ele almak ve sağlam veri bilimi modelleri oluşturmak için hastalık tespiti için oldukça yararlı bir veri işleme tekniğidir.
Örneğin, bir şirket, dolandırıcılığı tespit etmek ve daha fazla araştırma yapmak için bilinmeyen bir banka hesabına yapılan anormal veya yinelenen işlemleri bulmak için nakit akışını analiz etmek isteyebilir.
Anormallik Tespitinin Faydaları
Kullanıcı davranışı anormallik tespiti, güvenlik sistemlerini güçlendirmeye yardımcı olur ve onları daha kesin ve doğru hale getirir.
Ağ içindeki tehditleri ve potansiyel riskleri belirlemek için güvenlik sistemlerinin sağladığı çeşitli bilgileri analiz eder ve anlamlandırır.
Anomali tespitinin şirketler için avantajları şunlardır:
- Yapay zeka (AI) algoritmaları olağandışı davranışları bulmak için sürekli olarak verilerinizi taradığından , siber güvenlik tehditlerinin ve veri ihlallerinin gerçek zamanlı tespiti .
- Anormal etkinliklerin ve kalıpların izlenmesini, manuel anormallik tespitinden daha hızlı ve daha kolay hale getirerek tehditleri çözmek için gereken emek ve zamanı azaltır.
- Ani performans düşüşleri gibi operasyonel hataları gerçekleşmeden önce belirleyerek operasyonel riskleri en aza indirir .
- Bir anormallik tespit sistemi olmadan şirketlerin potansiyel tehditleri tespit etmesi haftalar ve aylar alabileceğinden, anormallikleri hızlı bir şekilde tespit ederek büyük iş zararlarının ortadan kaldırılmasına yardımcı olur .
Bu nedenle, anormallik tespiti, büyüme fırsatlarını bulmak ve güvenlik tehditlerini ve operasyonel darboğazları ortadan kaldırmak için kapsamlı müşteri ve iş veri kümelerini depolayan işletmeler için çok büyük bir varlıktır.
Anormallik Tespit Teknikleri
Anomali algılama, verileri izlemek ve tehditleri algılamak için çeşitli prosedürler ve makine öğrenimi (ML) algoritmaları kullanır.
Başlıca anomali tespit teknikleri şunlardır:
1 numara. Makine Öğrenimi Teknikleri

Makine Öğrenimi teknikleri, verileri analiz etmek ve anormallikleri tespit etmek için makine öğrenimi algoritmalarını kullanır. Anormallik tespiti için farklı Makine Öğrenimi algoritma türleri şunları içerir:
- Kümeleme algoritmaları
- sınıflandırma algoritmaları
- Derin öğrenme algoritmaları
Anormallik ve tehdit tespiti için yaygın olarak kullanılan makine öğrenimi teknikleri arasında destek vektör makineleri (SVM'ler), k-means kümeleme ve otomatik kodlayıcılar bulunur.
2 numara. İstatistiksel teknikler
İstatistiksel teknikler, beklenen değerlerin aralığının ötesine geçen değerleri saptamak için verilerdeki olağandışı kalıpları (belirli bir makinenin performansındaki olağandışı dalgalanmalar gibi) algılamak için istatistiksel modeller kullanır.
Yaygın istatistiksel anormallik algılama teknikleri arasında hipotez testi, IQR, Z-skoru, değiştirilmiş Z-skoru, yoğunluk tahmini, kutu grafiği, aşırı değer analizi ve histogram bulunur.
#3. Veri Madenciliği Teknikleri

Veri madenciliği teknikleri, veri kümesindeki anormallikleri bulmak için veri sınıflandırma ve kümeleme tekniklerini kullanır. Bazı yaygın veri madenciliği anomali teknikleri arasında spektral kümeleme, yoğunluğa dayalı kümeleme ve temel bileşen analizi bulunur.
Kümeleme veri madenciliği algoritmaları, veri noktalarını ve bu kümelerin dışında kalan anormallikleri bulmak için benzerliklerine göre farklı veri noktalarını kümeler halinde gruplandırmak için kullanılır.
Öte yandan, sınıflandırma algoritmaları, veri noktalarını önceden tanımlanmış belirli sınıflara tahsis eder ve bu sınıflara ait olmayan veri noktalarını tespit eder.
#4. Kural Tabanlı Teknikler
Adından da anlaşılacağı gibi, kural tabanlı anormallik tespit teknikleri, verilerdeki anormallikleri bulmak için önceden belirlenmiş bir dizi kural kullanır.
Bu tekniklerin kurulumu nispeten daha kolay ve basittir ancak esnek olmayabilir ve değişen veri davranışına ve modellerine uyum sağlamada verimli olmayabilir.
Örneğin, belirli bir dolar tutarını aşan işlemleri hileli olarak işaretlemek için kural tabanlı bir sistemi kolayca programlayabilirsiniz.
# 5. Etki Alanına Özgü Teknikler
Belirli veri sistemlerindeki anormallikleri algılamak için etki alanına özgü teknikleri kullanabilirsiniz. Bununla birlikte, belirli alanlardaki anormallikleri tespit etmede oldukça verimli olsalar da, belirtilen alan dışındaki diğer alanlarda daha az verimli olabilirler.
Örneğin, alana özgü teknikleri kullanarak, özellikle finansal işlemlerdeki anormallikleri bulmak için teknikler tasarlayabilirsiniz. Ancak, bir makinede anormallikleri veya performans düşüşlerini bulmak için çalışmayabilirler.
Anomali Tespiti İçin Makine Öğrenimi İhtiyacı
Makine öğrenimi, anormallik tespitinde çok önemli ve oldukça faydalıdır.
Günümüzde aykırı değer tespitine ihtiyaç duyan çoğu şirket ve kuruluş, metin, müşteri bilgileri ve işlemlerden resimler ve video içeriği gibi medya dosyalarına kadar çok büyük miktarda veriyle uğraşmaktadır.
Anlamlı içgörüler elde etmek için her saniye manuel olarak oluşturulan tüm banka işlemlerini ve verileri gözden geçirmek neredeyse imkansızdır. Ayrıca çoğu şirket, yapılandırılmamış verileri yapılandırmada ve verileri veri analizi için anlamlı bir şekilde düzenlemede zorluklarla ve büyük zorluklarla karşı karşıyadır.
Makine öğrenimi (ML) gibi araç ve tekniklerin büyük hacimli yapılandırılmamış verileri toplama, temizleme, yapılandırma, düzenleme, analiz etme ve depolamada büyük rol oynadığı yer burasıdır.
Makine Öğrenimi teknikleri ve algoritmaları, büyük veri kümelerini işler ve en iyi sonuçları elde etmek için farklı teknikleri ve algoritmaları kullanma ve birleştirme esnekliği sağlar.
Ayrıca makine öğrenimi, gerçek dünyadaki uygulamalar için anormallik algılama süreçlerini kolaylaştırmaya yardımcı olur ve değerli kaynakları korur.
Anormallik algılamada makine öğreniminin bazı diğer yararları ve önemi aşağıda verilmiştir:
- Açık programlama gerektirmeden kalıpların ve anormalliklerin tanımlanmasını otomatikleştirerek ölçeklendirme anomali tespitini kolaylaştırır .
- Makine Öğrenimi algoritmaları, değişen veri seti kalıplarına son derece uyarlanabilir , bu da onları zamanla oldukça verimli ve sağlam hale getirir.
- Büyük ve karmaşık veri kümelerini kolayca işleyerek , veri kümesi karmaşıklığına rağmen anormallik algılamayı verimli hale getirir.
- Anomalileri meydana geldikleri anda tanımlayarak erken anomali tanımlama ve tespitini sağlar , zamandan ve kaynaklardan tasarruf sağlar.
- Makine Öğrenimi tabanlı anomali tespit sistemleri, anomali tespitinde geleneksel yöntemlere kıyasla daha yüksek doğruluk seviyeleri elde edilmesine yardımcı olur.
Böylece, makine öğrenimiyle birlikte anormallik tespiti, güvenlik tehditlerini ve kötü amaçlı ihlalleri önlemek için anormalliklerin daha hızlı ve daha erken tespit edilmesine yardımcı olur.

Anomali Tespiti İçin Makine Öğrenimi Algoritmaları
Sınıflandırma, kümeleme veya birliktelik kuralı öğrenimi için farklı veri madenciliği algoritmalarının yardımıyla verilerdeki anormallikleri ve aykırı değerleri tespit edebilirsiniz.
Tipik olarak, bu veri madenciliği algoritmaları, denetimli ve denetimsiz öğrenme algoritmaları olmak üzere iki farklı kategoride sınıflandırılır.
Denetimli Öğrenme
Denetimli öğrenme, destek vektör makineleri, lojistik ve doğrusal regresyon ve çok sınıflı sınıflandırma gibi algoritmalardan oluşan yaygın bir öğrenme algoritması türüdür. Bu algoritma türü, etiketli veriler üzerinde eğitilir, yani eğitim veri seti, tahmine dayalı bir model oluşturmak için hem normal girdi verilerini hem de karşılık gelen doğru çıktıyı veya anormal örnekleri içerir.
Bu nedenle amacı, eğitim veri seti modellerine dayalı olarak görünmeyen ve yeni veriler için çıktı tahminleri yapmaktır. Denetimli öğrenme algoritmalarının uygulamaları arasında görüntü ve konuşma tanıma, tahmine dayalı modelleme ve doğal dil işleme (NLP) yer alır.
Denetimsiz Öğrenme
denetimsiz öğrenme herhangi bir etiketli veri üzerinde eğitilmemiştir. Bunun yerine, eğitim algoritması rehberliği sağlamadan ve belirli tahminler yapmak yerine karmaşık süreçleri ve altta yatan veri yapılarını keşfeder.
Denetimsiz öğrenme algoritmalarının uygulamaları arasında anormallik tespiti, yoğunluk tahmini ve veri sıkıştırma yer alır.
Şimdi bazı popüler makine öğrenimi tabanlı anormallik algılama algoritmalarını keşfedelim.
Yerel Aykırı Değer Faktörü (LOF)
Yerel Aykırı Değer Faktörü veya LOF, bir veri noktasının anormallik olup olmadığını belirlemek için yerel veri yoğunluğunu dikkate alan bir anormallik saptama algoritmasıdır.
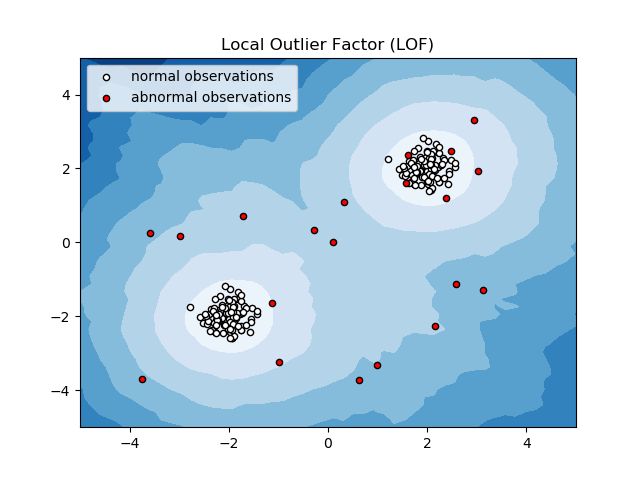
Bir öğenin yerel yoğunluğunu, komşularının yerel yoğunluklarıyla karşılaştırarak, benzer yoğunluklara sahip alanları ve komşularından nispeten daha düşük yoğunluğa sahip öğeleri (bunlar anormalliklerden veya aykırı değerlerden başka bir şey değildir) analiz eder.
Bu nedenle, basit bir ifadeyle, aykırı veya anormal bir öğeyi çevreleyen yoğunluk, komşularının etrafındaki yoğunluktan farklıdır. Bu nedenle, bu algoritmaya yoğunluk tabanlı aykırı değer tespit algoritması da denir.
K-En Yakın Komşu (K-NN)
K-NN, uygulaması kolay, mevcut tüm örnekleri ve verileri depolayan ve yeni örnekleri mesafe ölçümlerindeki benzerliklere göre sınıflandıran en basit sınıflandırma ve denetimli anomali algılama algoritmasıdır.
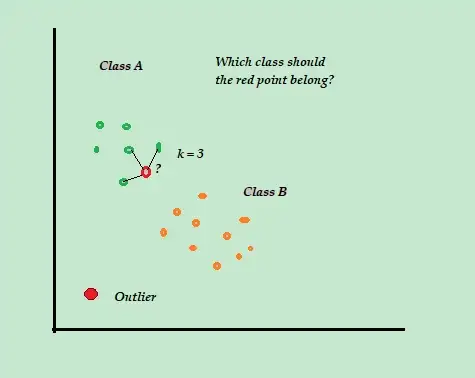
Bu sınıflandırma algoritmasına tembel öğrenen de denir çünkü eğitim sürecinde başka hiçbir şey yapmadan yalnızca etiketli eğitim verilerini depolar.
Yeni etiketlenmemiş eğitim veri noktası geldiğinde, algoritma, yeni etiketlenmemiş veri noktasının sınıfını sınıflandırmak ve belirlemek için bunları kullanmak üzere en yakın K-en yakın veya en yakın eğitim veri noktalarına bakar.
K-NN algoritması, en yakın veri noktalarını belirlemek için aşağıdaki algılama yöntemlerini kullanır:
- Sürekli veriler için mesafeyi ölçmek için Öklid mesafesi .
- Ayrık veriler için iki metin dizisinin yakınlığını veya "yakınlığını" ölçmek için Hamming mesafesi .
Örneğin, eğitim veri kümelerinizin A ve B olmak üzere iki sınıf etiketinden oluştuğunu düşünün. Yeni bir veri noktası geldiğinde, algoritma yeni veri noktası ile veri kümesindeki her bir veri noktası arasındaki mesafeyi hesaplar ve noktaları seçer. bunlar, yeni veri noktasına en yakın maksimum sayıdır.
Öyleyse, K=3 olduğunu varsayalım ve 3 veri noktasından 2'si A olarak etiketlendi, ardından yeni veri noktası A sınıfı olarak etiketlendi.
Bu nedenle, K-NN algoritması, sık veri güncelleme gereksinimleri olan dinamik ortamlarda en iyi şekilde çalışır.
Hileli işlemleri tespit etmek ve dolandırıcılık tespit oranını artırmak için finans ve işletmelerdeki uygulamaları ile popüler bir anormallik tespiti ve metin madenciliği algoritmasıdır.
Destek Vektör Makinesi (SVM)
Destek vektör makinesi, çoğunlukla regresyon ve sınıflandırma problemlerinde kullanılan denetimli makine öğrenmesi tabanlı bir anomali tespit algoritmasıdır.
Verileri iki gruba (yeni ve normal) ayırmak için çok boyutlu bir hiper düzlem kullanır. Böylece hiperdüzlem, normal veri gözlemleri ile yeni verileri ayıran bir karar sınırı görevi görür.
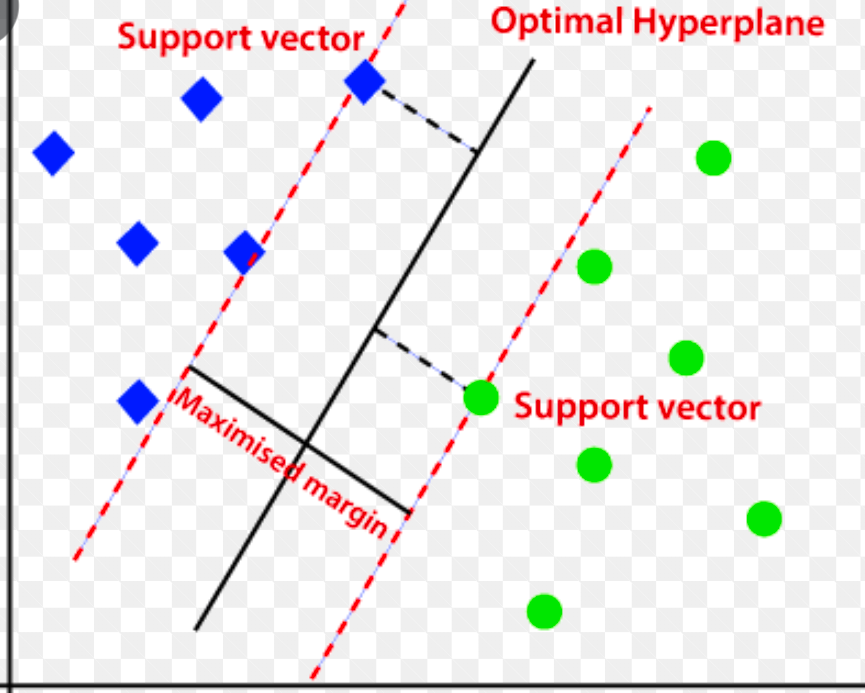
Bu iki veri noktası arasındaki mesafe kenar boşlukları olarak adlandırılır.
Amaç, iki nokta arasındaki mesafeyi artırmak olduğundan, DVM, iki sınıf arasındaki mesafenin olabildiğince geniş olmasını sağlamak için en iyi veya en uygun hiperdüzlemi maksimum marjla belirler.
Anormallik tespiti ile ilgili olarak SVM, sınıflandırmak için hiper düzlemden yeni veri noktası gözleminin marjını hesaplar.
Kenar boşluğu ayarlanan eşiği aşarsa, yeni gözlemi bir anormallik olarak sınıflandırır. Aynı zamanda marj eşiğin altındaysa gözlem normal olarak sınıflandırılır.
Bu nedenle, DVM algoritmaları, yüksek boyutlu ve karmaşık veri kümelerini işlemede oldukça etkilidir.
İzolasyon Ormanı
İzolasyon Ormanı, Rastgele Orman Sınıflandırıcı konseptine dayalı, denetimsiz bir makine öğrenimi anomali algılama algoritmasıdır.
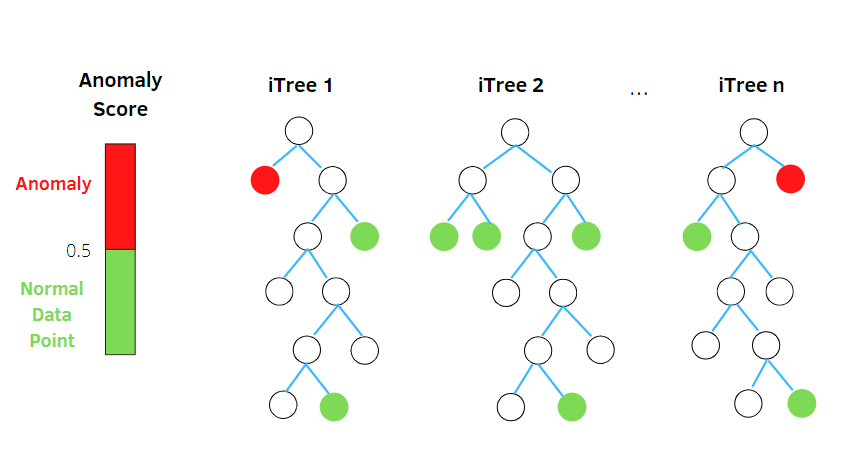
Bu algoritma, rastgele özniteliklere dayalı bir ağaç yapısındaki veri kümesindeki rastgele alt örneklenmiş verileri işler. Gözlemleri izole etmek için birkaç karar ağacı oluşturur. Ve belirli bir gözlemi, kirlenme oranına bağlı olarak daha az ağaçta izole edilmişse bir anormallik olarak kabul eder.
Böylece, basit bir ifadeyle, izolasyon ormanı algoritması , veri noktalarını farklı karar ağaçlarına ayırarak her gözlemin diğerinden izole edilmesini sağlar.
Anormallikler tipik olarak veri noktaları kümesinden uzakta yer alır ve bu da normal veri noktalarına kıyasla anormallikleri tanımlamayı kolaylaştırır.
İzolasyon ormanı algoritmaları, kategorik ve sayısal verileri kolayca işleyebilir. Sonuç olarak, daha hızlı eğitilirler ve yüksek boyutlu ve büyük veri kümelerindeki anormallikleri tespit etmede oldukça verimlidirler.
Çeyrekler arası aralık
Çeyrekler arası aralık veya IQR, veri kümelerindeki anormal noktaları çeyreklere bölerek bulmak için istatistiksel değişkenliği veya istatistiksel dağılımı ölçmek için kullanılır.
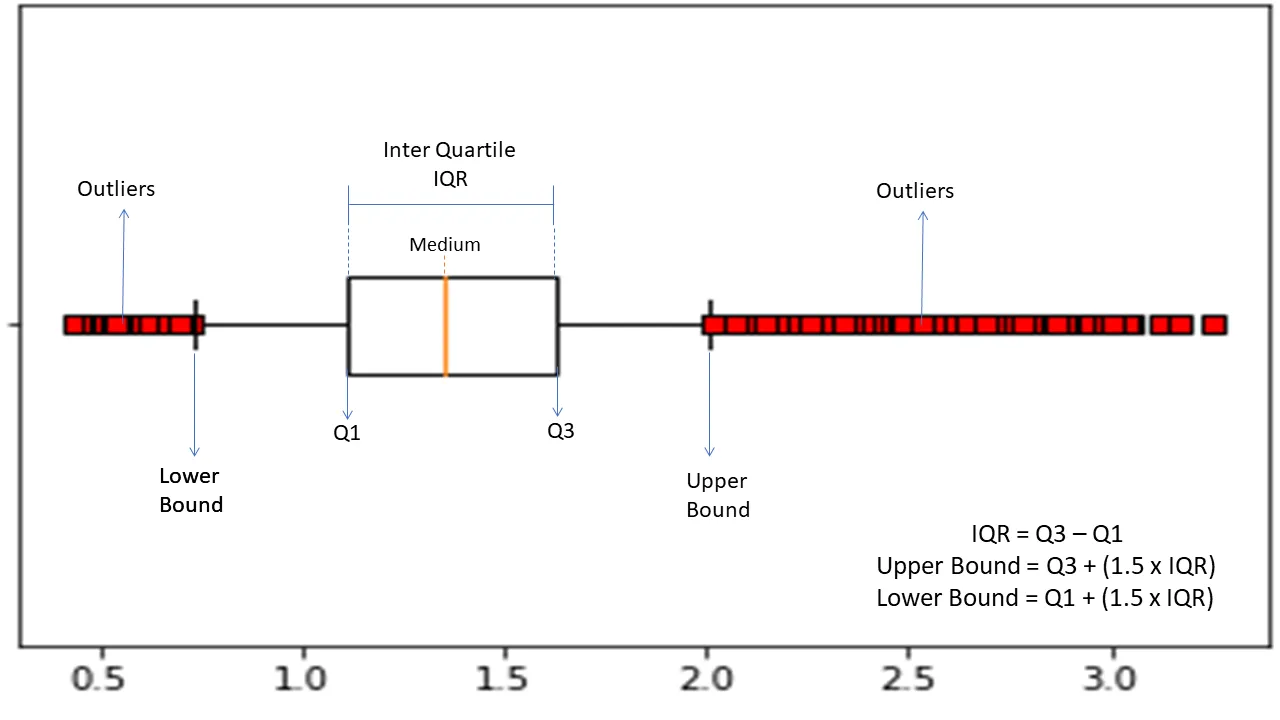
Algoritma, verileri artan düzende sıralar ve seti dört eşit parçaya böler. Bu parçaları ayıran değerler Q1, Q2 ve Q3'tür; birinci, ikinci ve üçüncü çeyrekler.
İşte bu çeyreklerin yüzdelik dağılımı:
- Q1, verilerin 25. yüzdelik dilimini ifade eder.
- Q2, verilerin 50. yüzdelik dilimini ifade eder.
- Q3, verilerin 75. yüzdelik dilimini ifade eder.
IQR, verilerin %50'sini temsil eden üçüncü (75.) ve birinci (25.) yüzdelik veri setleri arasındaki farktır.
Anormallik tespiti için IQR'yi kullanmak, veri kümenizin IQR'sini hesaplamanızı ve anormallikleri bulmak için verilerin alt ve üst sınırlarını tanımlamanızı gerektirir.
- Alt sınır: Q1 – 1,5 * IQR
- Üst sınır: Q3 + 1,5 * IQR
Tipik olarak, bu sınırların dışında kalan gözlemler anormallik olarak kabul edilir.
IQR algoritması, verilerin eşit olmayan şekilde dağıldığı ve dağılımın iyi anlaşılmadığı veri kümeleri için etkilidir.
Son sözler
Siber güvenlik riskleri ve veri ihlalleri önümüzdeki yıllarda azalacak gibi görünmüyor ve bu riskli sektörün 2023'te daha da büyümesi ve yalnızca IoT siber saldırılarının 2025'e kadar iki katına çıkması bekleniyor.
Ayrıca, siber suçlar, küresel şirketlere ve kuruluşlara 2025 yılına kadar yıllık tahmini 10,3 trilyon dolara mal olacak.
Bu nedenle, günümüzde dolandırıcılık tespiti ve ağ izinsiz girişlerini önlemek için anormallik tespit tekniklerine olan ihtiyaç daha yaygın ve gerekli hale geliyor.
Bu makale, veri madenciliğindeki anormalliklerin ne olduğunu, farklı anormallik türlerini ve makine öğrenimi tabanlı anormallik tespit tekniklerini kullanarak ağ izinsiz girişlerini önlemenin yollarını anlamanıza yardımcı olacaktır.
Ardından, makine öğrenimindeki karışıklık matrisiyle ilgili her şeyi keşfedebilirsiniz.