
วิธีซิงค์ฐานข้อมูล Oracle ภายในองค์กรของคุณกับ AWS
เผยแพร่แล้ว: 2023-01-11การเฝ้าดูการพัฒนาซอฟต์แวร์ขององค์กรจากแถวแรกเป็นเวลาสองทศวรรษ แนวโน้มที่ปฏิเสธไม่ได้ในช่วงไม่กี่ปีที่ผ่านมานั้นชัดเจน นั่นคือการย้ายฐานข้อมูลไปสู่ระบบคลาวด์
ฉันได้มีส่วนร่วมในโครงการการย้ายข้อมูลสองสามโครงการแล้ว ซึ่งเป้าหมายคือการนำฐานข้อมูลภายในองค์กรที่มีอยู่มาไว้ในฐานข้อมูล Amazon Web Services (AWS) Cloud จากเอกสารประกอบของ AWS คุณจะได้เรียนรู้ว่าสิ่งนี้สามารถทำได้ง่ายเพียงใด แต่ฉันมาที่นี่เพื่อบอกคุณว่าการดำเนินการตามแผนนั้นไม่ใช่เรื่องง่ายเสมอไป และมีบางกรณีที่อาจล้มเหลวได้

ในโพสต์นี้ ฉันจะครอบคลุมประสบการณ์จริงในกรณีต่อไปนี้:
- แหล่งที่มา : ในทางทฤษฎีแล้ว มันไม่สำคัญว่าแหล่งที่มาของคุณคืออะไร (คุณสามารถใช้วิธีการที่คล้ายกันมากกับฐานข้อมูลส่วนใหญ่ที่ได้รับความนิยมสูงสุด) Oracle เป็นระบบฐานข้อมูลที่ได้รับเลือกในบริษัทองค์กรขนาดใหญ่เป็นเวลาหลายปี และ นั่นคือจุดสนใจของฉัน
- The Target : ไม่มีเหตุผลว่าทำไมต้องเจาะจงด้านนี้ คุณสามารถเลือกฐานข้อมูลเป้าหมายใดก็ได้ใน AWS และแนวทางจะยังคงเหมาะสม
- โหมด : คุณสามารถรีเฟรชทั้งหมดหรือรีเฟรชส่วนเพิ่มได้ การโหลดข้อมูลเป็นชุด (สถานะต้นทางและเป้าหมายล่าช้า) หรือ (ใกล้) การโหลดข้อมูลตามเวลาจริง ทั้งสองจะถูกสัมผัสที่นี่
- ความถี่ : คุณอาจต้องการการย้ายข้อมูลเพียงครั้งเดียวตามด้วยการสลับไปยังระบบคลาวด์อย่างเต็มรูปแบบ หรือต้องการระยะเวลาการเปลี่ยนแปลงและให้ข้อมูลเป็นปัจจุบันทั้งสองด้านพร้อมกัน ซึ่งหมายถึงการพัฒนาการซิงโครไนซ์รายวันระหว่างภายในองค์กรและ AWS แบบแรกนั้นง่ายกว่าและสมเหตุสมผลกว่ามาก แต่แบบหลังมักถูกร้องขอมากกว่าและมีจุดพักมากกว่า ฉันจะครอบคลุมทั้งสองที่นี่
คำอธิบายปัญหา
ข้อกำหนดมักจะง่าย:
เราต้องการเริ่มต้นพัฒนาบริการภายใน AWS ดังนั้นโปรดคัดลอกข้อมูลทั้งหมดของเราไปยังฐานข้อมูล “ABC” อย่างรวดเร็วและง่ายดาย ตอนนี้เราจำเป็นต้องใช้ข้อมูลใน AWS ในภายหลัง เราจะพิจารณาว่าส่วนใดของการออกแบบ DB ที่จะเปลี่ยนแปลงเพื่อให้ตรงกับกิจกรรมของเรา
ก่อนที่จะดำเนินการต่อไป มีสิ่งที่ต้องพิจารณา:
- อย่ากระโดดเข้าสู่ความคิดที่ว่า “แค่คัดลอกสิ่งที่เรามีแล้วจัดการในภายหลัง” เร็วเกินไป ฉันหมายความว่า ใช่ นี่เป็นวิธีที่ง่ายที่สุดที่คุณสามารถทำได้ และจะเสร็จอย่างรวดเร็ว แต่สิ่งนี้มีศักยภาพที่จะสร้างปัญหาทางสถาปัตยกรรมพื้นฐานดังกล่าว ซึ่งจะไม่สามารถแก้ไขได้ในภายหลัง หากไม่มีการปรับโครงสร้างใหม่อย่างจริงจังของแพลตฟอร์มคลาวด์ใหม่ส่วนใหญ่ . ลองนึกภาพว่าระบบนิเวศของคลาวด์นั้นแตกต่างอย่างสิ้นเชิงจากระบบในองค์กร บริการใหม่ ๆ หลายอย่างจะถูกนำมาใช้เมื่อเวลาผ่านไป โดยธรรมชาติแล้วผู้คนจะเริ่มใช้สิ่งเดียวกันแตกต่างกันมาก แทบจะเป็นไปไม่ได้เลยที่จะจำลองสถานะภายในองค์กรในระบบคลาวด์แบบ 1:1 อาจเป็นในกรณีเฉพาะของคุณ แต่อย่าลืมตรวจสอบอีกครั้ง
- ถามข้อกำหนดด้วยข้อสงสัยที่มีความหมายเช่น:
- ใครจะเป็นผู้ใช้ทั่วไปที่ใช้แพลตฟอร์มใหม่ ในขณะที่อยู่ในองค์กร มันสามารถเป็นผู้ใช้ทางธุรกิจที่ทำธุรกรรมได้ ในระบบคลาวด์ อาจเป็นนักวิทยาศาสตร์ข้อมูลหรือนักวิเคราะห์คลังข้อมูล หรือผู้ใช้หลักของข้อมูลอาจเป็นบริการ (เช่น Databricks, Glue, โมเดลการเรียนรู้ของเครื่อง เป็นต้น)
- งานประจำวันปกติคาดว่าจะยังคงอยู่แม้ว่าจะเปลี่ยนไปใช้ระบบคลาวด์แล้วหรือไม่ ถ้าไม่ คาดว่าจะมีการเปลี่ยนแปลงอย่างไร
- คุณวางแผนการเติบโตของข้อมูลในช่วงเวลาหนึ่งหรือไม่? ส่วนใหญ่แล้ว คำตอบคือใช่ เนื่องจากนั่นมักเป็นเหตุผลเดียวที่สำคัญที่สุดในการโยกย้ายไปยังระบบคลาวด์ แบบจำลองข้อมูลใหม่จะต้องพร้อมสำหรับมัน
- คาดหวังให้ผู้ใช้คิดถึงคำถามทั่วไปที่คาดว่าจะได้รับจากผู้ใช้ฐานข้อมูลใหม่ สิ่งนี้จะกำหนดว่าโมเดลข้อมูลที่มีอยู่จะเปลี่ยนแปลงมากน้อยเพียงใดเพื่อให้สอดคล้องกับประสิทธิภาพ
การตั้งค่าการย้ายข้อมูล
เมื่อเลือกฐานข้อมูลเป้าหมายและพูดถึงโมเดลข้อมูลจนพอใจแล้ว ขั้นตอนต่อไปคือทำความคุ้นเคยกับ AWS Schema Conversion Tool มีหลายพื้นที่ที่เครื่องมือนี้สามารถให้บริการได้:
- วิเคราะห์และแยกโมเดลข้อมูลต้นทาง SCT จะอ่านสิ่งที่อยู่ในฐานข้อมูลภายในองค์กรปัจจุบัน และจะสร้างแบบจำลองแหล่งข้อมูลเพื่อเริ่มต้น
- แนะนำโครงสร้างโมเดลข้อมูลเป้าหมายตามฐานข้อมูลเป้าหมาย
- สร้างสคริปต์การปรับใช้ฐานข้อมูลเป้าหมายเพื่อติดตั้งโมเดลข้อมูลเป้าหมาย (ตามสิ่งที่เครื่องมือค้นพบจากฐานข้อมูลต้นทาง) สิ่งนี้จะสร้างสคริปต์การปรับใช้ และหลังจากดำเนินการ ฐานข้อมูลในระบบคลาวด์จะพร้อมสำหรับการโหลดข้อมูลจากฐานข้อมูลในสถานที่
ตอนนี้มีเคล็ดลับเล็กน้อยสำหรับการใช้เครื่องมือแปลงสคีมา
ประการแรก แทบจะเป็นไปไม่ได้เลยที่จะใช้เอาต์พุตโดยตรง ฉันจะพิจารณาว่ามันเป็นเหมือนผลอ้างอิง ซึ่งคุณจะต้องปรับเปลี่ยนตามความเข้าใจและวัตถุประสงค์ของข้อมูลของคุณ และวิธีที่ข้อมูลจะถูกใช้ในระบบคลาวด์
ประการที่สอง ก่อนหน้านี้ ผู้ใช้อาจเลือกตารางโดยคาดหวังผลลัพธ์สั้นๆ อย่างรวดเร็วเกี่ยวกับเอนทิตีโดเมนข้อมูลที่เป็นรูปธรรมบางอย่าง แต่ตอนนี้ ข้อมูลอาจถูกเลือกสำหรับวัตถุประสงค์ในการวิเคราะห์ ตัวอย่างเช่น ดัชนีฐานข้อมูลที่เคยทำงานในฐานข้อมูลภายในองค์กรจะไร้ประโยชน์และไม่ได้ปรับปรุงประสิทธิภาพของระบบ DB ที่เกี่ยวข้องกับการใช้งานใหม่นี้อย่างแน่นอน ในทำนองเดียวกัน คุณอาจต้องการแบ่งพาร์ติชันข้อมูลบนระบบเป้าหมายให้แตกต่างไปจากที่เคยเป็นมาก่อนบนระบบต้นทาง
นอกจากนี้ อาจเป็นการดีที่จะพิจารณาทำการแปลงข้อมูลบางอย่างในระหว่างกระบวนการย้าย ซึ่งโดยพื้นฐานแล้วหมายถึงการเปลี่ยนโมเดลข้อมูลเป้าหมายสำหรับบางตาราง (เพื่อให้ไม่ใช่สำเนา 1:1 อีกต่อไป) ในภายหลัง กฎการเปลี่ยนแปลงจะต้องนำไปใช้กับเครื่องมือการย้ายข้อมูล
การกำหนดค่าเครื่องมือการย้ายข้อมูล
หากฐานข้อมูลต้นทางและเป้าหมายเป็นประเภทเดียวกัน (เช่น Oracle on-premise เทียบกับ Oracle ใน AWS, PostgreSQL เทียบกับ Aurora Postgresql เป็นต้น) วิธีที่ดีที่สุดคือใช้เครื่องมือย้ายข้อมูลเฉพาะที่ฐานข้อมูลคอนกรีตรองรับแบบเนทีฟ ( เช่น การส่งออกและนำเข้า Data Pump, Oracle Goldengate เป็นต้น)
อย่างไรก็ตาม ในกรณีส่วนใหญ่ ฐานข้อมูลต้นทางและเป้าหมายจะใช้งานร่วมกันไม่ได้ จากนั้นเครื่องมือที่เลือกอย่างชัดเจนคือ AWS Database Migration Service
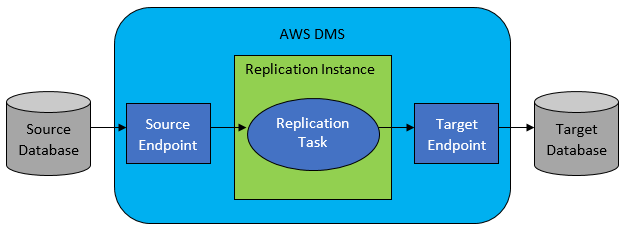
AWS DMS โดยทั่วไปอนุญาตให้กำหนดค่ารายการงานในระดับตาราง ซึ่งจะกำหนด:
- DB ต้นทางและตารางที่จะเชื่อมต่อคืออะไร
- ข้อกำหนดคำสั่งที่จะใช้เพื่อรับข้อมูลสำหรับตารางเป้าหมาย
- เครื่องมือการแปลง (ถ้ามี) กำหนดวิธีการแมปข้อมูลต้นทางเข้ากับข้อมูลตารางเป้าหมาย (หากไม่ใช่ 1:1)
- ฐานข้อมูลและตารางเป้าหมายที่แน่นอนในการโหลดข้อมูลคืออะไร
การกำหนดค่างาน DMS ทำในรูปแบบที่ใช้งานง่าย เช่น JSON
ตอนนี้ในสถานการณ์ที่ง่ายที่สุด สิ่งที่คุณต้องทำคือเรียกใช้สคริปต์การปรับใช้บนฐานข้อมูลเป้าหมายและเริ่มงาน DMS แต่มีอะไรมากกว่านั้น
การย้ายข้อมูลแบบเต็มเพียงครั้งเดียว

กรณีที่ง่ายที่สุดในการดำเนินการคือเมื่อคำขอย้ายฐานข้อมูลทั้งหมดไปยังฐานข้อมูลคลาวด์เป้าหมาย โดยพื้นฐานแล้ว สิ่งที่จำเป็นต้องทำจะมีลักษณะดังนี้:

- กำหนดงาน DMS สำหรับแต่ละตารางต้นทาง
- ตรวจสอบให้แน่ใจว่าได้ระบุการกำหนดค่าของงาน DMS อย่างถูกต้อง ซึ่งหมายถึงการตั้งค่าการขนานที่สมเหตุสมผล ตัวแปรแคช การกำหนดค่าเซิร์ฟเวอร์ DMS ขนาดของคลัสเตอร์ DMS เป็นต้น ขั้นตอนนี้มักเป็นขั้นตอนที่ใช้เวลานานที่สุด เนื่องจากต้องมีการทดสอบอย่างละเอียดถี่ถ้วนและการปรับแต่งสถานะการกำหนดค่าที่เหมาะสมที่สุด
- ตรวจสอบให้แน่ใจว่าแต่ละตารางเป้าหมายถูกสร้างขึ้น (ว่าง) ในฐานข้อมูลเป้าหมายในโครงสร้างตารางที่คาดหวัง
- กำหนดกรอบเวลาที่จะดำเนินการย้ายข้อมูล ก่อนหน้านั้น ตรวจสอบให้แน่ใจ (โดยทำการทดสอบประสิทธิภาพ) กรอบเวลาจะเพียงพอสำหรับการย้ายข้อมูลให้เสร็จสมบูรณ์ ในระหว่างการโอนย้าย ฐานข้อมูลต้นทางอาจถูกจำกัดจากมุมมองด้านประสิทธิภาพ นอกจากนี้ คาดว่าฐานข้อมูลต้นทางจะไม่เปลี่ยนแปลงในระหว่างเวลาที่การย้ายข้อมูลกำลังทำงาน มิฉะนั้น ข้อมูลที่ย้ายอาจแตกต่างจากที่จัดเก็บไว้ในฐานข้อมูลต้นทางเมื่อการย้ายข้อมูลเสร็จสิ้น
หากการกำหนดค่าของ DMS ทำได้ดี จะไม่มีอะไรเลวร้ายเกิดขึ้นในสถานการณ์นี้ ทุกตารางต้นฉบับจะถูกหยิบขึ้นมาและคัดลอกไปยังฐานข้อมูลเป้าหมายของ AWS ข้อกังวลเพียงอย่างเดียวคือประสิทธิภาพของกิจกรรมและตรวจสอบให้แน่ใจว่าขนาดถูกต้องในทุกขั้นตอน เพื่อไม่ให้เกิดข้อผิดพลาดเนื่องจากพื้นที่จัดเก็บไม่เพียงพอ
การซิงโครไนซ์รายวันที่เพิ่มขึ้น

นี่คือสิ่งที่เริ่มซับซ้อน ฉันหมายความว่า ถ้าโลกนี้อยู่ในอุดมคติ มันก็น่าจะใช้ได้ดีตลอดเวลา แต่โลกไม่เคยสมบูรณ์แบบ
สามารถกำหนดค่า DMS ให้ทำงานในสองโหมด:
- โหลดเต็ม – โหมดเริ่มต้นที่อธิบายและใช้ข้างต้น งาน DMS จะเริ่มต้นเมื่อคุณเริ่มต้นหรือเมื่อมีการกำหนดเวลาให้เริ่มต้น เมื่อเสร็จแล้ว งาน DMS ก็เสร็จสิ้น
- เปลี่ยนการเก็บข้อมูล (CDC) – ในโหมดนี้ งาน DMS จะทำงานอย่างต่อเนื่อง DMS จะสแกนฐานข้อมูลต้นทางเพื่อหาการเปลี่ยนแปลงในระดับตาราง หากการเปลี่ยนแปลงเกิดขึ้น ระบบจะพยายามจำลองการเปลี่ยนแปลงในฐานข้อมูลเป้าหมายโดยทันทีตามการกำหนดค่าภายในงาน DMS ที่เกี่ยวข้องกับตารางที่เปลี่ยนแปลง
เมื่อไปที่ CDC คุณต้องเลือกอีกทางหนึ่ง นั่นคือวิธีที่ CDC จะแยกการเปลี่ยนแปลงเดลต้าจากฐานข้อมูลต้นทาง
#1. โปรแกรมอ่านบันทึก Oracle Redo
ทางเลือกหนึ่งคือการเลือกตัวอ่านบันทึกการทำซ้ำของฐานข้อมูลดั้งเดิมจาก Oracle ซึ่ง CDC สามารถใช้เพื่อรับข้อมูลที่เปลี่ยนแปลง และทำซ้ำการเปลี่ยนแปลงเดียวกันบนฐานข้อมูลเป้าหมายตามการเปลี่ยนแปลงล่าสุด
แม้ว่าสิ่งนี้อาจดูเหมือนเป็นตัวเลือกที่ชัดเจนหากต้องจัดการกับ Oracle เป็นซอร์ส แต่ก็มีสิ่งที่จับได้: โปรแกรมอ่านบันทึกการทำซ้ำของ Oracle ใช้คลัสเตอร์ Oracle ต้นทางและส่งผลโดยตรงต่อกิจกรรมอื่นๆ ทั้งหมดที่ทำงานในฐานข้อมูล (อันที่จริงแล้วจะสร้างเซสชันที่ใช้งานอยู่ใน ฐานข้อมูล)
ยิ่งคุณกำหนดค่างาน DMS มากเท่าไร (หรือคลัสเตอร์ DMS ขนานกันมากขึ้น) คุณก็อาจต้องเพิ่มขนาดคลัสเตอร์ Oracle มากขึ้น โดยพื้นฐานแล้ว ให้ปรับขนาดแนวตั้งของคลัสเตอร์ฐานข้อมูล Oracle หลักของคุณ สิ่งนี้จะส่งผลต่อต้นทุนรวมของโซลูชันอย่างแน่นอน ยิ่งถ้าการซิงโครไนซ์รายวันกำลังจะอยู่กับโครงการเป็นระยะเวลานาน
#2. เครื่องมือขุดบันทึก AWS DMS
นี่เป็นโซลูชัน AWS แบบเนทีฟสำหรับปัญหาเดียวกัน ซึ่งแตกต่างจากตัวเลือกด้านบน ในกรณีนี้ DMS จะไม่ส่งผลกระทบต่อ Oracle DB ต้นทาง แต่จะคัดลอกบันทึกการทำซ้ำของ Oracle ลงในคลัสเตอร์ DMS และทำการประมวลผลทั้งหมดที่นั่นแทน แม้ว่าจะช่วยประหยัดทรัพยากรของ Oracle แต่ก็เป็นโซลูชันที่ช้ากว่า เนื่องจากเกี่ยวข้องกับการดำเนินการมากขึ้น และอย่างที่เราเดาได้ง่ายๆ ว่าตัวอ่านแบบกำหนดเองสำหรับบันทึกการทำซ้ำของ Oracle อาจทำงานได้ช้ากว่าตัวอ่านแบบเนทีฟจาก Oracle
ขึ้นอยู่กับขนาดของฐานข้อมูลต้นทางและจำนวนการเปลี่ยนแปลงรายวัน ในกรณีที่ดีที่สุด คุณอาจลงเอยด้วยการซิงโครไนซ์ที่เพิ่มขึ้นเกือบตามเวลาจริงของข้อมูลจากฐานข้อมูล Oracle ภายในองค์กรไปยังฐานข้อมูล AWS Cloud
ในสถานการณ์อื่นๆ จะยังไม่ใกล้เคียงกับการซิงโครไนซ์แบบเรียลไทม์ แต่คุณสามารถพยายามเข้าใกล้ความล่าช้าที่ยอมรับได้มากที่สุด (ระหว่างต้นทางและเป้าหมาย) โดยการปรับแต่งการกำหนดค่าประสิทธิภาพของคลัสเตอร์ต้นทางและเป้าหมายและการขนานกัน หรือการทดลองกับ จำนวนงาน DMS และการกระจายระหว่างอินสแตนซ์ CDC
และคุณอาจต้องการเรียนรู้ว่า CDC รองรับการเปลี่ยนแปลงตารางต้นฉบับใดบ้าง (เช่น การเพิ่มคอลัมน์ เป็นต้น) เนื่องจากไม่รองรับการเปลี่ยนแปลงที่เป็นไปได้ทั้งหมด ในบางกรณี วิธีเดียวคือทำให้ตารางเป้าหมายเปลี่ยนแปลงด้วยตนเองและเริ่มงาน CDC ใหม่ตั้งแต่ต้น (สูญเสียข้อมูลที่มีอยู่ทั้งหมดในฐานข้อมูลเป้าหมายไปพร้อมกัน)
เมื่อสิ่งต่าง ๆ ผิดพลาด ไม่ว่าอะไรจะเกิดขึ้น

ฉันเรียนรู้สิ่งนี้ด้วยวิธีที่ยาก แต่มีสถานการณ์เฉพาะหนึ่งที่เชื่อมต่อกับ DMS ซึ่งสัญญาของการจำลองแบบรายวันนั้นยากที่จะบรรลุ
DMS สามารถประมวลผลบันทึกการทำซ้ำด้วยความเร็วที่กำหนดเท่านั้น ไม่สำคัญว่าจะมี DMS จำนวนมากที่เรียกใช้งานของคุณหรือไม่ ถึงกระนั้น อินสแตนซ์ DMS แต่ละรายการจะอ่านบันทึกการทำซ้ำด้วยความเร็วที่กำหนดเดียวเท่านั้น และแต่ละอินสแตนซ์ต้องอ่านทั้งหมด ไม่สำคัญว่าคุณจะใช้ Oracle redo logs หรือ AWS log miner ทั้งคู่มีขีดจำกัดนี้
หากฐานข้อมูลต้นทางมีการเปลี่ยนแปลงจำนวนมากภายในหนึ่งวันที่บันทึกการทำซ้ำของ Oracle มีขนาดใหญ่มาก (เช่น 500GB+ ขนาดใหญ่) ทุกวัน CDC จะไม่ทำงาน การจำลองแบบจะไม่เสร็จสิ้นก่อนสิ้นวัน จะนำงานที่ยังไม่ได้ดำเนินการไปในวันถัดไป ซึ่งชุดการเปลี่ยนแปลงใหม่ที่จะทำซ้ำกำลังรออยู่แล้ว จำนวนข้อมูลที่ยังไม่ได้ประมวลผลจะเพิ่มขึ้นในแต่ละวันเท่านั้น
ในกรณีนี้ CDC ไม่ใช่ตัวเลือก (หลังจากการทดสอบประสิทธิภาพหลายครั้งและเราพยายามดำเนินการ) วิธีเดียวที่จะทำให้แน่ใจว่าการเปลี่ยนแปลงเดลต้าอย่างน้อยที่สุดจากวันปัจจุบันจะถูกจำลองแบบในวันเดียวกันคือทำดังนี้:
- แยกโต๊ะขนาดใหญ่ที่ไม่ได้ใช้งานบ่อยนัก และจัดโต๊ะซ้ำเพียงสัปดาห์ละครั้ง (เช่น ในช่วงวันหยุดสุดสัปดาห์)
- กำหนดค่าการจำลองแบบของตารางที่ไม่ใหญ่แต่ยังคงใหญ่เพื่อแยกระหว่างงาน DMS หลายงาน ในที่สุดตารางหนึ่งก็ถูกย้ายโดยงาน DMS ที่แยกจากกัน 10 งานขึ้นไปพร้อมกัน เพื่อให้แน่ใจว่าการแยกข้อมูลระหว่างงาน DMS นั้นแตกต่างกัน (เกี่ยวข้องกับการเข้ารหัสแบบกำหนดเองที่นี่) และดำเนินการทุกวัน
- เพิ่มอินสแตนซ์ของ DMS เพิ่ม (สูงสุด 4 อินสแตนซ์ในกรณีนี้) และแบ่งงาน DMS ระหว่างกันเท่าๆ กัน ซึ่งหมายความว่าไม่เพียงแค่จำนวนตารางเท่านั้น แต่ยังรวมถึงขนาดด้วย
โดยพื้นฐานแล้ว เราใช้โหมดโหลดเต็มของ DMS เพื่อจำลองข้อมูลรายวัน เพราะนั่นเป็นวิธีเดียวที่จะทำให้การจำลองข้อมูลเสร็จสิ้นภายในวันเดียวกันเป็นอย่างน้อย
ไม่ใช่วิธีแก้ปัญหาที่สมบูรณ์แบบ แต่ก็ยังมีอยู่ และแม้ผ่านไปหลายปี ก็ยังใช้งานได้เหมือนเดิม ดังนั้นอาจไม่ใช่วิธีแก้ปัญหาที่แย่นัก