
สนับสนุน Vector Machine (SVM) ในการเรียนรู้ของเครื่อง
เผยแพร่แล้ว: 2023-01-04Support Vector Machine เป็นหนึ่งในอัลกอริธึมการเรียนรู้ของเครื่องที่ได้รับความนิยมสูงสุด มีประสิทธิภาพและสามารถฝึกในชุดข้อมูลที่จำกัด แต่มันคืออะไร?
Support Vector Machine (SVM) คืออะไร?
Support vector machine เป็นอัลกอริธึมการเรียนรู้ของเครื่องที่ใช้การเรียนรู้ภายใต้การดูแลเพื่อสร้างแบบจำลองสำหรับการจำแนกประเภทไบนารี นั่นมันเต็มปากเต็มคำ บทความนี้จะอธิบาย SVM และความเกี่ยวข้องกับการประมวลผลภาษาธรรมชาติอย่างไร แต่ก่อนอื่น ให้เราวิเคราะห์ว่าเครื่องเวกเตอร์สนับสนุนทำงานอย่างไร
SVM ทำงานอย่างไร
พิจารณาปัญหาการจำแนกประเภทอย่างง่ายที่เรามีข้อมูลที่มีคุณลักษณะสองอย่าง คือ x และ y และหนึ่งผลลัพธ์ ซึ่งเป็นการจำแนกประเภทที่มีสีแดงหรือสีน้ำเงิน เราสามารถพล็อตชุดข้อมูลจินตภาพที่มีลักษณะดังนี้:
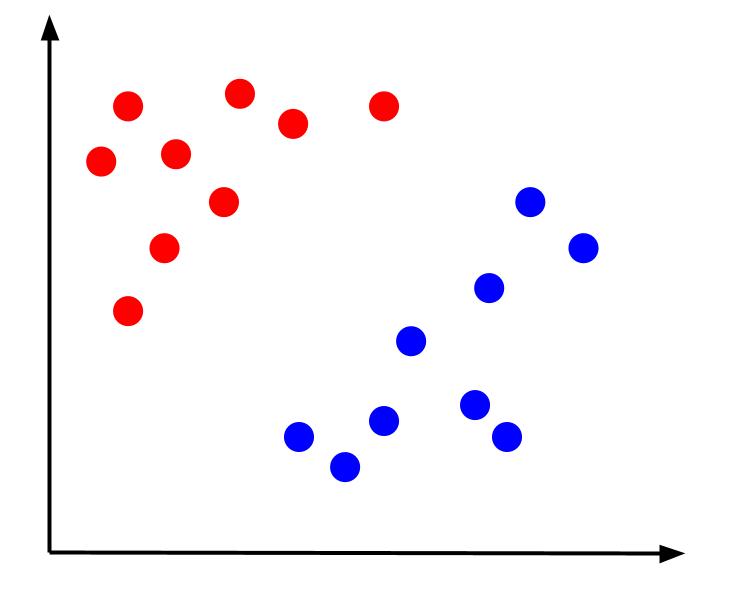
เมื่อได้รับข้อมูลเช่นนี้ ภารกิจคือการสร้างขอบเขตการตัดสินใจ ขอบเขตการตัดสินใจคือเส้นที่แยกสองคลาสของจุดข้อมูลของเรา นี่เป็นชุดข้อมูลเดียวกัน แต่มีขอบเขตการตัดสินใจ:
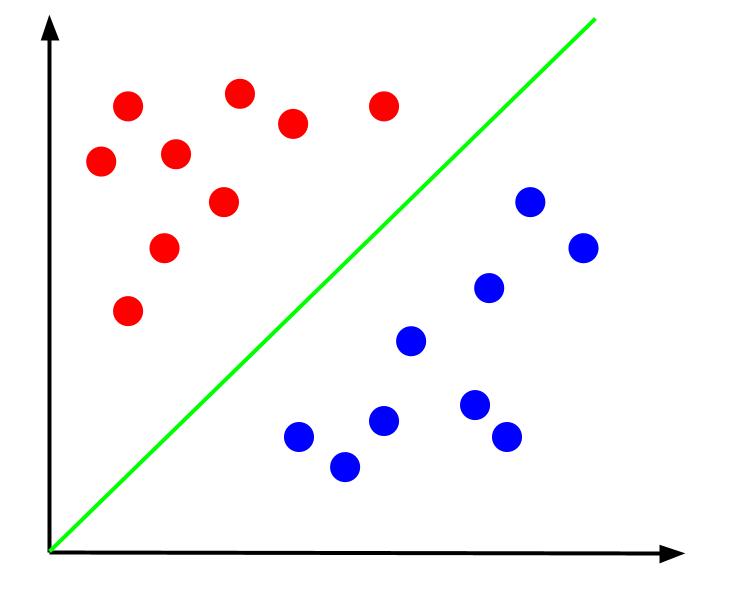
ด้วยขอบเขตการตัดสินใจนี้ เราสามารถคาดการณ์ได้ว่าดาต้าพอยต์อยู่ในคลาสใด โดยพิจารณาจากตำแหน่งที่ดาต้าพอยต์อยู่เมื่อเทียบกับขอบเขตการตัดสินใจ อัลกอริทึม Support Vector Machine สร้างขอบเขตการตัดสินใจที่ดีที่สุดที่จะใช้ในการจำแนกคะแนน
แต่เราหมายถึงอะไรโดยขอบเขตการตัดสินใจที่ดีที่สุด?
ขอบเขตการตัดสินใจที่ดีที่สุดสามารถโต้แย้งได้ว่าเป็นขอบเขตที่เพิ่มระยะห่างจากเวกเตอร์สนับสนุนตัวใดตัวหนึ่ง เวกเตอร์สนับสนุนคือจุดข้อมูลของคลาสใดคลาสหนึ่งที่อยู่ใกล้คลาสตรงข้ามมากที่สุด จุดข้อมูลเหล่านี้มีความเสี่ยงสูงสุดในการจัดประเภทที่ไม่ถูกต้อง เนื่องจากมีความใกล้ชิดกับอีกชั้นหนึ่ง
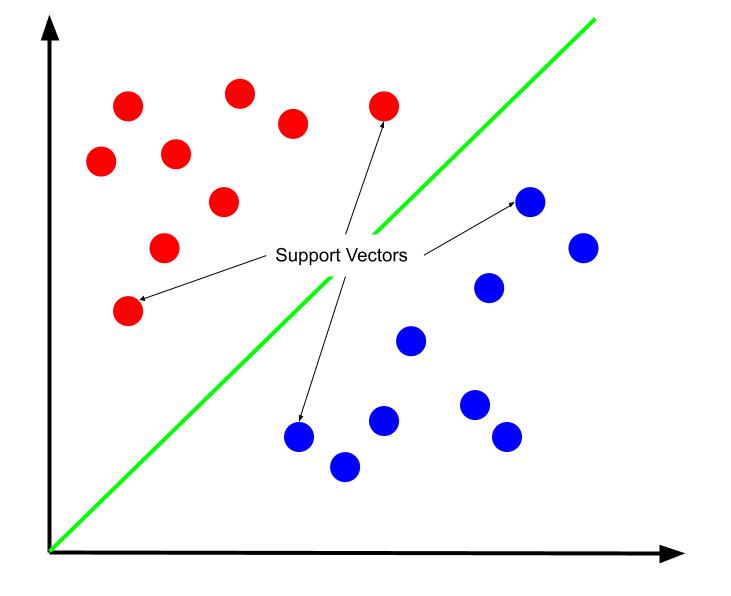
ดังนั้น การฝึกเครื่องเวกเตอร์สนับสนุนจึงเกี่ยวข้องกับการพยายามค้นหาเส้นที่เพิ่มระยะขอบระหว่างเวกเตอร์สนับสนุนให้สูงสุด
สิ่งสำคัญคือต้องสังเกตว่าเนื่องจากขอบเขตการตัดสินใจอยู่ในตำแหน่งที่สัมพันธ์กับเวกเตอร์สนับสนุน พวกมันจึงเป็นเพียงตัวกำหนดตำแหน่งของขอบเขตการตัดสินใจ ดังนั้นจุดข้อมูลอื่นจึงซ้ำซ้อน และด้วยเหตุนี้ การฝึกอบรมจึงต้องใช้เวกเตอร์สนับสนุนเท่านั้น
ในตัวอย่างนี้ ขอบเขตการตัดสินใจจะเป็นเส้นตรง นี่เป็นเพียงเพราะชุดข้อมูลมีคุณสมบัติเพียงสองอย่างเท่านั้น เมื่อชุดข้อมูลมีสามลักษณะ ขอบเขตการตัดสินใจจะเป็นระนาบแทนที่จะเป็นเส้น และเมื่อมีคุณสมบัติตั้งแต่สี่อย่างขึ้นไป ขอบเขตการตัดสินใจจะเรียกว่าไฮเปอร์เพลน
ข้อมูลที่แยกจากกันไม่เป็นเชิงเส้น
ตัวอย่างข้างต้นถือเป็นข้อมูลง่ายๆ ที่เมื่อลงจุดแล้ว สามารถแยกออกจากกันได้ด้วยขอบเขตการตัดสินใจเชิงเส้น พิจารณากรณีอื่นที่มีการลงจุดข้อมูลดังนี้:
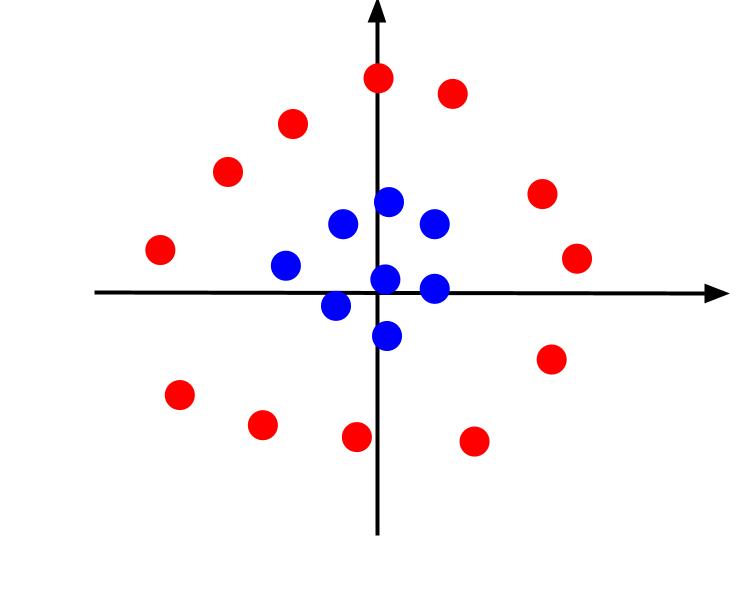
ในกรณีนี้ การแยกข้อมูลโดยใช้เส้นเป็นไปไม่ได้ แต่เราอาจสร้างคุณสมบัติอื่น z. และคุณสมบัตินี้อาจถูกกำหนดโดยสมการ: z = x^2 + y^2 เราสามารถเพิ่ม z เป็นแกนที่สามในระนาบเพื่อให้เป็นสามมิติ
เมื่อเราดูพล็อต 3 มิติจากมุมที่แกน x เป็นแนวนอนในขณะที่แกน z เป็นแนวตั้ง นี่คือมุมมองที่เราได้บางอย่างที่มีลักษณะดังนี้:
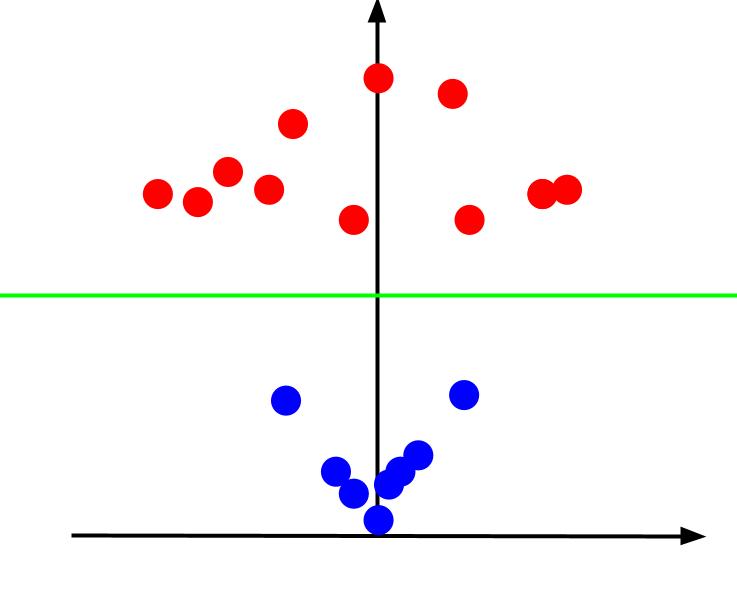
ค่า z แสดงถึงระยะทางจากจุดกำเนิดเมื่อเทียบกับจุดอื่นๆ ในระนาบ XY แบบเก่า เป็นผลให้จุดสีน้ำเงินใกล้กับจุดกำเนิดมีค่า z ต่ำ
ในขณะที่จุดสีแดงที่อยู่ห่างจากจุดกำเนิดมีค่า z สูงกว่า การพล็อตจุดเหล่านี้เทียบกับค่า z ทำให้เราได้การจัดประเภทที่ชัดเจนซึ่งสามารถแบ่งตามขอบเขตการตัดสินใจเชิงเส้นได้ดังที่แสดงไว้
นี่เป็นแนวคิดที่มีประสิทธิภาพที่ใช้ใน Support Vector Machines โดยทั่วไปแล้ว เป็นแนวคิดในการแมปมิติข้อมูลเป็นมิติข้อมูลจำนวนมากขึ้น เพื่อให้สามารถแยกจุดข้อมูลได้ด้วยขอบเขตเชิงเส้น ฟังก์ชันที่รับผิดชอบนี้คือฟังก์ชันเคอร์เนล มีฟังก์ชันเคอร์เนลมากมาย เช่น ซิกมอยด์ เชิงเส้น ไม่ใช่เชิงเส้น และ RBF
เพื่อให้การแมปคุณลักษณะเหล่านี้มีประสิทธิภาพมากขึ้น SVM ใช้เคล็ดลับเคอร์เนล
SVM ในการเรียนรู้ของเครื่อง
Support Vector Machine เป็นหนึ่งในอัลกอริทึมจำนวนมากที่ใช้ในการเรียนรู้ของเครื่องควบคู่ไปกับอัลกอริทึมยอดนิยมอย่าง Decision Trees และ Neural Networks เป็นที่ชื่นชอบเพราะทำงานได้ดีกับข้อมูลน้อยกว่าอัลกอริทึมอื่น ๆ นิยมใช้ทำดังนี้
- การจัดประเภทข้อความ : การจัดประเภทข้อมูลข้อความ เช่น ความคิดเห็นและบทวิจารณ์เป็นหนึ่งหมวดหมู่หรือมากกว่านั้น
- การ ตรวจจับใบหน้า : วิเคราะห์ภาพเพื่อตรวจจับใบหน้าเพื่อทำสิ่งต่างๆ เช่น เพิ่มฟิลเตอร์สำหรับความเป็นจริงเสริม
- การจำแนกรูปภาพ : เครื่องเวกเตอร์ที่รองรับสามารถจำแนกรูปภาพได้อย่างมีประสิทธิภาพเมื่อเทียบกับวิธีอื่นๆ
ปัญหาการจำแนกข้อความ
อินเทอร์เน็ตเต็มไปด้วยข้อมูลที่เป็นข้อความจำนวนมาก อย่างไรก็ตาม ข้อมูลส่วนใหญ่นี้ไม่มีโครงสร้างและไม่มีป้ายกำกับ หากต้องการใช้ข้อมูลข้อความนี้ได้ดีขึ้นและเข้าใจมากขึ้น จำเป็นต้องมีการจัดหมวดหมู่ ตัวอย่างของเวลาที่มีการจัดประเภทข้อความ ได้แก่:
- เมื่อทวีตถูกจัดหมวดหมู่เป็นหัวข้อเพื่อให้ผู้คนสามารถติดตามหัวข้อที่ต้องการได้
- เมื่ออีเมลถูกจัดประเภทเป็นโซเชียล โปรโมชัน หรือสแปม
- เมื่อความคิดเห็นจัดอยู่ในประเภทแสดงความเกลียดชังหรือหยาบคายในฟอรัมสาธารณะ
SVM ทำงานอย่างไรกับการจำแนกประเภทภาษาธรรมชาติ
Support Vector Machine ใช้เพื่อจำแนกข้อความเป็นข้อความที่อยู่ในหัวข้อเฉพาะและข้อความที่ไม่อยู่ในหัวข้อ สิ่งนี้ทำได้โดยการแปลงและแสดงข้อมูลข้อความเป็นชุดข้อมูลที่มีคุณสมบัติหลายอย่าง
วิธีหนึ่งในการทำเช่นนี้คือการสร้างคุณสมบัติสำหรับทุกคำในชุดข้อมูล จากนั้นสำหรับทุกจุดข้อมูลข้อความ คุณจะบันทึกจำนวนครั้งที่แต่ละคำเกิดขึ้น ดังนั้น สมมติว่ามีคำเฉพาะเกิดขึ้นในชุดข้อมูล คุณจะมีคุณสมบัติในชุดข้อมูล
นอกจากนี้ คุณจะจัดประเภทสำหรับจุดข้อมูลเหล่านี้ แม้ว่าการจำแนกประเภทเหล่านี้จะมีป้ายกำกับเป็นข้อความ การใช้งาน SVM ส่วนใหญ่คาดว่าจะมีป้ายกำกับที่เป็นตัวเลข
ดังนั้นคุณจะต้องแปลงป้ายกำกับเหล่านี้เป็นตัวเลขก่อนการฝึก เมื่อเตรียมชุดข้อมูลแล้ว โดยใช้คุณสมบัติเหล่านี้เป็นพิกัด คุณจะสามารถใช้โมเดล SVM เพื่อจัดประเภทข้อความได้
การสร้าง SVM ใน Python
ในการสร้าง support vector machine (SVM) ใน Python คุณสามารถใช้คลาส SVC จากไลบรารี sklearn.svm นี่คือตัวอย่างของวิธีใช้คลาส SVC เพื่อสร้างโมเดล SVM ใน Python:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) ในตัวอย่างนี้ เรานำเข้าคลาส SVC จากไลบรารี sklearn.svm ก่อน จากนั้น เราจะโหลดชุดข้อมูลและแบ่งออกเป็นชุดการฝึกและชุดทดสอบ
ต่อไป เราสร้างแบบจำลอง SVM โดยการสร้างอินสแตนซ์ของวัตถุ SVC และระบุพารามิเตอร์ kernel เป็น 'เชิงเส้น' จากนั้นเราฝึกโมเดลบนข้อมูลการฝึกโดยใช้วิธีการ fit และประเมินโมเดลบนข้อมูลทดสอบโดยใช้วิธีการ score วิธีการ score ส่งคืนความถูกต้องของแบบจำลองซึ่งเราพิมพ์ไปยังคอนโซล
คุณยังสามารถระบุพารามิเตอร์อื่นๆ สำหรับอ็อบเจ็กต์ SVC เช่น พารามิเตอร์ C ซึ่งควบคุมความแรงของการทำให้เป็นมาตรฐาน และพารามิเตอร์ gamma ซึ่งควบคุมค่าสัมประสิทธิ์เคอร์เนลสำหรับเคอร์เนลบางตัว
ประโยชน์ของ SVM
นี่คือรายการประโยชน์ของการใช้เครื่องเวกเตอร์สนับสนุน (SVMs):
- มีประสิทธิภาพ : โดยทั่วไป SVM มีประสิทธิภาพในการฝึกอบรม โดยเฉพาะอย่างยิ่งเมื่อจำนวนตัวอย่างมีจำนวนมาก
- ทนทานต่อเสียงรบกวน : SVM ค่อนข้างทนทานต่อเสียงรบกวนในข้อมูลการฝึกอบรมเนื่องจากพยายามหาตัวแยกประเภทระยะขอบสูงสุด ซึ่งมีความไวต่อเสียงรบกวนน้อยกว่าตัวแยกประเภทอื่นๆ
- หน่วยความจำที่มีประสิทธิภาพ: SVM ต้องการเพียงชุดย่อยของข้อมูลการฝึกให้อยู่ในหน่วยความจำ ณ เวลาใดเวลาหนึ่ง ทำให้หน่วยความจำมีประสิทธิภาพมากกว่าอัลกอริทึมอื่นๆ
- มีประสิทธิภาพในพื้นที่ที่มีมิติสูง: SVM ยังคงทำงานได้ดีแม้ว่าจำนวนคุณลักษณะจะเกินจำนวนตัวอย่างก็ตาม
- ความสามารถรอบด้าน : SVM สามารถใช้สำหรับการจำแนกประเภทและการถดถอย และสามารถจัดการข้อมูลประเภทต่างๆ รวมถึงข้อมูลเชิงเส้นและไม่เป็นเชิงเส้น
ตอนนี้ เรามาสำรวจแหล่งข้อมูลที่ดีที่สุดในการเรียนรู้ Support Vector Machine (SVM)

แหล่งเรียนรู้
ความรู้เบื้องต้นเกี่ยวกับการสนับสนุน Vector Machines
หนังสือเกี่ยวกับ Introduction to Support Vector Machines เล่มนี้จะแนะนำวิธีการเรียนรู้แบบใช้เคอร์เนลอย่างค่อยเป็นค่อยไป
| ดูตัวอย่าง | ผลิตภัณฑ์ | คะแนน | ราคา | |
|---|---|---|---|---|
 | บทนำเกี่ยวกับการสนับสนุน Vector Machines และวิธีการเรียนรู้ตามเคอร์เนลอื่นๆ | $75.00 | ซื้อในอเมซอน |
ช่วยให้คุณมีรากฐานที่มั่นคงเกี่ยวกับทฤษฎี Support Vector Machines
รองรับแอพพลิเคชั่น Vector Machines
แม้ว่าหนังสือเล่มแรกจะมุ่งเน้นไปที่ทฤษฎีของ Support Vector Machines แต่หนังสือเล่มนี้เกี่ยวกับ Support Vector Machines Applications จะมุ่งเน้นไปที่การใช้งานจริง
| ดูตัวอย่าง | ผลิตภัณฑ์ | คะแนน | ราคา | |
|---|---|---|---|---|
 | รองรับแอพพลิเคชั่น Vector Machines | $15.52 | ซื้อในอเมซอน |
โดยจะดูว่า SVM ใช้ในการประมวลผลภาพ การตรวจจับรูปแบบ และการมองเห็นของคอมพิวเตอร์อย่างไร
สนับสนุน Vector Machines (วิทยาการข้อมูลและสถิติ)
วัตถุประสงค์ของหนังสือเล่มนี้เกี่ยวกับ Support Vector Machines (สารสนเทศศาสตร์และสถิติ) คือการให้ภาพรวมของหลักการที่อยู่เบื้องหลังประสิทธิภาพของ Support Vector Machines (SVM) ในการใช้งานต่างๆ
| ดูตัวอย่าง | ผลิตภัณฑ์ | คะแนน | ราคา | |
|---|---|---|---|---|
 | สนับสนุน Vector Machines (วิทยาการข้อมูลและสถิติ) | $167.36 | ซื้อในอเมซอน |
ผู้เขียนเน้นปัจจัยหลายประการที่นำไปสู่ความสำเร็จของ SVM รวมถึงความสามารถในการทำงานได้ดีด้วยพารามิเตอร์ที่ปรับได้ในจำนวนจำกัด ความต้านทานต่อข้อผิดพลาดและความผิดปกติประเภทต่างๆ และประสิทธิภาพการคำนวณที่มีประสิทธิภาพเมื่อเทียบกับวิธีอื่นๆ
เรียนรู้กับเมล็ดพืช
“การเรียนรู้ด้วยเคอร์เนล” เป็นหนังสือที่แนะนำผู้อ่านเกี่ยวกับการสนับสนุนเครื่องเวคเตอร์ (SVM) และเทคนิคเคอร์เนลที่เกี่ยวข้อง
| ดูตัวอย่าง | ผลิตภัณฑ์ | คะแนน | ราคา | |
|---|---|---|---|---|
 | การเรียนรู้ด้วยเคอร์เนล: รองรับ Vector Machines, Regularization, Optimization และอื่นๆ (Adaptive... | $80.00 | ซื้อในอเมซอน |
ได้รับการออกแบบมาเพื่อให้ผู้อ่านมีความเข้าใจพื้นฐานเกี่ยวกับคณิตศาสตร์และความรู้ที่จำเป็นในการเริ่มใช้อัลกอริทึมเคอร์เนลในการเรียนรู้ของเครื่อง หนังสือเล่มนี้มีจุดมุ่งหมายเพื่อให้ความรู้เบื้องต้นอย่างละเอียดเกี่ยวกับ SVM และวิธีการเคอร์เนล
สนับสนุน Vector Machines ด้วย Sci-kit Learn
หลักสูตร Support Vector Machines พร้อม Sci-kit Learn ออนไลน์นี้โดยเครือข่ายโครงการ Coursera สอนวิธีใช้โมเดล SVM โดยใช้ไลบรารีการเรียนรู้ของเครื่องยอดนิยม Sci-Kit Learn

นอกจากนี้ คุณจะได้เรียนรู้ทฤษฎีเบื้องหลัง SVM และพิจารณาจุดแข็งและข้อจำกัดของ SVM หลักสูตรนี้เป็นระดับเริ่มต้นและใช้เวลาประมาณ 2.5 ชั่วโมง
รองรับ Vector Machines ใน Python: แนวคิดและรหัส
หลักสูตรออนไลน์แบบชำระเงินเกี่ยวกับ Support Vector Machines ใน Python โดย Udemy มีการสอนผ่านวิดีโอนานถึง 6 ชั่วโมงและมาพร้อมกับใบรับรอง

ครอบคลุม SVM และวิธีการนำไปใช้อย่างมั่นคงใน Python นอกจากนี้ยังครอบคลุมการใช้งานทางธุรกิจของ Support Vector Machines
การเรียนรู้ของเครื่องและ AI: รองรับ Vector Machines ใน Python
ในหลักสูตรการเรียนรู้ของเครื่องและ AI นี้ คุณจะได้เรียนรู้วิธีใช้เครื่องเวกเตอร์สนับสนุน (SVM) สำหรับการใช้งานจริงต่างๆ รวมถึงการจดจำภาพ การตรวจจับสแปม การวินิจฉัยทางการแพทย์ และการวิเคราะห์การถดถอย

คุณจะใช้ภาษาการเขียนโปรแกรม Python เพื่อใช้งานโมเดล ML สำหรับแอปพลิเคชันเหล่านี้
คำสุดท้าย
ในบทความนี้ เราได้เรียนรู้สั้น ๆ เกี่ยวกับทฤษฎีเบื้องหลัง Support Vector Machines เราได้เรียนรู้เกี่ยวกับการประยุกต์ใช้ใน Machine Learning และ Natural Langauge Processing
เรายังเห็นว่าการใช้งานโดยใช้ scikit-learn มีลักษณะอย่างไร นอกจากนี้ เรายังพูดถึงการใช้งานจริงและประโยชน์ของ Support Vector Machines
แม้ว่าบทความนี้จะเป็นเพียงบทนำ แต่แหล่งข้อมูลเพิ่มเติมแนะนำให้ลงรายละเอียดเพิ่มเติม โดยอธิบายเพิ่มเติมเกี่ยวกับ Support Vector Machines ด้วยความอเนกประสงค์และมีประสิทธิภาพ SVM จึงคุ้มค่าที่จะทำความเข้าใจเพื่อเติบโตในฐานะนักวิทยาศาสตร์ข้อมูลและวิศวกร ML
จากนั้น คุณสามารถดูโมเดลแมชชีนเลิร์นนิงยอดนิยม