
วิธีที่ถูกต้องในการ Noindex หน้า
เผยแพร่แล้ว: 2022-12-02อาจดูขัดกับสัญชาตญาณ แต่ไม่ใช่ว่าทุกหน้าในเว็บไซต์ของคุณควรจะปรากฏในผลการค้นหา การปรับแต่งเว็บไซต์ให้ติดอันดับบนเครื่องมือการค้นหา (SEO) มุ่งมั่นที่จะเพิ่มการมองเห็นการค้นหาและการเข้าชมทั่วไป — และบางครั้ง คุณสามารถบรรลุเป้าหมายนั้นได้ดีที่สุดโดยการจำกัดเนื้อหาที่สามารถปรากฏในผลการค้นหา
หากคุณกำลังเกาหัวของคุณหรือเรียกฉันว่าบลัฟ โปรดอ่านต่อเพื่อค้นหาคุณค่าของการจัดทำดัชนีหน้าหรือไดเรกทอรีย่อยและวิธีใช้แท็ก noindex
Noindex หมายถึงอะไร?
คำว่า “noindex” คือคำสั่งพิเศษในเมตาแท็กของโรบ็อตที่บอกให้โปรแกรมรวบรวมข้อมูลค้นหาแยกหน้านั้นออกจากหน้าผลลัพธ์ของเครื่องมือค้นหา (SERP) ซึ่งหมายความว่าผู้ค้นหาจะไม่สามารถเข้าถึงเพจผ่านการค้นหาได้
เมตาแท็กของโรบ็อตเป็นส่วนสำคัญของกลยุทธ์ SEO ทางเทคนิค ช่วยให้คุณสามารถยกเว้นหน้าที่ไม่ให้คุณค่าแก่ผู้ค้นหาหรือที่เก็บข้อมูลที่คุณไม่ต้องการให้ปรากฏในผลการค้นหา เช่น:
- หน้ายืนยันและขอบคุณ
- หน้าเข้าสู่ระบบ
- หน้านโยบายความเป็นส่วนตัวหรือข้อกำหนดในการให้บริการ
- เนื้อหาที่มีรั้วรอบขอบชิด
- ข้อความแสดงข้อผิดพลาด
Robots Meta Tag กับ Robots.txt กับ X-Robots Tag
เมตาแท็กของ Robots มักจะสับสนกับไฟล์ robots.txt และแท็ก x-robots ทั้งสามให้คำแนะนำในการค้นหาโปรแกรมรวบรวมข้อมูลเกี่ยวกับหน้าเว็บและเป็นส่วนหนึ่งของโปรโตคอลการยกเว้นโรบ็อต (REP) พูดง่ายๆ ก็คือ พวกเขาบอก Google ว่าควรใส่อะไรลงใน Google Search และอะไรที่ควรหลีกเลี่ยง รวมทั้งหน้าใดที่พวกเขาควรรวบรวมข้อมูล อย่างไรก็ตาม ไม่สามารถและไม่ควรใช้แทนกันได้
เมตาแท็กของหุ่นยนต์
เมตาแท็กของโรบ็อตถูกเพิ่มลงในส่วน <head> ของหน้าเว็บหนึ่งๆ และส่งเฉพาะคำแนะนำเกี่ยวกับหน้านั้นเท่านั้น มักเรียกว่าแท็ก noindex หรือเมตาแท็ก noindex เมตาแท็กของโรบ็อตทำได้มากกว่าแค่บอกโปรแกรมรวบรวมข้อมูลการค้นหาว่าไม่ต้องจัดทำดัชนีหน้า
นอกจากนี้ยังสามารถใช้เพื่อขอให้โปรแกรมรวบรวมข้อมูลไม่ติดตามลิงก์ แปลหน้า บล็อกบอทค้นหาเฉพาะ หรือป้องกันไม่ให้ลิงก์แคชปรากฏใน SERP
คำสั่งเมตาแท็กของโรบ็อตทั่วไปประกอบด้วย:
- Noindex, nofollow — <meta name=”robots” content=”noindex, nofollow”>
Googlebot และโปรแกรมรวบรวมข้อมูลเว็บอื่นๆ สามารถเข้าถึงหน้าเว็บได้ แต่ไม่ควรจัดทำดัชนีหรือติดตามลิงก์ - Noindex ติดตาม — <meta name=”robots” content=”noindex”>
Googlebot และโปรแกรมรวบรวมข้อมูลเว็บอื่นๆ อาจเข้าถึงหน้าเว็บและติดตามลิงก์ในหน้านั้น แต่ไม่ควรจัดทำดัชนีหน้านั้น คุณไม่จำเป็นต้องใส่ "ติดตาม" ในเมตาแท็กเนื่องจากเป็นค่าเริ่มต้น
โรบอท.txt
Robots.txt เป็นไฟล์ที่ช่วยให้เจ้าของไซต์สามารถบอกเครื่องมือค้นหาว่าไม่ต้องการให้รวบรวมข้อมูลส่วนใดของไซต์ของตน เป็นเหมือนสัญลักษณ์ห้ามรบกวนส่วนตัวสำหรับเว็บไซต์ของคุณที่แฮงเอาท์ในไดเร็กทอรีรากของโดเมนหรือโดเมนย่อยของคุณ
ไฟล์ robots.txt เหมาะที่สุดสำหรับการบล็อกไดเรกทอรีย่อยทั้งหมดไม่ให้เข้าถึงและรวบรวมข้อมูล แทนที่จะบล็อกแต่ละหน้า ใช้เพื่อบล็อกโปรแกรมรวบรวมข้อมูลการค้นหาไม่ให้เข้าถึงและจัดทำดัชนี:
- หน้าค้นหาภายใน
- พารามิเตอร์ URL
- ฟอรัมที่สแปมที่ผู้ใช้สร้างขึ้นอาจทำให้เกิดปัญหาได้
- ไดเร็กทอรีย่อยภายใน เช่น ไดเร็กทอรีย่อยสำหรับพนักงานเท่านั้น
ทำตามขั้นตอนเหล่านี้เพื่อสร้างไฟล์ robots.txt และอย่าลืมลิงก์ไปยังแผนผังไซต์ XML ของคุณ
หากคุณลิงก์ไปยังหน้าที่รวมอยู่ในไฟล์ robots.txt คุณอาจต้องการเพิ่มเมตาแท็กของโรบ็อตในหน้านั้นด้วยเพื่อให้แน่ใจว่าหน้านั้นจะไม่ปรากฏในผลการค้นหา ข้อควรจำ — robots.txt บล็อกเฉพาะโปรแกรมรวบรวมข้อมูลไม่ให้เข้าถึงหน้าเว็บ ไม่ใช่จากการจัดทำดัชนี หากหน้าที่อยู่ภายใต้คำสั่ง robots.txt ของคุณได้รับลิงก์ภายนอก เครื่องมือค้นหาอาจจัดทำดัชนีลิงก์เหล่านั้น ใช้เมตาแท็กของ robots ร่วมกับไฟล์ robots.txt เพื่อหลีกเลี่ยงปัญหานี้
แท็ก X-Robots
หากต้องการบล็อก PDF วิดีโอ หรือรูปภาพไม่ให้ปรากฏใน SERP ให้ใช้แท็ก x-robots คำสั่งเดียวกันที่ระบุสำหรับเมตาแท็กของโรบ็อตใช้สำหรับ x-robot อย่างไรก็ตาม ไม่เหมือนกับเมตาแท็กของโรบ็อตซึ่งอยู่ในส่วนหัว HTML ของหน้า แท็ก x-robots จะอยู่ในการตอบสนองของส่วนหัว HTTP
คำสั่งมีลักษณะดังนี้:
X-Robots-Tag: noindexเมื่อต้องการ Noindex หน้า
ระงับการขยายตัวของดัชนี
การขยายตัวของดัชนีเกิดขึ้นเมื่อ Google จัดทำดัชนีหน้าเว็บที่มีค่าเพียงเล็กน้อยหรือไม่มีเลยสำหรับผู้ค้นหา เพจที่ไม่เกี่ยวข้องเหล่านี้ลดทรัพยากรจากเพจที่มีค่ามากกว่า ใช้เมตาแท็กของโรบ็อตเพื่อจัดการหน้าที่ปรากฏในผลการค้นหา
กำจัดการใช้คำหลักร่วมกัน
การกินคำหลักเกิดขึ้นเมื่อสองหน้าใช้คำหลักและจุดประสงค์ในการค้นหาที่คล้ายคลึงกัน ด้วยเหตุนี้จึงทำให้พวกเขาแข่งขันกันเองใน SERPs
หากคุณมีสองเพจที่แย่งชิงกันและกันและต้องการเก็บทั้งสองไว้โดยไม่เปลี่ยนเนื้อหา ให้ noindex หนึ่งหน้า กล่าวคือ คุณควรดำเนินการนี้เฉพาะเมื่อหน้าเว็บที่คุณกำลังจัดทำดัชนีไม่ได้ดึงดูดการเข้าชมจากคำหลักซึ่งอีกหน้าหนึ่งไม่ทำ ในสถานการณ์เช่นนี้ คุณอาจต้องปรับปรุงเนื้อหาในหน้าใดหน้าหนึ่งหรือทั้งสองหน้าเพื่อแก้ปัญหาการกินกันร่วมกัน
ปกป้องแลนดิ้งเพจ Gated
เมื่อคุณเสนอทรัพยากรที่มีมูลค่าสูงแก่ลูกค้าเพื่อแลกกับข้อมูลติดต่อ ตรวจสอบให้แน่ใจว่าไม่สามารถเข้าถึงได้ด้วยวิธีอื่น เพิ่มเมตาแท็กของโรบ็อตเพื่อไม่จัดทำดัชนีหน้าและป้องกันไม่ให้ปรากฏใน SERP
ยกเว้นผลิตภัณฑ์ที่ไม่เป็นที่นิยมจากการค้นหา
ไซต์อีคอมเมิร์ซมักจะมีผลิตภัณฑ์เพื่อให้บริการลูกค้าบางรายแม้ว่าจะไม่มีความต้องการมากเกินไปก็ตาม ตัวอย่างเช่น ผู้ค้าปลีกชิ้นส่วนรถยนต์หรือบริษัทด้านเทคนิคอื่นๆ อาจมีผลิตภัณฑ์สำหรับรุ่นเฉพาะหรืออุปกรณ์ที่หายาก หากหน้าผลิตภัณฑ์หรือหมวดหมู่เหล่านี้ไม่ได้กระตุ้นการเข้าชมแบบออร์แกนิก โดยทั่วไปแล้วจะไม่มีการจัดทำดัชนี
วิธี Noindex หน้าเว็บ
เมตาแท็ก noindex จะอยู่ที่ส่วนหัวของ HTML ของหน้า รหัสไม่คำนึงถึงขนาดตัวพิมพ์และมีลักษณะดังนี้:
<meta name="robots" content="noindex">“โรบ็อต” หมายถึงคำสั่งที่ใช้กับโปรแกรมรวบรวมข้อมูลใดๆ แต่คุณสามารถเลือกโปรแกรมรวบรวมข้อมูลได้โดยการแทนที่ "หุ่นยนต์" ด้วยชื่อโปรแกรมรวบรวมข้อมูลที่รู้จัก เช่น "Googlebot" หรือ "bingbot"

โปรแกรมรวบรวมข้อมูลจะยังคงติดตามลิงก์ในหน้านั้น เว้นแต่คุณจะเพิ่มคำสั่ง nofollow ด้วย คุณอาจทำเช่นนี้เพื่อป้องกันไม่ให้ส่วนของลิงก์ไหลผ่านหน้าหรือเพื่อป้องกันไม่ให้โปรแกรมรวบรวมข้อมูลติดตามลิงก์ไปยังเนื้อหาที่มีรั้วรอบขอบชิด
หากต้องการเพิ่มค่า nofollow ให้แยกค่านั้นออกจากคำสั่ง noindex ด้วยเครื่องหมายจุลภาค
<meta name="robots" content="noindex, nofollow">หมายเหตุ: ก่อนที่จะไม่จัดทำดัชนีหน้า ให้ตรวจสอบว่ามีการเข้าชมแบบออร์แกนิกเข้ามาใน Google Search Console หรือไม่ ถ้าเป็นเช่นนั้น ให้พิจารณาว่าไซต์ของคุณสามารถจับการเข้าชมนี้ต่อไปได้อย่างไรก่อนที่จะไม่จัดทำดัชนีหน้านี้
วิธีเพิ่มเมตาแท็กของ Robots ในโค้ด HTML ของคุณ
- เปิดซอร์สโค้ดของเพจที่คุณต้องการทำดัชนี
- ค้นหาส่วนหัวที่ด้านบนของหน้า ขึ้นต้นด้วย <head> และลงท้ายด้วย </head> น่าจะมีโค้ดอื่นในส่วนหัวด้วย
- เพิ่มเมตาแท็กของโรบ็อตในบรรทัดใหม่ ตรวจสอบให้แน่ใจว่าปรากฏอยู่ระหว่างแท็ก <head> และ </head>
แค่นั้นแหละ! หากหน้าเว็บของคุณได้รับการจัดทำดัชนีแล้ว คุณสามารถขอให้ Google รวบรวมข้อมูลอีกครั้งโดยวาง URL ของหน้านั้นลงในเครื่องมือตรวจสอบ URL
จัดทำดัชนีแล้ว? ใช้เครื่องมือลบ URL
เมื่อคุณเพิ่มแท็ก noindex ในหน้าเนื้อหาใหม่ Googlebot จะเห็นคำสั่งเมื่อรวบรวมข้อมูลหน้านั้น และจะไม่จัดทำดัชนีหน้านั้น
อย่างไรก็ตาม หากคุณเพิ่มแท็กลงในหน้าเว็บที่มีการ จัดทำดัชนีแล้ว หน้าดังกล่าวจะยังคงปรากฏในผลการค้นหาต่อไปจนกว่าจะมีการรวบรวมข้อมูลอีกครั้ง และบอทจะเห็นคำสั่ง noindex ใหม่ คุณสามารถขอให้ Google รวบรวมข้อมูล URL อีกครั้งใน Google Search Console ผ่านเครื่องมือตรวจสอบ URL แต่จะไม่ลบหน้านั้นออกจาก SERP ทันที
หากคุณต้องการลบหน้าออกจาก SERP ทันที ให้ใช้เครื่องมือลบใน Google Search Console วิธีนี้จะทำให้หน้าเว็บไม่อยู่ในผลการค้นหาของ Google ประมาณหกเดือน เมื่อถึงตอนนั้น เมตาแท็ก noindex ควรใช้งานได้
วิธี Noindex หน้าบน WordPress
ทุกหน้าใน WordPress ได้รับการจัดทำดัชนีตามค่าเริ่มต้น คุณสามารถใช้ปลั๊กอิน Yoast SEO เพื่อ noindex หน้าใน WordPress โดยไม่ต้องเขียนโค้ด นี่คือวิธีการ
คลิกแท็บ 'ขั้นสูง' ในกล่องเมตา Yoast SEO
ใต้คำถาม 'อนุญาตให้เครื่องมือค้นหาแสดงโพสต์นี้ในผลการค้นหาหรือไม่' เลือก 'ไม่' จากกล่องแบบเลื่อนลง
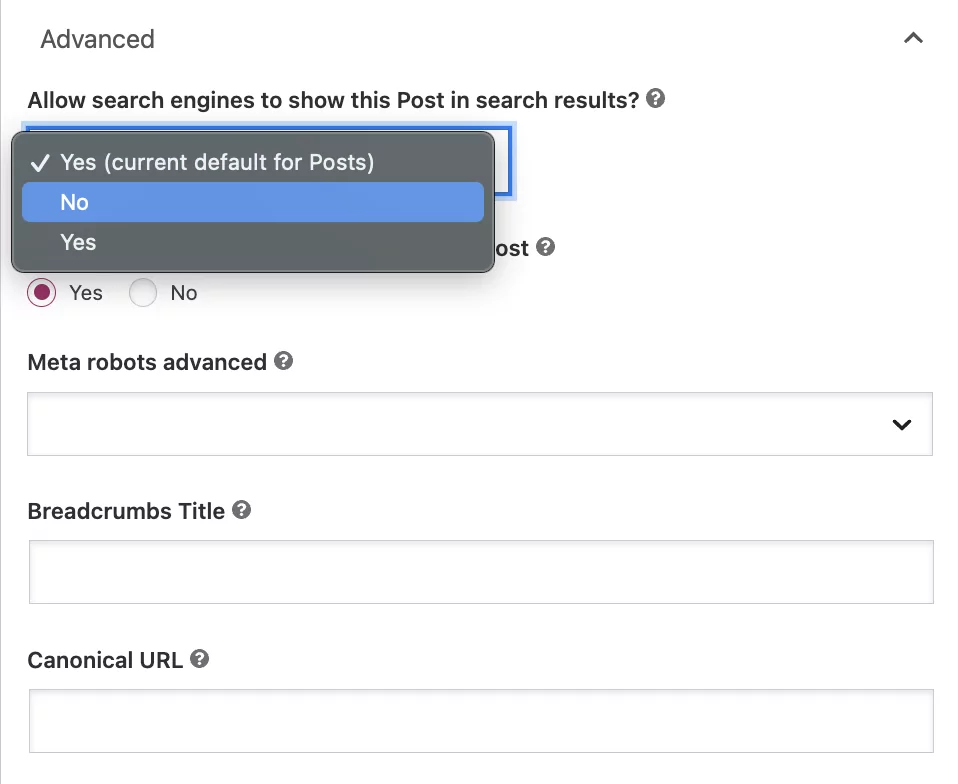
แม้ว่าการตั้งค่านี้จะสั่งให้ Google ไม่ต้องจัดทำดัชนีโพสต์ แต่บอทจะยังคงติดตามลิงก์ในหน้านั้นโดยอัตโนมัติเพื่อรวบรวมข้อมูลหน้าอื่นๆ
หากคุณต้องการเพิ่มคำสั่ง nofollow ให้เลือกปุ่ม 'ไม่' ใต้คำถาม: 'เครื่องมือค้นหาควรติดตามลิงก์ในโพสต์นี้หรือไม่'
คำถามที่พบบ่อยเกี่ยวกับเมตาแท็กของ Robots
เครื่องมือค้นหาทั้งหมดปฏิบัติตามคำสั่ง noindex หรือไม่
คุณสามารถคาดหวังว่า Google, Bing และเครื่องมือค้นหาที่ถูกต้องตามกฎหมายอื่นๆ จะปฏิบัติตามเมตาแท็กของโรบ็อต
ฉันสามารถเชื่อมโยงไปยังหน้าที่ไม่มีการจัดทำดัชนีได้หรือไม่
ใช่. แท็ก noindex จะบอกบอทการค้นหาว่าควรปฏิบัติต่อหน้าเว็บอย่างไรเมื่อรวบรวมข้อมูลและจัดทำดัชนี ไม่ส่งผลต่อความสามารถในการเชื่อมโยงไปยังเพจ สิ่งนี้มีประโยชน์สำหรับหน้าหมวดหมู่ในบล็อก ซึ่งไม่ควรแสดงในผลการค้นหา แต่สามารถให้บอทที่มีลิงก์ไปยังหน้าที่มีค่าที่ควร
ฉันควรใช้เมตาแท็กของโรบ็อตเมื่อใด
หากคุณมีหน้าเว็บที่ไม่ได้ให้คุณค่าใดๆ แก่ผู้ค้นหา เช่น หน้าขอบคุณหรือหน้าที่เป็นมิตรต่อการพิมพ์ ให้จัดทำดัชนีหน้านั้นด้วยเมตาแท็กของโรบ็อตเพื่อป้องกันไม่ให้ปรากฏใน SERP
เมื่อใดที่ฉันไม่ควรใช้คำสั่ง noindex
ในทางเทคนิค คุณสามารถแก้ปัญหาเนื้อหาที่ซ้ำกันและปัญหางบประมาณในการรวบรวมข้อมูลบางอย่างได้ด้วยคำสั่ง noindex แต่นี่ไม่ใช่วิธีที่ดีที่สุด เนื้อหาที่ซ้ำกันจะจัดการได้ดีที่สุดโดยใช้แท็กตามรูปแบบบัญญัติ ซึ่งรวมส่วนของลิงก์จากเนื้อหาที่ซ้ำกันไปยังหน้าตามรูปแบบบัญญัติ หากคุณพยายามประหยัดงบประมาณในการรวบรวมข้อมูล คุณควรใช้ไฟล์ robots.txt เพื่อไม่อนุญาตให้รวบรวมข้อมูลส่วนนั้นของไซต์
เพจที่ไม่มีการจัดทำดัชนีจะส่งส่วนของลิงก์หรือไม่
ใช่. แม้ว่าเพจจะไม่ได้รับการจัดทำดัชนี แต่เพจนั้นยังสามารถแบ่งปันอำนาจการจัดอันดับที่สร้างขึ้นได้ อย่างไรก็ตาม โปรแกรมรวบรวมข้อมูลการค้นหาต้องมีความสามารถในการติดตามลิงก์ในหน้าเพื่อให้ส่วนของลิงก์ไหลผ่าน หากเพจถูกตั้งค่าเป็น noindex และ nofollow เพจนั้นจะไม่สามารถส่งส่วนของลิงค์ได้
การทำดัชนีหน้าจะลบออกจาก Google SERPs โดยอัตโนมัติหรือไม่
หากหน้าเว็บของคุณได้รับการจัดทำดัชนีแล้ว การเพิ่มเมตาแท็กของโรบ็อตจะไม่ทำให้หน้านั้นหยุดทำงานโดยอัตโนมัติจากผลการค้นหา ต้องใช้เวลาสักระยะกว่าเพจที่มีการจัดทำดัชนีจะหายไปจาก SERP บอทค้นหาจำเป็นต้องรวบรวมข้อมูลหน้าใหม่เพื่อดูแท็ก noindex เพื่อผลลัพธ์ที่เร็วขึ้น โปรดขอให้ Google รวบรวมข้อมูลหน้าอีกครั้งและใช้เครื่องมือลบ URL
ค้นพบหน้าที่มีปัญหาด้วยการตรวจสอบ SEO
อย่าให้เนื้อหาบางหรือซ้ำกันส่งผลกระทบต่อการมองเห็นการค้นหาของคุณ ตรวจสอบให้แน่ใจว่าคุณให้โอกาสที่ดีที่สุดแก่หน้าเว็บของคุณในการจัดอันดับ การตรวจสอบ SEO 200+ จุดของเราจะแจ้งปัญหาต่างๆ เช่น เนื้อหาที่ซ้ำกัน, ไฟล์ robots.txt ที่ขาดหายไป, เมตาแท็กของโรบ็อตที่ใช้ไม่ถูกต้อง, การขยายดัชนี และอื่นๆ ลงทะเบียนเพื่อรับคำปรึกษาด้าน SEO ฟรี เพื่อดูว่าบริการตรวจสอบ SEO ของเราสามารถเพิ่มการมองเห็นทางออนไลน์ของคุณให้สูงสุดและช่วยให้ธุรกิจของคุณเติบโตได้อย่างไร