
รับประโยชน์สูงสุดจาก Apache Solr: การสำรวจทางเทคนิคของการจัดทำดัชนีการค้นหา
เผยแพร่แล้ว: 2023-02-21คุณลักษณะการค้นหาช่วยเพิ่มประสบการณ์ของผู้ใช้เว็บไซต์โดยช่วยให้ผู้ใช้สามารถค้นหาสิ่งที่ต้องการได้ง่ายและรวดเร็ว ยิ่งไปกว่านั้นสำหรับเว็บไซต์ขนาดใหญ่ ไซต์อีคอมเมิร์ซ และไซต์ที่มีเนื้อหาแบบไดนามิก (ไซต์ข่าว บล็อก)
Apache Solr เป็นหนึ่งในแพลตฟอร์มการค้นหายอดนิยมที่ใช้โดยเว็บไซต์ทุกขนาด เป็นเครื่องมือค้นหาแบบโอเพ่นซอร์สที่ใช้ Java ซึ่งช่วยให้คุณค้นหาข้อมูลจำนวนมาก เช่น บทความ ผลิตภัณฑ์ บทวิจารณ์จากลูกค้า และอื่นๆ ดูข้อมูลเพิ่มเติมเกี่ยวกับ Apache Solr ในบทความนี้
ลองอ่านบทความนี้เพื่อเรียนรู้วิธีกำหนดค่า Apache Solr ใน Drupal

ทำไม Apache Solr ถึงได้รับความนิยม?
Apache Solr นั้นรวดเร็วและยืดหยุ่นและอนุญาตให้ ค้นหาข้อความแบบเต็ม การเน้นการกด (เน้นคำค้นหาที่ตรงกัน) การค้นหาแบบแยกส่วน (การค้นหาที่ละเอียดยิ่งขึ้น) การจัดทำดัชนีตามเวลาจริง (อนุญาตให้สร้างดัชนีเนื้อหาใหม่ได้ทันที) การจัดกลุ่มแบบไดนามิก ( จัดผลการค้นหาเป็นกลุ่ม) การรวมฐานข้อมูล ฟีเจอร์ NoSQL (ฐานข้อมูลที่ไม่ใช่เชิงสัมพันธ์) และ การจัดการเอกสารที่หลากหลาย (เพื่อสร้างดัชนีรูปแบบเอกสารที่หลากหลาย เช่น PDF, MS Office, Open office)
ข้อเท็จจริงที่ควรรู้เกี่ยวกับ Apache Solr:
- ได้รับการพัฒนาในขั้นต้นโดยเครือข่าย CNET, inc. เป็นเครื่องมือค้นหาสำหรับเว็บไซต์และบทความของพวกเขา ต่อมามันเป็นโอเพ่นซอร์สและกลายเป็นโครงการ Apache ระดับบนสุด
- รองรับภาษาโปรแกรมหลายภาษา เช่น PHP, Java, Python และ Ruby นอกจากนี้ยังมี API สำหรับภาษาเหล่านี้
- มีการสนับสนุนการค้นหาเชิงพื้นที่ในตัว ทำให้สามารถค้นหาเนื้อหาตามสถานที่ตั้งได้ มีประโยชน์อย่างยิ่งสำหรับเว็บไซต์ เช่น เว็บไซต์อสังหาริมทรัพย์ เว็บไซต์ท่องเที่ยว เป็นต้น
- รองรับคุณสมบัติการค้นหาขั้นสูง เช่น การตรวจตัวสะกด การเติมข้อความอัตโนมัติ และการค้นหาแบบกำหนดเองผ่าน API และปลั๊กอิน
- ใช้ Lucene สำหรับการจัดทำดัชนีและการค้นหา
ลูซีนคืออะไร
Apache Lucene เป็นไลบรารีการค้นหา Java แบบโอเพ่นซอร์สที่ให้คุณเพิ่มการค้นหาหรือดึงข้อมูลไปยังแอปพลิเคชันได้อย่างง่ายดาย มีความอเนกประสงค์ ทรงพลัง แม่นยำ และทำงานบนอัลกอริธึมการค้นหาที่มีประสิทธิภาพ
แม้ว่าจะรู้จักความสามารถในการค้นหาข้อความแบบเต็ม แต่ Lucene ยังสามารถใช้สำหรับการจำแนกเอกสาร การวิเคราะห์ข้อมูล และการดึงข้อมูล นอกจากนี้ยังรองรับหลายภาษานอกเหนือจากภาษาอังกฤษ เช่น เยอรมัน ฝรั่งเศส สเปน จีน ญี่ปุ่น และอื่น ๆ
การจัดทำดัชนีคืออะไร?
เครื่องมือค้นหาทั้งหมดเริ่มต้นด้วยการจัดทำดัชนี การทำดัชนีคือการประมวลผลข้อมูลต้นฉบับเป็นการค้นหาแบบอ้างอิงโยงที่มีประสิทธิภาพสูงเพื่ออำนวยความสะดวกในการค้นหาอย่างรวดเร็ว
เครื่องมือค้นหาไม่ได้ทำดัชนีข้อมูลโดยตรง ข้อความจะถูกแบ่งออกเป็นโทเค็น (องค์ประกอบปรมาณู) ก่อน การค้นหาคือกระบวนการปรึกษาดัชนีการค้นหาและดึงเอกสารที่ตรงกับคำค้นหา
ข้อดีของการจัดทำดัชนี
- การดึงข้อมูลที่รวดเร็วและแม่นยำ (รวบรวม แยกวิเคราะห์ และจัดเก็บ)
- หากไม่มีการจัดทำดัชนี เครื่องมือค้นหาต้องใช้เวลามากขึ้นในการสแกนเอกสารทุกฉบับ
การไหลของการจัดทำดัชนี
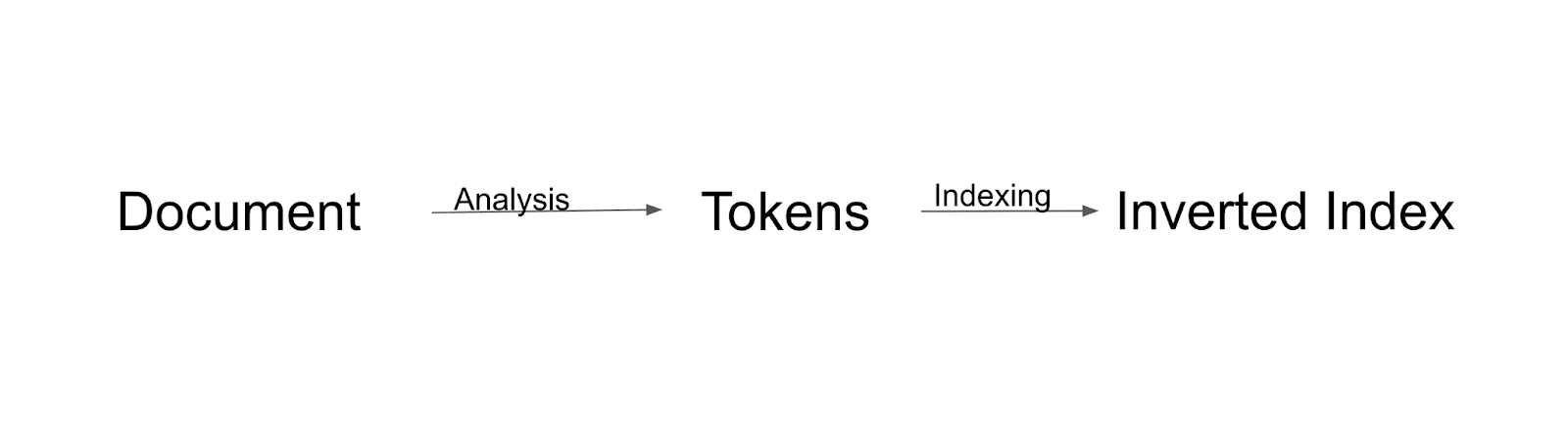
ขั้นแรก เอกสารจะได้รับการวิเคราะห์และแบ่งออกเป็นโทเค็น โทเค็นเหล่านั้นทั้งหมดจะถูกจัดทำดัชนีเป็นดัชนีกลับด้าน Inverted index เป็นวิธีที่ Solr สร้างดัชนี
การจัดทำดัชนีกลับด้านทำงานอย่างไร
ให้พิจารณาว่าเรามีเอกสาร 3 ฉบับ:
- ฉันรักช็อคโกแลต (D 1)
- ฉันสั่งเค้กช็อคโกแลต (D 2)
- ฉันเตรียมเค้กวานิลลาก้อนใหญ่ (D 3)
วิธีโทเค็นดังแสดงในคอลัมน์ที่ 2 ของตารางด้านล่าง

“ช็อกโกแลต” มีอยู่ใน D1 และ D2
“เค้ก” มีให้บริการใน D2 และ D3
“ใหญ่” มีอยู่ใน D3
“สั่งซื้อแล้ว” มีอยู่ใน D2
“เตรียมพร้อม” มีอยู่ใน D3
“วานิลลา” มีอยู่ใน D3
คุณจะสังเกตเห็นว่าคำว่า “ฉัน” และ “ความรัก” นั้นไม่ได้ถูกแปลงเป็นโทเค็น สิ่งเหล่านี้เรียกว่า Stop words ซึ่งจะไม่ถูกจัดทำดัชนีหรือค้นหาโดย Solr
ดังนั้นเมื่อมีคนค้นหาคำว่า "เค้กช็อกโกแลต" เครื่องมือจะดูที่ดัชนี แทนที่จะมองหาเอกสาร ขั้นแรกจะค้นหาดัชนีเพื่อดูว่าเอกสารใดที่มีคำว่า "ช็อกโกแลต" และ "เค้ก" อยู่ภายใต้ ทำให้การดึงข้อมูลเฉพาะเอกสารนั้นง่ายและรวดเร็วขึ้น สิ่งนี้เรียกว่าการทำดัชนีกลับด้าน
สคีมาการจัดเก็บ
Apache Solr ใช้สคีมาการจัดเก็บข้อมูลตามเอกสารและจัดเก็บข้อมูลทุกชิ้นเป็นเอกสารแยกต่างหากภายในคอลเลกชัน ซึ่งช่วยให้สามารถจัดเก็บและเรียกใช้ข้อมูลได้อย่างมีประสิทธิภาพและยืดหยุ่น
ใน Drupal แต่ละโหนดถือเป็นเอกสาร ดังนั้น เมื่อคุณสร้างดัชนีโหนดของคุณเป็น Apache Solr จะถือว่าเป็นเอกสาร เอกสารแต่ละฉบับสามารถมีได้หลายฟิลด์ Lucene ไม่มีสคีมาทั่วไป ซึ่งหมายความว่าคุณสามารถจัดทำดัชนีฟิลด์ประเภทใดก็ได้ในแต่ละเอกสารใน Apache Solr

วิธีการติดตั้ง Apache Solr
- ขั้นแรก ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Java บนระบบของคุณแล้ว
- ต่อไป มาติดตั้ง Solr จากที่นี่: https://solr.apache.org/downloads.html
- ดาวน์โหลดและแตกไฟล์ Solr.
- เรียกใช้คำสั่งนี้ในโฟลเดอร์ Solr
◦ ผลิตภัณฑ์เทคโนโลยี bin/solr -e
สิ่งนี้จะสร้างแกนจำลองสำหรับการสาธิตและจะเริ่มต้นเซิร์ฟเวอร์ Solr ด้วย
- เมื่อเซิร์ฟเวอร์เริ่มทำงาน ให้ไปที่เบราว์เซอร์ของคุณแล้วพิมพ์ “http://localhost:8983/”
- ตรวจสอบให้แน่ใจว่าได้ติดตั้ง Solr ด้วย dummy core เรียบร้อยแล้ว
โครงสร้างไดเรกทอรี
เมื่อคุณติดตั้ง Solr แล้ว คุณจะเห็นโฟลเดอร์มากมายเช่น:
เอกสาร - มีเอกสารประกอบเกี่ยวกับ Solr
Dist - ไฟล์ .jar หลัก Solr
Contrib - มีปลั๊กอินเสริมและคุณสมบัติพิเศษของ Solr
Bin - สคริปต์ของ Solr
ตัวอย่าง - มีการแสดงความสามารถของ Solr
เซิร์ฟเวอร์ - หัวใจของ Solr มีแอปพลิเคชันเว็บ Solr, บันทึก, แกน Solr

ไฟล์กำหนดค่า
ในการสร้างแกนเราต้องการไฟล์สองไฟล์ที่จำเป็น
- Schema.xml
- Solrconfig.xml
Schema.xml
- ซึ่งจะมีประเภทของฟิลด์ที่คุณวางแผนจะรองรับและวิธีวิเคราะห์ประเภทเหล่านั้น
Solrconfig.xml
- มีการตั้งค่าต่างๆ ที่ควบคุมลักษณะการทำงานของแกน Solr เช่น ตัวจัดการคำขอ ตัวจัดการคำขอ ส่วนประกอบการสืบค้น ตัวจัดการการอัปเดต ฯลฯ
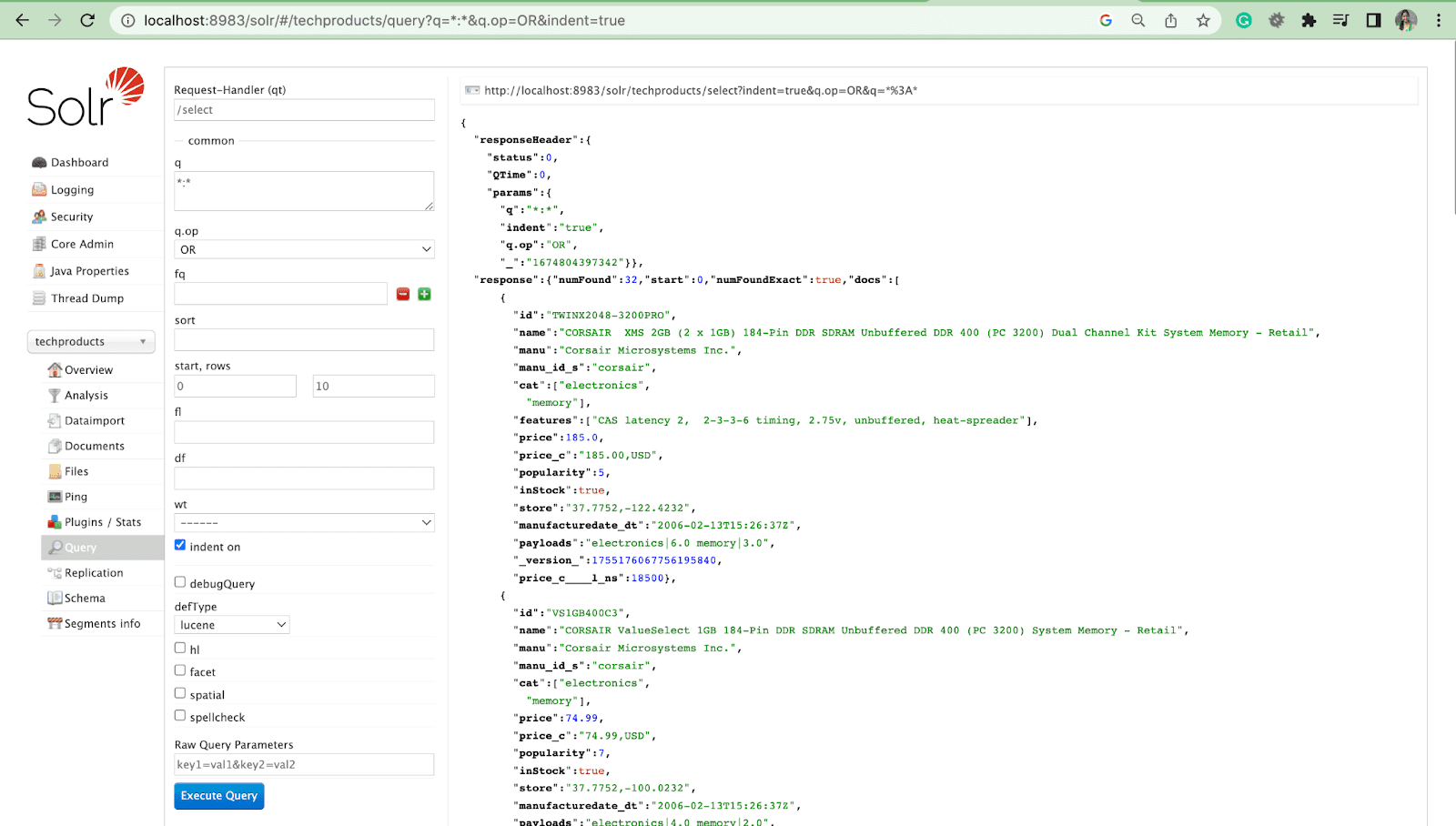
การค้นหาใน Solr
ตอนนี้ให้ดูวิธีการสืบค้นผลลัพธ์ Solr ใน Solr admin UI
พารามิเตอร์แบบสอบถาม
- พารามิเตอร์โลคัลเป็นอาร์กิวเมนต์ในคำขอ Solr ที่เฉพาะเจาะจงกับพารามิเตอร์เคียวรี
ตัวอย่างเช่น: แมว: อิเล็กทรอนิกส์
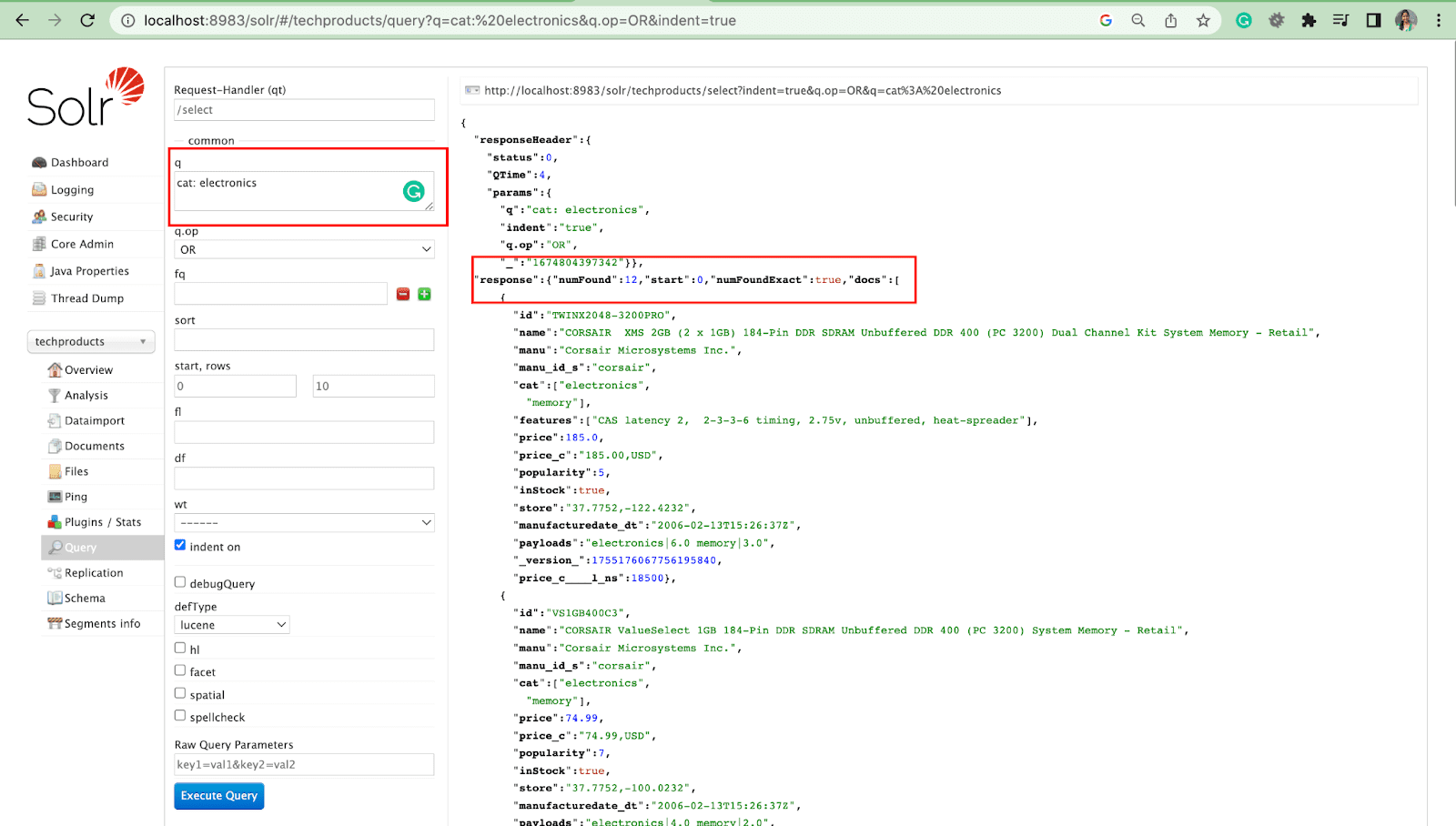
พารามิเตอร์แบบสอบถามพร้อมการดำเนินการ
- เราสามารถสอบถามหลายฟิลด์ด้วยการดำเนินการ
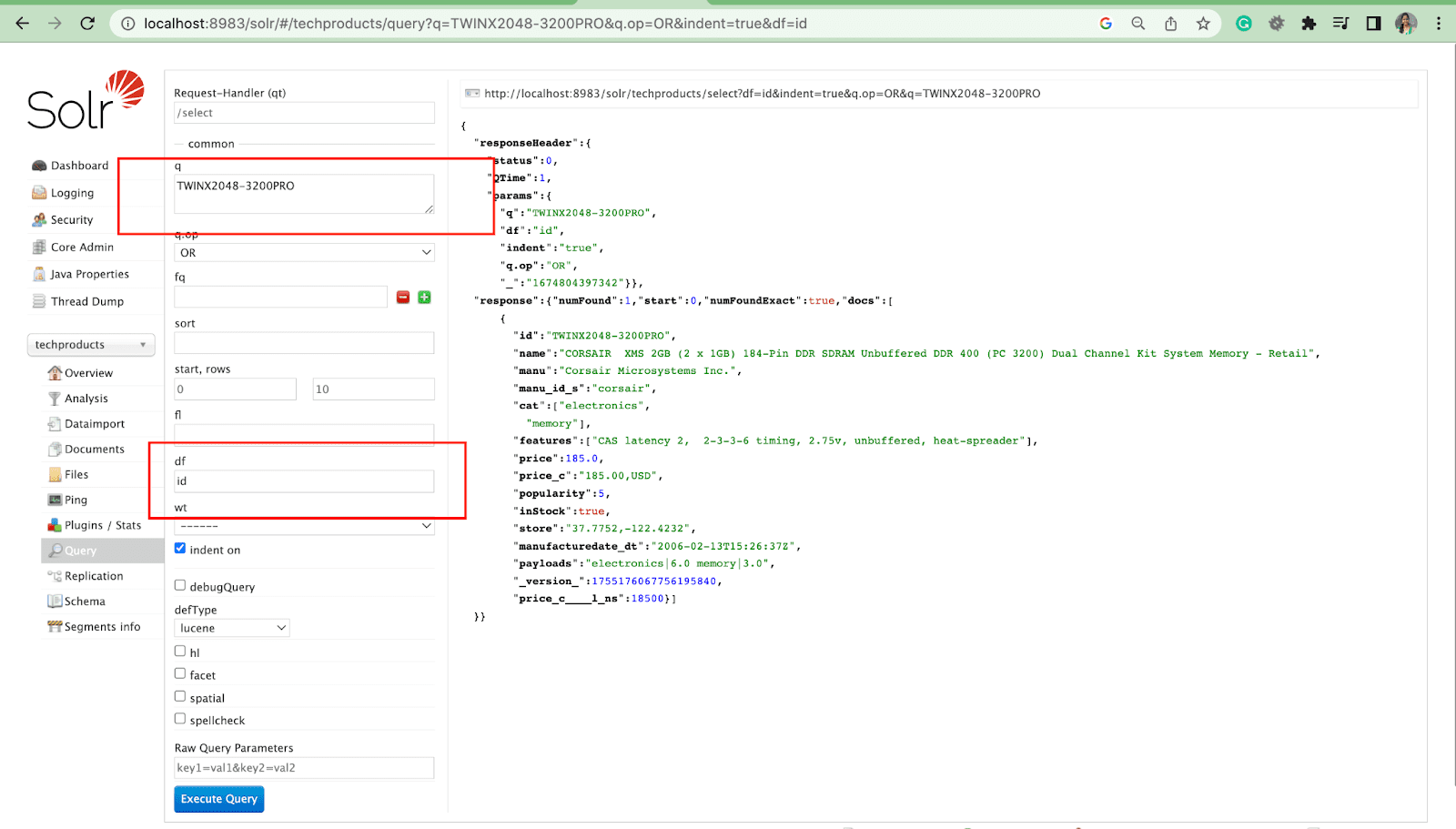
ตัวอย่างเช่น: cat: electronics id:TWINX2048-3200PRO กับ q.op AND
[หรือ]
แมว: อิเล็กทรอนิกส์และ id:TWINX2048-3200PRO
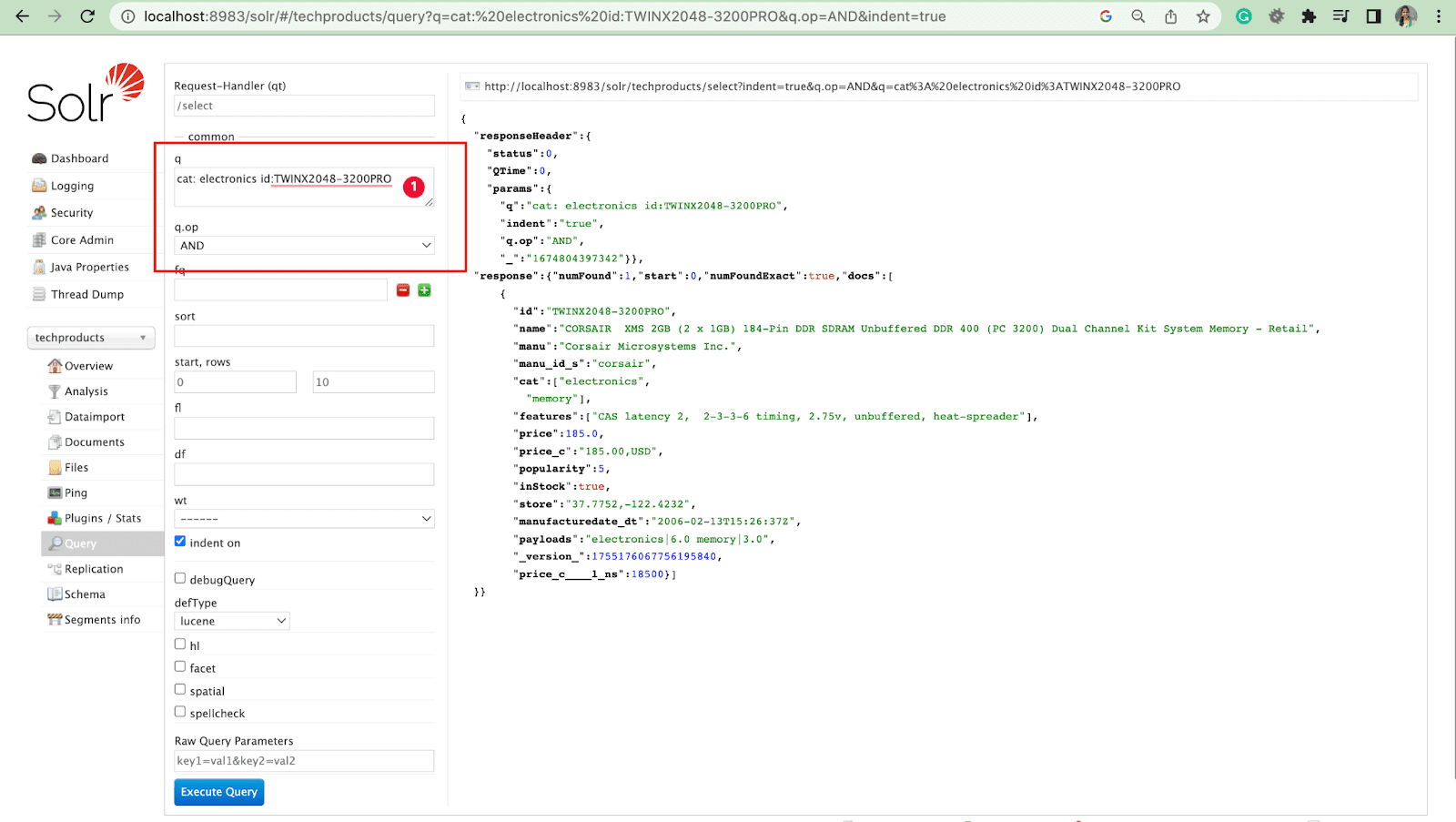
[หรือ]
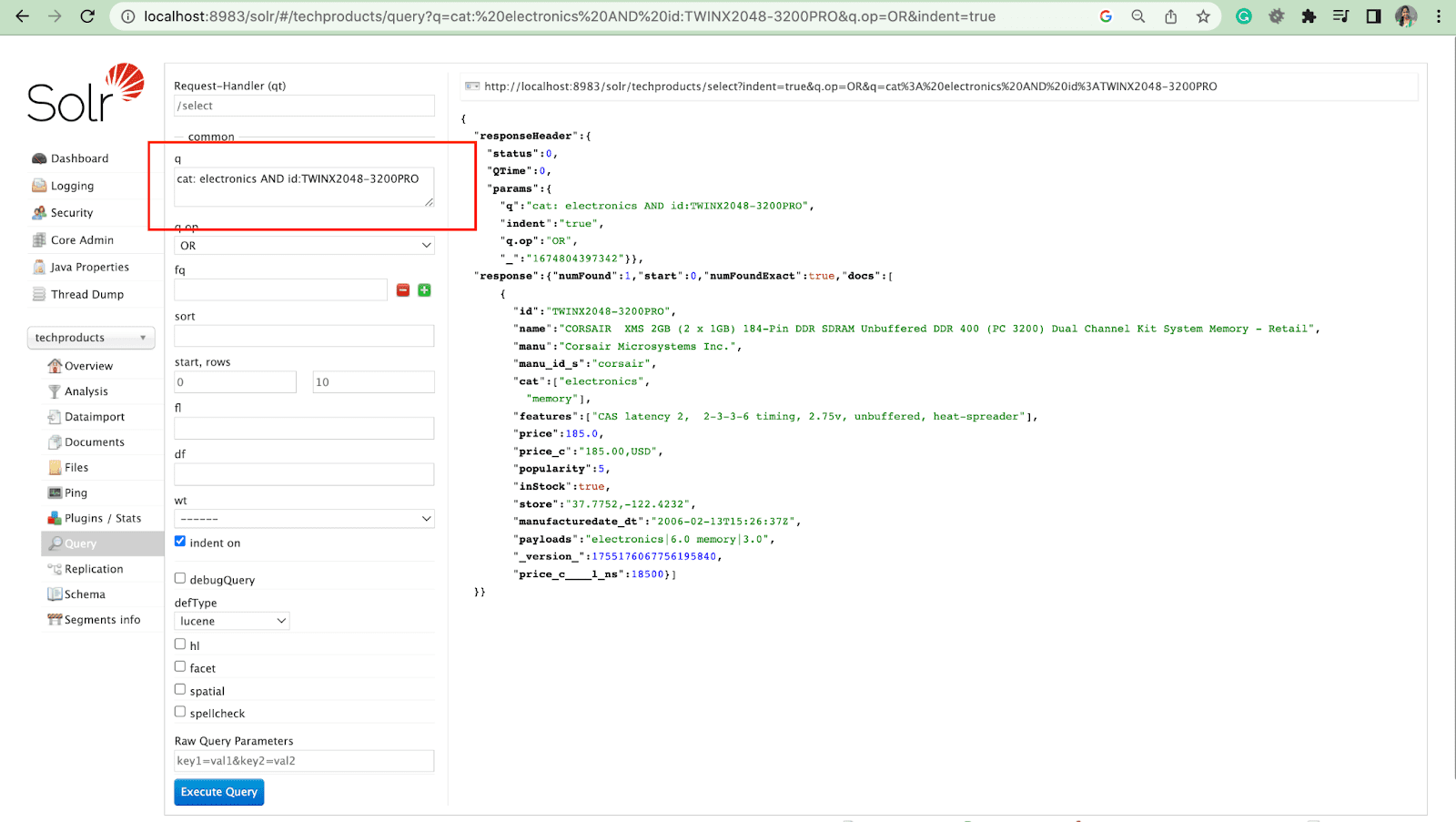
กรองแบบสอบถาม
ข้อความค้นหาตัวกรองช่วยจำกัดผลการค้นหาให้แคบลง เคียวรีสามารถระบุได้ด้วยพารามิเตอร์ fq เพื่อจำกัดเอกสารที่ส่งคืนใน superset โดยไม่ส่งผลต่อคะแนน
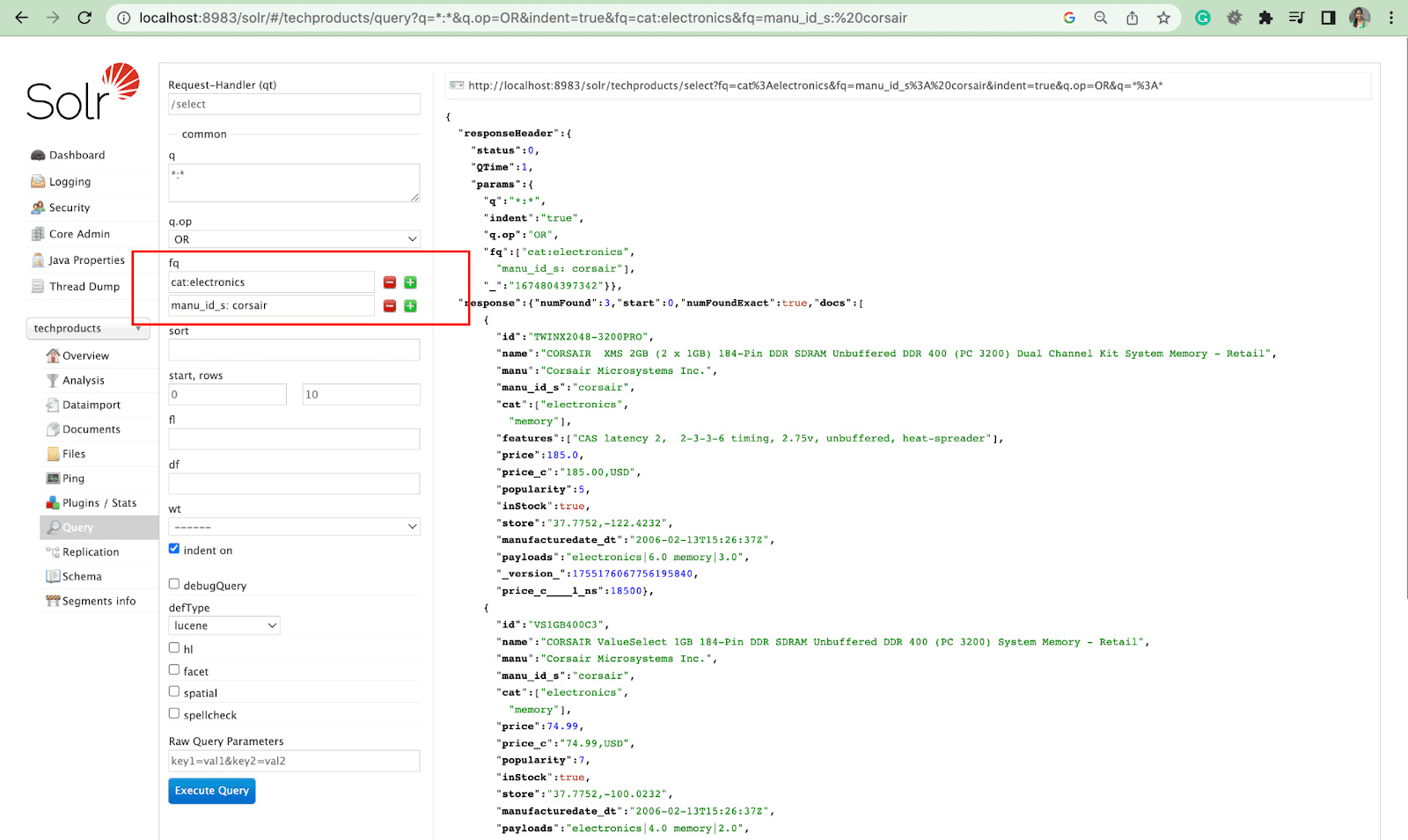
พารามิเตอร์การเรียงลำดับ
พารามิเตอร์ sort จัดเรียงผลการค้นหาตามลำดับจากน้อยไปมาก (asc) หรือจากมากไปหาน้อย (desc) พารามิเตอร์สามารถใช้เป็นตัวเลขหรือตัวอักษรก็ได้ ทั้งนี้ขึ้นอยู่กับเนื้อหา
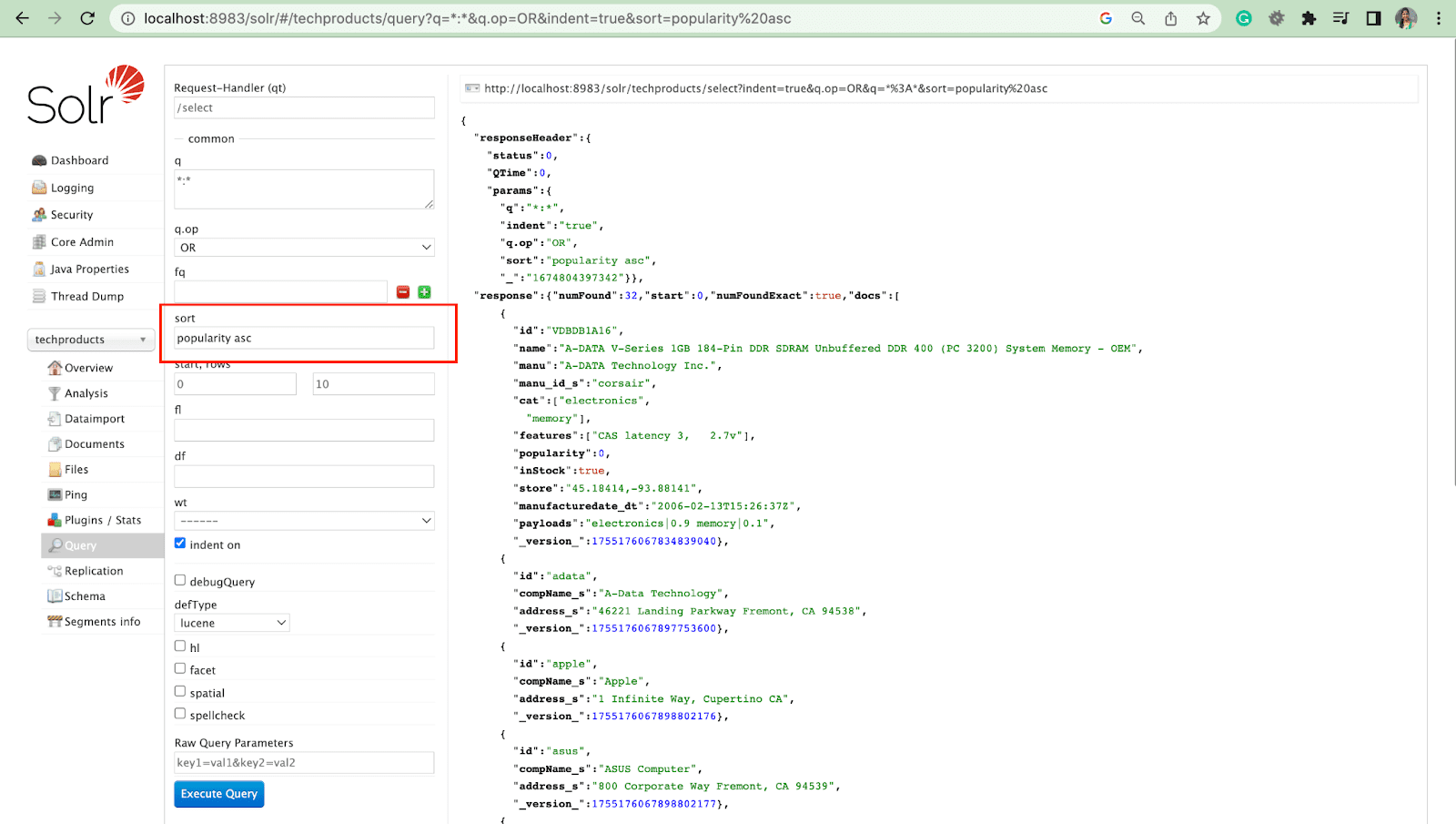
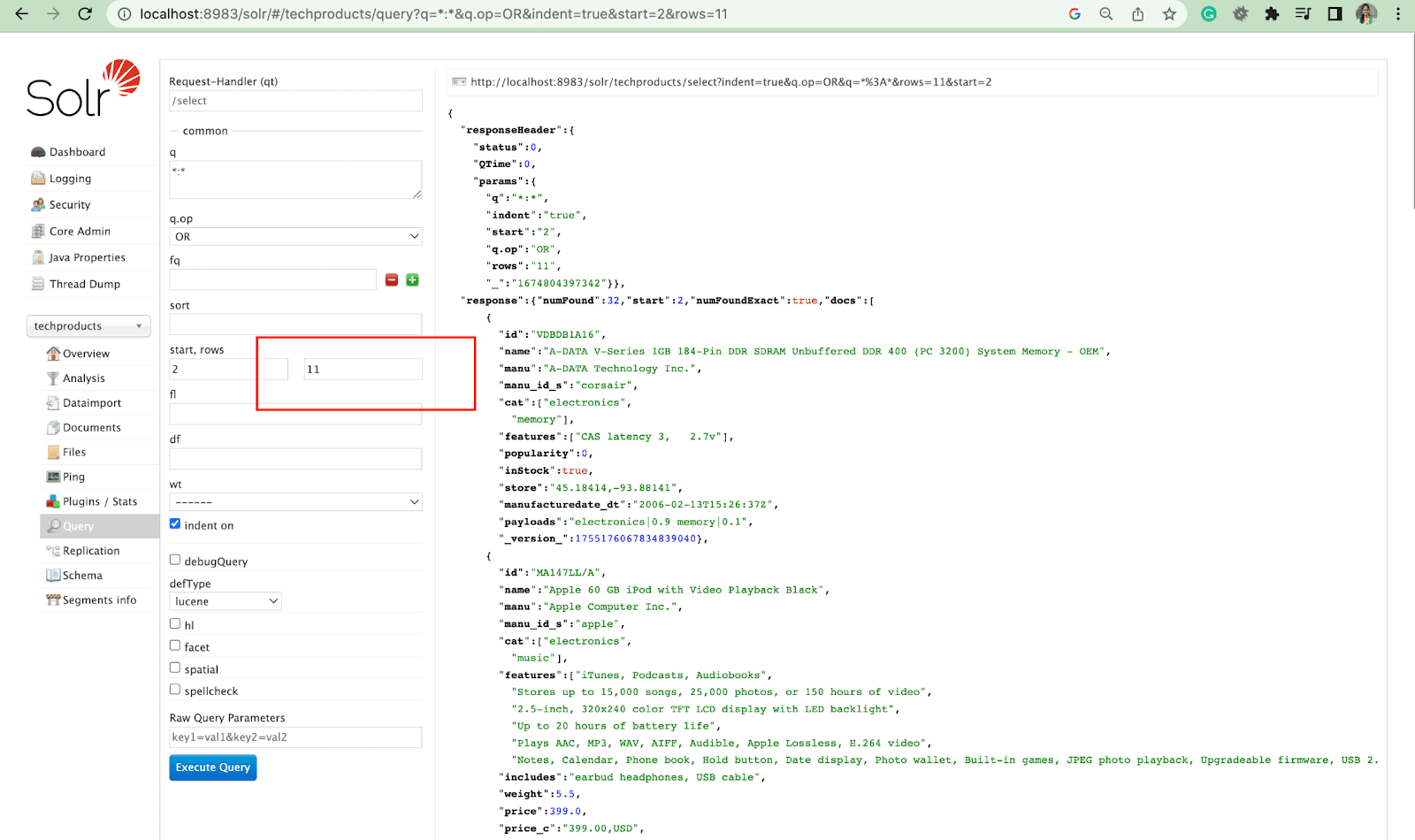
พารามิเตอร์แถว
พารามิเตอร์แถวช่วยให้คุณสามารถแบ่งหน้าผลลัพธ์จากแบบสอบถาม
พารามิเตอร์รายการฟิลด์
พารามิเตอร์ fl จำกัดข้อมูลที่รวมอยู่ในการตอบกลับแบบสอบถามไปยังรายการฟิลด์ที่ระบุ
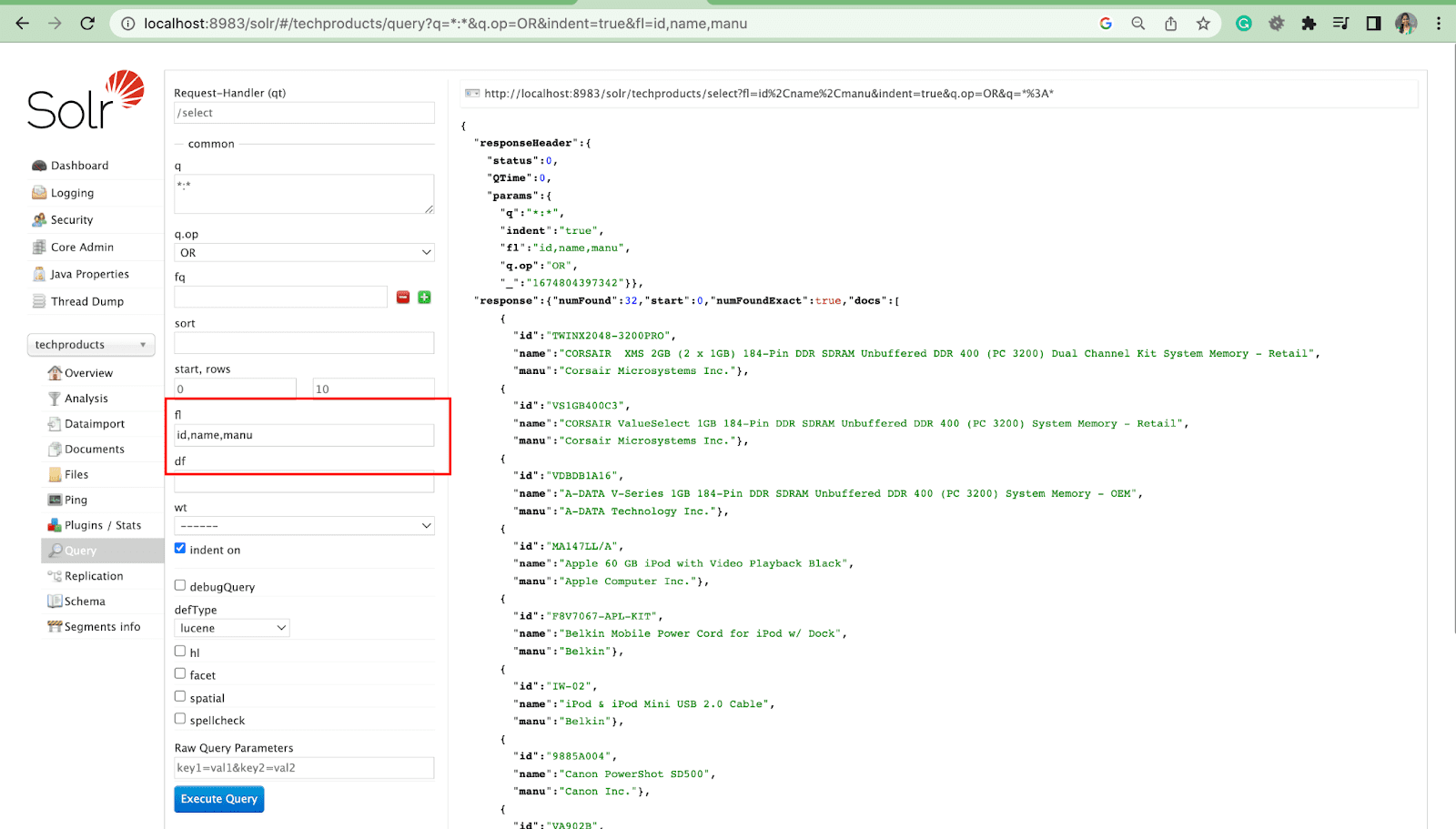
พารามิเตอร์ฟิลด์เริ่มต้น
พารามิเตอร์ช่องเริ่มต้นเป็นช่องเริ่มต้นสำหรับพารามิเตอร์การค้นหา
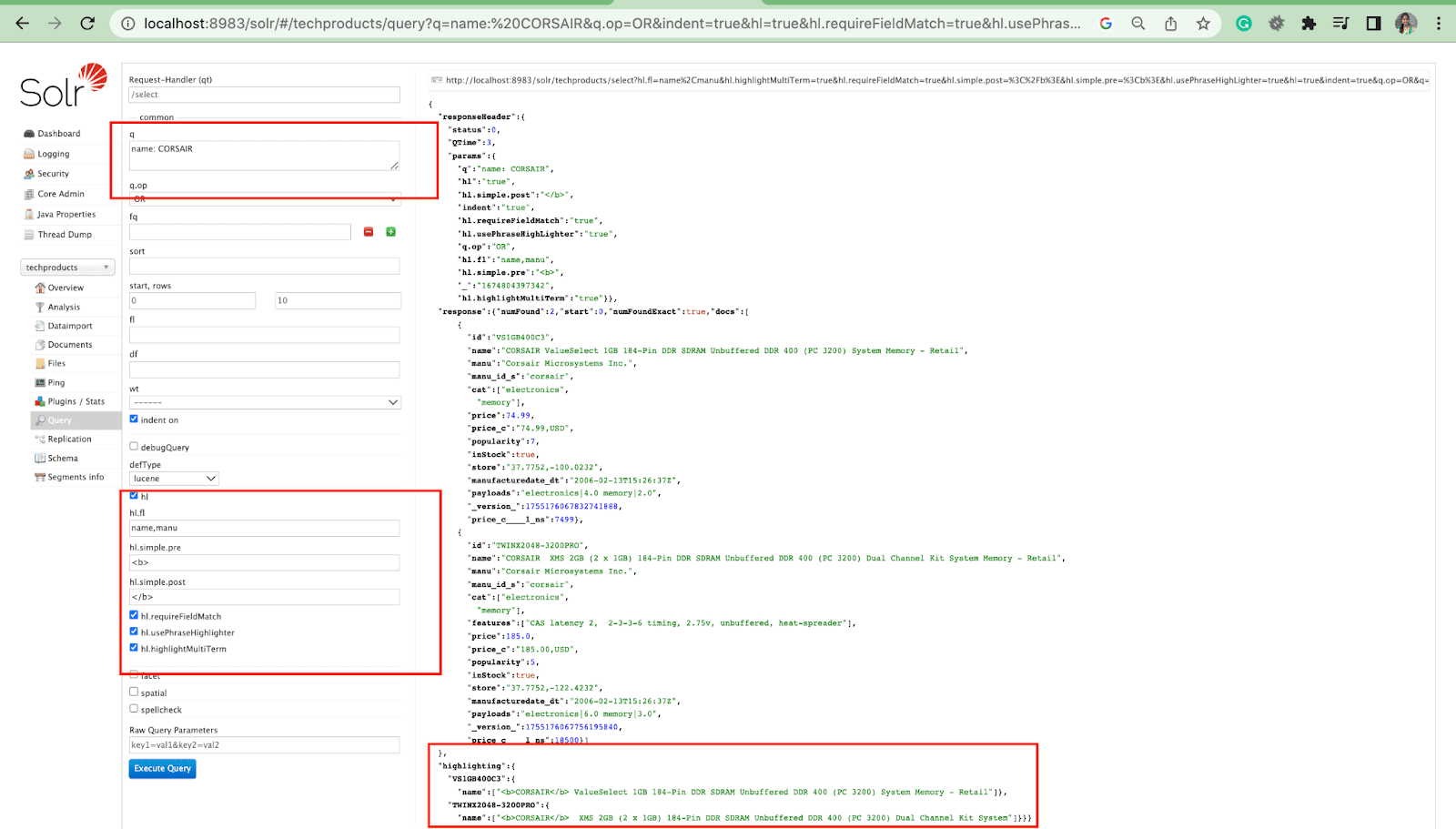
ไฮไลท์พารามิเตอร์
คุณลักษณะไฮไลท์ใน Solr ช่วยให้สามารถรวมส่วนย่อยของเอกสารที่ตรงกับข้อความค้นหาได้
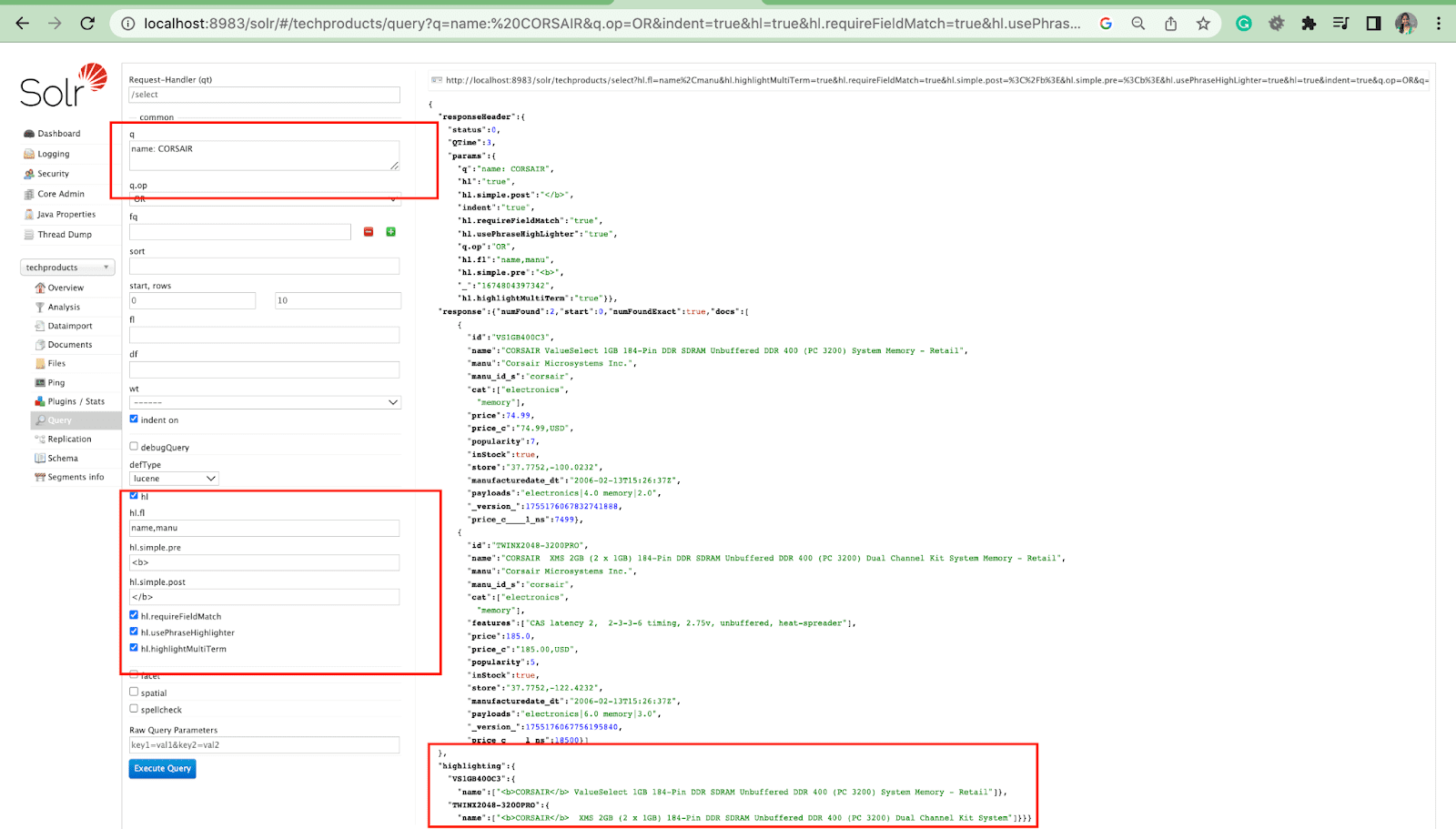
พารามิเตอร์ไฮไลต์ที่พบได้บ่อยที่สุดคือ:
- Hl.fl - ไฮไลท์รายการฟิลด์
- Hl.simple.pre - ระบุว่าควรใช้ "แท็ก" ใดก่อนคำที่ไฮไลต์
- Hl.simple.post - ระบุว่าควรใช้ “แท็ก” ใดหลังจากคำที่ไฮไลต์
- hl.highlightMultiTerm - หากตั้งค่าเป็น true Solr จะเน้นข้อความค้นหาไวด์การ์ด หากเป็น เท็จ จะไม่ถูกเน้นเลย
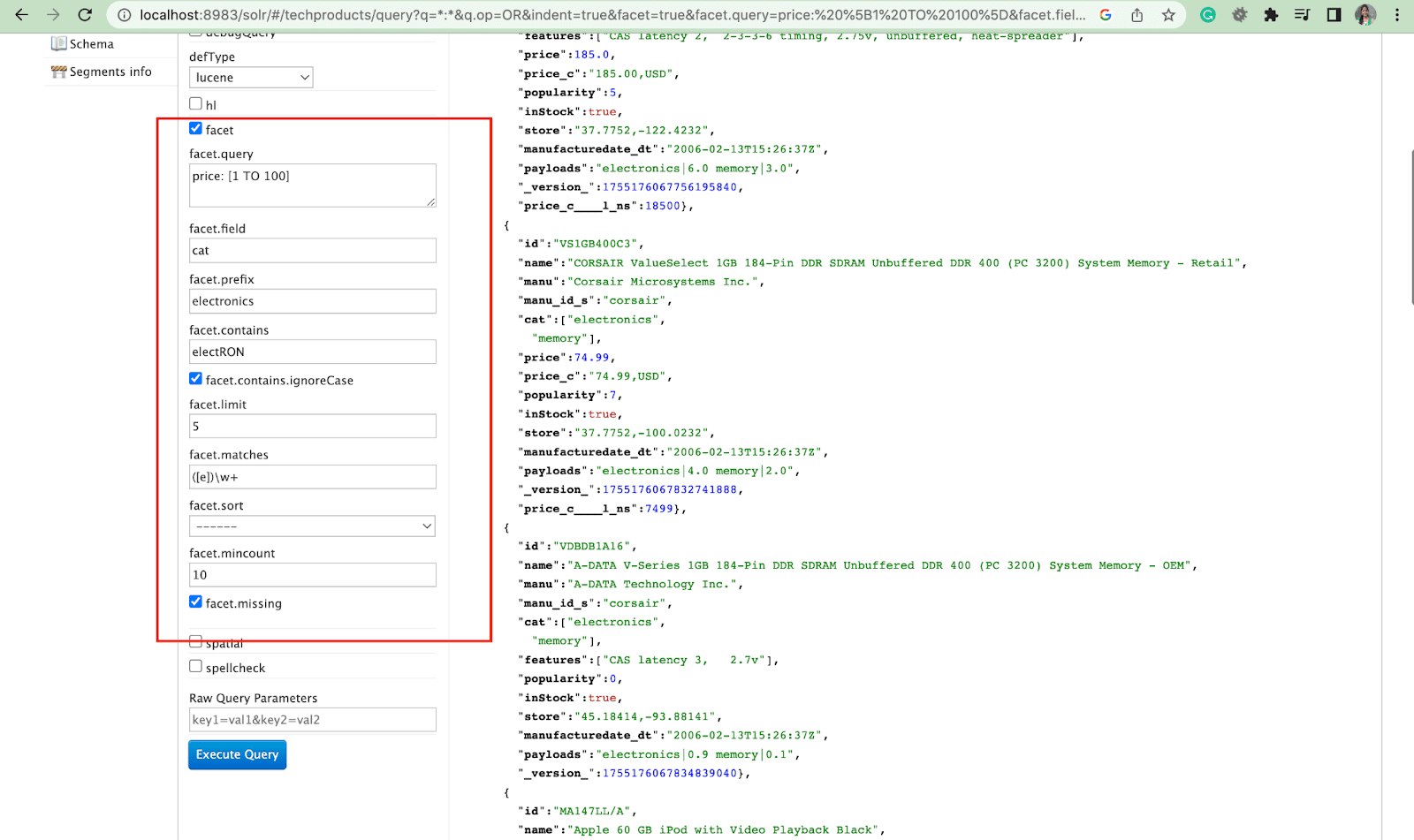
ด้าน:
Facets ช่วยให้ผู้ใช้สามารถสำรวจและปรับแต่งผลการค้นหาจำนวนมากได้ โดยจะแสดงใน UI เป็นช่องทำเครื่องหมาย เมนูแบบเลื่อนลง หรือตัวควบคุมอื่นๆ พารามิเตอร์ทั่วไป 2 ตัวในการควบคุม facet คือ:
- พารามิเตอร์ด้าน
เมื่อใช้พารามิเตอร์ facet ผู้ใช้สามารถสร้าง facet ตามค่าของฟิลด์อย่างน้อยหนึ่งฟิลด์ในดัชนีการค้นหาของตน ในผลการค้นหา สามารถกำหนดค่าพารามิเตอร์ facet เพื่อควบคุมวิธีสร้างและแสดง facet ได้
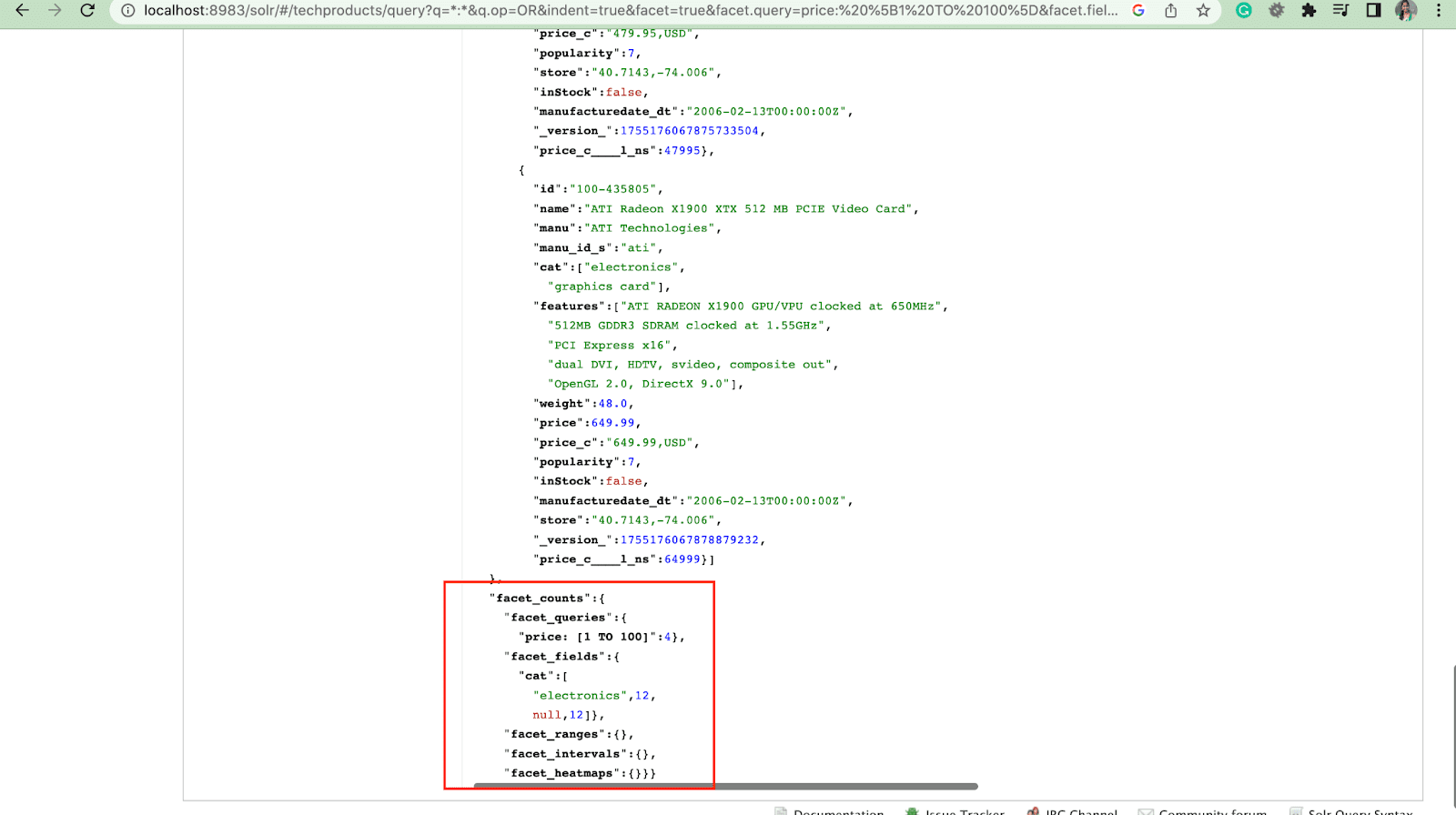
2. พารามิเตอร์ Facet.query
เมื่อผู้ใช้ใส่พารามิเตอร์ facet.query ในการสืบค้น Solr ของตน Solr จะสร้างรายการจำนวน facet ที่สอดคล้องกับจำนวนเอกสารในดัชนีที่ตรงกับการสืบค้นแต่ละรายการ Facet.query มีประโยชน์เมื่อคุณต้องการสร้างข้อมูลประกอบตามเกณฑ์การค้นหาที่ซับซ้อนซึ่งไม่สามารถแสดงได้ง่ายๆ โดยใช้ค่าฟิลด์แบบธรรมดา
มีพารามิเตอร์ facet อื่นๆ อีกหลายอย่าง เช่น facet.field (เพื่อระบุฟิลด์ที่ควรใช้สร้าง facet) , facet.limit (จำนวนสูงสุดของ facet ที่จะแสดงสำหรับแต่ละฟิลด์) , facet.mincount (จำนวนขั้นต่ำของเอกสารที่จำเป็นสำหรับ facet ที่จะรวมในการตอบกลับ) , facet.sort (ระบุลำดับที่ควรแสดงค่า facet)
ความคิดสุดท้าย
Apache Solr เป็นเสิร์ชเอ็นจิ้นอเนกประสงค์ที่มาพร้อมกับคุณสมบัติที่น่าสนใจมากมาย ซึ่งสามารถปรับแต่งได้ตามความต้องการของคุณ Drupal ทำงานร่วมกับ Apache Solr ได้เป็นอย่างดี หากคุณกำลังมองหาผู้เชี่ยวชาญ Drupal เพื่อกำหนดค่าเสิร์ชเอ็นจิ้นที่มีประสิทธิภาพสำหรับโปรเจ็กต์ใหม่ของคุณ เรายินดีเป็นอย่างยิ่งที่จะพัฒนาต่อไป!