
การตรวจจับความผิดปกติ: แนวทางป้องกันการบุกรุกเครือข่าย
เผยแพร่แล้ว: 2023-01-09ข้อมูลเป็นส่วนที่ขาดไม่ได้ของธุรกิจและองค์กร และจะมีค่าก็ต่อเมื่อมีการจัดโครงสร้างอย่างเหมาะสมและจัดการอย่างมีประสิทธิภาพเท่านั้น
จากสถิติพบว่า 95% ของธุรกิจในปัจจุบันพบว่าการจัดการและจัดโครงสร้างข้อมูลที่ไม่มีโครงสร้างเป็นปัญหา
นี่คือที่มาของการทำเหมืองข้อมูล เป็นกระบวนการค้นหา วิเคราะห์ และแยกรูปแบบที่มีความหมายและข้อมูลที่มีค่าจากชุดข้อมูลที่ไม่มีโครงสร้างจำนวนมาก
บริษัทต่างๆ ใช้ซอฟต์แวร์เพื่อระบุรูปแบบในชุดข้อมูลขนาดใหญ่เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับลูกค้าและกลุ่มเป้าหมาย และพัฒนากลยุทธ์ทางธุรกิจและการตลาดเพื่อปรับปรุงการขายและลดต้นทุน
นอกจากประโยชน์นี้แล้ว การตรวจจับการฉ้อโกงและความผิดปกติยังเป็นแอปพลิเคชันที่สำคัญที่สุดของการทำเหมืองข้อมูล
บทความนี้จะอธิบายการตรวจจับความผิดปกติและสำรวจเพิ่มเติมว่าสามารถช่วยป้องกันการละเมิดข้อมูลและการบุกรุกเครือข่ายได้อย่างไรเพื่อรับประกันความปลอดภัยของข้อมูล
การตรวจจับความผิดปกติและประเภทของมันคืออะไร?

แม้ว่าการทำเหมืองข้อมูลจะเกี่ยวข้องกับการค้นหารูปแบบ ความสัมพันธ์ และแนวโน้มที่เชื่อมโยงเข้าด้วยกัน แต่ก็เป็นวิธีที่ดีในการค้นหาความผิดปกติหรือจุดข้อมูลผิดปกติภายในเครือข่าย
ความผิดปกติในการขุดข้อมูลคือจุดข้อมูลที่แตกต่างจากจุดข้อมูลอื่นๆ ในชุดข้อมูล และเบี่ยงเบนไปจากรูปแบบพฤติกรรมปกติของชุดข้อมูล
ความผิดปกติสามารถจำแนกออกเป็นประเภทและหมวดหมู่ที่แตกต่างกัน ได้แก่:
- การเปลี่ยนแปลงในเหตุการณ์: หมายถึงการเปลี่ยนแปลงอย่างกะทันหันหรือเป็นระบบจากพฤติกรรมปกติก่อนหน้านี้
- Outliers: รูปแบบความผิดปกติขนาดเล็กที่ปรากฏขึ้นอย่างไม่เป็นระบบในการรวบรวมข้อมูล สิ่งเหล่านี้สามารถจัดประเภทเพิ่มเติมเป็นค่าผิดปกติระดับโลก บริบท และค่าผิดปกติโดยรวม
- การ เลื่อนลอย: การเปลี่ยนแปลงทีละน้อย ไม่มีทิศทาง และระยะยาวในชุดข้อมูล
ดังนั้น การตรวจจับความผิดปกติจึงเป็นเทคนิคการประมวลผลข้อมูลที่มีประโยชน์อย่างมากสำหรับการตรวจจับธุรกรรมที่เป็นการฉ้อโกง การจัดการกรณีศึกษาที่มีความไม่สมดุลระดับสูง และการตรวจจับโรคเพื่อสร้างแบบจำลองด้านวิทยาศาสตร์ข้อมูลที่มีประสิทธิภาพ
ตัวอย่างเช่น บริษัทอาจต้องการวิเคราะห์กระแสเงินสดเพื่อค้นหาธุรกรรมที่ผิดปกติหรือเกิดซ้ำในบัญชีธนาคารที่ไม่รู้จัก เพื่อตรวจหาการฉ้อโกงและดำเนินการตรวจสอบเพิ่มเติม
ประโยชน์ของการตรวจจับความผิดปกติ
การตรวจจับพฤติกรรมที่ผิดปกติของผู้ใช้จะช่วยเสริมความแข็งแกร่งให้กับระบบรักษาความปลอดภัยและทำให้มีความแม่นยำและแม่นยำยิ่งขึ้น
โดยจะวิเคราะห์และทำความเข้าใจกับข้อมูลต่างๆ ที่ระบบรักษาความปลอดภัยมอบให้เพื่อระบุภัยคุกคามและความเสี่ยงที่อาจเกิดขึ้นภายในเครือข่าย
ข้อดีของการตรวจจับความผิดปกติสำหรับบริษัทมีดังนี้
- การตรวจจับภัยคุกคามความปลอดภัยทางไซเบอร์และการละเมิดข้อมูลตามเวลาจริง เนื่องจากอัลกอริธึมปัญญาประดิษฐ์ (AI) สแกนข้อมูลของคุณอย่างต่อเนื่องเพื่อค้นหาพฤติกรรมที่ผิดปกติ
- ทำให้ ติดตามกิจกรรมและรูปแบบที่ผิดปกติได้รวดเร็ว และง่ายกว่าการตรวจจับความผิดปกติด้วยตนเอง ลดแรงงานและเวลาที่ต้องใช้ในการแก้ไขภัยคุกคาม
- ลดความเสี่ยง ในการปฏิบัติงานให้เหลือน้อยที่สุดโดยการระบุข้อผิดพลาดในการปฏิบัติงาน เช่น ประสิทธิภาพการทำงานลดลงกะทันหัน ก่อนที่จะเกิดขึ้น
- ช่วยขจัดความเสียหายทางธุรกิจที่สำคัญ ด้วยการตรวจจับความผิดปกติอย่างรวดเร็ว เนื่องจากหากไม่มีระบบตรวจจับความผิดปกติ บริษัทต่างๆ อาจใช้เวลาหลายสัปดาห์และหลายเดือนในการระบุภัยคุกคามที่อาจเกิดขึ้น
ดังนั้น การตรวจจับความผิดปกติจึงเป็นสินทรัพย์ขนาดใหญ่สำหรับธุรกิจที่จัดเก็บชุดข้อมูลลูกค้าและธุรกิจจำนวนมากเพื่อค้นหาโอกาสในการเติบโตและกำจัดภัยคุกคามด้านความปลอดภัยและปัญหาคอขวดในการดำเนินงาน
เทคนิคการตรวจจับความผิดปกติ
การตรวจจับความผิดปกติใช้หลายขั้นตอนและอัลกอริทึมการเรียนรู้ของเครื่อง (ML) เพื่อตรวจสอบข้อมูลและตรวจจับภัยคุกคาม
ต่อไปนี้คือเทคนิคการตรวจจับความผิดปกติที่สำคัญ:
#1. เทคนิคการเรียนรู้ของเครื่อง

เทคนิคการเรียนรู้ของเครื่องใช้อัลกอริทึม ML เพื่อวิเคราะห์ข้อมูลและตรวจจับความผิดปกติ อัลกอริทึมการเรียนรู้ของเครื่องประเภทต่างๆ สำหรับการตรวจจับความผิดปกติ ได้แก่:
- อัลกอริทึมการจัดกลุ่ม
- อัลกอริธึมการจำแนกประเภท
- อัลกอริทึมการเรียนรู้เชิงลึก
และเทคนิค ML ที่ใช้กันทั่วไปสำหรับการตรวจจับความผิดปกติและการคุกคาม ได้แก่ เครื่องเวกเตอร์สนับสนุน (SVM) การจัดกลุ่มค่า k-mean และโปรแกรมเข้ารหัสอัตโนมัติ
#2. เทคนิคทางสถิติ
เทคนิคทางสถิติใช้แบบจำลองทางสถิติเพื่อตรวจหารูปแบบที่ผิดปกติ (เช่น ความผันผวนที่ผิดปกติในประสิทธิภาพของเครื่องจักรเฉพาะ) ในข้อมูลเพื่อตรวจหาค่าที่เกินช่วงของค่าที่คาดไว้
เทคนิคการตรวจจับความผิดปกติทางสถิติทั่วไป ได้แก่ การทดสอบสมมติฐาน, IQR, Z-score, modified Z-score, การประมาณค่าความหนาแน่น, boxplot, การวิเคราะห์ค่ามาก และฮิสโตแกรม
#3. เทคนิคการขุดข้อมูล

เทคนิคการทำเหมืองข้อมูลใช้เทคนิคการจำแนกประเภทข้อมูลและการจัดกลุ่มเพื่อค้นหาความผิดปกติภายในชุดข้อมูล เทคนิคความผิดปกติของการทำเหมืองข้อมูลทั่วไปบางอย่าง ได้แก่ การจัดกลุ่มสเปกตรัม การจัดกลุ่มตามความหนาแน่น และการวิเคราะห์องค์ประกอบหลัก
อัลกอริทึมการทำเหมืองข้อมูลแบบคลัสเตอร์ใช้เพื่อจัดกลุ่มจุดข้อมูลต่างๆ ออกเป็นคลัสเตอร์ตามความคล้ายคลึงกันเพื่อค้นหาจุดข้อมูลและความผิดปกติที่อยู่นอกคลัสเตอร์เหล่านี้
ในทางกลับกัน อัลกอริทึมการจัดหมวดหมู่จะจัดสรรจุดข้อมูลให้กับคลาสที่กำหนดไว้ล่วงหน้าเฉพาะเจาะจง และตรวจหาจุดข้อมูลที่ไม่ได้เป็นของคลาสเหล่านี้
#4. เทคนิคตามกฎ
ตามชื่อที่แนะนำ เทคนิคการตรวจจับความผิดปกติตามกฎจะใช้ชุดของกฎที่กำหนดไว้ล่วงหน้าเพื่อค้นหาความผิดปกติภายในข้อมูล
เทคนิคเหล่านี้ค่อนข้างง่ายกว่าและตั้งค่าได้ง่ายกว่า แต่อาจไม่ยืดหยุ่นและอาจไม่มีประสิทธิภาพในการปรับให้เข้ากับพฤติกรรมและรูปแบบข้อมูลที่เปลี่ยนแปลงไป
ตัวอย่างเช่น คุณสามารถตั้งโปรแกรมระบบตามกฎได้อย่างง่ายดายเพื่อตั้งค่าสถานะธุรกรรมที่เกินจำนวนเงินที่ระบุว่าเป็นการฉ้อโกง
#5. เทคนิคเฉพาะโดเมน
คุณสามารถใช้เทคนิคเฉพาะโดเมนเพื่อตรวจหาความผิดปกติในระบบข้อมูลเฉพาะ อย่างไรก็ตาม แม้ว่าอาจมีประสิทธิภาพสูงในการตรวจจับความผิดปกติในโดเมนเฉพาะ แต่อาจมีประสิทธิภาพน้อยกว่าในโดเมนอื่นนอกโดเมนที่ระบุ
ตัวอย่างเช่น การใช้เทคนิคเฉพาะโดเมน คุณสามารถออกแบบเทคนิคเฉพาะเพื่อค้นหาความผิดปกติในธุรกรรมทางการเงิน แต่อาจไม่ได้ผลในการค้นหาความผิดปกติหรือประสิทธิภาพการทำงานที่ลดลงในเครื่อง
ต้องการการเรียนรู้ของเครื่องสำหรับการตรวจจับความผิดปกติ
แมชชีนเลิร์นนิงมีความสำคัญและมีประโยชน์อย่างมากในการตรวจจับความผิดปกติ
ปัจจุบัน บริษัทและองค์กรส่วนใหญ่ต้องการการตรวจจับค่าผิดปกติที่ต้องจัดการกับข้อมูลจำนวนมหาศาล ตั้งแต่ข้อความ ข้อมูลลูกค้า และธุรกรรม ไปจนถึงไฟล์มีเดีย เช่น รูปภาพและเนื้อหาวิดีโอ
การทำธุรกรรมธนาคารทั้งหมดและข้อมูลที่สร้างขึ้นในแต่ละวินาทีด้วยตนเองเพื่อขับเคลื่อนข้อมูลเชิงลึกที่มีความหมายนั้นแทบจะเป็นไปไม่ได้เลย ยิ่งไปกว่านั้น บริษัทส่วนใหญ่เผชิญกับความท้าทายและความยากลำบากอย่างมากในการจัดโครงสร้างข้อมูลที่ไม่มีโครงสร้างและการจัดเรียงข้อมูลในลักษณะที่มีความหมายสำหรับการวิเคราะห์ข้อมูล
นี่คือจุดที่เครื่องมือและเทคนิคต่างๆ เช่น แมชชีนเลิร์นนิง (ML) มีบทบาทอย่างมากในการรวบรวม ทำความสะอาด จัดโครงสร้าง จัดเรียง วิเคราะห์ และจัดเก็บข้อมูลที่ไม่มีโครงสร้างปริมาณมหาศาล
เทคนิคการเรียนรู้ของเครื่องและอัลกอริทึมจะประมวลผลชุดข้อมูลขนาดใหญ่และให้ความยืดหยุ่นในการใช้งานและรวมเทคนิคและอัลกอริทึมต่างๆ เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด
นอกจากนี้ แมชชีนเลิร์นนิงยังช่วยปรับปรุงกระบวนการตรวจจับความผิดปกติสำหรับแอปพลิเคชันในโลกแห่งความเป็นจริงและช่วยประหยัดทรัพยากรอันมีค่า
ประโยชน์และความสำคัญของแมชชีนเลิร์นนิงในการตรวจจับความผิดปกติมีดังนี้
- ทำให้การตรวจหาความผิดปกติปรับขนาดได้ง่ายขึ้น โดยการระบุรูปแบบและความผิดปกติโดยอัตโนมัติโดยไม่ต้องมีการเขียนโปรแกรมที่ชัดเจน
- อัลกอริทึมการเรียนรู้ของเครื่อง สามารถปรับ ให้เข้ากับรูปแบบชุดข้อมูลที่เปลี่ยนแปลงได้อย่างมาก ทำให้มีประสิทธิภาพสูงและทนทานตามกาลเวลา
- จัดการชุดข้อมูลขนาดใหญ่และซับซ้อนได้อย่างง่ายดาย ทำให้การตรวจจับความผิดปกติมีประสิทธิภาพแม้ว่าชุดข้อมูลจะซับซ้อนก็ตาม
- รับรอง การระบุและตรวจจับความผิดปกติตั้งแต่เนิ่นๆ ด้วยการระบุความผิดปกติเมื่อเกิดขึ้น ประหยัดเวลาและทรัพยากร
- ระบบตรวจจับความผิดปกติที่ใช้การเรียนรู้ของเครื่องช่วยให้ได้รับ ความแม่นยำในการตรวจจับความผิดปกติในระดับที่สูงขึ้น เมื่อเทียบกับวิธีการแบบเดิม
ดังนั้น การตรวจจับความผิดปกติที่จับคู่กับแมชชีนเลิร์นนิงจะช่วยให้ตรวจจับความผิดปกติได้เร็วขึ้นและเร็วขึ้น เพื่อป้องกันภัยคุกคามด้านความปลอดภัยและการละเมิดที่เป็นอันตราย

อัลกอริทึมการเรียนรู้ของเครื่องสำหรับการตรวจจับความผิดปกติ
คุณสามารถตรวจจับความผิดปกติและค่าผิดปกติในข้อมูลด้วยความช่วยเหลือของอัลกอริทึมการทำเหมืองข้อมูลที่แตกต่างกันสำหรับการเรียนรู้การจัดหมวดหมู่ การจัดกลุ่ม หรือกฎการเชื่อมโยง
โดยทั่วไปแล้ว อัลกอริธึมการทำเหมืองข้อมูลเหล่านี้จะถูกจำแนกออกเป็น 2 ประเภทที่แตกต่างกัน ได้แก่ อัลกอริทึมการเรียนรู้แบบมีผู้ดูแลและไม่มีผู้ดูแล
การเรียนรู้ภายใต้การนิเทศ
การเรียนรู้ภายใต้การดูแลเป็นอัลกอริทึมการเรียนรู้ประเภททั่วไปที่ประกอบด้วยอัลกอริทึม เช่น เครื่องเวกเตอร์สนับสนุน การถดถอยโลจิสติกและเชิงเส้น และการจำแนกประเภทหลายชั้น อัลกอริทึมประเภทนี้ได้รับการฝึกอบรมบนข้อมูลที่มีป้ายกำกับ ซึ่งหมายความว่าชุดข้อมูลการฝึกอบรมมีทั้งข้อมูลอินพุตปกติและเอาต์พุตที่ถูกต้องหรือตัวอย่างที่ผิดปกติเพื่อสร้างแบบจำลองการทำนาย
ดังนั้น เป้าหมายของมันคือการคาดการณ์เอาต์พุตสำหรับข้อมูลที่มองไม่เห็นและข้อมูลใหม่ตามรูปแบบชุดข้อมูลการฝึกอบรม การประยุกต์ใช้อัลกอริธึมการเรียนรู้แบบมีผู้สอน ได้แก่ การรู้จำภาพและคำพูด การสร้างแบบจำลองเชิงทำนาย และการประมวลผลภาษาธรรมชาติ (NLP)
การเรียนรู้แบบไม่มีผู้ควบคุม
การเรียนรู้แบบไม่มีผู้ควบคุม ไม่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลที่มีป้ายกำกับใด ๆ แต่จะค้นพบกระบวนการที่ซับซ้อนและโครงสร้างข้อมูลพื้นฐานโดยไม่ต้องให้คำแนะนำอัลกอริทึมการฝึกอบรมและแทนที่จะทำการคาดคะเนที่เฉพาะเจาะจง
การประยุกต์ใช้อัลกอริธึมการเรียนรู้แบบไม่มีผู้ดูแล ได้แก่ การตรวจจับความผิดปกติ การประมาณค่าความหนาแน่น และการบีบอัดข้อมูล
ตอนนี้ เรามาสำรวจอัลกอริธึมการตรวจจับความผิดปกติที่ใช้การเรียนรู้ของเครื่องยอดนิยมกันบ้าง
ปัจจัยภายนอกท้องถิ่น (LOF)
Local Outlier Factor หรือ LOF เป็นอัลกอริธึมการตรวจจับความผิดปกติที่พิจารณาความหนาแน่นของข้อมูลในเครื่องเพื่อพิจารณาว่าจุดข้อมูลมีความผิดปกติหรือไม่
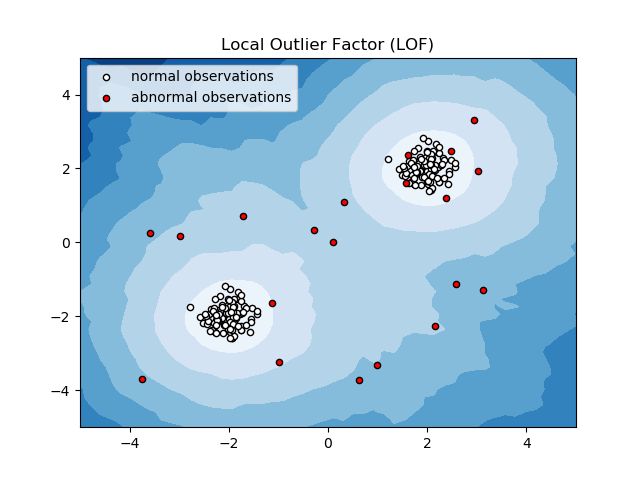
โดยจะเปรียบเทียบความหนาแน่นในท้องถิ่นของสิ่งของกับความหนาแน่นในท้องถิ่นของเพื่อนบ้าน เพื่อวิเคราะห์พื้นที่ที่มีความหนาแน่นใกล้เคียงกัน และสิ่งของที่มีความหนาแน่นต่ำกว่าเพื่อนบ้าน ซึ่งไม่ใช่สิ่งผิดปกติหรือค่าผิดปกติแต่อย่างใด
ดังนั้น พูดง่ายๆ ก็คือ ความหนาแน่นรอบๆ สิ่งของผิดปกติหรือสิ่งผิดปกติจะแตกต่างจากความหนาแน่นรอบๆ เพื่อนบ้าน ดังนั้น อัลกอริทึมนี้จึงเรียกอีกอย่างว่าอัลกอริธึมการตรวจจับค่าผิดปกติตามความหนาแน่น
K-เพื่อนบ้านที่ใกล้ที่สุด (K-NN)
K-NN เป็นอัลกอริธึมการตรวจจับความผิดปกติที่จัดหมวดหมู่และควบคุมดูแลอย่างง่ายที่สุด ซึ่งง่ายต่อการใช้งาน จัดเก็บตัวอย่างและข้อมูลที่มีอยู่ทั้งหมด และจัดประเภทตัวอย่างใหม่ตามความคล้ายคลึงกันในมาตรวัดระยะทาง
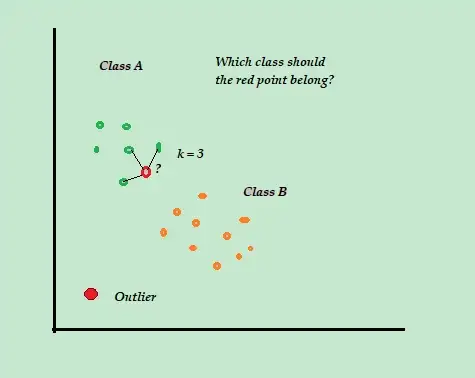
อัลกอริธึมการจัดหมวดหมู่นี้เรียกอีกอย่างว่า ผู้เรียนที่ขี้เกียจ เพราะจะเก็บเฉพาะข้อมูลการฝึกอบรมที่มีป้ายกำกับเท่านั้น โดยไม่ต้องดำเนินการอื่นใดในระหว่างกระบวนการฝึกอบรม
เมื่อจุดข้อมูลการฝึกอบรมที่ไม่มีป้ายกำกับใหม่มาถึง อัลกอริทึมจะดูที่จุดข้อมูลการฝึกอบรม K-Nearest หรือที่ใกล้ที่สุดเพื่อใช้จัดประเภทและกำหนดระดับของจุดข้อมูลใหม่ที่ไม่มีป้ายกำกับ
อัลกอริทึม K-NN ใช้วิธีการตรวจจับต่อไปนี้เพื่อกำหนดจุดข้อมูลที่ใกล้เคียงที่สุด:
- Euclidean Distance เพื่อวัดระยะทางสำหรับข้อมูลต่อเนื่อง
- Hamming Distance เพื่อวัดความใกล้ชิดหรือ “ความใกล้ชิด” ของสตริงข้อความทั้งสองสำหรับข้อมูลที่แยกจากกัน
ตัวอย่างเช่น พิจารณาว่าชุดข้อมูลการฝึกอบรมของคุณประกอบด้วยป้ายกำกับระดับสองป้าย คือ A และ B หากจุดข้อมูลใหม่มาถึง อัลกอริทึมจะคำนวณระยะห่างระหว่างจุดข้อมูลใหม่กับจุดข้อมูลแต่ละจุดในชุดข้อมูล แล้วเลือกจุด ซึ่งเป็นจำนวนสูงสุดที่ใกล้เคียงกับจุดข้อมูลใหม่
ดังนั้น สมมติว่า K=3 และจุดข้อมูล 2 ใน 3 จุดถูกระบุว่าเป็น A จากนั้นจุดข้อมูลใหม่จะถูกระบุว่าเป็นคลาส A
ดังนั้น อัลกอริทึม K-NN จึงทำงานได้ดีที่สุดในสภาพแวดล้อมแบบไดนามิกที่มีข้อกำหนดในการอัปเดตข้อมูลบ่อยครั้ง
อัลกอริทึมการตรวจจับความผิดปกติและการทำเหมืองข้อความยอดนิยมพร้อมแอปพลิเคชันในด้านการเงินและธุรกิจเพื่อตรวจจับธุรกรรมที่ฉ้อโกงและเพิ่มอัตราการตรวจจับการฉ้อโกง
รองรับ Vector Machine (SVM)
Support vector machine เป็นอัลกอริธึมการตรวจจับความผิดปกติที่ใช้การเรียนรู้ของเครื่องภายใต้การดูแล ซึ่งส่วนใหญ่ใช้ในปัญหาการถดถอยและการจำแนกประเภท
ใช้ ไฮเปอร์เพลนหลายมิติ เพื่อแยกข้อมูลออกเป็นสองกลุ่ม (ใหม่และปกติ) ดังนั้น ไฮเปอร์เพลนจึงทำหน้าที่เป็นขอบเขตการตัดสินใจที่แยกการสังเกตข้อมูลปกติและข้อมูลใหม่
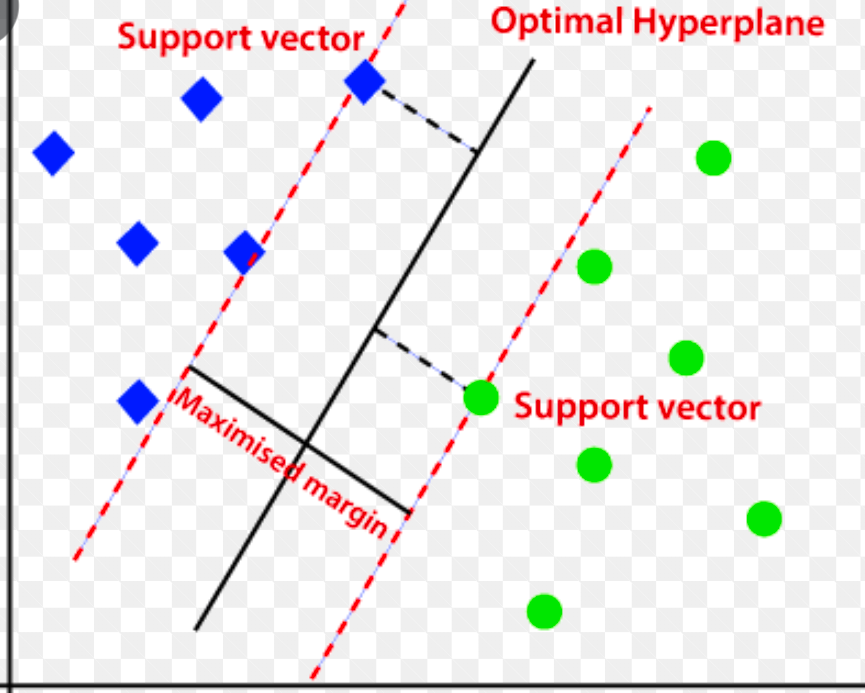
ระยะห่างระหว่างจุดข้อมูลทั้งสองนี้เรียกว่า ระยะขอบ
เนื่องจากเป้าหมายคือการเพิ่มระยะห่างระหว่างจุดสองจุด SVM จึงกำหนด ไฮเปอร์เพลนที่ดีที่สุดหรือดีที่สุดด้วยระยะขอบสูงสุด เพื่อให้แน่ใจว่าระยะห่างระหว่างสองคลาสนั้นกว้างที่สุดเท่าที่จะเป็นไปได้
เกี่ยวกับการตรวจจับความผิดปกติ SVM คำนวณระยะขอบของการสังเกตจุดข้อมูลใหม่จากไฮเปอร์เพลนเพื่อจัดประเภท
หากระยะขอบเกินเกณฑ์ที่ตั้งไว้ จะจัดประเภทการสังเกตใหม่เป็นความผิดปกติ ในเวลาเดียวกัน หากมาร์จินน้อยกว่าเกณฑ์ การสังเกตจะจัดอยู่ในประเภทปกติ
ดังนั้น อัลกอริทึม SVM จึงมีประสิทธิภาพสูงในการจัดการชุดข้อมูลที่มีมิติสูงและซับซ้อน
ป่าเปลี่ยว
Isolation Forest เป็นอัลกอริธึมการตรวจจับความผิดปกติที่เรียนรู้ด้วยเครื่องโดยไม่ได้รับการดูแล โดยยึดตามแนวคิดของ Random Forest Classifier
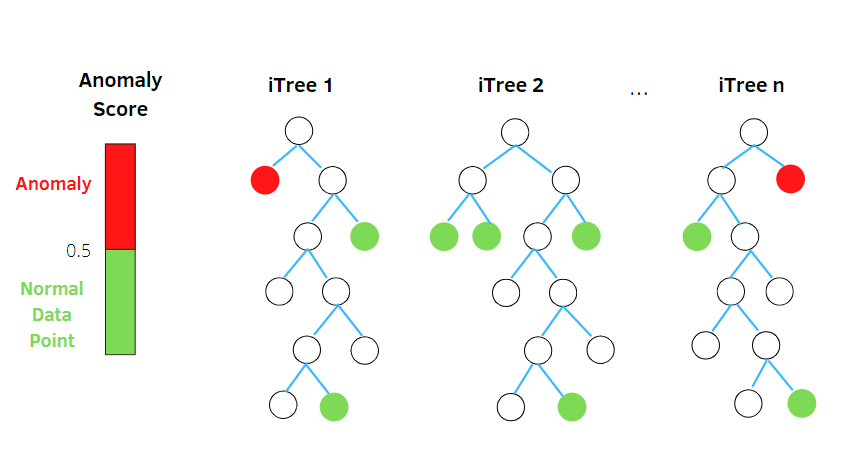
อัลกอริทึมนี้ประมวลผลข้อมูลตัวอย่างย่อยแบบสุ่มในชุดข้อมูลในโครงสร้างแบบต้นไม้ตามแอตทริบิวต์แบบสุ่ม มันสร้างต้นไม้การตัดสินใจหลายต้นเพื่อแยกการสังเกต และจะถือว่าการสังเกตเฉพาะเป็นความผิดปกติหากแยกในต้นไม้จำนวนน้อยลงตามอัตราการปนเปื้อน
ดังนั้น พูดง่ายๆ ก็คือ อัลกอริทึมของฟอเรสต์ แยกจะแบ่งจุดข้อมูลออกเป็นแผนผังการตัดสินใจที่แตกต่างกัน เพื่อให้แน่ใจว่าการสังเกตแต่ละครั้งจะถูกแยกออกจากกัน
ความผิดปกติมักจะอยู่ห่างจากคลัสเตอร์จุดข้อมูล ทำให้ระบุความผิดปกติได้ง่ายขึ้นเมื่อเทียบกับจุดข้อมูลปกติ
อัลกอริทึมฟอเรสต์แยกสามารถจัดการข้อมูลเชิงหมวดหมู่และตัวเลขได้อย่างง่ายดาย เป็นผลให้ฝึกได้เร็วกว่าและมีประสิทธิภาพสูงในการตรวจจับความผิดปกติของชุดข้อมูลขนาดใหญ่และมิติสูง
ช่วงระหว่างควอไทล์
ช่วงระหว่างควอไทล์หรือ IQR ใช้ในการ วัดความแปรปรวนทางสถิติหรือการกระจายตัวทางสถิติ เพื่อค้นหาจุดผิดปกติในชุดข้อมูลโดย แบ่งเป็นควอไทล์
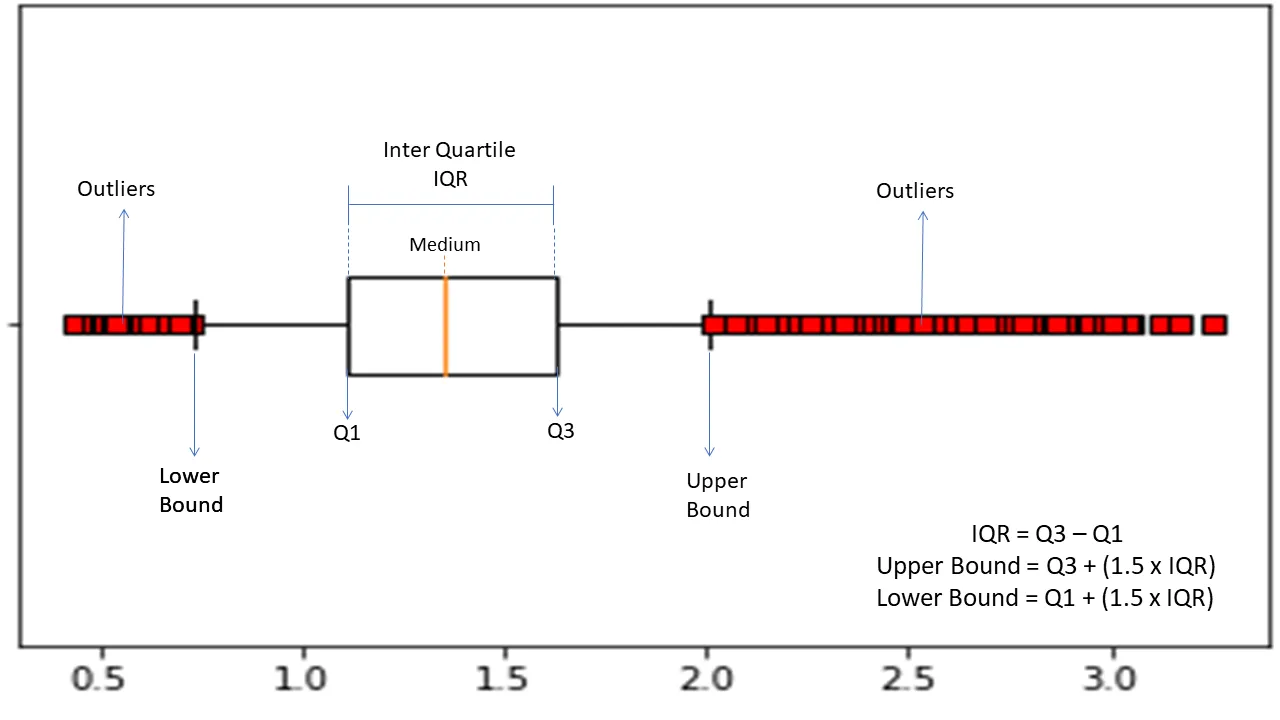
อัลกอริทึมจะจัดเรียงข้อมูลตามลำดับจากน้อยไปหามาก และแบ่งชุดข้อมูลออกเป็นสี่ส่วนเท่าๆ กัน ค่าที่แยกส่วนต่างๆ เหล่านี้คือ Q1, Q2 และ Q3—ควอไทล์ที่หนึ่ง สอง และสาม
นี่คือการแจกแจงเปอร์เซ็นต์ไทล์ของควอร์ไทล์เหล่านี้:
- Q1 หมายถึงเปอร์เซ็นไทล์ที่ 25 ของข้อมูล
- Q2 หมายถึงเปอร์เซ็นไทล์ที่ 50 ของข้อมูล
- Q3 หมายถึงเปอร์เซ็นต์ไทล์ที่ 75 ของข้อมูล
IQR คือความแตกต่างระหว่างชุดข้อมูลเปอร์เซ็นไทล์ที่สาม (75) และชุดแรก (25) ซึ่งคิดเป็น 50% ของข้อมูล
การใช้ IQR สำหรับการตรวจจับความผิดปกติ คุณจะต้องคำนวณ IQR ของชุดข้อมูลและกำหนดขอบเขตล่างและบนของข้อมูลเพื่อค้นหาความผิดปกติ
- ขอบเขตล่าง: Q1 – 1.5 * IQR
- ขอบเขตบน: Q3 + 1.5 * IQR
โดยทั่วไปแล้ว การสังเกตการณ์ที่อยู่นอกขอบเขตเหล่านี้ถือเป็นความผิดปกติ
อัลกอริทึม IQR มีประสิทธิภาพสำหรับชุดข้อมูลที่มีการกระจายข้อมูลไม่สม่ำเสมอและในกรณีที่ไม่เข้าใจการกระจายที่ดี
คำสุดท้าย
ความเสี่ยงด้านความปลอดภัยทางไซเบอร์และการละเมิดข้อมูลดูเหมือนจะไม่ลดลงในอีกไม่กี่ปีข้างหน้า และคาดว่าอุตสาหกรรมที่มีความเสี่ยงนี้จะเติบโตต่อไปในปี 2566 และการโจมตีทางไซเบอร์ของ IoT เพียงอย่างเดียวคาดว่าจะเพิ่มขึ้นเป็นสองเท่าภายในปี 2568
ยิ่งไปกว่านั้น อาชญากรรมทางไซเบอร์จะทำให้บริษัทและองค์กรทั่วโลกต้องเสียค่าใช้จ่ายประมาณ 10.3 ล้านล้านดอลลาร์ต่อปีภายในปี 2568
ด้วยเหตุนี้ความต้องการเทคนิคการตรวจจับความผิดปกติจึงแพร่หลายมากขึ้นและจำเป็นในปัจจุบันสำหรับการตรวจจับการฉ้อโกงและป้องกันการบุกรุกเครือข่าย
บทความนี้จะช่วยให้คุณเข้าใจว่าความผิดปกติในการขุดข้อมูลคืออะไร ความผิดปกติประเภทต่างๆ และวิธีป้องกันการบุกรุกเครือข่ายโดยใช้เทคนิคการตรวจจับความผิดปกติแบบ ML
จากนั้น คุณสามารถสำรวจทุกอย่างเกี่ยวกับเมทริกซ์ความสับสนในแมชชีนเลิร์นนิง