
Как синхронизировать локальную базу данных Oracle с AWS
Опубликовано: 2023-01-11Наблюдая за развитием корпоративного программного обеспечения с первого ряда на протяжении двух десятков лет, становится очевидным бесспорный тренд последних нескольких лет – перемещение баз данных в облако.
Я уже участвовал в нескольких проектах миграции, целью которых было перенести существующую локальную базу данных в облачную базу данных Amazon Web Services (AWS). Хотя из материалов документации AWS вы узнаете, насколько это может быть просто, я здесь, чтобы сказать вам, что выполнение такого плана не всегда проходит легко, и бывают случаи, когда он может потерпеть неудачу.

В этом посте я расскажу о реальном опыте для следующего случая:
- Источник : Хотя теоретически не имеет большого значения, какой у вас источник (вы можете использовать очень похожий подход для большинства самых популярных БД), Oracle на протяжении многих лет была предпочтительной системой баз данных в крупных корпоративных компаниях, и на этом я буду сосредоточен.
- Цель : Нет причин быть конкретным на этой стороне. Вы можете выбрать любую целевую базу данных в AWS, и подход все равно подойдет.
- Режим : у вас может быть полное обновление или добавочное обновление. Пакетная загрузка данных (исходное и целевое состояния задерживаются) или (почти) загрузка данных в реальном времени. Оба будут затронуты здесь.
- Частота : вам может понадобиться однократная миграция, за которой следует полный переход в облако, или вам может потребоваться некоторый переходный период и одновременное обновление данных на обеих сторонах, что подразумевает ежедневную синхронизацию между локальной средой и AWS. Первый проще и имеет гораздо больше смысла, но последний чаще запрашивается и имеет гораздо больше точек останова. Я расскажу об обоих здесь.
описание проблемы
Требование часто простое:
Мы хотим начать разработку сервисов внутри AWS, поэтому скопируйте все наши данные в базу данных «ABC». Быстро и просто. Теперь нам нужно использовать данные внутри AWS. Позже мы выясним, какие части дизайна БД нужно изменить, чтобы они соответствовали нашим действиям.
Прежде чем идти дальше, есть что рассмотреть:
- Не прибегайте к идее «просто скопируйте то, что у нас есть, и займитесь этим позже» слишком быстро. Я имею в виду, да, это самое простое, что вы можете сделать, и это будет сделано быстро, но это может создать такую фундаментальную архитектурную проблему, которую будет невозможно исправить позже без серьезного рефакторинга большей части новой облачной платформы. . Только представьте, что облачная экосистема полностью отличается от локальной. Со временем будет введено несколько новых услуг. Естественно, люди начнут использовать одно и то же по-разному. Практически никогда не рекомендуется копировать локальное состояние в облаке в масштабе 1:1. Это может быть в вашем конкретном случае, но обязательно перепроверьте это.
- Поставьте под сомнение требование с некоторыми значимыми сомнениями, такими как:
- Кто будет типичным пользователем, использующим новую платформу? Находясь локально, он может быть транзакционным бизнес-пользователем; в облаке это может быть специалист по данным или аналитик хранилища данных, либо основным пользователем данных может быть служба (например, Databricks, Glue, модели машинного обучения и т. д.).
- Ожидается ли, что обычные повседневные рабочие места останутся даже после перехода в облако? Если нет, то как они должны измениться?
- Планируете ли вы значительный рост данных с течением времени? Скорее всего, ответ положительный, так как это часто является единственной и самой важной причиной миграции в облако. Для этого должна быть готова новая модель данных.
- Ожидайте, что конечный пользователь подумает о некоторых общих ожидаемых запросах, которые новая база данных будет получать от пользователей. Это определит, насколько существующая модель данных должна измениться, чтобы оставаться актуальной для производительности.
Настройка миграции
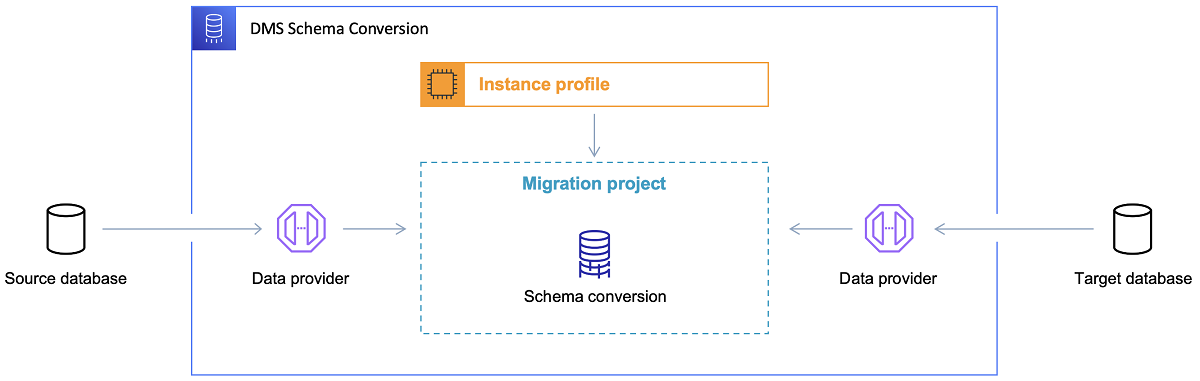
После того, как целевая база данных выбрана и модель данных удовлетворительно обсуждена, следующим шагом будет знакомство с инструментом преобразования схемы AWS. Есть несколько областей, в которых этот инструмент может служить:
- Проанализируйте и извлеките исходную модель данных. SCT прочитает, что находится в текущей локальной базе данных, и для начала создаст исходную модель данных.
- Предложите целевую структуру модели данных на основе целевой базы данных.
- Создайте сценарии развертывания целевой базы данных, чтобы установить целевую модель данных (на основе того, что инструмент обнаружил в исходной базе данных). Это сгенерирует сценарии развертывания, и после их выполнения база данных в облаке будет готова к загрузке данных из локальной базы данных.
Теперь есть несколько советов по использованию инструмента преобразования схемы.
Во-первых, почти никогда не следует использовать вывод напрямую. Я бы рассматривал это скорее как справочные результаты, из которых вы будете вносить свои коррективы на основе вашего понимания и назначения данных, а также того, как данные будут использоваться в облаке.
Во-вторых, ранее таблицы, вероятно, выбирались пользователями, ожидающими быстрых кратких результатов о каком-то конкретном объекте предметной области. Но теперь данные могут быть отобраны для аналитических целей. Например, индексы базы данных, ранее работавшие в локальной базе данных, теперь будут бесполезны и определенно не улучшат производительность системы БД, связанную с этим новым использованием. Точно так же вы можете захотеть по-другому разбить данные в целевой системе, как это было раньше в исходной системе.
Кроме того, было бы неплохо подумать о некоторых преобразованиях данных в процессе миграции, что в основном означает изменение целевой модели данных для некоторых таблиц (чтобы они больше не были копиями 1:1). Позже правила преобразования необходимо будет внедрить в инструмент миграции.
Настройка инструмента миграции
Если исходная и целевая базы данных относятся к одному и тому же типу (например, локальная база данных Oracle или Oracle в AWS, PostgreSQL или Aurora Postgresql и т. д.), то лучше всего использовать специальный инструмент миграции, который изначально поддерживает конкретная база данных ( например, экспорт и импорт перекачки данных, Oracle Goldengate и т. д.).
Однако в большинстве случаев исходная и целевая базы данных несовместимы, и тогда очевидным выбором будет служба миграции баз данных AWS.
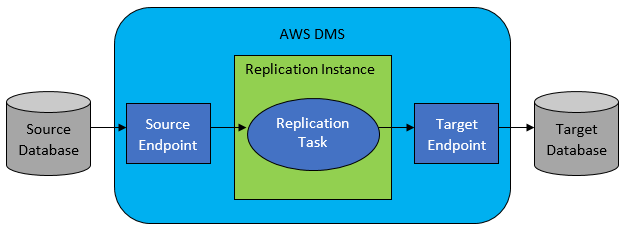
AWS DMS в основном позволяет настроить список задач на уровне таблицы, который будет определять:
- Какова точная исходная БД и таблица для подключения?
- Спецификации операторов, которые будут использоваться для получения данных для целевой таблицы.
- Инструменты преобразования (если есть), определяющие, как исходные данные должны отображаться в данные целевой таблицы (если не 1:1).
- Какова точная целевая база данных и таблица для загрузки данных?
Конфигурация задач DMS выполняется в удобном для пользователя формате, таком как JSON.
Теперь в самом простом сценарии все, что вам нужно сделать, это запустить сценарии развертывания в целевой базе данных и запустить задачу DMS. Но это еще не все.
Единовременная полная миграция данных

Легче всего выполнить запрос, когда требуется однократно переместить всю базу данных в целевую облачную базу данных. Тогда в основном все, что необходимо сделать, будет выглядеть следующим образом:

- Определите задачу DMS для каждой исходной таблицы.
- Обязательно правильно укажите конфигурацию заданий DMS. Это означает настройку разумного параллелизма, кэширование переменных, конфигурацию сервера DMS, определение размера кластера DMS и т. д. Обычно это самый трудоемкий этап, поскольку он требует тщательного тестирования и точной настройки оптимального состояния конфигурации.
- Убедитесь, что каждая целевая таблица создана (пустая) в целевой базе данных в ожидаемой структуре таблицы.
- Запланируйте временное окно, в течение которого будет выполняться миграция данных. Перед этим, очевидно, убедитесь (выполнив тесты производительности), что временного окна будет достаточно для завершения миграции. Во время самой миграции исходная база данных может быть ограничена с точки зрения производительности. Кроме того, ожидается, что исходная база данных не изменится во время выполнения миграции. В противном случае перенесенные данные могут отличаться от тех, которые хранятся в исходной базе данных после завершения миграции.
Если конфигурация DMS выполнена правильно, ничего плохого в этом сценарии не произойдет. Каждая исходная таблица будет выбрана и скопирована в целевую базу данных AWS. Единственными опасениями будут производительность действия и обеспечение правильного размера на каждом этапе, чтобы не произошло сбоя из-за нехватки места для хранения.
Инкрементная ежедневная синхронизация

Здесь все начинает усложняться. Я имею в виду, что если бы мир был идеальным, то он, вероятно, все время работал бы просто отлично. Но мир никогда не бывает идеальным.
DMS можно настроить для работы в двух режимах:
- Полная загрузка – режим по умолчанию, описанный и используемый выше. Задачи DMS запускаются либо при их запуске, либо по расписанию. После завершения задачи DMS выполняются.
- Change Data Capture (CDC) — в этом режиме задачи DMS выполняются непрерывно. DMS сканирует исходную базу данных на наличие изменений на уровне таблицы. Если изменение происходит, он немедленно пытается реплицировать изменение в целевой базе данных на основе конфигурации внутри задачи DMS, связанной с измененной таблицей.
При переходе на CDC вам нужно сделать еще один выбор, а именно, как CDC будет извлекать дельта-изменения из исходной БД.
№1. Читатель журналов повторов Oracle
Одним из вариантов является выбор собственного средства чтения журналов повторного выполнения базы данных от Oracle, которое CDC может использовать для получения измененных данных и, на основе последних изменений, реплицировать те же изменения в целевой базе данных.
Хотя это может показаться очевидным выбором при работе с Oracle в качестве источника, есть одна загвоздка: средство чтения журналов повторного выполнения Oracle использует исходный кластер Oracle и, таким образом, напрямую влияет на все другие действия, выполняемые в базе данных (на самом деле, оно напрямую создает активные сеансы в базу данных).
Чем больше задач DMS вы настроили (или чем больше кластеров DMS параллельно), тем больше вам, вероятно, потребуется увеличить размер кластера Oracle — в основном, отрегулировать вертикальное масштабирование вашего основного кластера базы данных Oracle. Это, безусловно, повлияет на общую стоимость решения, особенно если ежедневная синхронизация будет оставаться в проекте в течение длительного периода времени.
№ 2. AWS DMS Log Miner
В отличие от варианта выше, это собственное решение AWS для той же проблемы. В этом случае DMS не влияет на исходную БД Oracle. Вместо этого он копирует журналы повторов Oracle в кластер DMS и выполняет там всю обработку. Хотя это экономит ресурсы Oracle, это более медленное решение, так как задействовано больше операций. А также, как можно легко предположить, пользовательский ридер для журналов повторного выполнения Oracle, вероятно, медленнее в своей работе, чем собственный ридер от Oracle.
В зависимости от размера исходной базы данных и количества ежедневных изменений, в лучшем случае вы можете получить инкрементную синхронизацию данных из локальной базы данных Oracle в облачную базу данных AWS почти в режиме реального времени.
В любых других сценариях это все равно не будет близко к синхронизации в реальном времени, но вы можете попытаться максимально приблизиться к допустимой задержке (между исходным и целевым), настроив конфигурацию производительности исходного и целевого кластеров и параллелизм или поэкспериментировав с количество задач DMS и их распределение между экземплярами CDC.
И вы можете узнать, какие изменения исходной таблицы поддерживаются CDC (например, добавление столбца), потому что не все возможные изменения поддерживаются. В некоторых случаях единственный способ — вручную изменить целевую таблицу и перезапустить задачу CDC с нуля (попутно потеряв все существующие данные в целевой базе данных).
Когда что-то идет не так, несмотря ни на что

Я понял это на собственном горьком опыте, но есть один конкретный сценарий, связанный с DMS, где трудно добиться ежедневной репликации.
DMS может обрабатывать журналы повторов только с определенной скоростью. Неважно, есть ли еще экземпляры DMS, выполняющие ваши задачи. Тем не менее, каждый экземпляр DMS читает журналы повторов только с одной определенной скоростью, и каждый из них должен читать их целиком. Даже не имеет значения, используете ли вы журналы повторов Oracle или майнер журналов AWS. Оба имеют этот предел.
Если исходная база данных включает большое количество изменений в течение дня, а журналы повторного выполнения Oracle становятся безумно большими (например, более 500 ГБ) каждый день, CDC просто не будет работать. Репликация не будет завершена до конца дня. Это перенесет некоторую необработанную работу на следующий день, где уже ждет новый набор изменений, которые нужно реплицировать. Количество необработанных данных будет только расти день ото дня.
В данном конкретном случае CDC не подходил (после многих тестов производительности и попыток, которые мы выполнили). Единственный способ гарантировать, что по крайней мере все дельта-изменения текущего дня будут воспроизведены в тот же день, — это подойти к этому следующим образом:
- Отделяйте действительно большие таблицы, которые используются не так часто, и реплицируйте их только раз в неделю (например, по выходным).
- Настроить репликацию не очень больших, но все же больших таблиц для разделения между несколькими задачами DMS; в конечном итоге одна таблица была перенесена 10 или более отдельными задачами DMS параллельно, что обеспечило разделение данных между задачами DMS (здесь задействовано специальное кодирование) и их ежедневное выполнение.
- Добавьте больше (в данном случае до 4) экземпляров DMS и равномерно распределите задачи DMS между ними, то есть не только по количеству таблиц, но и по размеру.
По сути, мы использовали режим полной загрузки DMS для репликации ежедневных данных, потому что это был единственный способ добиться завершения репликации данных хотя бы в тот же день.
Не идеальное решение, но оно все еще есть, и даже спустя много лет все так же работает. Так что, может быть, не так уж плохо решение в конце концов.