
Объяснение регрессии и классификации в машинном обучении
Опубликовано: 2022-12-19Регрессия и классификация являются двумя наиболее фундаментальными и важными областями машинного обучения.
Может быть сложно отличить алгоритмы регрессии от алгоритмов классификации, когда вы только начинаете изучать машинное обучение. Понимание того, как работают эти алгоритмы и когда их использовать, может иметь решающее значение для создания точных прогнозов и эффективных решений.
Во-первых, давайте посмотрим на машинное обучение.
Что такое машинное обучение?

Машинное обучение — это метод обучения компьютеров обучению и принятию решений без явного программирования. Он включает в себя обучение компьютерной модели на наборе данных, что позволяет модели делать прогнозы или принимать решения на основе закономерностей и взаимосвязей в данных.
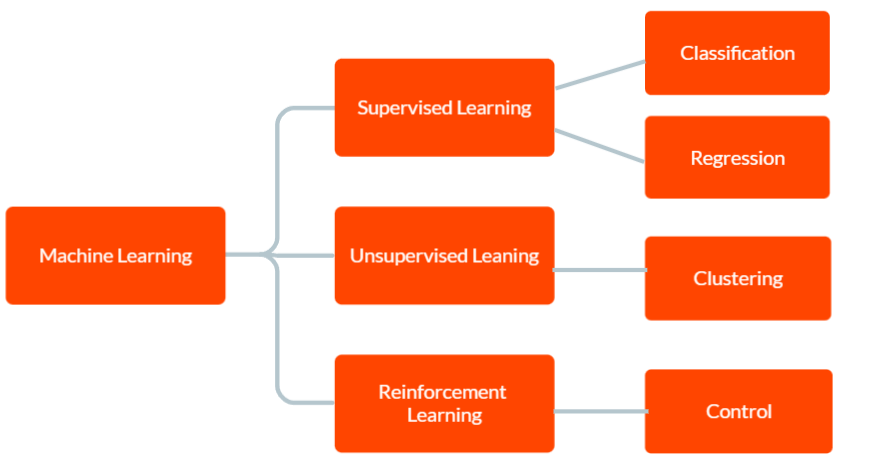
Существует три основных типа машинного обучения: обучение с учителем, обучение без учителя и обучение с подкреплением.
В контролируемом обучении модели предоставляются помеченные обучающие данные, включая входные данные и соответствующие правильные выходные данные. Цель состоит в том, чтобы модель делала прогнозы о выводе новых, невидимых данных на основе шаблонов, которые она извлекла из обучающих данных.
В неконтролируемом обучении модель не получает никаких помеченных обучающих данных. Вместо этого остается самостоятельно обнаруживать закономерности и взаимосвязи в данных. Это можно использовать для идентификации групп или кластеров в данных или для поиска аномалий или необычных закономерностей.
А в Reinforcement Learning агент учится взаимодействовать с окружающей средой, чтобы максимизировать вознаграждение. Он включает в себя обучение модели принимать решения на основе обратной связи, которую она получает от окружающей среды.
Машинное обучение используется в различных приложениях, включая распознавание изображений и речи, обработку естественного языка, обнаружение мошенничества и беспилотные автомобили. Он может автоматизировать многие задачи и улучшить процесс принятия решений в различных отраслях.
В этой статье основное внимание уделяется концепциям классификации и регрессии, которые относятся к контролируемому машинному обучению. Давайте начнем!
Классификация в машинном обучении

Классификация — это метод машинного обучения, который включает в себя обучение модели присвоению метки класса заданным входным данным. Это контролируемая задача обучения, что означает, что модель обучается на помеченном наборе данных, который включает примеры входных данных и соответствующие метки классов.
Модель направлена на изучение взаимосвязи между входными данными и метками классов, чтобы предсказать метку класса для новых, невидимых входных данных.
Существует множество различных алгоритмов, которые можно использовать для классификации, включая логистическую регрессию, деревья решений и методы опорных векторов. Выбор алгоритма будет зависеть от характеристик данных и желаемой производительности модели.
Некоторые распространенные приложения классификации включают обнаружение спама, анализ настроений и обнаружение мошенничества. В каждом из этих случаев входные данные могут включать текст, числовые значения или их комбинацию. Метки классов могут быть бинарными (например, спам или не спам) или мультиклассовыми (например, положительные, нейтральные, отрицательные настроения).
Например, рассмотрим набор данных отзывов клиентов о продукте. Входными данными может быть текст отзыва, а меткой класса может быть рейтинг (например, положительный, нейтральный, отрицательный). Модель будет обучена на наборе данных помеченных обзоров, а затем сможет предсказать рейтинг нового обзора, которого она раньше не видела.
Типы алгоритмов классификации ML
В машинном обучении существует несколько типов алгоритмов классификации:
Логистическая регрессия
Это линейная модель, используемая для бинарной классификации. Он используется для прогнозирования вероятности наступления определенного события. Цель логистической регрессии — найти наилучшие коэффициенты (веса), минимизирующие ошибку между прогнозируемой вероятностью и наблюдаемым результатом.
Это делается с помощью алгоритма оптимизации, такого как градиентный спуск, для настройки коэффициентов до тех пор, пока модель не будет максимально соответствовать обучающим данным.
Деревья решений
Это древовидные модели, которые принимают решения на основе значений признаков. Их можно использовать как для бинарной, так и для многоклассовой классификации. Деревья решений имеют ряд преимуществ, в том числе их простоту и совместимость.
Они также быстро обучаются и делают прогнозы, и они могут обрабатывать как числовые, так и категориальные данные. Однако они могут быть склонны к переоснащению, особенно если дерево глубокое и имеет много ветвей.
Случайная классификация леса
Классификация случайного леса — это метод ансамбля, который объединяет прогнозы нескольких деревьев решений для получения более точного и стабильного прогноза. Оно менее подвержено переоснащению, чем одно дерево решений, поскольку прогнозы отдельных деревьев усредняются, что снижает дисперсию модели.
АдаБуст
Это алгоритм повышения, который адаптивно изменяет вес ошибочно классифицированных примеров в обучающем наборе. Он часто используется для бинарной классификации.
Наивный Байес
Наивный Байес основан на теореме Байеса, которая представляет собой способ обновления вероятности события на основе новых данных. Это вероятностный классификатор, часто используемый для классификации текста и фильтрации спама.
K-ближайший сосед
K-ближайшие соседи (KNN) используются для задач классификации и регрессии. Это непараметрический метод, который классифицирует точку данных на основе класса ее ближайших соседей. KNN имеет несколько преимуществ, в том числе простоту и простоту реализации. Он также может обрабатывать как числовые, так и категориальные данные и не делает никаких предположений о базовом распределении данных.
Повышение градиента
Это ансамбли слабых учеников, которые обучаются последовательно, при этом каждая модель пытается исправить ошибки предыдущей модели. Их можно использовать как для классификации, так и для регрессии.
Регрессия в машинном обучении
В машинном обучении регрессия — это тип контролируемого обучения, целью которого является прогнозирование зависимой переменной переменного тока на основе одного или нескольких входных признаков (также называемых предикторами или независимыми переменными).
Алгоритмы регрессии используются для моделирования взаимосвязи между входными и выходными данными и прогнозирования на основе этой взаимосвязи. Регрессия может использоваться как для непрерывных, так и для категориальных зависимых переменных.

В общем, цель регрессии состоит в том, чтобы построить модель, которая может точно предсказать выходные данные на основе входных функций и понять базовую связь между входными функциями и выходными данными.
Регрессионный анализ используется в различных областях, включая экономику, финансы, маркетинг и психологию, для понимания и прогнозирования взаимосвязей между различными переменными. Это фундаментальный инструмент в анализе данных и машинном обучении, который используется для прогнозирования, выявления тенденций и понимания основных механизмов, управляющих данными.
Например, в простой модели линейной регрессии целью может быть прогнозирование цены дома на основе его размера, местоположения и других характеристик. Размер дома и его расположение будут независимыми переменными, а цена дома будет зависимой переменной.
Модель будет обучаться на входных данных, которые включают размер и расположение нескольких домов, а также их соответствующие цены. После того, как модель обучена, ее можно использовать для прогнозирования цены дома с учетом его размера и местоположения.
Типы алгоритмов регрессии ML
Алгоритмы регрессии доступны в различных формах, и использование каждого алгоритма зависит от количества параметров, таких как тип значения атрибута, шаблон линии тренда и количество независимых переменных. Методы регрессии, которые часто используются, включают:
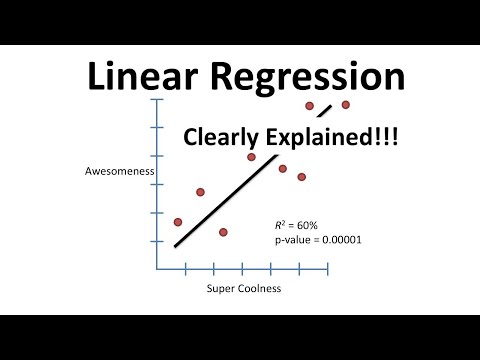
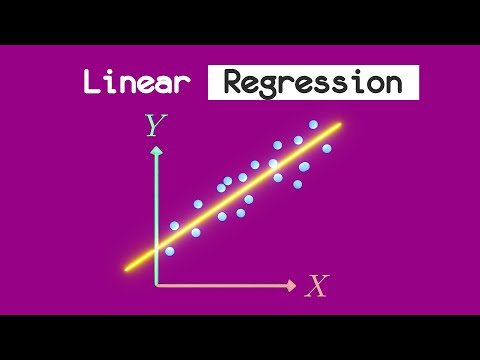
Линейная регрессия
Эта простая линейная модель используется для прогнозирования непрерывного значения на основе набора признаков. Он используется для моделирования взаимосвязи между функциями и целевой переменной путем подгонки линии к данным.
Полиномиальная регрессия
Это нелинейная модель, которая используется для подбора кривой к данным. Он используется для моделирования взаимосвязей между функциями и целевой переменной, когда взаимосвязь не является линейной. Он основан на идее добавления членов более высокого порядка к линейной модели для фиксации нелинейных отношений между зависимыми и независимыми переменными.
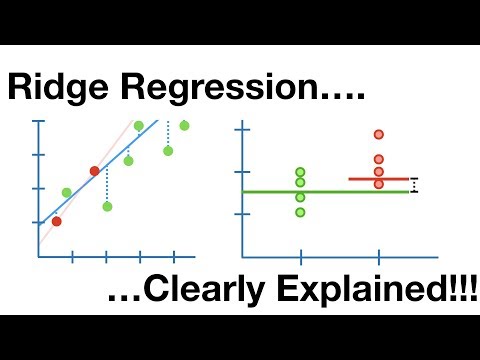
Ридж-регрессия
Это линейная модель, которая решает проблему переобучения в линейной регрессии. Это регуляризованная версия линейной регрессии, которая добавляет штрафной член к функции стоимости, чтобы уменьшить сложность модели.
Опорная векторная регрессия
Как и SVM, регрессия опорных векторов представляет собой линейную модель, которая пытается подобрать данные, находя гиперплоскость, которая максимизирует разницу между зависимыми и независимыми переменными.
Однако, в отличие от SVM, которые используются для классификации, SVR используется для задач регрессии, где цель состоит в том, чтобы предсказать непрерывное значение, а не метку класса.
Лассо-регрессия
Это еще одна регуляризованная линейная модель, используемая для предотвращения переобучения в линейной регрессии. Он добавляет штрафной член к функции стоимости на основе абсолютного значения коэффициентов.
Байесовская линейная регрессия
Байесовская линейная регрессия — это вероятностный подход к линейной регрессии, основанный на теореме Байеса, которая представляет собой способ обновления вероятности события на основе новых данных.
Эта регрессионная модель предназначена для оценки апостериорного распределения параметров модели с учетом данных. Это делается путем определения априорного распределения параметров и последующего использования теоремы Байеса для обновления распределения на основе наблюдаемых данных.
Регрессия против классификации
Регрессия и классификация — это два типа контролируемого обучения, что означает, что они используются для прогнозирования результата на основе набора входных признаков. Однако между ними есть некоторые ключевые различия:
| Регрессия | Классификация | |
| Определение | Тип контролируемого обучения, который прогнозирует непрерывное значение | Тип контролируемого обучения, который прогнозирует категориальное значение |
| Тип выхода | Непрерывный | Дискретный |
| Метрики оценки | Среднеквадратическая ошибка (MSE), среднеквадратическая ошибка (RMSE) | Точность, точность, отзыв, оценка F1 |
| Алгоритмы | Линейная регрессия, Лассо, Ридж, KNN, Дерево решений | Логистическая регрессия, SVM, Наивный Байес, KNN, Дерево решений |
| Сложность модели | Менее сложные модели | Более сложные модели |
| Предположения | Линейная связь между функциями и целью | Никаких конкретных предположений о взаимосвязи между функциями и целью |
| Дисбаланс классов | Непригодный | Это может быть проблемой |
| Выбросы | Может повлиять на производительность модели | Обычно не проблема |
| Важность функции | Особенности ранжируются по важности | Особенности не ранжируются по важности |
| Примеры приложений | Прогнозирование цен, температур, количества | Прогнозирование спама по электронной почте, прогнозирование оттока клиентов |
Образовательные ресурсы
Может быть сложно выбрать лучшие онлайн-ресурсы для понимания концепций машинного обучения. Мы изучили популярные курсы, предоставляемые надежными платформами, чтобы представить вам наши рекомендации по лучшим курсам машинного обучения по регрессии и классификации.
№1. Учебный курс по классификации машинного обучения в Python
Этот курс предлагается на платформе Udemy. Он охватывает множество алгоритмов и методов классификации, включая деревья решений и логистическую регрессию, а также поддерживает векторные машины.

Вы также можете узнать о таких темах, как переоснащение, компромисс смещения и дисперсии и оценка модели. В курсе используются библиотеки Python, такие как sci-kit-learn и pandas, для реализации и оценки моделей машинного обучения. Таким образом, для начала работы с этим курсом необходимы базовые знания Python.
№ 2. Мастер-класс по регрессии машинного обучения в Python
В этом курсе Udemy тренер охватывает основы и базовую теорию различных алгоритмов регрессии, включая линейную регрессию, полиномиальную регрессию и методы регрессии Лассо и Риджа.
К концу этого курса вы сможете внедрять алгоритмы регрессии и оценивать производительность обученных моделей машинного обучения с использованием различных ключевых показателей эффективности.
Подведение итогов
Алгоритмы машинного обучения могут быть очень полезны во многих приложениях и могут помочь автоматизировать и оптимизировать многие процессы. Алгоритмы машинного обучения используют статистические методы для изучения закономерностей в данных и делают прогнозы или решения на основе этих закономерностей.
Их можно обучать на больших объемах данных и использовать для выполнения задач, которые людям было бы трудно или отнимать много времени вручную.
Каждый алгоритм ML имеет свои сильные и слабые стороны, и выбор алгоритма зависит от характера данных и требований задачи. Важно выбрать подходящий алгоритм или комбинацию алгоритмов для конкретной проблемы, которую вы пытаетесь решить.
Важно выбрать правильный тип алгоритма для вашей задачи, так как использование неправильного типа алгоритма может привести к снижению производительности и неточным прогнозам. Если вы не уверены, какой алгоритм использовать, может быть полезно попробовать алгоритмы регрессии и классификации и сравнить их эффективность в вашем наборе данных.
Я надеюсь, что вы нашли эту статью полезной для изучения регрессии и классификации в машинном обучении. Вам также может быть интересно узнать о лучших моделях машинного обучения.