
Правильный способ запретить индексацию страницы
Опубликовано: 2022-12-02Это может показаться нелогичным, но не каждая страница вашего сайта должна отображаться в результатах поиска. Поисковая оптимизация (SEO) направлена на повышение видимости в поиске и органического трафика, и иногда вы можете лучше всего достичь этой цели, ограничивая контент, который может отображаться в результатах поиска.
Если вы ломаете голову или считаете, что я блефую, читайте дальше, чтобы узнать о преимуществах отсутствия индексации страницы или подкаталога и о том, как реализовать теги noindex.
Что означает Noindex?
Термин «noindex» — это специальная директива в метатеге robots, которая указывает поисковым роботам исключить страницу из страниц результатов поисковой системы (SERP). Это означает, что искатели не смогут получить доступ к странице через поиск.
Метатеги robots являются ценной частью любой технической SEO-стратегии и позволяют исключать страницы, которые не представляют ценности для пользователей или содержат информацию, которую вы не хотите отображать в результатах поиска, например:
- Страницы подтверждения и благодарности
- Страницы входа
- Политика конфиденциальности или страница условий обслуживания
- Закрытый контент
- Сообщения об ошибках
Сравнение метатегов Robots.txt и X-Robots
Метатег robots часто путают с файлом robots.txt и тегом x-robots. Все три дают инструкции поисковым роботам на страницах и являются частью протокола исключения роботов (REP). Проще говоря: они сообщают Google, что вводить в поиск Google, а что не включать в него, а также какие страницы следует сканировать. Однако они не могут и не должны использоваться взаимозаменяемо.
Метатег роботов
Метатег robots добавляется в раздел <head> определенной веб-страницы и передает инструкции только для этой конкретной страницы. Метатег robots, который часто называют тегом noindex или метатегом noindex, может сделать больше, чем просто указать поисковому роботу не индексировать страницу.
Его также можно использовать, чтобы попросить сканеров не переходить по ссылкам, перевести страницу, заблокировать определенного поискового робота или предотвратить появление кэшированной ссылки в поисковой выдаче.
Общие директивы метатегов robots включают:
- Noindex, nofollow — <meta name="robots" content="noindex, nofollow">
Googlebot и другие поисковые роботы могут получить доступ к странице, но они не должны индексировать ее или переходить по ее ссылкам. - Noindex, следуйте — <meta name="robots" content="noindex">
Робот Googlebot и другие поисковые роботы могут получать доступ к странице и переходить по ссылкам на ней, но они не должны индексировать саму страницу. Вам не нужно включать «follow» в метатег, так как это значение по умолчанию.
Роботы.txt
Robots.txt — это файл, который позволяет владельцам сайтов сообщать поисковым системам, какие части их сайта они не должны сканировать. Это похоже на личную табличку «Не беспокоить» для вашего веб-сайта, которая висит в корневом каталоге вашего домена или поддомена.
Файл robots.txt лучше всего подходит для блокировки доступа и сканирования целых подкаталогов, а не отдельных страниц. Используйте его, чтобы заблокировать поисковым роботам доступ и индексацию:
- Страницы внутреннего поиска
- URL-параметры
- Форумы, на которых пользовательский спам может вызвать проблемы
- Внутренние подкаталоги, такие как те, которые предназначены только для сотрудников
Выполните следующие действия, чтобы создать файл robots.txt и обязательно укажите ссылку на карту сайта в формате XML.
Если вы ссылаетесь на страницу, включенную в файл robots.txt, вы можете также добавить к ней метатег robots, чтобы она не отображалась в результатах поиска. Помните: robots.txt блокирует доступ поисковых роботов к странице, но не ее индексацию. Если страницы, на которые распространяются ваши директивы robots.txt, получают внешние ссылки, поисковые системы могут их проиндексировать. Чтобы избежать этого, используйте метатег robots вместе с файлом robots.txt.
X-роботы Тег
Чтобы заблокировать отображение PDF, видео или изображения в поисковой выдаче, используйте тег x-robots. Те же самые директивы, указанные для метатегов robots, используются для x-robots. Однако, в отличие от метатега robots, который находится в заголовке HTML страницы, тег x-robots размещается в ответе заголовка HTTP.
Директива выглядит так:
X-Robots-Tag: noindexКогда не индексировать страницу
Раздувание индекса ограничения
Раздувание индекса происходит, когда Google индексирует страницы, практически не представляющие ценности для пользователей. Эти посторонние страницы отвлекают ресурсы от более ценных страниц. Используйте метатег robots, чтобы управлять тем, какие страницы будут отображаться в результатах поиска.
Искоренить каннибализацию ключевых слов
Каннибализация ключевых слов происходит, когда две страницы имеют одинаковое ключевое слово и цель поиска, что заставляет их конкурировать друг с другом в поисковой выдаче.
Если у вас есть две страницы, поглощающие друг друга, и вы хотите сохранить обе без изменения их содержимого, не индексируйте одну из них. Тем не менее, вы должны делать это только в том случае, если страница, которую вы не индексируете, не привлекает трафик по ключевым словам, которых нет на другой странице. В такой ситуации вам может потребоваться переработать контент на одной или обеих страницах, чтобы решить проблему каннибализации.
Защитите закрытые целевые страницы
Когда вы предлагаете ценный ресурс клиентам в обмен на контактную информацию, убедитесь, что он недоступен каким-либо другим способом. Добавьте метатег robots, чтобы не индексировать страницу, чтобы она не отображалась в поисковой выдаче.
Исключить непопулярные товары из поиска
Сайты электронной коммерции часто предлагают продукты для обслуживания определенных клиентов, даже если спрос на них не слишком велик. Например, у продавца автозапчастей или у другой технической компании могут быть товары для конкретных моделей или редкого оборудования. Если эти страницы продуктов или категорий не привлекают органического трафика, их можно вообще не индексировать.
Как запретить индексацию веб-страницы
Метатег noindex размещается в заголовке HTML-кода страницы. Код не чувствителен к регистру и выглядит так:
<meta name="robots" content="noindex">«Роботы» означает, что директива применяется к любому сканеру, но вы можете выделить сканеры, заменив «роботы» известными именами сканеров, такими как «Googlebot» или «bingbot».

Поисковые роботы по-прежнему будут переходить по ссылкам на странице, если вы не добавите команду nofollow. Вы можете сделать это, чтобы предотвратить прохождение ссылочного капитала через страницу или предотвратить переход сканера по ссылке на закрытый контент.
Чтобы добавить значение nofollow, отделите его от директивы noindex запятой.
<meta name="robots" content="noindex, nofollow">Примечание. Прежде чем запретить индексирование страницы, проверьте, есть ли на ней входящий органический трафик в Google Search Console. Если это так, определите, как ваш сайт может продолжать захватывать этот трафик, прежде чем не индексировать страницу.
Как добавить метатег Robots в ваш HTML-код
- Откройте исходный код страницы, которую вы хотите запретить индексировать.
- Найдите заголовок в верхней части страницы. Он начинается с <head> и заканчивается на </head>. Вероятно, в заголовке будет и другой код.
- Добавьте метатег robots в новую строку так, чтобы он отображался между тегами <head> и </head>.
Вот и все! Если ваша страница уже проиндексирована, вы можете попросить Google повторно просканировать ее, вставив ее URL-адрес в инструмент проверки URL-адресов.
Уже проиндексировано? Используйте инструмент для удаления URL-адресов
Когда вы добавляете тег noindex на новую страницу контента, робот Googlebot увидит директиву при сканировании страницы и не будет ее индексировать.
Однако если вы добавляете тег на уже проиндексированную страницу , эта страница будет отображаться в результатах поиска до тех пор, пока она не будет просканирована повторно и боты не увидят новые инструкции noindex. Вы можете попросить Google повторно просканировать URL-адрес в Google Search Console с помощью инструмента проверки URL-адресов, но это не приведет к мгновенному удалению страницы из поисковой выдачи.
Если вам нужно немедленно удалить страницу из поисковой выдачи, используйте инструмент удаления в Google Search Console. Это предотвратит появление страниц в результатах поиска Google примерно на шесть месяцев. К тому времени метатег noindex должен работать.
Как не индексировать страницу в WordPress
Каждая страница в WordPress индексируется по умолчанию. Вы можете использовать плагин Yoast SEO, чтобы не индексировать страницу в WordPress без написания кода. Вот как.
Перейдите на вкладку «Дополнительно» в мета-поле Yoast SEO.
Под вопросом «Разрешить поисковым системам показывать этот пост в результатах поиска?» выберите «Нет» в раскрывающемся списке.
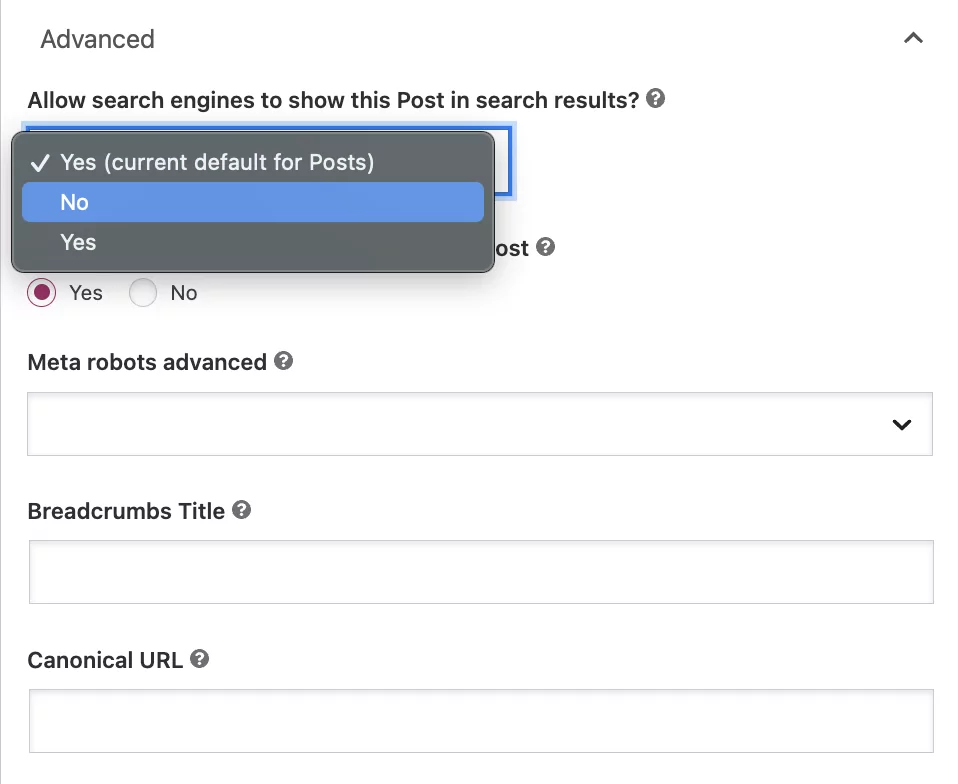
Хотя этот параметр предписывает Google не индексировать сообщение, боты по-прежнему будут автоматически переходить по ссылкам на странице для сканирования других страниц.
Если вы хотите добавить директиву nofollow, нажмите кнопку «Нет» под вопросом: «Должны ли поисковые системы переходить по ссылкам в этом сообщении?»
Часто задаваемые вопросы о метатегах роботов
Все ли поисковые системы подчиняются директиве noindex?
Вы можете ожидать, что Google, Bing и другие законные поисковые системы будут соблюдать метатег robots.
Могу ли я ссылаться на неиндексированные страницы?
Да. Тег noindex сообщает поисковым роботам, как обрабатывать страницу при сканировании и индексировании. Это не влияет на вашу способность ссылаться на страницу. Это может быть полезно для страниц категорий в блоге, которые не должны отображаться в результатах поиска, но могут предоставить ботам ссылки на ценные страницы, которые должны.
Когда следует использовать метатег robots?
Если у вас есть страница, которая не представляет никакой ценности для пользователей, например страница благодарности или страница для печати, не индексируйте ее с помощью метатега robots, чтобы она не отображалась в поисковой выдаче.
Когда я не должен использовать директиву noindex?
Технически вы можете решить проблемы с дублированием контента и некоторые проблемы с краулинговым бюджетом с помощью директив noindex, но это не лучший способ сделать это. Дублированный контент лучше всего обрабатывается с помощью канонических тегов, которые концентрируют ссылочный вес дубликатов на каноническую страницу. Если вы пытаетесь сэкономить бюджет сканирования, вам следует использовать файл robots.txt, чтобы запретить сканирование этого раздела сайта.
Пропускают ли неиндексированные страницы ссылочный вес?
Да. Несмотря на то, что страница не проиндексирована, она все равно может иметь общий авторитет ранжирования. Однако поисковые роботы должны иметь возможность переходить по ссылкам на странице, чтобы ссылочный вес проходил через них. Если для страницы установлены значения noindex и nofollow, она не может передать ссылочный вес.
Удаляет ли страница без индексирования автоматически ее из поисковой выдачи Google?
Если ваша страница уже проиндексирована, добавление метатега robots не приведет к ее автоматическому удалению из результатов поиска. Чтобы страницы, которые уже проиндексированы, исчезли из поисковой выдачи, требуется некоторое время. Поисковым ботам необходимо повторно просканировать страницы, чтобы увидеть тег noindex. Чтобы получить более быстрые результаты, попросите Google повторно просканировать страницу и использовать инструмент для удаления URL.
Выявление проблемных страниц с помощью SEO-аудита
Не позволяйте неполноценному или дублированному контенту влиять на вашу видимость в поиске. Убедитесь, что вы даете своим страницам наилучшие шансы на ранжирование. Наш SEO-аудит, насчитывающий более 200 баллов, выявляет такие проблемы, как дублирование контента, отсутствие файла robots.txt, неправильное применение метатегов robots, раздувание индекса и многое другое. Запишитесь на бесплатную консультацию по SEO, чтобы узнать, как наша служба SEO-аудита может увеличить вашу видимость в Интернете и помочь вашему бизнесу расти.