
Что такое отказоустойчивая кластеризация? Как это работает + решения
Опубликовано: 2023-09-22Компании, которым необходимы онлайн-транзакции, не могут позволить себе поломки серверов. В результате эти компании ищут способы создать отказоустойчивую процедуру, которая сохранит их данные в безопасности, даже если сервер выйдет из строя. Одним из таких методов является отказоустойчивая кластеризация.
Отказоустойчивая кластеризация может управляться решениями поставщика управляемой системы доменных имен (DNS); однако понимание его механизма и ключевых функций может помочь ограничить любые проблемы с аварийным переключением.
Что такое отказоустойчивая кластеризация?
Отказоустойчивый кластер работает на группе компьютерных серверов, обеспечивая высокую доступность (HA) или постоянную доступность (CA) для серверных приложений. Эта технология гарантирует, что в случае сбоя одного сервера или узла другой узел кластера будет готов принять рабочую нагрузку без сбоев.
Такой подход обеспечивает масштабируемость и доступность рабочих нагрузок вашего сервера. Многие основные серверные программы, такие как Microsoft Exchange , Microsoft SQL Server и Hyper-V , для своей защиты полагаются на отказоустойчивую кластеризацию.
В некоторых отказоустойчивых кластерах используются физические серверы, а в других — виртуальные машины (ВМ) . Каждый выбирает тип кластера, который ему нужен, исходя из требований своего серверного приложения.
Кластер состоит из двух или более узлов, которые обмениваются данными и программным обеспечением для обработки через физические кабели или специализированную защищенную сеть. Технологии кластеризации нескольких типов могут использоваться для балансировки нагрузки, хранения, а также параллельных или параллельных вычислений. В некоторых случаях отказоустойчивые кластеры сочетаются с дополнительными технологиями кластеризации.
Основная функция отказоустойчивого кластера — предоставление CA или HA для приложений и служб. Кластеры CA, также известные как отказоустойчивые кластеры (FT), позволяют конечным пользователям продолжать использовать приложения и службы даже в случае сбоя сервера. Вы можете увидеть кратковременный перерыв в обслуживании, вызванный кластерами высокой доступности, но система может восстановиться без потери данных и с небольшим временем простоя.
Почему важна отказоустойчивая кластеризация?
Благодаря отказоустойчивой кластеризации вы можете восстанавливать неактивные узлы, не выключая базу данных, избегая простоев и быстро восстанавливая сломанные серверы. Более того, в случае аппаратного сбоя этот метод завершает работу базы данных, чтобы защитить активные узлы.
Отказоустойчивая кластеризация также автоматизирует восстановление данных в случае сбоя. Это снижает вашу зависимость от специалистов по информационным технологиям (ИТ) и позволяет вашим серверам быстро восстановиться. Он также обеспечивает превосходную доступность кластера языка структурированных запросов (SQL) с минимальным временем простоя. Функция автоматического переключения при отказе кластеризации сохраняет работоспособность вашей базы данных даже в случае сбоя оборудования.
Как работают отказоустойчивые кластеры?
Отказоустойчивая кластеризация состоит из двух фундаментальных процессов: HA и CA, для серверных приложений.
В то время как отказоустойчивые кластеры CA пытаются достичь 100% доступности, кластеры HA стремятся к 99,999%, что широко известно как пять девяток. Общее время простоя составляет не более 5,26 минут в год. Кластеры CA имеют более высокую доступность, но для работы требуется больше оборудования, что увеличивает их общую стоимость.
Отказоустойчивые кластеры высокой доступности
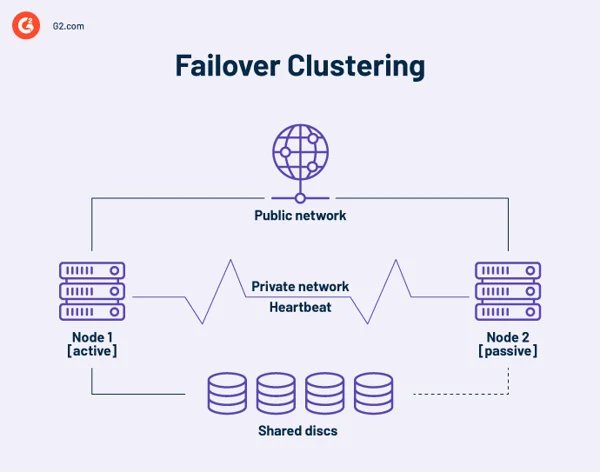
Кластер высокой доступности — это совокупность независимых компьютеров, которые совместно используют ресурсы и данные. Узлы отказоустойчивого кластера имеют доступ к общему хранилищу. Канал мониторинга также включен в кластеры высокой доступности для проверки работоспособности и работоспособности других серверов. Heartbeat — это частная сеть, совместно используемая только узлами кластера. Он недоступен снаружи.
В любой момент хотя бы один узел в кластере активен, а по крайней мере один — бездействующий или пассивный.
В базовой схеме с двумя узлами, если узел 1 выходит из строя, узел 2 распознает сбой через контрольное соединение и настраивает себя в качестве активного узла. Программное обеспечение для кластеризации на каждом узле гарантирует подключение клиентов к активному узлу.
В более крупных установках для администрирования кластера могут использоваться выделенные серверы. Сервер управления кластером всегда отправляет сигналы пульса, чтобы идентифицировать сбойные узлы и, если да, сообщить другому узлу, чтобы тот взял на себя работу.
Некоторые программные инструменты управления кластером обеспечивают высокую доступность виртуальных машин, группируя машины и серверы в кластер. В случае сбоя хоста другой хост возобновляет работу виртуальных машин.
Как возможная единственная точка отказа, общее хранилище представляет собой риск. Однако объединение резервного массива независимых дисков 6 и 10 (т.н. RAID 6 и RAID 10) может помочь поддерживать работоспособность даже в случае выхода из строя двух жестких дисков.
Электроэнергия может стать еще одной точкой отказа, если все серверы подключены к одной сети. Обеспечение каждого узла собственным источником бесперебойного питания (ИБП) обеспечивает их защиту.
Отказоустойчивые кластеры с постоянной доступностью
В отличие от парадигмы высокой доступности, отказоустойчивый кластер состоит из множества компьютеров, на которых используется одна копия операционной системы (ОС) компьютера. Программные команды, данные одной системе, также выполняются в других системах.
CA настаивает на том, что в организации используется отформатированное компьютерное оборудование и резервный ИБП. Центру сертификации необходима постоянно доступная и почти идеальная копия физической или виртуальной системы, на которой работает сервис. Эта модель резервирования известна как 2N.
Системы CA могут компенсировать широкий спектр неисправностей. Отказоустойчивая система может выявить неисправность:
- Жесткий диск
- Процессор в компьютере
- Подсистема ввода и вывода (I/O)
- Источник питания
- Компонент сети
Точка сбоя может быть обнаружена быстро, и ее место может быть немедленно заменено резервным компонентом или методом, не нарушая работу следующей службы.
Программное обеспечение кластеризации может соединять два или более серверов, чтобы они работали как один виртуальный сервер, или создавать различные альтернативные конфигурации отказоустойчивого кластера ЦС. Например, если один из виртуальных серверов выходит из строя, остальные реагируют временным удалением виртуального сервера из кворума кластера. Затем виртуальный сервер перераспределяет нагрузку между другими серверами до тех пор, пока вышедший из строя сервер не будет готов к перезапуску.
Альтернативой отказоустойчивым кластерам CA является двойной аппаратный сервер , на котором реплицируются все физические компоненты. Они выполняют вычисления отдельно и одновременно на различных аппаратных платформах и синхронизируются с помощью выделенного узла, который отслеживает результаты с обоих физических серверов. Хотя это решение обеспечивает защиту, оно может быть более дорогим.
Функции отказоустойчивой кластеризации
Многие организации используют отказоустойчивую кластеризацию для критически важных приложений. Это связано с тем, что следующие характеристики делают отказоустойчивую кластеризацию важным методом.
- Масштабируемость . Поскольку отказоустойчивая кластеризация основана на группе кластеров, взаимодействующих для предотвращения сбоя сервера, вы можете легко масштабировать ее по мере необходимости, добавляя новые кластеры.
- Стабильность: кластерные серверы подключаются посредством проводов. Остальные кластеры по-прежнему смогут предоставлять услуги, даже если один или несколько из них выйдут из строя из-за внешних факторов.
- Мониторинг в реальном времени: узлы кластера постоянно контролируются, чтобы убедиться, что они работают правильно. Когда кластер перезапускается или переносится на другой узел.
- Общий том кластера (CSV). Эта функция обеспечивает согласованное и распределенное пространство имен, которое узлы могут использовать при работе с общим хранилищем. Крайне важно, чтобы серверные приложения работали бесперебойно от начала до конца.
Типы отказоустойчивых кластеров
Значительные успехи в отказоустойчивой кластеризации произошли за последнее десятилетие, и многие организации теперь предлагают свои собственные версии кластерных решений. Здесь подробно описаны некоторые наиболее распространенные кластерные службы.

Отказоустойчивые кластеры VMware
VMware предоставляет множество технологий виртуализации для кластеров виртуальных машин. Архитектура CA vSphere vMotion точно дублирует виртуальную машину VMware и ее сеть между физическими сетями центров обработки данных.
VMware vSphere HA, второй продукт, обеспечивает высокую доступность виртуальных машин, группируя их и их хосты в кластер для автоматического переключения при отказе. Кроме того, программа не полагается на внешние компоненты, такие как DNS, что снижает количество возможных сбоев.
Отказоустойчивый кластер серверов Windows
Метод отказоустойчивого кластера серверов Windows (WSFC) способствует созданию отказоустойчивых серверов Hyper-V. В период с 2016 по 2019 год эта стратегия стала популярной среди пользователей Microsoft Windows. WSFC позволяет осуществлять мониторинг кластера и автоматически предлагает необходимый механизм аварийного переключения. В случае потери сервера WFSC перемещает кластеры на отдельный узел или пытается их перезапустить. Кроме того, технология CSV обеспечивает распределенное пространство имен, которое позволяет нескольким узлам совместно использовать память.
SQL-сервер
Этот продукт Microsoft, представленный вместе с SQL Server 2017, содержит надежные решения высокой доступности, использующие технологию WSFC. В этом контексте компоненты SQL-сервера считаются ресурсами кластера WSFC. Они дополнительно интегрированы с другими ресурсами, зависящими от WSFC. В результате WSFC имеет полномочия определять и передавать приказы о перезапуске экземпляра SQL-сервера или перемещении подобных экземпляров на новый узел.
Ред Хэт Линукс
Помимо Microsoft, другие поставщики операционных систем предлагают свои собственные отказоустойчивые кластерные решения. Например, поклонники Red Hat Enterprise Linux (RHEL) могут использовать расширение HA и глобальную файловую систему Red Hat (GFS/GFS2) для создания отказоустойчивых кластеров высокой доступности. Поддерживаются однокластерные растянутые кластеры, охватывающие множество расположений, а также многосайтовые, устойчивые к катастрофам кластеры. Репликация хранилища данных сети хранения данных (SAN) обычно используется в многосайтовых кластерах.
Применение отказоустойчивой кластеризации
Этот надежный механизм облегчает работу следующих приложений реального времени.
Наличие критически важных приложений.
Компьютеры онлайн-обработки транзакций (OLTP) должны иметь отказоустойчивые системы. OLTP, требующий полной доступности, используется в системах бронирования авиабилетов, электронной торговле акциями и банкоматах.
Многие отрасли, такие как производство, доставка и розничная торговля, используют кластеры CA или отказоустойчивые компьютеры для важных приложений. В качестве примеров можно привести электронную коммерцию, управление заказами и системы учета рабочего времени персонала.
Кластеры высокой доступности часто подходят для кластеризации приложений и сервисов, которым требуется время бесперебойной работы всего пять девяток.
Помощь при стихийных бедствиях
Аварийное восстановление также выигрывает от отказоустойчивой кластеризации. Настоятельно рекомендуется размещать серверы аварийного переключения на удаленных площадках, поскольку в случае стихийного бедствия, такого как пожар или наводнение, уничтожается все физическое оборудование и программное обеспечение.
Реплика хранилища — технология, которая дублирует тома между серверами для аварийного восстановления — включена в Windows Server 2016 и 2019. Растянутое переключение при отказе — это технологическая функция, которая позволяет отказоустойчивым кластерам охватывать два расположения.
Организации могут реплицировать данные в различные центры, расширяя отказоустойчивые кластеры. Если трагедия случается в одном месте, все данные сохраняются на резервных серверах в других.
Репликация базы данных
По словам Microsoft, WSFC был впервые запущен в Windows Server 2016 для защиты «критически важных» сервисов, таких как база данных SQL-сервера и коммуникационный сервер Microsoft Exchange.
Для репликации базы данных другие поставщики предоставляют технологию отказоустойчивого кластера. Например, MySQL Cluster имеет метод Heartbeat, который позволяет быстро обнаруживать сбои на других узлах кластера, часто менее чем за секунду, без перебоев в обслуживании клиентов.
Базы данных можно реплицировать на удаленные сайты, используя возможность географической репликации.
Преимущества отказоустойчивых кластеров
Идея отказоустойчивых кластеров заключается в том, чтобы пользователи испытывали минимальные перебои в обслуживании. Однако другие дополнительные преимущества отказоустойчивой кластеризации обсуждаются ниже.
- Повышенная доступность ресурсов: если один интеллектуальный сервер выходит из строя, остальные в кластере берут на себя эту нагрузку. Это экономит время и информацию.
- Стратегическое распределение ресурсов: вы можете распределять проекты между узлами любым удобным для вас способом. Это сводит к минимуму накладные расходы, поскольку не всем компьютерам требуется одновременное выполнение всех проектов, что дает вам возможность более свободно использовать свои ресурсы.
- Повышенная вычислительная мощность: больше машин, больше мощности.
- Большая масштабируемость. По мере расширения вашей пользовательской базы и сложности отчетов растут и ваши ресурсы.
- Упрощенное управление. Кластеризация упрощает работу с важными или быстро меняющимися системами.
Ограничения отказоустойчивой кластеризации
Какой бы важной ни была отказоустойчивая кластеризация, она сталкивается со следующими ограничениями.
- Сложные конфигурации. Конфигурация отказоустойчивого кластера для Windows требует одновременной обработки множества сетей и сетевых карт. В результате внедрение этого метода затруднено, особенно для новичков.
- Интеграция инструментов. Отказоустойчивая кластеризация Windows и Hyper-V должны быть более тесно интегрированы. Вам придется настроить каждый из них для успешного завершения отказоустойчивой кластеризации.
- Веб-интерфейс. Веб-интерфейс для настройки параметров кластера отсутствует. Чтобы получить доступ к функции диспетчера кластера, вам необходимо вручную войти на удаленный рабочий стол.
Решения отказоустойчивой кластеризации: поставщики управляемых DNS
Работая совместно с системами отказоустойчивой кластеризации, управляемые поставщики DNS перенаправляют трафик на альтернативные серверы или центры обработки данных во время аварийного переключения, обеспечивая бесперебойный доступ к вашим службам, чтобы вы могли достичь высокой доступности и минимизировать время простоя.
Пять крупнейших поставщиков управляемых DNS:
- Облачный DNS
- Azure DNS
- Инфоблок НИОС
- РАЗРАБОТЧИК WPMU
- DNS-менеджер
* Выше приведены пять ведущих поставщиков управляемого программного обеспечения DNS из отчета G2 Grid Report за осень 2023 года.

Модернизация надежности
Отказоустойчивая кластеризация стала надежным и важным вариантом обеспечения высокой доступности и отказоустойчивости в существующих ИТ-инфраструктурах. Он обеспечивает непрерывную работу, несмотря на сбои оборудования или плановое обслуживание, автоматически распределяя рабочие нагрузки и ресурсы по многочисленным сетевым узлам. Эта технология дает вам еще один способ справиться с самым важным аспектом вашего бизнеса – сделать обслуживание каждого клиента безопасным и приятным.
Повышение устойчивости вашей системы также не повредит!
Начните с руководства по безопасности DNS для разработки надежной системной стратегии.