
Развенчание 3 распространенных мифов о сканировании сайта, индексации и XML-картах сайта
Опубликовано: 2018-03-07Многие из нас ошибочно полагают, что запуск веб-сайта с XML-картой сайта автоматически приведет к сканированию и индексированию всех его страниц.
В связи с этим складывается ряд мифов и заблуждений. Наиболее распространенные из них:
- Google автоматически сканирует все сайты и делает это быстро.
- При сканировании веб-сайта Google переходит по всем ссылкам и посещает все его страницы и сразу включает их все в индекс.
- Добавление XML-карты сайта — лучший способ обеспечить сканирование и индексацию всех страниц сайта.
К сожалению, попадание вашего сайта в индекс Google — задача немного более сложная. Читайте дальше, чтобы лучше понять, как работает процесс сканирования и индексации и какую роль в нем играет карта сайта XML.
Прежде чем мы приступим к развенчанию вышеупомянутых мифов, давайте изучим некоторые важные понятия SEO:
Сканирование — это действие, осуществляемое поисковыми системами для отслеживания и сбора URL-адресов со всего Интернета.
Индексация — это процесс, следующий за сканированием. По сути, речь идет об анализе и хранении веб-данных, которые впоследствии используются при предоставлении результатов для запросов поисковых систем. Индекс поисковой системы — это место, где хранятся все собранные веб-данные для дальнейшего использования.
Crawl Rank — это значение, которое Google присваивает вашему сайту и его страницам. До сих пор неизвестно, как эта метрика рассчитывается поисковой системой. Google неоднократно подтверждал, что частота индексации не связана с ранжированием, поэтому нет прямой зависимости между авторитетом ранжирования веб-сайтов и его рейтингом при сканировании.
Новостные веб-сайты, сайты с ценным контентом и сайты, которые регулярно обновляются, имеют более высокие шансы на регулярное сканирование.
Бюджет сканирования — это объем ресурсов сканирования, которые поисковая система выделяет веб-сайту. Обычно Google рассчитывает эту сумму на основе рейтинга сканирования вашего сайта.
Глубина сканирования — это степень, в которой Google детализирует уровень веб-сайта при его изучении.
Приоритет сканирования — это порядковый номер, присвоенный странице сайта, который означает ее важность для сканирования.
Теперь, зная все основы этого процесса, давайте развенчаем эти 3 мифа, лежащие в основе XML-карт сайта, сканирования и индексации!
Оглавление
- Миф 1. Google автоматически сканирует все сайты и делает это быстро.
- Выводы
- Миф 2. Добавление XML-карты сайта — лучший способ просканировать и проиндексировать все страницы сайта.
- Выводы
- Миф 3. Карта сайта в формате XML может решить все проблемы со сканированием и индексацией.
- Выводы
Миф 1. Google автоматически сканирует все сайты и делает это быстро.
Google утверждает, что когда дело доходит до сбора веб-данных, он проявляет гибкость и гибкость.
Но по правде говоря, поскольку на данный момент в Сети триллионы страниц, технически поисковая система не может быстро их все просканировать.
Выбор веб-сайтов для выделения краулингового бюджета
Умный алгоритм Google (он же Crawl Budget) распределяет ресурсы поисковой системы и решает, какие сайты стоит сканировать, а какие нет.
Обычно Google отдает приоритет надежным веб-сайтам, которые соответствуют установленным требованиям и служат основой для определения того, насколько другие сайты соответствуют требованиям.
Поэтому, если у вас есть веб-сайт, который только что вышел из печи, или веб-сайт с скопированным, дублирующимся или неполноценным контентом, шансы, что он будет правильно просканирован, довольно малы.
Важными факторами, которые также могут повлиять на распределение краулингового бюджета, являются:
- размер сайта,
- его общее состояние (этот набор показателей определяется количеством ошибок, которые могут быть у вас на каждой странице),
- и количество входящих и внутренних ссылок.
Чтобы увеличить свои шансы на получение краулингового бюджета, убедитесь, что ваш сайт соответствует всем требованиям Google, упомянутым выше, а также оптимизируйте эффективность его краулинга (см. следующий раздел в статье).
Прогнозирование расписания сканирования
Google не объявляет о своих планах по сканированию веб-URL. Также трудно угадать периодичность, с которой поисковик посещает некоторые сайты.
Может случиться так, что для одного сайта он может выполнять сканирование не реже одного раза в день, а для другого — раз в месяц или даже реже.
- Периодичность обходов зависит от:
- качество контента сайта,
- новизна и актуальность информации, предоставляемой веб-сайтом,
- и насколько важными или популярными, по мнению поисковой системы, являются URL-адреса сайтов.
Принимая во внимание эти факторы, вы можете попытаться предсказать, как часто Google будет посещать ваш сайт.
Роль внешних/внутренних ссылок и XML-карт сайта
В качестве путей роботы Googlebot используют ссылки, которые соединяют страницы сайта и веб-сайт друг с другом. Таким образом, поисковая система достигает триллионов взаимосвязанных страниц, существующих в Интернете.
Поисковик может начать сканирование вашего сайта с любой страницы, не обязательно с домашней. Выбор точки входа сканирования зависит от источника входящей ссылки. Скажем, на некоторых страницах вашего продукта есть много ссылок с разных веб-сайтов. Google соединяет точки и посещает такие популярные страницы в первую очередь.
Карта сайта в формате XML — отличный инструмент для создания продуманной структуры сайта. Кроме того, это может сделать процесс сканирования сайта более целенаправленным и интеллектуальным.
По сути, карта сайта — это концентратор со всеми ссылками сайта. Каждая включенная в него ссылка может быть снабжена некоторой дополнительной информацией: датой последнего обновления, периодичностью обновления, ее отношением к другим URL-адресам на сайте и т.д.
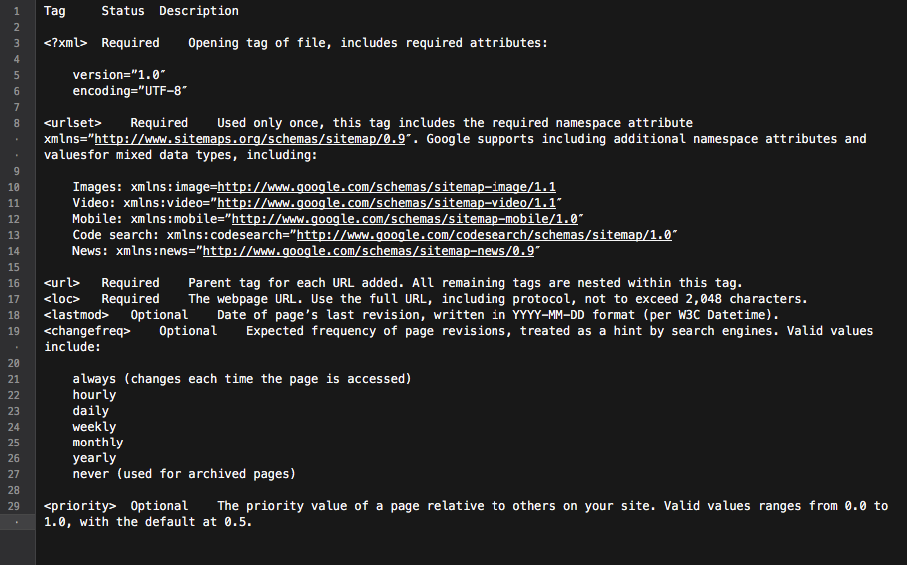 Все это дает Googlebots подробную дорожную карту сканирования веб-сайтов и делает сканирование более информативным. Кроме того, все основные поисковые системы отдают приоритет URL-адресам, указанным в карте сайта.
Все это дает Googlebots подробную дорожную карту сканирования веб-сайтов и делает сканирование более информативным. Кроме того, все основные поисковые системы отдают приоритет URL-адресам, указанным в карте сайта.
Подводя итог, можно сказать, что для того, чтобы страницы вашего сайта попали в поле зрения робота Googlebot, вам необходимо создать веб-сайт с отличным содержанием и оптимизировать внутреннюю структуру ссылок.
Выводы
• Google не сканирует автоматически все ваши веб-сайты.
• Периодичность сканирования сайта зависит от того, насколько важны или популярны сайт и его страницы.
• Благодаря обновлению контента Google чаще посещает веб-сайт.
• Веб-сайты, которые не соответствуют требованиям поисковых систем, вряд ли будут правильно просканированы.
• Веб-сайты и страницы сайтов, не имеющие внутренних/внешних ссылок, обычно игнорируются ботами поисковых систем.
• Добавление XML-карты сайта может улучшить процесс сканирования веб-сайта и сделать его более интеллектуальным.
Миф 2. Добавление XML-карты сайта — лучший способ просканировать и проиндексировать все страницы сайта.
Каждому владельцу веб-сайта хочется, чтобы робот Googlebot посещал все важные страницы сайта (кроме скрытых от индексации), а также мгновенно изучал новый и обновленный контент.
Однако у поисковой системы есть свое видение приоритетов сканирования сайта.
Когда дело доходит до проверки веб-сайта и его содержимого, Google использует набор алгоритмов, называемый краулинговым бюджетом. По сути, он позволяет поисковой системе сканировать страницы сайта, умело используя собственные ресурсы.
Проверка краулингового бюджета сайта
Довольно легко выяснить, как сканируется ваш сайт и есть ли у вас проблемы с краулинговым бюджетом.
Вам просто нужно:
- подсчитайте количество страниц на вашем сайте и в карте сайта XML,
- посетите консоль поиска Google, перейдите в раздел «Сканирование» -> «Статистика сканирования» и проверьте, сколько страниц ежедневно сканируется на вашем сайте,
- разделите общее количество страниц вашего сайта на количество страниц, просматриваемых за день.
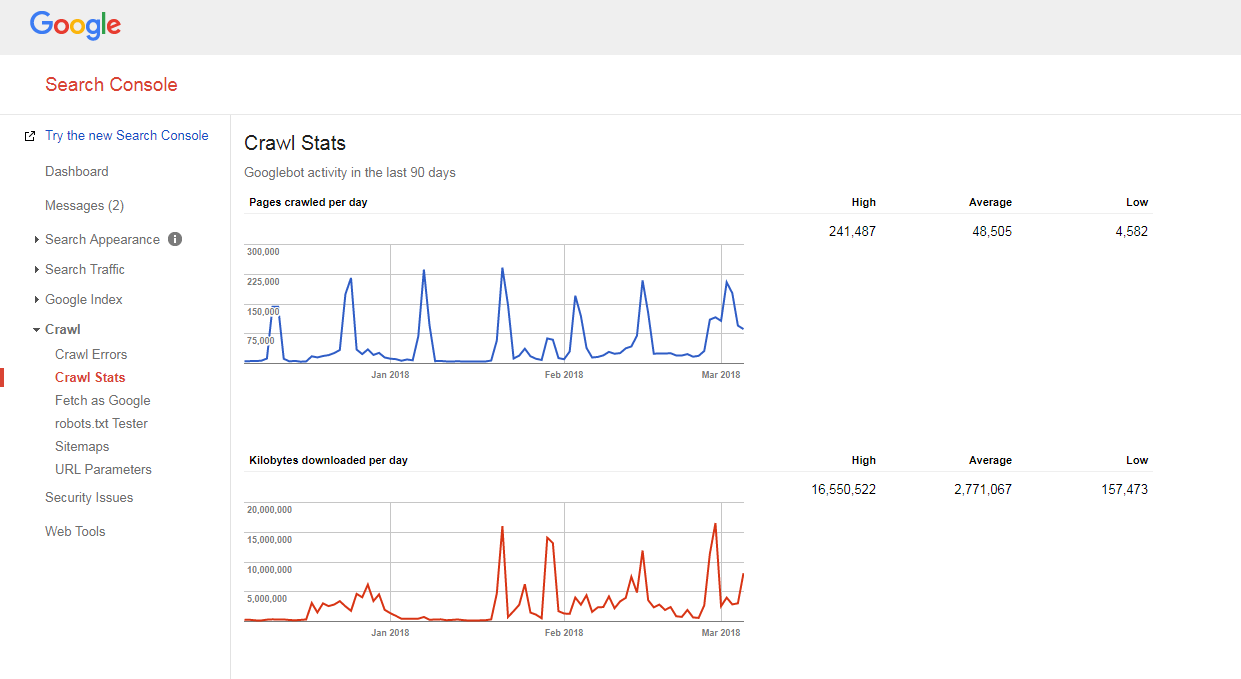 Если полученное вами число превышает 10 (на вашем сайте в 10 раз больше страниц, чем ежедневно сканирует Google), у нас для вас плохие новости: у вашего сайта проблемы со сканированием.
Если полученное вами число превышает 10 (на вашем сайте в 10 раз больше страниц, чем ежедневно сканирует Google), у нас для вас плохие новости: у вашего сайта проблемы со сканированием.
Но прежде чем вы научитесь их исправлять, вам нужно понять еще одно понятие, а именно…
Глубина сканирования
Глубина сканирования — это степень, в которой Google продолжает исследовать веб-сайт до определенного уровня.
Как правило, домашняя страница считается уровнем 1, страница, находящаяся на расстоянии 1 клика, — уровнем 2 и т. д.
Страницы глубокого уровня имеют более низкий PageRank (или вообще не имеют его) и с меньшей вероятностью будут просканированы роботом Googlebot. Обычно поисковая система не копает глубже четвертого уровня.
В идеальном сценарии конкретная страница должна находиться в 1-4 кликах от главной страницы или основных категорий сайта. Чем длиннее путь к этой странице, тем больше ресурсов нужно выделить поисковым системам, чтобы добраться до нее.
Если на веб-сайте Google считает, что путь слишком длинный, он прекращает дальнейшее сканирование.
Оптимизация глубины сканирования и бюджета
Чтобы предотвратить замедление работы робота Googlebot, оптимизировать бюджет и глубину сканирования веб-сайта, вам необходимо:
- исправить все 404, JS и другие ошибки страницы;
Чрезмерное количество ошибок на странице может значительно снизить скорость работы поискового робота Google. Чтобы найти все основные ошибки сайта, войдите в панель инструментов Google (Bing, Yandex) для веб-мастеров и следуйте всем инструкциям, приведенным здесь.

- оптимизировать пагинацию;
Если у вас слишком длинные списки страниц или ваша схема разбивки на страницы не позволяет щелкнуть дальше, чем на пару страниц вниз по списку, поисковый робот, скорее всего, перестанет копаться в такой куче страниц.
Также, если на такой странице мало элементов, она может считаться малоконтентной и не будет просканирована.
- проверить навигационные фильтры;
Некоторые схемы навигации могут поставляться с несколькими фильтрами, создающими новые страницы (например, страницы, отфильтрованные с помощью многоуровневой навигации). Хотя такие страницы могут иметь потенциал органического трафика, они также могут создавать нежелательную нагрузку на сканеры поисковых систем.
Лучший способ решить эту проблему — ограничить систематические ссылки на отфильтрованные списки. В идеале вы должны использовать максимум 1-2 фильтра. Например, если у вас есть магазин с 3 фильтрами LN (цвет/размер/пол), вы должны разрешить систематическое сочетание только 2 фильтров (например, цвет-размер, пол-размер). Если вам нужно добавить комбинации из большего количества фильтров, вы должны вручную добавить к ним ссылки.
- Оптимизировать параметры отслеживания в URL-адресах;
Различные параметры отслеживания URL-адресов (например, '?source=thispage') могут создавать ловушки для поисковых роботов, поскольку они генерируют огромное количество новых URL-адресов. Эта проблема характерна для страниц с блоками «похожие товары» или «похожие истории», где эти параметры используются для отслеживания поведения пользователей.
Чтобы оптимизировать эффективность сканирования в этом случае, рекомендуется передавать информацию об отслеживании после «#» в конце URL-адреса. Таким образом, такой URL-адрес останется неизменным. Кроме того, также можно перенаправить URL-адреса с параметрами отслеживания на те же URL-адреса, но без отслеживания.
- удалить лишние 301 редиректы;
Скажем, у вас есть большой кусок URL-адресов, на которые есть ссылки без завершающей косой черты. Когда поисковый бот посещает такие страницы, он перенаправляется на версию со слэшем.
Таким образом, боту приходится делать в два раза больше, чем положено, и в конце концов он может сдаться и перестать ползать. Чтобы избежать этого, просто старайтесь обновлять все ссылки на вашем сайте всякий раз, когда вы меняете URL-адреса.
Приоритет сканирования
Как было сказано выше, Google отдает предпочтение веб-сайтам для сканирования. Поэтому неудивительно, что то же самое он делает со страницами просканированного веб-сайта.
Для большинства веб-сайтов главной страницей является страница с наивысшим приоритетом сканирования.
Однако, как было сказано ранее, в некоторых случаях это также может быть самая популярная категория или самая посещаемая страница продукта. Чтобы найти страницы, которые робот Googlebot сканирует чаще всего, просто просмотрите журналы своего сервера.
Хотя Google официально не объявляет, что факторы, которые предположительно могут влиять на приоритет сканирования страницы сайта, следующие:
- включение в XML-карту сайта (и добавление тегов Priority* для наиболее важных страниц),
- количество внешних ссылок,
- количество внутренних ссылок,
- популярность страницы (количество посещений),
- PageRank.
Но даже после того, как вы расчистили путь поисковым ботам для сканирования вашего сайта, они все равно могут его игнорировать. Читайте дальше, чтобы узнать, почему.
Чтобы лучше понять приоритет сканирования, посмотрите это виртуальное выступление Гэри Иллиса.
Что касается тегов Priority в XML-карте сайта, то их можно добавить либо вручную, либо с помощью встроенного функционала платформы, на которой основан ваш сайт. Кроме того, некоторые платформы поддерживают сторонние расширения/приложения XML карты сайта, которые упрощают процесс.
С помощью тега Priority карты сайта XML вы можете присвоить разным категориям страниц сайта следующие значения:
- 0,0-0,3 на служебные страницы, устаревший контент и любые страницы второстепенной важности,
- 0,4–0,7 к статьям вашего блога, часто задаваемым вопросам и информационным страницам, страницам категорий и подкатегорий второстепенного значения, а также
- 0.8-1.0 в основные категории вашего сайта, ключевые целевые страницы и главную страницу.
Выводы
• У Google есть собственное видение приоритетов процесса сканирования.
• Страница, которая должна попасть в индекс поисковых систем, должна находиться в 1-4 кликах от главной страницы, основных категорий сайта или самых популярных страниц сайта.
• Чтобы предотвратить замедление работы робота Googlebot и оптимизировать бюджет и глубину сканирования вашего веб-сайта, вам следует найти и исправить ошибки 404, JS и другие ошибки страниц, оптимизировать пагинацию сайта и фильтры навигации, удалить лишние перенаправления 301 и оптимизировать параметры отслеживания в URL-адресах.
• Чтобы повысить приоритет сканирования важных страниц сайта, убедитесь, что они включены в XML-карту сайта (с тегами приоритета) и хорошо связаны с другими страницами сайта, имеют ссылки с других соответствующих и авторитетных веб-сайтов.
Миф 3. Карта сайта в формате XML может решить все проблемы со сканированием и индексацией.
Являясь хорошим средством связи, которое предупреждает Google об URL-адресах вашего сайта и способах их доступа, XML-карта сайта не дает НИКАКИХ гарантий того, что ваш сайт будет посещен ботами поисковых систем (не говоря уже о включении всех страниц сайта в индекс). .
Кроме того, вы должны понимать, что карты сайта не помогут вам улучшить рейтинг вашего сайта. Даже если страница просканирована и включена в индекс поисковой системы, эффективность ее ранжирования зависит от множества других факторов (внутренних и внешних ссылок, контента, качества сайта и т. д.).
Однако при правильном использовании XML-карта сайта может значительно повысить эффективность сканирования вашего сайта. Ниже приведены несколько советов о том, как максимально использовать SEO-потенциал этого инструмента.
Быть последовательным
При создании карты сайта помните, что она будет использоваться в качестве дорожной карты для поисковых роботов Google. Следовательно, важно не вводить поисковую систему в заблуждение, указывая неправильные направления.
Например, вы можете время от времени включать в свою XML-карту сайта некоторые служебные страницы ( свяжитесь с нами или страницы TOS, страницы для входа в систему, страницу восстановления утерянного пароля, страницы для обмена контентом и т. д.).
Эти страницы обычно скрыты от индексации метатегами noindex robots или запрещены в файле robots.txt.
Таким образом, включение их в XML-карту сайта только запутает роботов Google, что может негативно повлиять на процесс сбора информации о вашем сайте.
Регулярно обновляйте
Большинство веб-сайтов в Интернете меняются почти каждый день. Особенно веб-сайт электронной коммерции с продуктами и категориями, которые регулярно перетасовываются на сайте и за его пределами.
Чтобы Google был в курсе, вам необходимо обновлять карту сайта в формате XML.
Некоторые платформы (Magento, Shopify) либо имеют встроенную функциональность, позволяющую периодически обновлять карты сайта в формате XML, либо поддерживают некоторые сторонние решения, способные выполнять эту задачу.
Например, в Magento 2 можно настроить периодичность циклов обновления карты сайта. Когда вы определяете его в настройках конфигурации платформы, вы сообщаете сканеру, что страницы вашего сайта обновляются с определенным интервалом времени (ежечасно, еженедельно, ежемесячно), и ваш сайт нуждается в повторном сканировании.
Нажмите здесь, чтобы узнать больше об этом.
Но помните, что хотя установка приоритета и частоты обновлений карты сайта помогает, они могут не успевать за реальными изменениями и иногда не давать истинной картины.
Вот почему убедитесь, что ваша карта сайта отражает все недавно внесенные изменения.
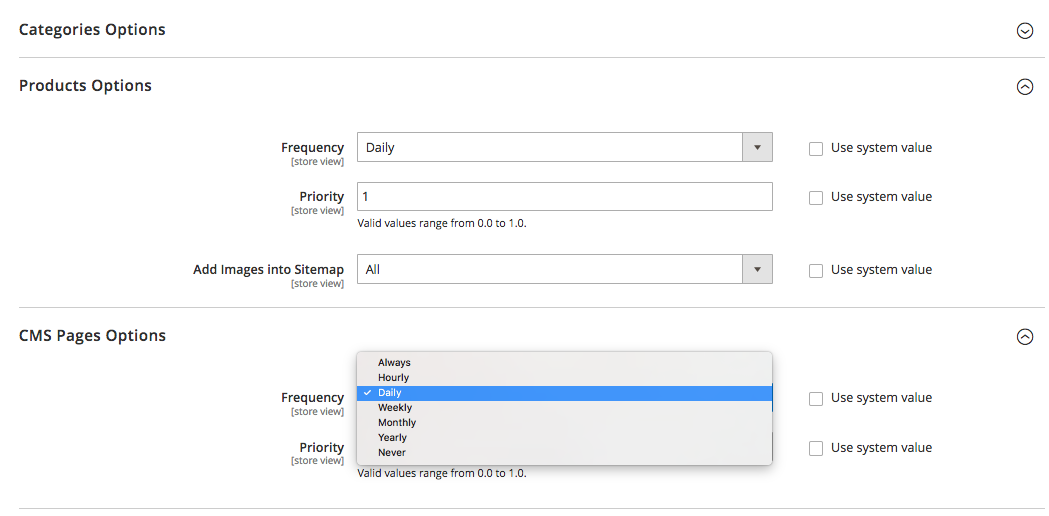 Сегментируйте контент сайта и установите правильные приоритеты сканирования
Сегментируйте контент сайта и установите правильные приоритеты сканирования
Google усердно работает над измерением общего качества сайта и выдает только самые лучшие и наиболее релевантные веб-сайты.
Но, как это часто бывает, не все сайты одинаковы и способны приносить реальную пользу.
Скажем, сайт может состоять из 1000 страниц, и только 50 из них категории «А». Остальные либо чисто функциональные, либо имеют устаревшее содержание, либо вообще не имеют содержания.
Если Google начнет исследовать такой веб-сайт, он, вероятно, решит, что он довольно дрянной из-за высокого процента малоценных, спамных или устаревших страниц.
Вот почему при создании XML-карты сайта рекомендуется сегментировать контент веб-сайта и направлять поисковых роботов только на достойные области сайта.
И, как вы, возможно, помните, теги Priority, назначенные наиболее важным страницам сайта в вашей XML-карте сайта, также могут быть очень полезны.
Выводы
• При создании карты сайта убедитесь, что вы не включаете страницы, скрытые от индексации метатегами noindex robots или запрещенные в файле robots.txt.
• Обновляйте XML-карты сайта (вручную или автоматически) сразу после внесения изменений в структуру и содержание веб-сайта.
• Сегментируйте содержимое своего сайта, чтобы включить в карту сайта только страницы с оценкой «А».
• Установить приоритет сканирования для разных типов страниц.
Это в основном все.
Есть что сказать по теме? Не стесняйтесь поделиться своим мнением о сканировании, индексации или картах сайта в разделе комментариев ниже.