
Получите максимум от Apache Solr: техническое исследование поискового индексирования
Опубликовано: 2023-02-21Функция поиска улучшает взаимодействие с пользователем веб-сайта, позволяя пользователю легко и быстро находить то, что он ищет. Тем более для крупных веб-сайтов, сайтов электронной коммерции и сайтов с динамическим контентом (новостные сайты, блоги).
Apache Solr — одна из самых популярных поисковых платформ, используемых веб-сайтами любого размера. Это поисковая система с открытым исходным кодом, основанная на Java, которая позволяет выполнять поиск в больших объемах данных, таких как статьи, продукты, отзывы клиентов и многое другое. Подробно изучите Apache Solr в этой статье.
Ознакомьтесь с этой статьей, чтобы узнать, как настроить Apache Solr в Drupal.

Почему Apache Solr так популярен?
Apache Solr является быстрым и гибким и обеспечивает полнотекстовый поиск, выделение совпадений (выделение соответствующего условия поиска), фасетный поиск (более точный поиск), индексирование в реальном времени (позволяет немедленно индексировать новый контент), динамическую кластеризацию ( систематизирует результаты поиска по группам), интеграцию с базой данных, функции NoSQL (нереляционная база данных) и широкие возможности обработки документов (для индексации документов различных форматов, таких как PDF, MS Office, Open office).
Несколько полезных фактов об Apache Solr:
- Первоначально он был разработан CNET Networks, Inc. в качестве поисковой системы для своих веб-сайтов и статей. Позже он был открыт и стал проектом Apache верхнего уровня.
- Поддерживает несколько языков программирования, таких как PHP, Java, Python и Ruby. Он также предоставляет API для этих языков.
- Имеет встроенную поддержку геопространственного поиска, позволяющую искать контент на основе его местоположения. Особенно полезно для таких сайтов, как сайты о недвижимости, туристические сайты и т. д.
- Поддерживает расширенные функции поиска, такие как проверка орфографии, автозаполнение и пользовательский поиск с помощью API и плагинов.
- Использует Lucene для индексации и поиска.
Что такое Люсен
Apache Lucene — это библиотека поиска Java с открытым исходным кодом, которая позволяет легко добавлять в приложение функции поиска или извлечения информации. Он универсальный, мощный, точный и работает на основе эффективного алгоритма поиска.
Хотя Lucene известна своими возможностями полнотекстового поиска, ее также можно использовать для классификации документов, анализа данных и поиска информации. Он также поддерживает множество языков, кроме английского, таких как немецкий, французский, испанский, китайский, японский и другие.
Что такое индексация?
Все поисковые системы начинают с индексации. Индексирование — это обработка исходных данных в высокоэффективный поиск по перекрестным ссылкам для облегчения быстрого поиска.
Поисковые системы не индексируют данные напрямую. Тексты сначала разбиваются на токены (атомарные элементы). Поиск — это процесс обращения к поисковому индексу и получения документа, соответствующего запросу.
Преимущества индексации
- Быстрый и точный поиск информации (собирает, анализирует и сохраняет)
- Без индексации поисковой системе требуется больше времени для сканирования каждого документа.
Поток индексации
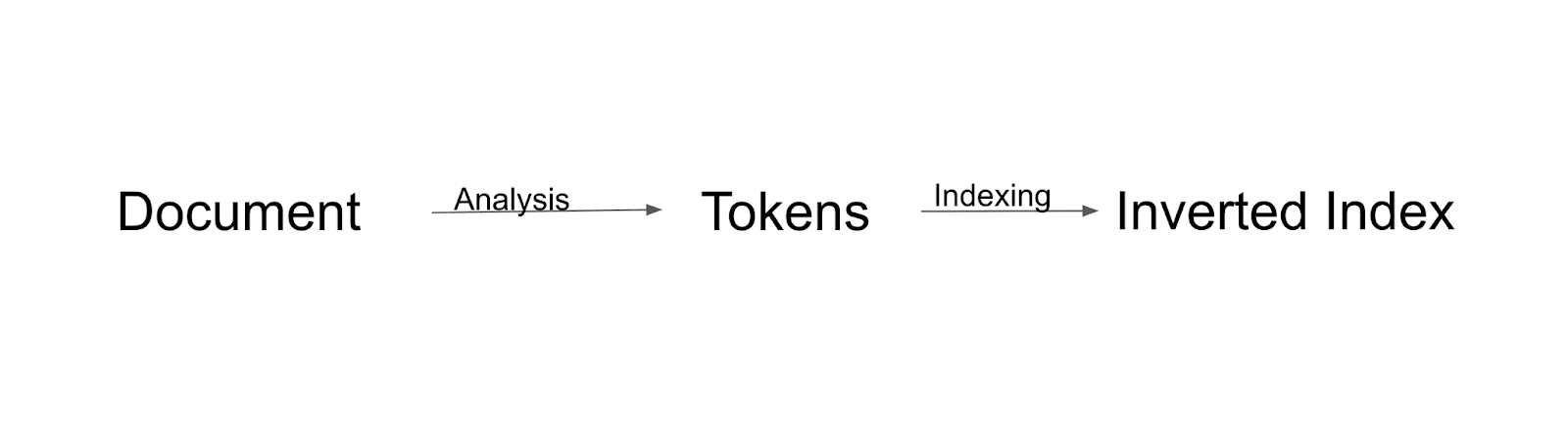
Сначала документ будет проанализирован и разбит на токены. Все эти токены будут проиндексированы по инвертированному индексу. Инвертированный индекс — это способ, которым Solr строит индекс.
Как работает инвертированное индексирование
Предположим, у нас есть 3 документа:
- Я люблю шоколад (D 1)
- Я заказал шоколадный торт (D 2)
- Я приготовила большой ванильный торт (D 3)
Способ его токенизации показан во 2-м столбце таблицы ниже.

«Шоколад» доступен в D1 и D2.
«Торт» доступен в D2 и D3.
«Большой» доступен в D3
«Заказано» доступно в D2
«Подготовлено» доступно в D3
«Ваниль» доступна в D3
Вы заметите, что такие слова, как «я», «люблю», не токенизированы. Это так называемые стоп-слова, которые Solr не будет индексировать или искать.
Поэтому, когда кто-то ищет термин «Шоколадный торт», движок просматривает индекс. Вместо того, чтобы искать документ, он сначала просматривает индекс, чтобы увидеть, к каким документам относятся слова «Шоколад» и «Торт». Это упрощает и ускоряет получение только определенного документа. Это называется инвертированной индексацией.
Схема хранения
Apache Solr использует схему хранения на основе документов и хранит каждый фрагмент данных в виде отдельного документа в коллекции. Это обеспечивает эффективное и гибкое хранение и извлечение данных.
В Drupal каждый узел рассматривается как документ. Поэтому, когда вы индексируете свой узел в Apache Solr, он считается документом. Каждый документ может содержать несколько полей. Lucene не имеет общей глобальной схемы. Это означает, что вы можете индексировать поля любого типа в каждом документе в Apache Solr.

Как установить Apache Solr
- Во-первых, убедитесь, что в вашей системе установлена Java.
- Далее давайте установим Solr отсюда: https://solr.apache.org/downloads.html
- Загрузите и распакуйте Solr.
- Запустите эту команду в папке Solr.
◦ bin/solr -e techproducts
Это создаст фиктивное ядро для демонстрации, а также запустит сервер Solr.
- После запуска сервера перейдите в браузер и введите «http://localhost:8983/».
- Убедитесь, что Solr успешно установлен с фиктивным ядром.
Структура каталогов
После того, как вы установили Solr, вы увидите множество папок, таких как:
Документы — содержит документацию по Solr.
Dist — основной файл Solr .jar
Contrib — содержит дополнительные плагины и специальные функции Solr.
Bin - скрипты Solr
Пример — содержит демонстрацию возможностей solr
Сервер - сердце Solr. Содержит веб-приложение Solr, журналы, ядро Solr.

Файлы конфигурации
Для создания ядра нам потребуются два файла обязательно.
- Схема.xml
- Solrconfig.xml
Схема.xml
- Он будет содержать типы полей, которые вы планируете поддерживать, и способы анализа этих типов.
Solrconfig.xml
- Содержит различные настройки, управляющие поведением ядра Solr, например, обработчик запросов, диспетчер запросов, компоненты запросов, обработчики обновлений и т. д.
Запрос в Solr
Теперь давайте посмотрим, как запрашивать результаты Solr в пользовательском интерфейсе администратора Solr.
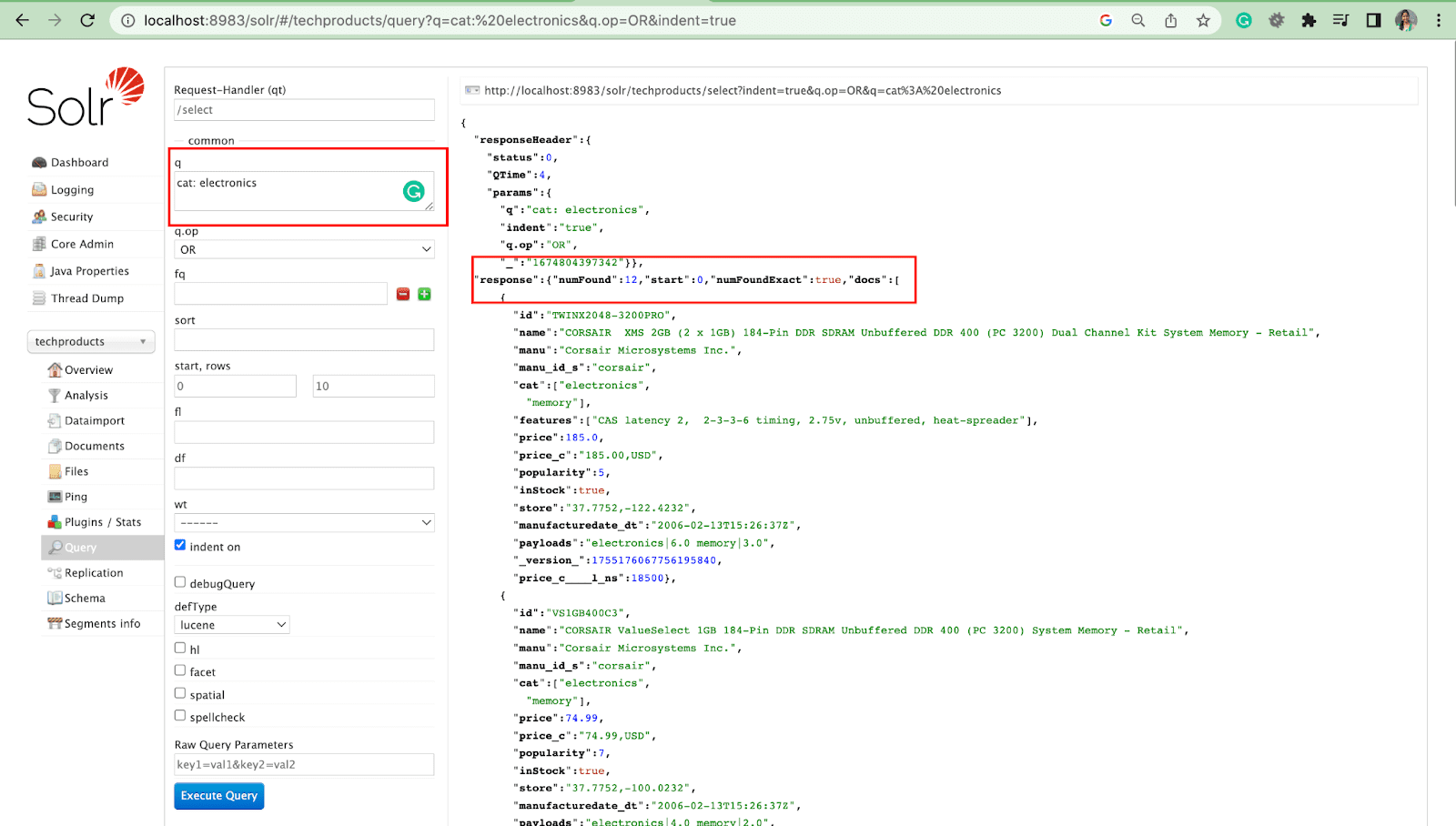
Параметр запроса
- Локальные параметры — это аргументы в запросе Solr, относящиеся к параметру запроса.
Например: кот: электроника
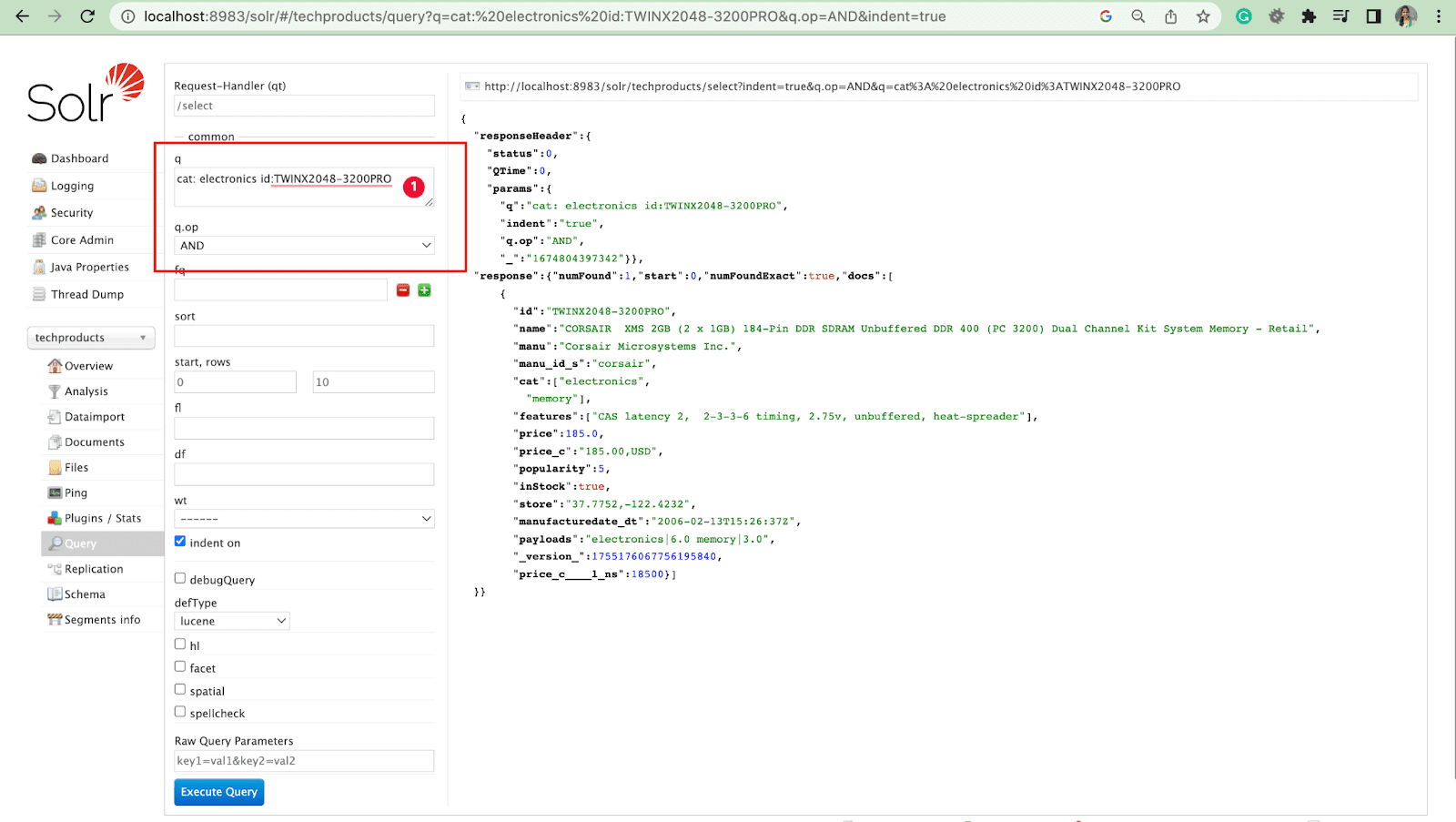
Параметр запроса с операциями
- Мы можем запросить несколько полей с помощью операции.
Например: cat:electronics id:TWINX2048-3200PRO с q.op И
[ИЛИ]
кот: электроника И id:TWINX2048-3200PRO
[ИЛИ]
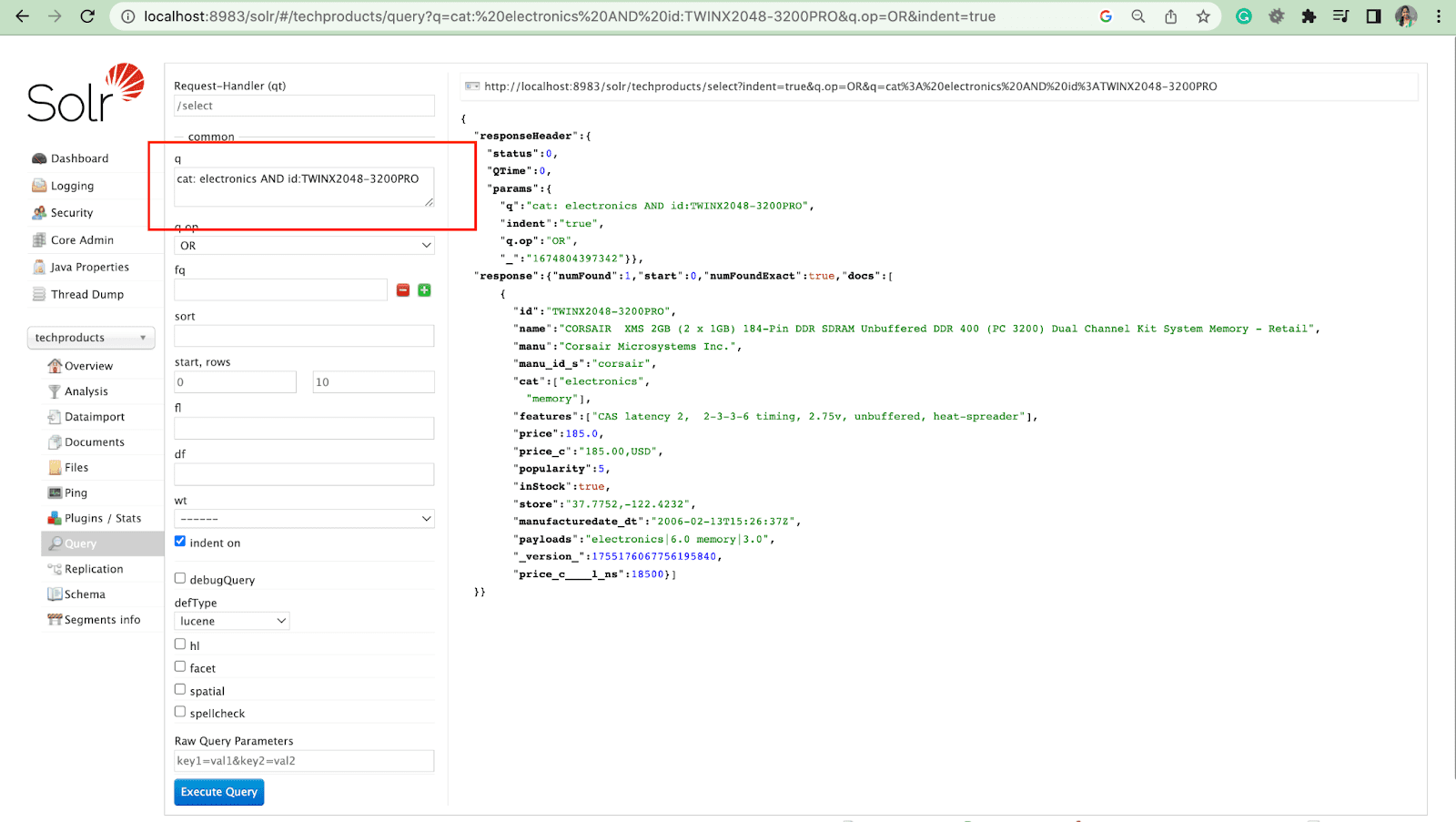
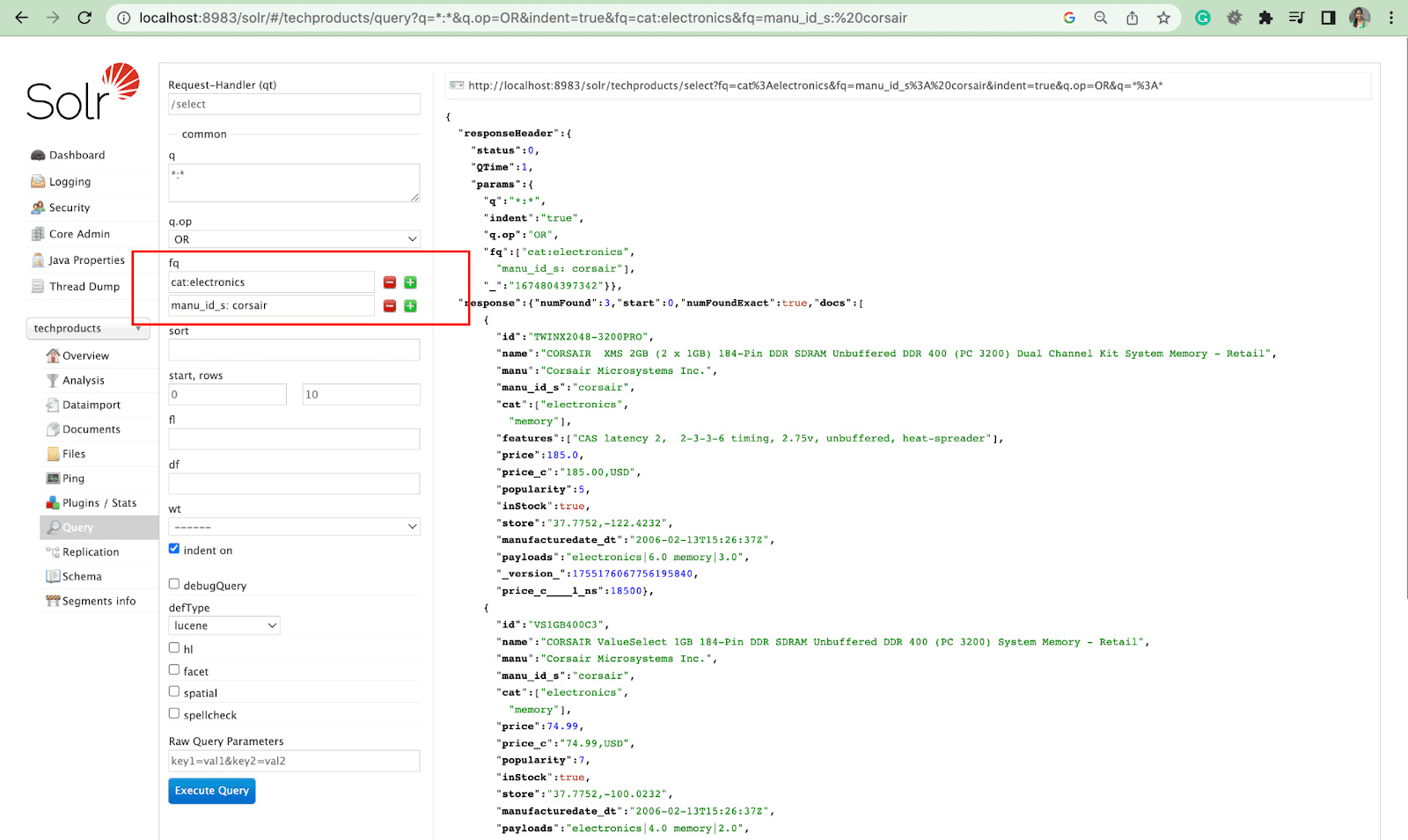
Фильтровать запрос
Фильтрующий запрос помогает сузить результаты поиска. Запрос можно указать с помощью параметра fq, чтобы ограничить, какие документы возвращаются в расширенном наборе, не влияя на оценку.
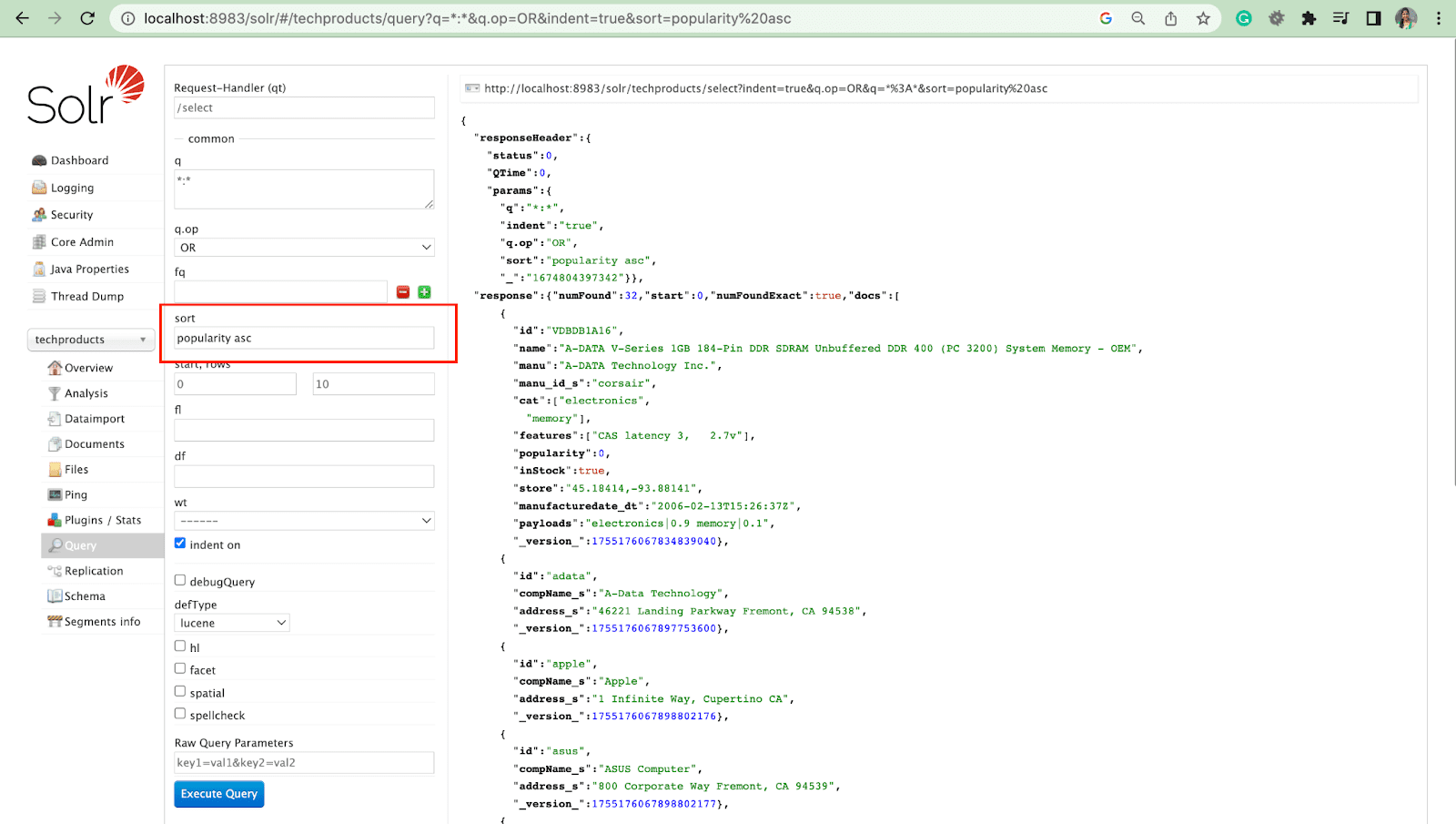
Сортировать параметр
Параметр sort упорядочивает результаты поиска по возрастанию (asc) или по убыванию (desc). В зависимости от содержания параметр может использоваться как в числовом, так и в алфавитном порядке.
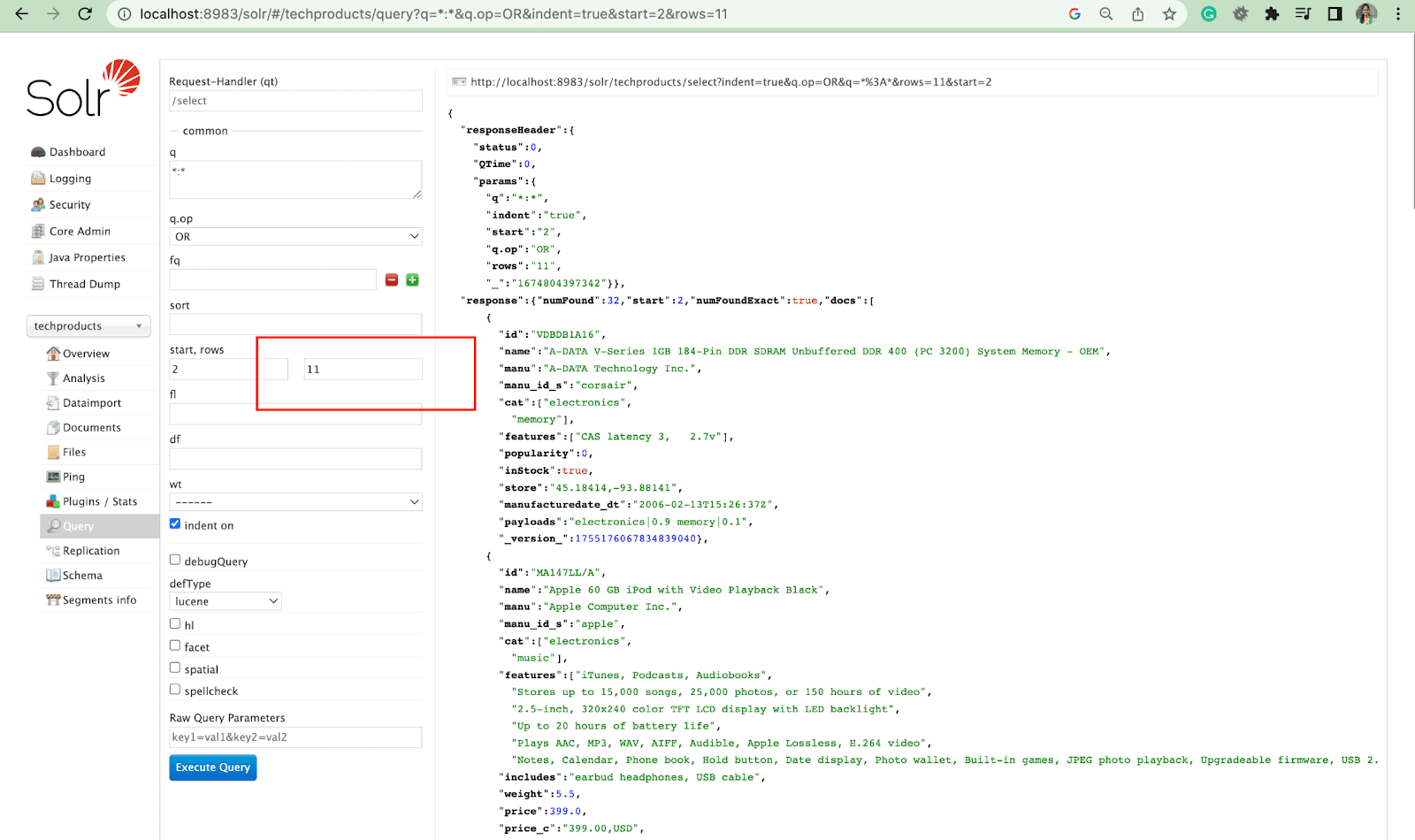
Строки Параметр
Параметр rows позволяет разбить результаты запроса на страницы.
Параметр списка полей
Параметр fl ограничивает информацию, включенную в ответ на запрос, указанным списком полей.
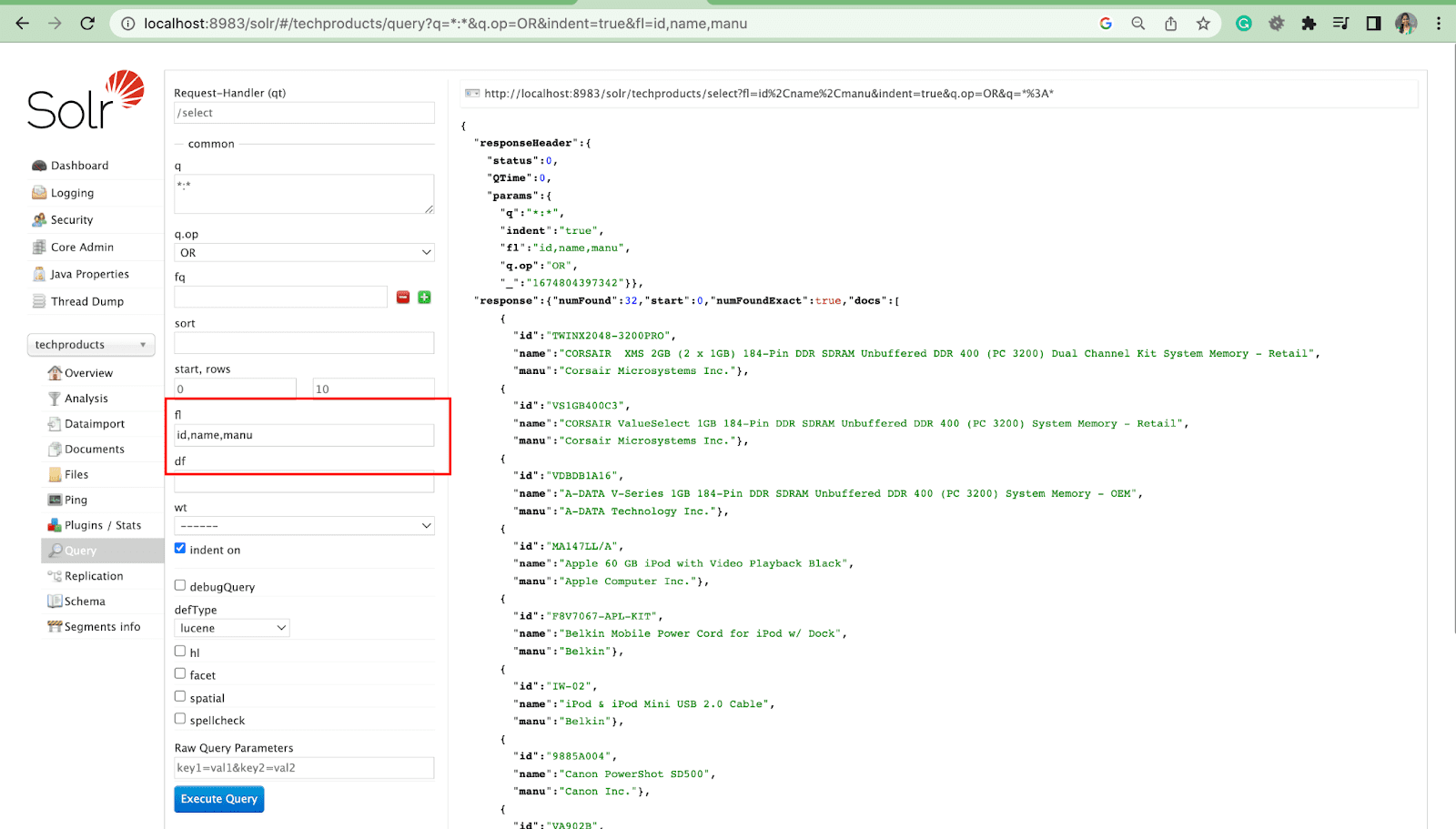
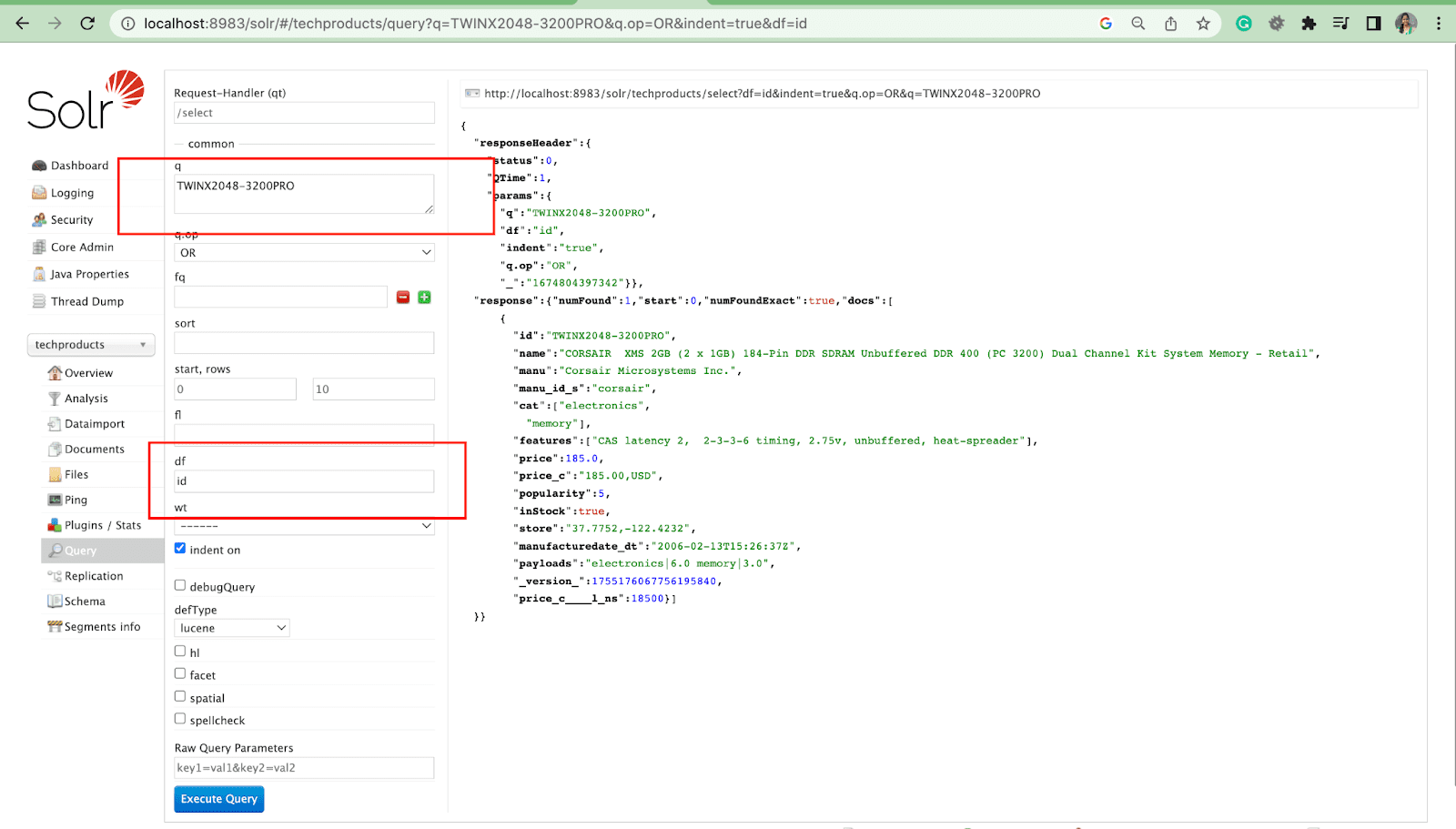
Поле по умолчанию Параметр
Параметр поля по умолчанию — это поле по умолчанию для параметра запроса.
Основные параметры
Функция выделения в Solr позволяет включать фрагменты документов, соответствующие запросу.
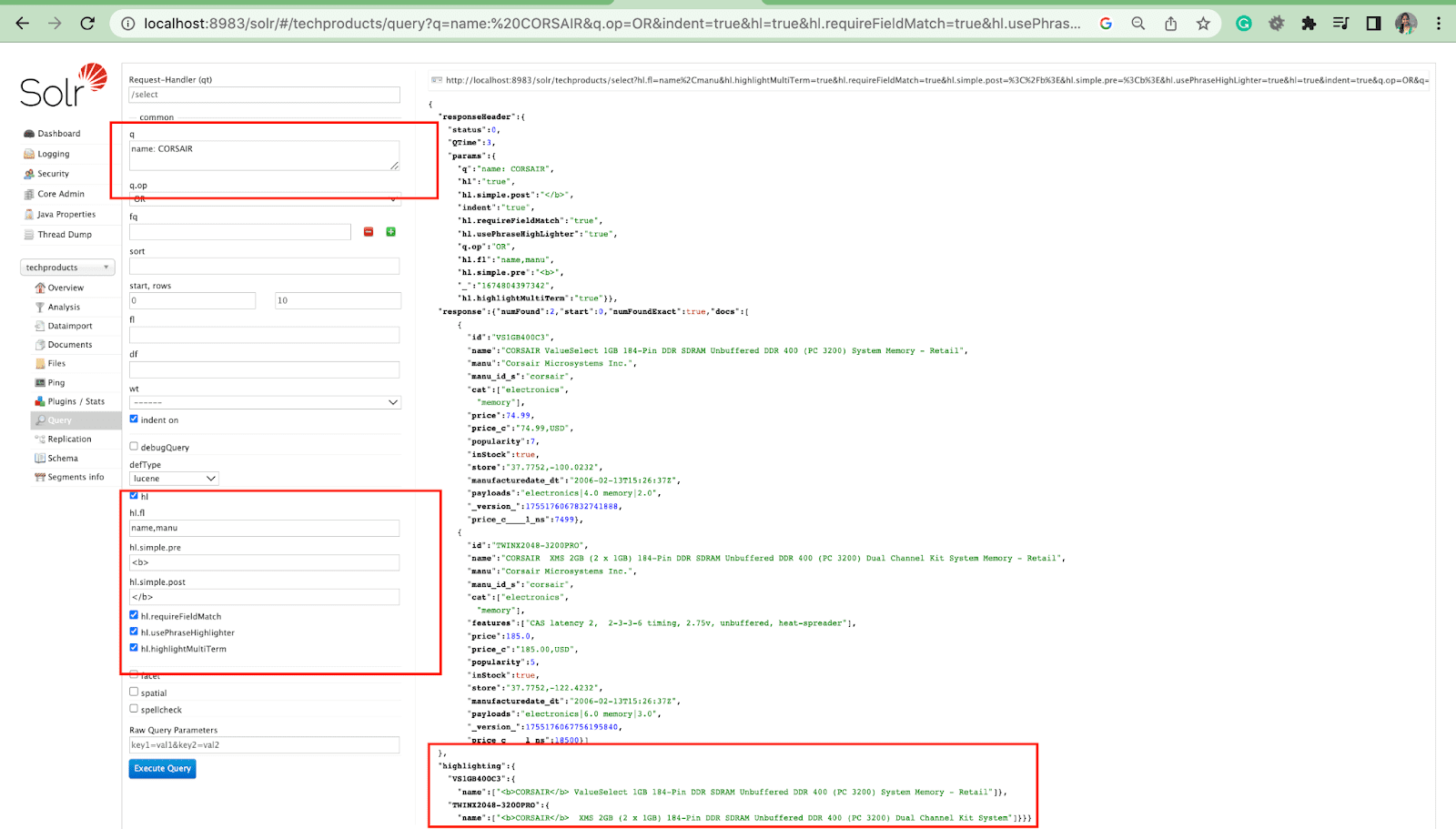
Некоторые из наиболее распространенных параметров выделения:
- Hl.fl — выделяет список полей.
- Hl.simple.pre — указывает, какой «тег» следует использовать перед выделенным словом.
- Hl.simple.post — указывает, какой «тег» следует использовать после выделенного термина.
- hl.highlightMultiTerm — если установлено значение true , Solr будет выделять запросы с подстановочными знаками. Если false , они вообще не будут выделены.
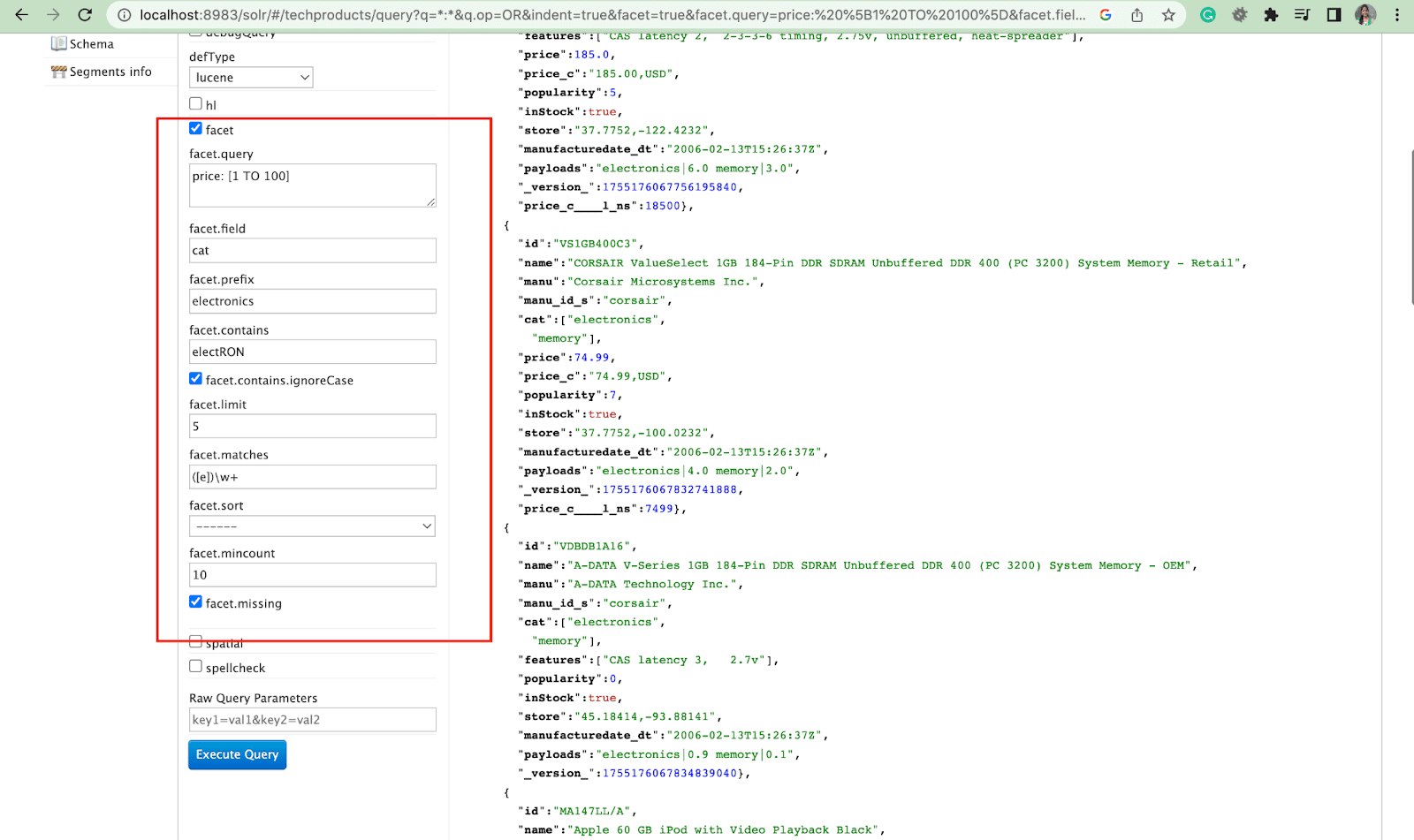
Аспект:
Фасеты позволяют пользователям исследовать и уточнять большие наборы результатов поиска. Они отображаются в пользовательском интерфейсе в виде флажков, раскрывающихся списков или других элементов управления. Два общих параметра для управления фасетами:
- Параметр фасета
С помощью параметра фасета пользователи могут создавать фасеты на основе значений одного или нескольких полей в своем поисковом индексе. В результатах поиска параметр фасета можно настроить для управления тем, как генерируются и отображаются фасеты.
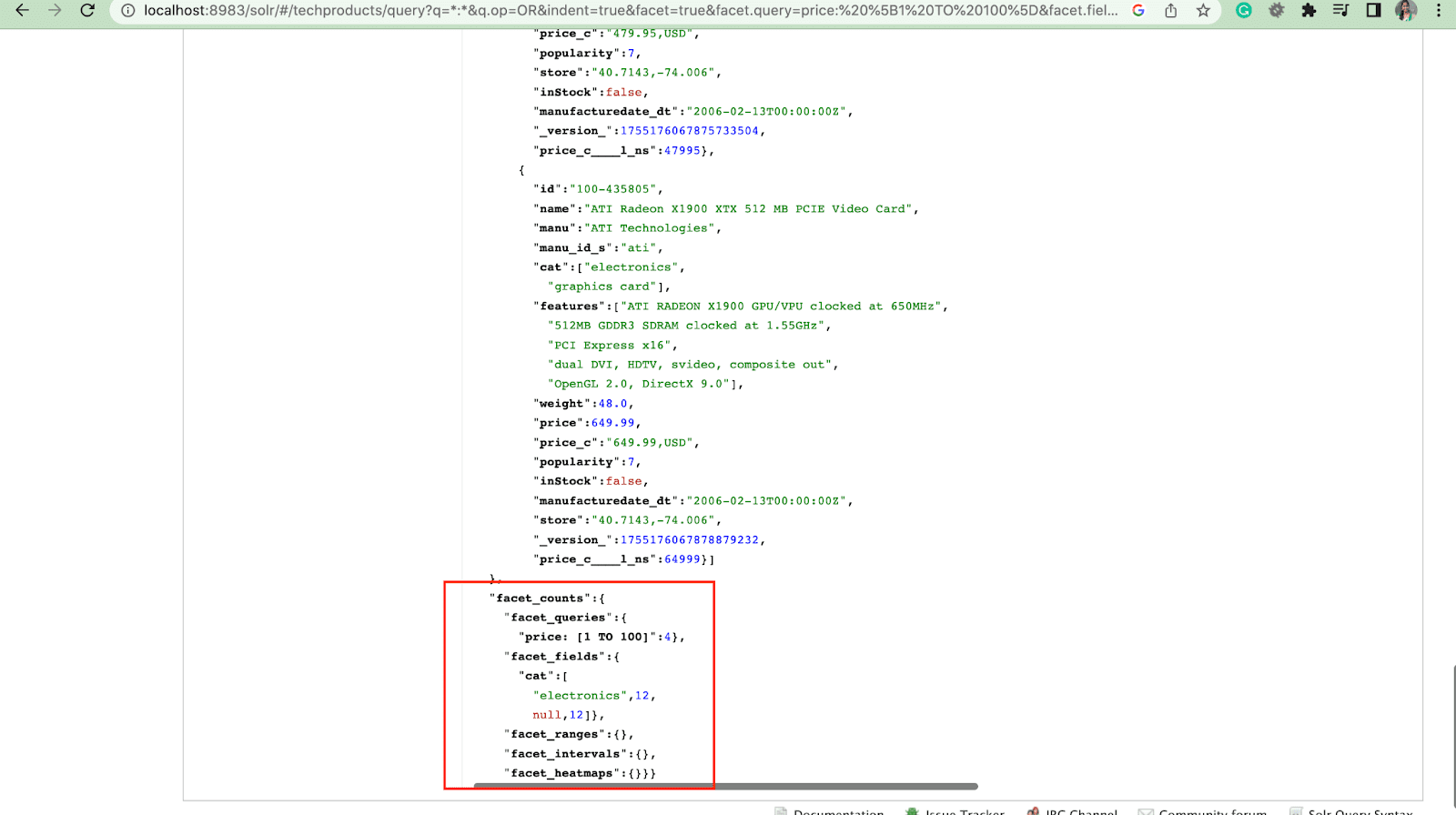
2. Параметр Facet.query
Когда пользователь включает параметр facet.query в свой запрос Solr, Solr создает список счетчиков фасетов, соответствующих количеству документов в индексе, соответствующих каждому запросу. Facet.query полезен, когда вы хотите создать фасеты на основе сложных критериев поиска, которые не могут быть легко представлены с помощью простого значения поля.
Есть несколько других параметров фасета, таких как facet.field (для указания полей, которые должны использоваться для создания фасетов) , facet.limit (максимальное количество фасетов для отображения для каждого поля) , facet.mincount (минимальное количество документов, необходимых для фасет, который должен быть включен в ответ) , facet.sort (указывает порядок, в котором должны отображаться значения фасета) .
Последние мысли
Apache Solr — это очень универсальная поисковая система со множеством интересных функций, которые можно настроить в соответствии с вашими требованиями. Drupal очень хорошо работает с Apache Solr. Если вы ищете экспертов Drupal для настройки мощной поисковой системы для вашего нового проекта, мы будем рады пойти дальше!