
Обнаружение аномалий: руководство по предотвращению сетевых вторжений
Опубликовано: 2023-01-09Данные — неотъемлемая часть бизнеса и организаций, и они ценны только при правильной структуре и эффективном управлении.
Согласно статистике, 95% предприятий сегодня сталкиваются с проблемой управления и структурирования неструктурированных данных.
Именно здесь вступает в действие интеллектуальный анализ данных. Это процесс обнаружения, анализа и извлечения значимых закономерностей и ценной информации из больших наборов неструктурированных данных.
Компании используют программное обеспечение для выявления закономерностей в больших пакетах данных, чтобы больше узнать о своих клиентах и целевой аудитории, а также разработать бизнес-стратегии и маркетинговые стратегии для повышения продаж и снижения затрат.
Помимо этого преимущества, наиболее важными приложениями интеллектуального анализа данных являются обнаружение мошенничества и аномалий.
В этой статье объясняется обнаружение аномалий и дополнительно исследуется, как это может помочь предотвратить утечку данных и вторжение в сеть для обеспечения безопасности данных.
Что такое обнаружение аномалий и его виды?

Хотя интеллектуальный анализ данных включает в себя поиск закономерностей, корреляций и тенденций, которые связаны друг с другом, это отличный способ найти аномалии или выбросы данных в сети.
Аномалии в интеллектуальном анализе данных — это точки данных, которые отличаются от других точек данных в наборе данных и отклоняются от нормального шаблона поведения набора данных.
Аномалии можно разделить на отдельные типы и категории, в том числе:
- Изменения в событиях: относятся к внезапным или систематическим изменениям по сравнению с предыдущим нормальным поведением.
- Выбросы: Небольшие аномальные закономерности, проявляющиеся несистематически при сборе данных. Их можно дополнительно разделить на глобальные, контекстуальные и коллективные выбросы.
- Дрейфы: постепенные, ненаправленные и долгосрочные изменения в наборе данных.
Таким образом, обнаружение аномалий — это метод обработки данных, очень полезный для обнаружения мошеннических транзакций, обработки тематических исследований с дисбалансом высокого класса и обнаружения болезней для построения надежных моделей обработки данных.
Например, компания может захотеть проанализировать свой денежный поток, чтобы найти аномальные или повторяющиеся транзакции с неизвестным банковским счетом, чтобы обнаружить мошенничество и провести дальнейшее расследование.
Преимущества обнаружения аномалий
Обнаружение аномалий поведения пользователей помогает укрепить системы безопасности и сделать их более точными и точными.
Он анализирует и анализирует различную информацию, которую системы безопасности предоставляют для выявления угроз и потенциальных рисков в сети.
Вот преимущества обнаружения аномалий для компаний:
- Обнаружение угроз кибербезопасности и утечек данных в режиме реального времени, поскольку его алгоритмы искусственного интеллекта (ИИ) постоянно сканируют ваши данные, чтобы обнаружить необычное поведение.
- Это делает отслеживание аномальных действий и шаблонов быстрее и проще, чем ручное обнаружение аномалий, сокращая трудозатраты и время, необходимые для устранения угроз.
- Сводит к минимуму операционные риски , выявляя операционные ошибки, такие как внезапное падение производительности, еще до их возникновения.
- Это помогает устранить крупный ущерб бизнесу за счет быстрого обнаружения аномалий, поскольку без системы обнаружения аномалий компаниям могут потребоваться недели и месяцы для выявления потенциальных угроз.
Таким образом, обнаружение аномалий является огромным преимуществом для компаний, хранящих обширные наборы данных о клиентах и бизнесе, для поиска возможностей роста и устранения угроз безопасности и операционных узких мест.
Методы обнаружения аномалий
Обнаружение аномалий использует несколько процедур и алгоритмов машинного обучения (ML) для мониторинга данных и обнаружения угроз.
Вот основные методы обнаружения аномалий:
№1. Методы машинного обучения

Методы машинного обучения используют алгоритмы машинного обучения для анализа данных и обнаружения аномалий. Различные типы алгоритмов машинного обучения для обнаружения аномалий включают в себя:
- Алгоритмы кластеризации
- Алгоритмы классификации
- Алгоритмы глубокого обучения
А широко используемые методы ML для обнаружения аномалий и угроз включают машины опорных векторов (SVM), кластеризацию k-средних и автокодировщики.
№ 2. Статистические методы
Статистические методы используют статистические модели для обнаружения необычных закономерностей (например, необычных колебаний производительности конкретной машины) в данных, чтобы обнаруживать значения, выходящие за пределы диапазона ожидаемых значений.
Общие методы обнаружения статистических аномалий включают проверку гипотез, IQR, Z-оценку, модифицированную Z-оценку, оценку плотности, ящичковую диаграмму, анализ экстремальных значений и гистограмму.
№3. Методы интеллектуального анализа данных

Методы интеллектуального анализа данных используют методы классификации и кластеризации данных для поиска аномалий в наборе данных. Некоторые распространенные методы анализа аномалий интеллектуального анализа данных включают спектральную кластеризацию, кластеризацию на основе плотности и анализ основных компонентов.
Алгоритмы кластеризации интеллектуального анализа данных используются для группировки различных точек данных в кластеры на основе их сходства для поиска точек данных и аномалий, выходящих за пределы этих кластеров.
С другой стороны, алгоритмы классификации распределяют точки данных по определенным предопределенным классам и обнаруживают точки данных, которые не принадлежат этим классам.
№ 4. Методы, основанные на правилах
Как следует из названия, методы обнаружения аномалий на основе правил используют набор заранее определенных правил для поиска аномалий в данных.
Эти методы сравнительно легче и проще настроить, но они могут быть негибкими и неэффективными при адаптации к изменяющемуся поведению и шаблонам данных.
Например, вы можете легко запрограммировать систему, основанную на правилах, чтобы помечать транзакции, превышающие определенную сумму в долларах, как мошеннические.
№ 5. Специфичные для предметной области методы
Вы можете использовать специфичные для предметной области методы для обнаружения аномалий в определенных системах данных. Однако, хотя они могут быть очень эффективными при обнаружении аномалий в определенных областях, они могут быть менее эффективными в других областях за пределами указанной.
Например, с помощью методов, специфичных для предметной области, вы можете разработать методы специально для поиска аномалий в финансовых транзакциях. Но они могут не работать для обнаружения аномалий или снижения производительности машины.
Необходимость машинного обучения для обнаружения аномалий
Машинное обучение очень важно и очень полезно для обнаружения аномалий.
Сегодня большинство компаний и организаций, которым требуется обнаружение выбросов, имеют дело с огромными объемами данных, от текста, информации о клиентах и транзакциях до мультимедийных файлов, таких как изображения и видеоконтент.
Просматривать все банковские транзакции и данные, генерируемые каждую секунду вручную, для получения осмысленной информации практически невозможно. Более того, большинство компаний сталкиваются с проблемами и серьезными трудностями при структурировании неструктурированных данных и упорядочивании данных таким образом, чтобы их можно было анализировать.
Именно здесь инструменты и методы, такие как машинное обучение (ML), играют огромную роль в сборе, очистке, структурировании, упорядочении, анализе и хранении огромных объемов неструктурированных данных.
Методы и алгоритмы машинного обучения обрабатывают большие наборы данных и обеспечивают гибкость использования и сочетания различных методов и алгоритмов для достижения наилучших результатов.
Кроме того, машинное обучение также помогает оптимизировать процессы обнаружения аномалий для реальных приложений и экономит ценные ресурсы.
Вот еще несколько преимуществ и важности машинного обучения для обнаружения аномалий:
- Это упрощает масштабирование обнаружения аномалий за счет автоматизации идентификации закономерностей и аномалий без необходимости явного программирования.
- Алгоритмы машинного обучения легко адаптируются к изменяющимся шаблонам наборов данных, что делает их очень эффективными и надежными с течением времени.
- Легко обрабатывает большие и сложные наборы данных, делая обнаружение аномалий эффективным, несмотря на сложность набора данных.
- Обеспечивает раннюю идентификацию и обнаружение аномалий, выявляя аномалии по мере их возникновения, экономя время и ресурсы.
- Системы обнаружения аномалий на основе машинного обучения помогают достичь более высокого уровня точности обнаружения аномалий по сравнению с традиционными методами.
Таким образом, обнаружение аномалий в сочетании с машинным обучением помогает быстрее и раньше обнаруживать аномалии для предотвращения угроз безопасности и злонамеренных нарушений.

Алгоритмы машинного обучения для обнаружения аномалий
Вы можете обнаруживать аномалии и выбросы в данных с помощью различных алгоритмов интеллектуального анализа данных для классификации, кластеризации или изучения правил ассоциации.
Как правило, эти алгоритмы интеллектуального анализа данных подразделяются на две разные категории — алгоритмы обучения с учителем и без учителя.
Контролируемое обучение
Обучение с учителем — это распространенный тип алгоритма обучения, который состоит из таких алгоритмов, как машины опорных векторов, логистическая и линейная регрессия, а также многоклассовая классификация. Этот тип алгоритма обучается на помеченных данных, что означает, что его набор обучающих данных включает как нормальные входные данные, так и соответствующие правильные выходные данные или аномальные примеры для построения прогностической модели.
Таким образом, его цель состоит в том, чтобы делать выходные прогнозы для невидимых и новых данных на основе шаблонов набора обучающих данных. К приложениям алгоритмов обучения с учителем относятся распознавание изображений и речи, прогнозное моделирование и обработка естественного языка (NLP).
Неконтролируемое обучение
Неконтролируемое обучение не обучается ни на каких размеченных данных. Вместо этого он обнаруживает сложные процессы и базовые структуры данных, не предоставляя руководства по алгоритму обучения и вместо того, чтобы делать конкретные прогнозы.
Приложения алгоритмов обучения без учителя включают обнаружение аномалий, оценку плотности и сжатие данных.
Теперь давайте рассмотрим некоторые популярные алгоритмы обнаружения аномалий на основе машинного обучения.
Фактор локального выброса (LOF)
Local Outlier Factor или LOF — это алгоритм обнаружения аномалий, который учитывает локальную плотность данных, чтобы определить, является ли точка данных аномалией.
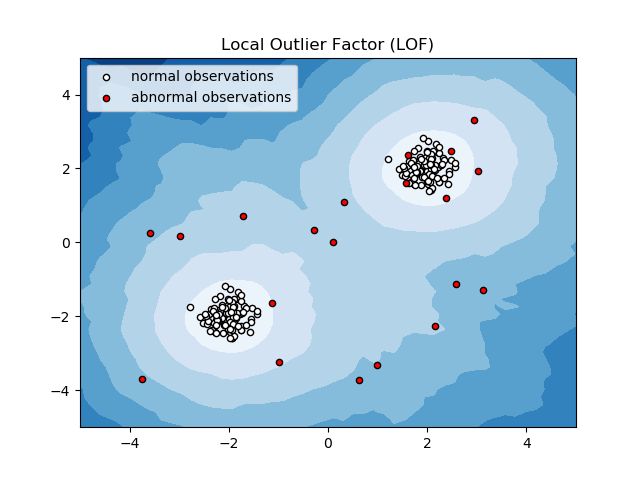
Он сравнивает локальную плотность элемента с локальными плотностями его соседей, чтобы анализировать области с аналогичной плотностью и элементы со сравнительно более низкой плотностью, чем их соседи, которые являются ничем иным, как аномалиями или выбросами.
Таким образом, говоря простыми словами, плотность вокруг выброса или аномального объекта отличается от плотности вокруг его соседей. Следовательно, этот алгоритм также называют алгоритмом обнаружения выбросов на основе плотности.
K-ближайший сосед (K-NN)
K-NN — это простейший алгоритм классификации и контролируемого обнаружения аномалий, который легко реализовать, он хранит все доступные примеры и данные и классифицирует новые примеры на основе сходства показателей расстояния.
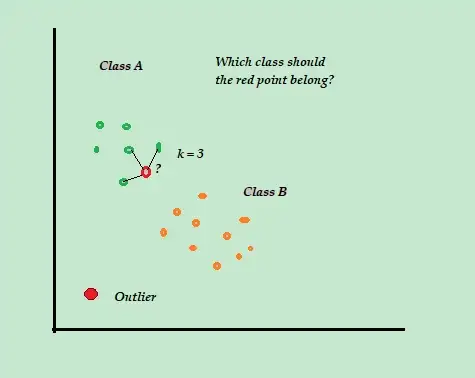
Этот алгоритм классификации также называют ленивым учеником , потому что он сохраняет только помеченные обучающие данные, не делая ничего другого в процессе обучения.
Когда поступает новая немаркированная точка обучающих данных, алгоритм просматривает K-ближайшие или самые близкие обучающие точки данных, чтобы использовать их для классификации и определения класса новой немаркированной точки данных.
Алгоритм K-NN использует следующие методы обнаружения для определения ближайших точек данных:
- Евклидово расстояние для измерения расстояния для непрерывных данных.
- Расстояние Хэмминга для измерения близости или «близости» двух текстовых строк для дискретных данных.
Например, предположим, что наборы обучающих данных состоят из двух меток классов, A и B. Если поступает новая точка данных, алгоритм рассчитает расстояние между новой точкой данных и каждой из точек данных в наборе данных и выберет точки. которые являются максимальным числом ближайшим к новой точке данных.
Итак, предположим, что K=3, и 2 из 3 точек данных помечены как A, тогда новая точка данных помечена как класс A.
Следовательно, алгоритм K-NN лучше всего работает в динамических средах с частыми требованиями к обновлению данных.
Это популярный алгоритм обнаружения аномалий и анализа текста с приложениями в сфере финансов и бизнеса для обнаружения мошеннических транзакций и повышения скорости обнаружения мошенничества.
Метод опорных векторов (SVM)
Машина опорных векторов — это контролируемый алгоритм обнаружения аномалий на основе машинного обучения, который в основном используется в задачах регрессии и классификации.
Он использует многомерную гиперплоскость для разделения данных на две группы (новые и обычные). Таким образом, гиперплоскость действует как граница решения, которая разделяет наблюдения обычных данных и новые данные.
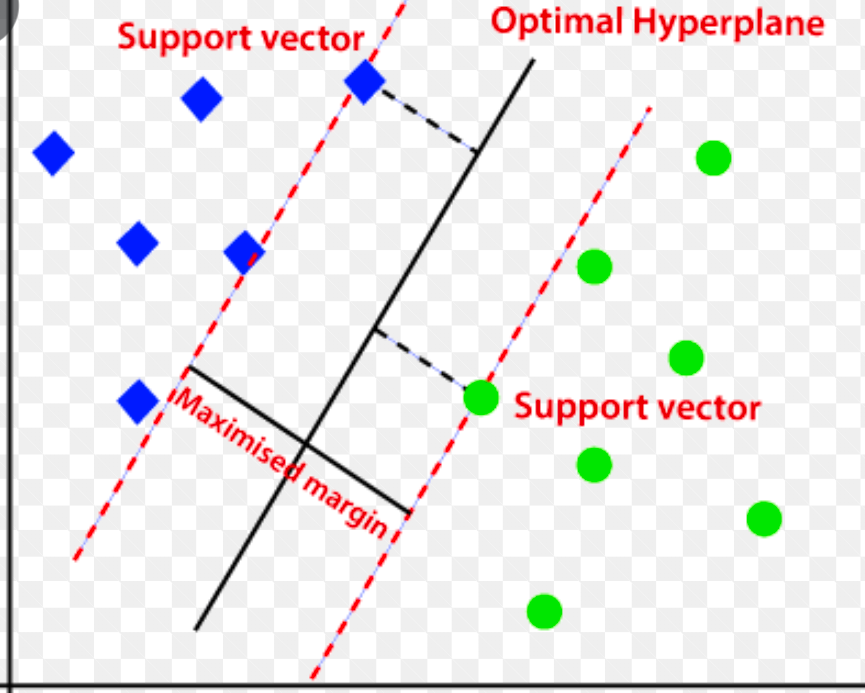
Расстояние между этими двумя точками данных называется полями.
Поскольку цель состоит в том, чтобы увеличить расстояние между двумя точками, SVM определяет наилучшую или оптимальную гиперплоскость с максимальным запасом , чтобы расстояние между двумя классами было как можно больше.
Что касается обнаружения аномалий, SVM вычисляет границу наблюдения новой точки данных от гиперплоскости, чтобы классифицировать ее.
Если маржа превышает установленный порог, новое наблюдение классифицируется как аномалия. В то же время, если запас меньше порога, наблюдение классифицируется как нормальное.
Таким образом, алгоритмы SVM очень эффективны при обработке многомерных и сложных наборов данных.
Изоляция Лес
Isolation Forest — это неконтролируемый алгоритм обнаружения аномалий на основе машинного обучения, основанный на концепции классификатора случайного леса.
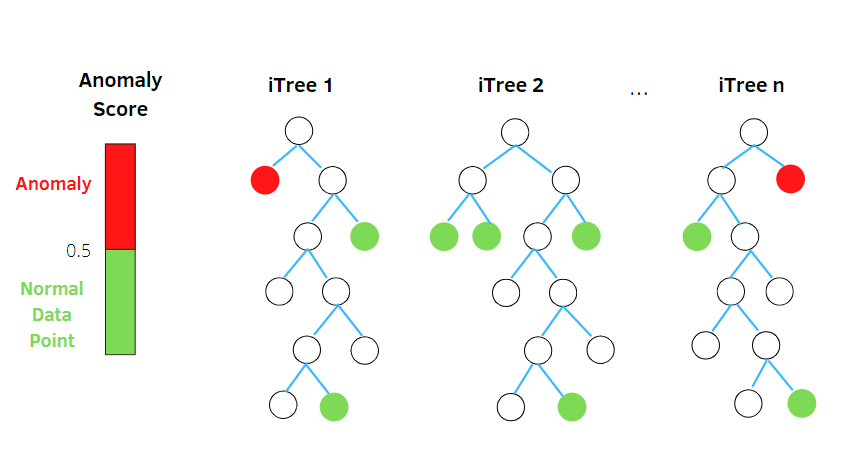
Этот алгоритм обрабатывает случайно отобранные данные в наборе данных в древовидной структуре на основе случайных атрибутов. Он строит несколько деревьев решений, чтобы изолировать наблюдения. И он считает конкретное наблюдение аномалией, если оно изолировано на меньшем количестве деревьев в зависимости от степени его загрязнения.
Таким образом, говоря простыми словами, алгоритм изолированного леса разбивает точки данных на разные деревья решений, обеспечивая изоляцию каждого наблюдения от другого.
Аномалии обычно лежат в стороне от кластера точек данных, что упрощает выявление аномалий по сравнению с обычными точками данных.
Алгоритмы изолированного леса могут легко обрабатывать категориальные и числовые данные. В результате они быстрее обучаются и очень эффективно обнаруживают аномалии в многомерных и больших наборах данных.
Межквартильный диапазон
Межквартильный диапазон или IQR используется для измерения статистической изменчивости или статистической дисперсии , чтобы найти аномальные точки в наборах данных, разделив их на квартили.
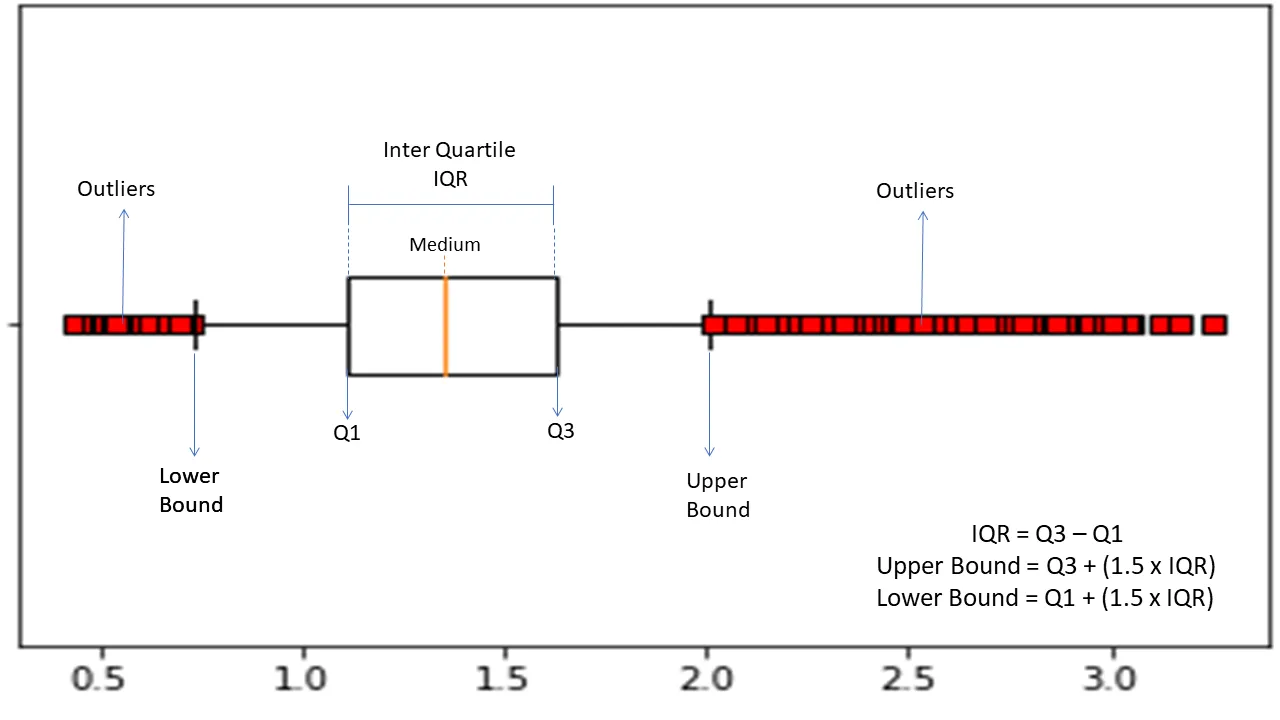
Алгоритм сортирует данные в порядке возрастания и разбивает набор на четыре равные части. Значения, разделяющие эти части, — это Q1, Q2 и Q3 — первый, второй и третий квартили.
Вот процентное распределение этих квартилей:
- Q1 означает 25-й процентиль данных.
- Q2 означает 50-й процентиль данных.
- Q3 означает 75-й процентиль данных.
IQR — это разница между наборами данных третьего (75-го) и первого (25-го) процентилей, представляющая 50% данных.
Использование IQR для обнаружения аномалий требует, чтобы вы рассчитали IQR вашего набора данных и определили нижнюю и верхнюю границы данных для поиска аномалий.
- Нижняя граница: Q1 – 1,5 * IQR
- Верхняя граница: Q3 + 1,5 * IQR
Обычно наблюдения, выходящие за эти границы, считаются аномалиями.
Алгоритм IQR эффективен для наборов данных с неравномерно распределенными данными и где распределение не совсем понятно.
Заключительные слова
Риски кибербезопасности и утечки данных, похоже, не уменьшатся в ближайшие годы, и ожидается, что эта рискованная отрасль продолжит расти в 2023 году, а к 2025 году ожидается, что только кибератаки IoT удвоятся.
Более того, к 2025 году киберпреступления будут стоить глобальным компаниям и организациям примерно 10,3 триллиона долларов в год.
Вот почему потребность в методах обнаружения аномалий становится все более распространенной и необходимой сегодня для обнаружения мошенничества и предотвращения вторжений в сеть.
Эта статья поможет вам понять, что такое аномалии в интеллектуальном анализе данных, различные типы аномалий и способы предотвращения сетевых вторжений с помощью методов обнаружения аномалий на основе машинного обучения.
Далее вы можете изучить все о матрице путаницы в машинном обучении.