
Cum să vă sincronizați baza de date Oracle locală în AWS
Publicat: 2023-01-11Urmărind dezvoltarea software-ului corporativ din primul rând timp de două decenii, tendința incontestabilă din ultimii câțiva ani este clară – mutarea bazelor de date în cloud.
Eram deja implicat în câteva proiecte de migrare, în care scopul a fost să aduc baza de date on-premise existentă în baza de date Cloud Amazon Web Services (AWS). În timp ce din materialele de documentare AWS, veți afla cât de ușor poate fi acest lucru, sunt aici să vă spun că executarea unui astfel de plan nu este întotdeauna ușoară și există cazuri în care poate eșua.

În această postare, voi acoperi experiența din lumea reală pentru următorul caz:
- Sursa : În timp ce, în teorie, nu contează cu adevărat care este sursa dvs. (puteți folosi o abordare foarte similară pentru majoritatea celor mai populare baze de date), Oracle a fost sistemul de bază de date ales în marile companii corporative timp de mulți ani și acolo va fi concentrarea mea.
- Ținta : Nu există niciun motiv pentru care să fii specific pe această parte. Puteți alege orice bază de date țintă în AWS și abordarea se va potrivi în continuare.
- Modul : Puteți avea o reîmprospătare completă sau o reîmprospătare incrementală. O încărcare de date în lot (stările sursă și țintă sunt întârziate) sau încărcare de date (aproape) în timp real. Ambele vor fi atinse aici.
- Frecvența : S-ar putea să doriți o migrare unică urmată de o trecere completă la cloud sau să aveți nevoie de o perioadă de tranziție și să aveți datele actualizate de ambele părți simultan, ceea ce implică dezvoltarea sincronizării zilnice între on-premise și AWS. Primul este mai simplu și are mult mai mult sens, dar cel de-al doilea este mai des solicitat și are mult mai multe puncte de break. Le voi acoperi pe ambele aici.
Descrierea problemei
Cerința este adesea simplă:
Dorim să începem să dezvoltăm servicii în AWS, așa că vă rugăm să copiați toate datele noastre în baza de date „ABC”. Rapid și simplu. Trebuie să folosim datele din AWS acum. Mai târziu, ne vom da seama ce părți ale designului DB trebuie schimbate pentru a se potrivi cu activitățile noastre.
Înainte de a merge mai departe, este ceva de luat în considerare:
- Nu săriți prea repede la ideea de „doar copiați ceea ce avem și rezolvați-l mai târziu”. Adică, da, acesta este cel mai ușor lucru pe care îl poți face și se va face rapid, dar acest lucru are potențialul de a crea o problemă arhitecturală atât de fundamentală, care va fi imposibil de rezolvat mai târziu fără o refactorizare serioasă a majorității noii platforme cloud. . Imaginați-vă că ecosistemul cloud este complet diferit de cel on-premise. De-a lungul timpului vor fi introduse mai multe servicii noi. Desigur, oamenii vor începe să folosească același lucru în mod foarte diferit. Aproape niciodată nu este o idee bună să reproduci starea on-premise în cloud într-un mod 1:1. Ar putea fi în cazul dvs. particular, dar asigurați-vă că verificați acest lucru.
- Întrebați cerința cu câteva îndoieli semnificative, cum ar fi:
- Cine va fi utilizatorul obișnuit care utilizează noua platformă? În timp ce este on-premise, poate fi un utilizator de afaceri tranzacțional; în cloud, poate fi un cercetător de date sau un analist de depozit de date sau utilizatorul principal al datelor poate fi un serviciu (de exemplu, Databricks, Glue, modele de învățare automată etc.).
- Se așteaptă ca locurile de muncă obișnuite de zi cu zi să rămână chiar și după trecerea la cloud? Dacă nu, cum se așteaptă să se schimbe?
- Planificați o creștere substanțială a datelor în timp? Cel mai probabil, răspunsul este da, deoarece acesta este adesea cel mai important motiv pentru a migra în cloud. Un nou model de date va fi pregătit pentru acesta.
- Așteptați-vă ca utilizatorul final să se gândească la unele interogări generale anticipate pe care noua bază de date le va primi de la utilizatori. Aceasta va defini cât de mult se va schimba modelul de date existent pentru a rămâne relevant pentru performanță.
Configurarea migrației
Odată ce baza de date țintă este aleasă și modelul de date este discutat satisfăcător, următorul pas este să vă familiarizați cu AWS Schema Conversion Tool. Există mai multe domenii în care acest instrument poate servi:
- Analizați și extrageți modelul de date sursă. SCT va citi ce este în baza de date actuală și va genera un model de date sursă pentru a începe cu.
- Sugerați o structură de model de date țintă bazată pe baza de date țintă.
- Generați scripturi de implementare a bazei de date țintă pentru a instala modelul de date țintă (pe baza a ceea ce instrumentul a aflat din baza de date sursă). Acest lucru va genera scripturi de implementare, iar după executarea lor, baza de date din cloud va fi pregătită pentru încărcarea datelor din baza de date locală.
Acum există câteva sfaturi pentru utilizarea Instrumentului de conversie a schemelor.
În primul rând, nu ar trebui să fie aproape niciodată cazul să folosiți ieșirea direct. L-aș considera mai degrabă rezultate de referință, de unde vă veți face ajustările în funcție de înțelegerea și scopul dvs. al datelor și de modul în care datele vor fi utilizate în cloud.
În al doilea rând, mai devreme, tabelele au fost probabil selectate de utilizatori care se așteptau la rezultate scurte rapide despre o entitate concretă de domeniu de date. Dar acum, datele ar putea fi selectate în scopuri analitice. De exemplu, indecșii bazei de date care lucrau anterior în baza de date on-premise vor fi acum inutile și cu siguranță nu vor îmbunătăți performanța sistemului DB legat de această nouă utilizare. În mod similar, este posibil să doriți să partiționați datele în mod diferit pe sistemul țintă, așa cum a fost înainte pe sistemul sursă.
De asemenea, ar putea fi bine să luați în considerare realizarea unor transformări de date în timpul procesului de migrare, ceea ce înseamnă, practic, schimbarea modelului de date țintă pentru unele tabele (astfel încât acestea să nu mai fie copii 1:1). Mai târziu, regulile de transformare vor trebui implementate în instrumentul de migrare.
Configurarea instrumentului de migrare
Dacă bazele de date sursă și țintă sunt de același tip (de exemplu, Oracle on-premise vs. Oracle în AWS, PostgreSQL vs. Aurora Postgresql etc.), atunci cel mai bine este să utilizați un instrument de migrare dedicat pe care baza de date concretă o acceptă nativ ( de exemplu, exporturile și importurile cu pompe de date, Oracle Goldengate etc.).
Cu toate acestea, în majoritatea cazurilor, baza de date sursă și țintă nu vor fi compatibile, iar apoi instrumentul evident de alegere va fi AWS Database Migration Service.
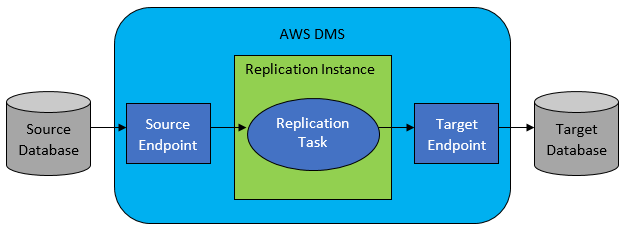
AWS DMS permite practic configurarea unei liste de sarcini la nivel de tabel, care va defini:
- Care este sursa exactă DB și tabelul la care să vă conectați?
- Specificații de declarație care vor fi utilizate pentru obținerea datelor pentru tabelul țintă.
- Instrumente de transformare (dacă există), care definesc modul în care datele sursă vor fi mapate în datele tabelului țintă (dacă nu 1:1).
- Care este baza de date țintă exactă și tabelul în care să încărcați datele?
Configurarea sarcinilor DMS se face într-un format ușor de utilizat, cum ar fi JSON.
Acum, în cel mai simplu scenariu, tot ce trebuie să faceți este să rulați scripturile de implementare pe baza de date țintă și să începeți sarcina DMS. Dar este mult mai mult la asta.

Migrare o singură dată completă a datelor

Cel mai ușor de executat este atunci când cererea este de a muta întreaga bază de date o dată în baza de date cloud țintă. Apoi, practic, tot ceea ce este necesar de făcut va arăta astfel:
- Definiți sarcina DMS pentru fiecare tabel sursă.
- Asigurați-vă că specificați corect configurația joburilor DMS. Aceasta înseamnă configurarea paralelismului rezonabil, variabilelor de stocare în cache, configurarea serverului DMS, dimensionarea clusterului DMS etc. Aceasta este, de obicei, faza cea mai consumatoare de timp, deoarece necesită testare extinsă și reglare fină a stării optime de configurare.
- Asigurați-vă că fiecare tabel țintă este creat (gol) în baza de date țintă în structura tabelului așteptată.
- Programați o fereastră de timp în care va fi efectuată migrarea datelor. Înainte de asta, evident, asigurați-vă că (făcând teste de performanță) fereastra de timp va fi suficientă pentru finalizarea migrației. În timpul migrării în sine, baza de date sursă ar putea fi restricționată din punct de vedere al performanței. De asemenea, este de așteptat ca baza de date sursă să nu se schimbe în timpul în care se va rula migrarea. În caz contrar, datele migrate pot fi diferite de cele stocate în baza de date sursă odată ce migrarea este finalizată.
Dacă configurația DMS este făcută bine, nu se va întâmpla nimic rău în acest scenariu. Fiecare tabel sursă va fi preluat și copiat în baza de date țintă AWS. Singurele preocupări vor fi desfășurarea activității și asigurarea faptului că dimensionarea este corectă la fiecare pas pentru a nu eșua din cauza spațiului de stocare insuficient.
Sincronizare zilnică incrementală

Aici lucrurile încep să se complice. Adică, dacă lumea ar fi ideală, atunci probabil că ar funcționa bine tot timpul. Dar lumea nu este niciodată ideală.
DMS poate fi configurat să funcționeze în două moduri:
- Încărcare completă – modul implicit descris și utilizat mai sus. Sarcinile DMS sunt pornite fie când le porniți, fie când sunt programate să înceapă. Odată terminate, sarcinile DMS sunt finalizate.
- Change Data Capture (CDC) – în acest mod, sarcina DMS rulează continuu. DMS scanează baza de date sursă pentru o modificare la nivel de tabel. Dacă se produce schimbarea, încearcă imediat să reproducă modificarea în baza de date țintă pe baza configurației din interiorul sarcinii DMS aferente tabelului modificat.
Când alegeți CDC, trebuie să faceți încă o alegere - și anume modul în care CDC va extrage modificările delta din DB sursă.
#1. Oracle Redo Logs Reader
O opțiune este să alegeți cititorul de jurnalele de refacere a bazei de date nativ de la Oracle, pe care CDC îl poate utiliza pentru a obține datele modificate și, pe baza celor mai recente modificări, să reproducă aceleași modificări în baza de date țintă.
Deși aceasta ar putea părea o alegere evidentă dacă ai de-a face cu Oracle ca sursă, există o problemă: cititorul de jurnale de refacere Oracle utilizează clusterul Oracle sursă și astfel afectează direct toate celelalte activități care rulează în baza de date (de fapt creează direct sesiuni active în baza de date).
Cu cât ați configurat mai multe sarcini DMS (sau cu cât mai multe clustere DMS în paralel), cu atât mai mult va trebui probabil să măriți clusterul Oracle – practic, ajustați scalarea verticală a clusterului dumneavoastră principal de baze de date Oracle. Acest lucru va influența cu siguranță costurile totale ale soluției, cu atât mai mult dacă sincronizarea zilnică este pe cale să rămână cu proiectul pentru o perioadă lungă de timp.
#2. AWS DMS Log Miner
Spre deosebire de opțiunea de mai sus, aceasta este o soluție AWS nativă pentru aceeași problemă. În acest caz, DMS nu afectează sursa Oracle DB. În schimb, copiază jurnalele de refacere Oracle în clusterul DMS și face toată procesarea acolo. Deși economisește resurse Oracle, este soluția mai lentă, deoarece sunt implicate mai multe operațiuni. Și, de asemenea, după cum se poate presupune cu ușurință, cititorul personalizat pentru jurnalele de refacere Oracle este probabil mai lent în munca sa ca cititor nativ de la Oracle.
În funcție de dimensiunea bazei de date sursă și de numărul de modificări zilnice de acolo, în cel mai bun scenariu, s-ar putea ajunge la o sincronizare incrementală aproape în timp real a datelor din baza de date Oracle locală în baza de date cloud AWS.
În orice alte scenarii, încă nu va fi aproape de sincronizare în timp real, dar puteți încerca să vă apropiați cât mai mult posibil de întârzierea acceptată (între sursă și țintă) prin reglarea configurației și paralelismului performanței clusterelor sursă și țintă sau experimentând cu cantitatea de sarcini DMS și distribuirea acestora între instanțele CDC.
Și poate doriți să aflați ce modificări tabelului sursă sunt acceptate de CDC (cum ar fi adăugarea unei coloane, de exemplu), deoarece nu toate modificările posibile sunt acceptate. În unele cazuri, singura modalitate este de a modifica manual tabelul țintă și de a reporni sarcina CDC de la zero (pierderea tuturor datelor existente în baza de date țintă pe parcurs).
Când lucrurile merg prost, indiferent ce

Am învățat acest lucru pe cale grea, dar există un scenariu specific legat de DMS în care promisiunea replicării zilnice este greu de realizat.
DMS poate procesa jurnalele de refacere numai cu o anumită viteză definită. Nu contează dacă există mai multe cazuri de DMS care vă execută sarcinile. Totuși, fiecare instanță DMS citește jurnalele de refacere doar cu o singură viteză definită și fiecare dintre ele trebuie să le citească întreg. Nici măcar nu contează dacă utilizați jurnalele de refacere Oracle sau AWS log miner. Ambele au această limită.
Dacă baza de date sursă include un număr mare de modificări într-o zi în care jurnalele de refacere Oracle devin foarte nebunești (cum ar fi 500 GB+ mari) în fiecare zi, CDC pur și simplu nu va funcționa. Replicarea nu va fi finalizată înainte de sfârșitul zilei. Va aduce niște lucrări neprocesate în ziua următoare, unde deja așteaptă un nou set de modificări care urmează să fie replicate. Cantitatea de date neprocesate va crește doar de la o zi la alta.
În acest caz particular, CDC nu era o opțiune (după multe teste de performanță și încercări pe care le-am executat). Singura modalitate de a vă asigura că cel puțin toate modificările delta din ziua curentă vor fi replicate în aceeași zi a fost să o abordați astfel:
- Separați mesele cu adevărat mari care nu sunt folosite atât de des și replicați-le doar o dată pe săptămână (de exemplu, în weekend).
- Configurați replicarea tabelelor nu atât de mari, dar încă mari pentru a fi împărțite între mai multe sarcini DMS; un tabel a fost în cele din urmă migrat de 10 sau mai multe sarcini DMS separate în paralel, asigurându-se că împărțirea datelor între sarcinile DMS este distinctă (codificare personalizată implicată aici) și executarea lor zilnic.
- Adăugați mai multe (până la 4 în acest caz) instanțe de DMS și împărțiți sarcinile DMS între ele în mod egal, ceea ce înseamnă nu numai după numărul de tabele, ci și după dimensiune.
Practic, am folosit modul de încărcare completă al DMS pentru a replica datele zilnice, deoarece aceasta era singura modalitate de a obține finalizarea replicării datelor cel puțin în aceeași zi.
Nu este o soluție perfectă, dar încă există și, chiar și după mulți ani, încă funcționează în același mod. Deci, poate nu este o soluție atât de rea până la urmă.