
Sprijină Vector Machine (SVM) în Machine Learning
Publicat: 2023-01-04Support Vector Machine este printre cei mai populari algoritmi de învățare automată. Este eficient și se poate antrena în seturi limitate de date. Dar ce este?
Ce este un suport Vector Machine (SVM)?
Mașina vectorială de suport este un algoritm de învățare automată care utilizează învățarea supravegheată pentru a crea un model de clasificare binară. Asta este o gură. Acest articol va explica SVM și modul în care se leagă de procesarea limbajului natural. Dar mai întâi, să analizăm modul în care funcționează o mașină vectorială de suport.
Cum funcționează SVM?
Luați în considerare o problemă simplă de clasificare în care avem date care au două caracteristici, x și y, și o ieșire - o clasificare care este fie roșie, fie albastră. Putem reprezenta un set de date imaginar care arată astfel:
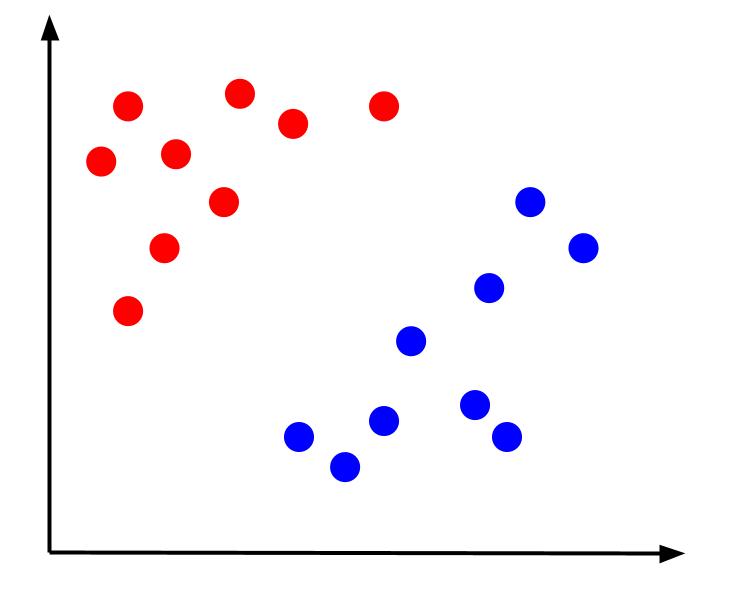
Având în vedere astfel de date, sarcina ar fi crearea unei limite de decizie. O graniță de decizie este o linie care separă cele două clase ale punctelor noastre de date. Acesta este același set de date, dar cu o limită de decizie:
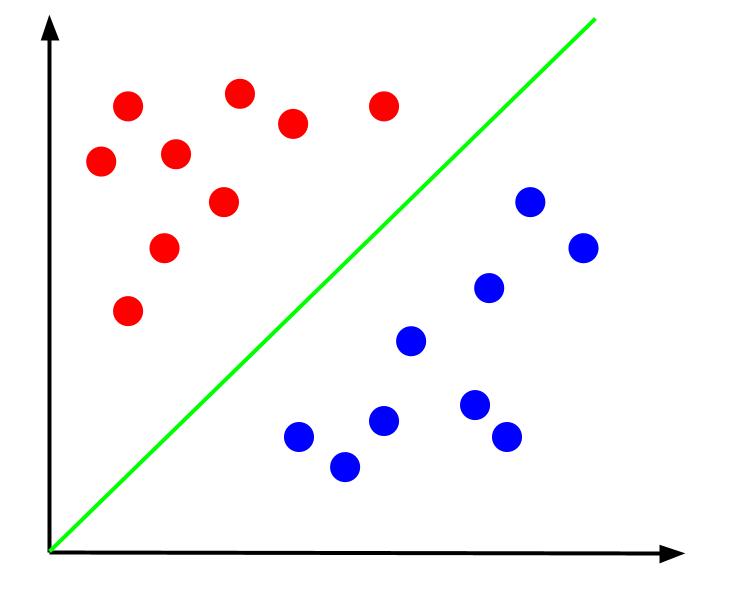
Cu această limită de decizie, putem face predicții pentru care clasă îi aparține un punct de date, dat fiind locul în care se află în raport cu limita de decizie. Algoritmul Support Vector Machine creează cea mai bună limită de decizie care va fi folosită pentru a clasifica punctele.
Dar ce înțelegem prin limita cea mai bună decizie?
Cea mai bună limită de decizie poate fi argumentată a fi cea care își maximizează distanța față de oricare dintre vectorii suport. Vectorii suport sunt puncte de date ale fiecărei clase cele mai apropiate de clasa opusă. Aceste puncte de date prezintă cel mai mare risc de clasificare greșită din cauza apropierii lor de cealaltă clasă.
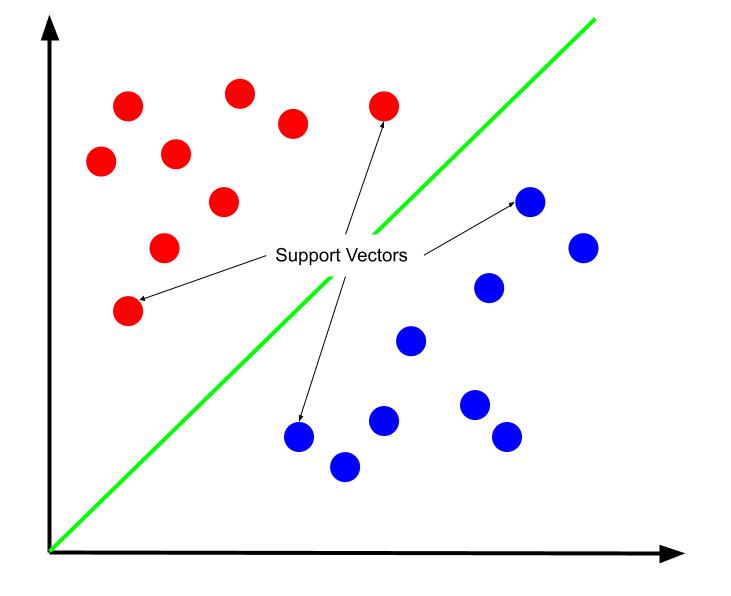
Prin urmare, antrenamentul unei mașini cu vector de suport implică încercarea de a găsi o linie care maximizează marja dintre vectorii de suport.
De asemenea, este important de menționat că, deoarece limita de decizie este poziționată în raport cu vectorii suport, ei sunt singurii determinanți ai poziției limitei de decizie. Celelalte puncte de date sunt, prin urmare, redundante. Și astfel, antrenamentul necesită doar vectorii suport.
În acest exemplu, granița de decizie formată este o linie dreaptă. Acest lucru se datorează faptului că setul de date are doar două caracteristici. Când setul de date are trei caracteristici, granița de decizie formată este mai degrabă un plan decât o linie. Și când are patru sau mai multe caracteristici, limita de decizie este cunoscută sub numele de hiperplan.
Date non-liniar separabile
Exemplul de mai sus a luat în considerare date foarte simple care, atunci când sunt reprezentate grafic, pot fi separate printr-o limită de decizie liniară. Luați în considerare un caz diferit în care datele sunt reprezentate după cum urmează:
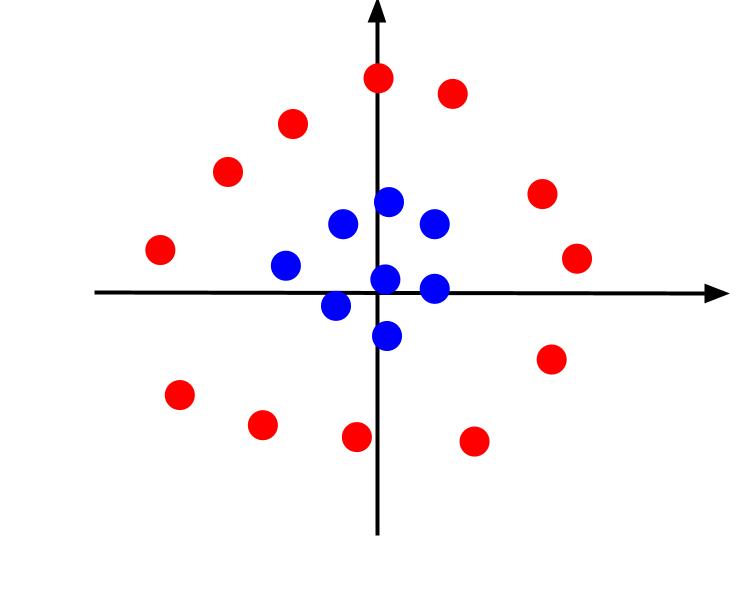
În acest caz, separarea datelor folosind o linie este imposibilă. Dar putem crea o altă caracteristică, z. Și această caracteristică poate fi definită prin ecuația: z = x^2 + y^2. Putem adăuga z ca a treia axă în plan pentru a-l face tridimensional.
Când privim graficul 3D dintr-un unghi astfel încât axa x să fie orizontală, în timp ce axa z este verticală, aceasta este vizualizarea în care obținem ceva care arată astfel:
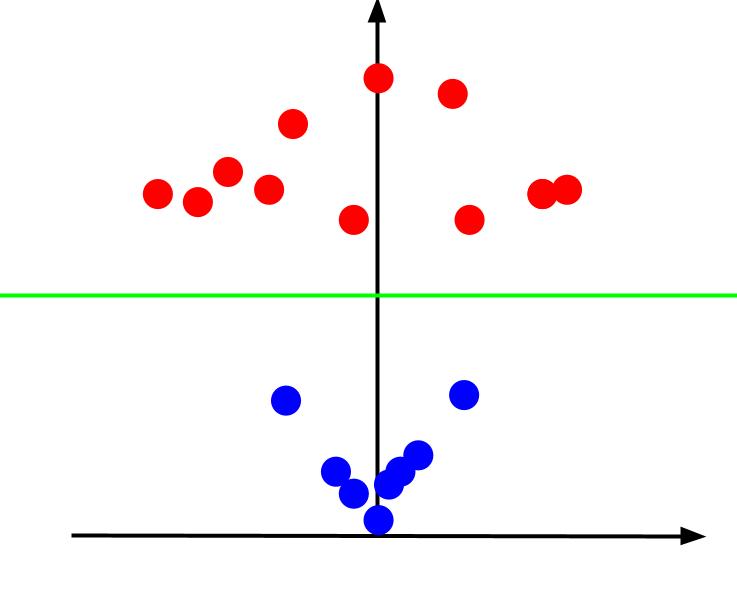
Valoarea z reprezintă cât de departe este un punct de la origine față de celelalte puncte din vechiul plan XY. Ca urmare, punctele albastre mai apropiate de origine au valori z scăzute.
În timp ce punctele roșii mai departe de origine au avut valori z mai mari, reprezentarea lor în raport cu valorile lor z ne oferă o clasificare clară care poate fi delimitată printr-o graniță de decizie liniară, așa cum este ilustrat.
Aceasta este o idee puternică care este folosită în mașinile de suport Vector. Mai general, este ideea de a mapa dimensiunile într-un număr mai mare de dimensiuni, astfel încât punctele de date să poată fi separate printr-o limită liniară. Funcțiile care sunt responsabile pentru aceasta sunt funcțiile nucleului. Există multe funcții ale nucleului, cum ar fi sigmoid, liniar, neliniar și RBF.
Pentru a face maparea acestor caracteristici mai eficientă, SVM folosește un truc al nucleului.
SVM în Machine Learning
Support Vector Machine este unul dintre numeroșii algoritmi folosiți în învățarea automată alături de cei populari, cum ar fi Decision Trees și Neural Networks. Este favorizat deoarece funcționează bine cu mai puține date decât alți algoritmi. Este de obicei folosit pentru a face următoarele:
- Clasificare text: clasificarea datelor text, cum ar fi comentariile și recenziile, în una sau mai multe categorii
- Detectarea feței : analiza imaginilor pentru a detecta fețele pentru a face lucruri precum adăugarea de filtre pentru realitate augmentată
- Clasificarea imaginilor : Mașinile de suport vector pot clasifica imaginile în mod eficient în comparație cu alte abordări.
Problema clasificării textului
Internetul este plin de o mulțime de date textuale. Cu toate acestea, multe dintre aceste date sunt nestructurate și neetichetate. Pentru a utiliza mai bine aceste date text și pentru a le înțelege mai bine, este nevoie de clasificare. Exemple de momente în care textul este clasificat includ:
- Când tweet-urile sunt clasificate în subiecte, astfel încât oamenii să poată urmări subiectele pe care le doresc
- Când un e-mail este clasificat ca Social, Promoții sau Spam
- Când comentariile sunt clasificate ca fiind urâtoare sau obscene pe forumurile publice
Cum funcționează SVM cu clasificarea limbajului natural
Support Vector Machine este folosit pentru a clasifica textul în text care aparține unui anumit subiect și text care nu aparține subiectului. Acest lucru se realizează prin conversia și reprezentarea datelor text într-un set de date cu mai multe caracteristici.
O modalitate de a face acest lucru este prin crearea de caracteristici pentru fiecare cuvânt din setul de date. Apoi, pentru fiecare punct de date text, înregistrați de câte ori apare fiecare cuvânt. Deci, să presupunem că în setul de date apar cuvinte unice; veți avea caracteristici în setul de date.
În plus, veți furniza clasificări pentru aceste puncte de date. În timp ce aceste clasificări sunt etichetate prin text, majoritatea implementărilor SVM se așteaptă la etichete numerice.
Prin urmare, va trebui să convertiți aceste etichete în numere înainte de antrenament. Odată ce setul de date a fost pregătit, folosind aceste caracteristici ca coordonate, puteți utiliza apoi un model SVM pentru a clasifica textul.
Crearea unui SVM în Python
Pentru a crea o mașină vectorială de suport (SVM) în Python, puteți utiliza clasa SVC din biblioteca sklearn.svm . Iată un exemplu despre cum puteți utiliza clasa SVC pentru a construi un model SVM în Python:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) În acest exemplu, importăm mai întâi clasa SVC din biblioteca sklearn.svm . Apoi, încărcăm setul de date și îl împărțim în seturi de antrenament și de testare.
Apoi, creăm un model SVM prin instanțierea unui obiect SVC și specificând parametrul kernel ca „liniar”. Apoi antrenăm modelul pe datele de antrenament folosind metoda de fit și evaluăm modelul pe datele de testare folosind metoda score . Metoda score returnează acuratețea modelului, pe care o imprimăm pe consolă.
De asemenea, puteți specifica alți parametri pentru obiectul SVC , cum ar fi parametrul C care controlează puterea regularizării și parametrul gamma , care controlează coeficientul nucleului pentru anumite nuclee.
Beneficiile SVM
Iată o listă cu câteva beneficii ale utilizării mașinilor vectoriale de suport (SVM):
- Eficiente : SVM-urile sunt în general eficiente de antrenat, mai ales când numărul de mostre este mare.
- Robust la zgomot : SVM-urile sunt relativ robuste la zgomot din datele de antrenament, deoarece încearcă să găsească clasificatorul de marjă maximă, care este mai puțin sensibil la zgomot decât alți clasificatori.
- Eficiență în memorie: SVM-urile necesită doar un subset al datelor de antrenament să fie în memorie la un moment dat, făcându-le mai eficiente în memorie decât alți algoritmi.
- Eficient în spații cu dimensiuni mari: SVM-urile pot funcționa în continuare bine chiar și atunci când numărul de caracteristici depășește numărul de mostre.
- Versatilitate : SVM-urile pot fi utilizate pentru sarcini de clasificare și regresie și pot gestiona diferite tipuri de date, inclusiv date liniare și neliniare.
Acum, să explorăm unele dintre cele mai bune resurse pentru a învăța Support Vector Machine (SVM).

Resurse de învățare
O introducere în suportul mașinilor vectoriale
Această carte despre Introducere în suportul mașinilor vectoriale vă prezintă în mod cuprinzător și treptat metodele de învățare bazate pe kernel.
| previzualizare | Produs | Evaluare | Preț | |
|---|---|---|---|---|
 | O introducere în sprijinirea mașinilor vectoriale și a altor metode de învățare bazate pe kernel | 75,00 USD | Cumpărați pe Amazon |
Vă oferă o bază fermă pe teoria suportului Vector Machines.
Suport aplicații Vector Machines
În timp ce prima carte s-a concentrat pe teoria mașinilor vectoriale de suport, această carte despre aplicațiile mașinilor vectoriale suport se concentrează pe aplicațiile lor practice.
| previzualizare | Produs | Evaluare | Preț | |
|---|---|---|---|---|
 | Suport aplicații Vector Machines | 15,52 USD | Cumpărați pe Amazon |
Acesta analizează modul în care SVM-urile sunt utilizate în procesarea imaginilor, detectarea modelelor și viziunea computerizată.
Mașini vectoriale de sprijin (știința informației și statistică)
Scopul acestei cărți despre Support Vector Machines (știința informației și statistică) este de a oferi o privire de ansamblu asupra principiilor din spatele eficienței mașinilor de suport vector (SVM) în diferite aplicații.
| previzualizare | Produs | Evaluare | Preț | |
|---|---|---|---|---|
 | Mașini vectoriale de sprijin (știința informației și statistică) | 167,36 USD | Cumpărați pe Amazon |
Autorii evidențiază mai mulți factori care contribuie la succesul SVM-urilor, inclusiv capacitatea lor de a funcționa bine cu un număr limitat de parametri ajustabili, rezistența lor la diferite tipuri de erori și anomalii și performanța lor de calcul eficientă în comparație cu alte metode.
Învățarea cu Kernels
„Learning with Kernels” este o carte care îi prezintă pe cititori să accepte mașinile vectoriale (SVM) și tehnicile asociate nucleului.
| previzualizare | Produs | Evaluare | Preț | |
|---|---|---|---|---|
 | Învățare cu nuclee: suport pentru mașini vectoriale, regularizare, optimizare și mai departe (Adaptive... | 80,00 USD | Cumpărați pe Amazon |
Este conceput pentru a oferi cititorilor o înțelegere de bază a matematicii și cunoștințele de care au nevoie pentru a începe să folosească algoritmi de nucleu în învățarea automată. Cartea își propune să ofere o introducere amănunțită, dar accesibilă, a SVM-urilor și a metodelor de kernel.
Sprijiniți mașinile vectoriale cu Sci-kit Learn
Acest curs online Support Vector Machines cu Sci-kit Learn al rețelei de proiect Coursera învață cum să implementați un model SVM folosind populara bibliotecă de învățare automată, Sci-Kit Learn.

În plus, veți învăța teoria din spatele SVM-urilor și veți determina punctele forte și limitările acestora. Cursul este la nivel de începător și necesită aproximativ 2,5 ore.
Suport mașini vectoriale în Python: concepte și cod
Acest curs online plătit despre Support Vector Machines în Python de la Udemy are până la 6 ore de instruire bazată pe video și vine cu o certificare.

Acoperă SVM-urile și modul în care acestea pot fi implementate solid în Python. În plus, acoperă aplicațiile de afaceri ale mașinilor de suport Vector.
Învățare automată și IA: sprijină mașinile vectoriale în Python
În acest curs despre învățarea automată și AI, veți învăța cum să utilizați mașinile vectoriale suport (SVM) pentru diverse aplicații practice, inclusiv recunoașterea imaginilor, detectarea spamului, diagnosticarea medicală și analiza regresiei.

Veți folosi limbajul de programare Python pentru a implementa modele ML pentru aceste aplicații.
Cuvinte finale
În acest articol, am aflat pe scurt despre teoria din spatele mașinilor vectoriale de suport. Am aflat despre aplicarea lor în Machine Learning și Natural Language Processing.
De asemenea, am văzut cum arată implementarea sa folosind scikit-learn . În plus, am vorbit despre aplicațiile practice și beneficiile suportului Vector Machines.
În timp ce acest articol a fost doar o introducere, resursele suplimentare recomandau să intre în mai multe detalii, explicând mai multe despre Support Vector Machines. Având în vedere cât de versatile și eficiente sunt, SVM-urile merită înțelese pentru a crește ca cercetător de date și inginer ML.
În continuare, puteți consulta cele mai bune modele de învățare automată.