
Ce este failover clustering? Cum funcționează + soluții
Publicat: 2023-09-22Companiile care au nevoie de tranzacții online nu își pot permite defecțiuni ale serverului. Drept urmare, aceste companii caută modalități de a crea o procedură de siguranță care să-și păstreze datele în siguranță, chiar dacă serverul se prăbușește. O astfel de metodă este clustering-ul de failover.
Gruparea de failover poate fi guvernată de soluții ale furnizorilor de sisteme de nume de domenii gestionate (DNS); cu toate acestea, înțelegerea mecanismului și a caracteristicilor cheie ale acestuia poate ajuta la limitarea oricăror provocări de failover.
Ce este clusteringul de failover?
Gruparea de failover funcționează pe un grup de servere de computer pentru a asigura disponibilitatea ridicată (HA) sau disponibilitatea continuă (CA) pentru aplicațiile server. Această tehnologie asigură că, dacă un server sau un nod eșuează, un alt nod de cluster este pregătit să preia sarcina de lucru fără întreruperi.
Această abordare menține încărcările de lucru ale serverului dvs. scalabile și disponibile. Multe programe majore de server, cum ar fi Microsoft Exchange , Microsoft SQL Server și Hyper-V , se bazează pe clusteringul de failover pentru a se proteja.
Unele clustere de failover folosesc servere fizice, în timp ce altele folosesc mașini virtuale (VM) . Fiecare selectează tipul de cluster de care are nevoie în funcție de cerințele aplicației server.
Un cluster este format din două sau mai multe noduri care fac schimb de date și software pentru a fi procesate prin cabluri fizice sau o rețea securizată specializată. Tehnologia de clusterizare de mai multe tipuri poate fi utilizată pentru echilibrarea sarcinii, stocare și calcule simultane sau paralele. În unele cazuri, clusterele de failover sunt combinate cu tehnologii de clustering suplimentare.
Funcția principală a unui cluster de failover este de a furniza CA sau HA pentru aplicații și servicii. Clusterele CA, cunoscute și sub denumirea de clustere tolerante la eșec (FT), permit utilizatorilor finali să continue să utilizeze aplicații și servicii chiar dacă un server se defectează. Este posibil să observați o scurtă întrerupere a serviciului cauzată de clusterele HA, dar sistemul se poate recupera fără pierderi de date și fără timp de nefuncționare.
De ce este importantă clusteringul de failover?
Cu clusteringul de failover, puteți repara nodurile inactive fără a vă închide baza de date, evitând problemele legate de timpul de nefuncționare, în timp ce reparați rapid serverele defecte. În plus, în cazul unei defecțiuni hardware, această tehnică închide baza de date pentru a proteja nodurile active.
De asemenea, clusteringul de failover automatizează recuperarea datelor în cazul unei erori. Acest lucru reduce dependența dvs. de echipajul de tehnologie a informației (IT) și permite serverelor dvs. să se recupereze rapid. Oferă, de asemenea, o excelentă disponibilitate a clusterului în limbajul de interogare structurat (SQL) cu un timp de nefuncționare minim. Funcționalitatea automată de failover a clusteringului de failover păstrează funcția bazei de date, chiar dacă există o defecțiune hardware.
Cum funcționează clusterele de failover?
Gruparea de failover constă din două procese fundamentale, HA și CA, pentru aplicațiile server.
În timp ce clusterele de failover CA încearcă să atingă o disponibilitate de 100%, clusterele HA se străduiesc să obțină 99,999%, cunoscută în mod obișnuit ca cinci nouă. Acest timp de nefuncționare totalizează nu mai mult de 5,26 minute în fiecare an. Clusterele CA au o disponibilitate mai mare, dar necesită mai mult hardware pentru a funcționa, crescând costul lor total.
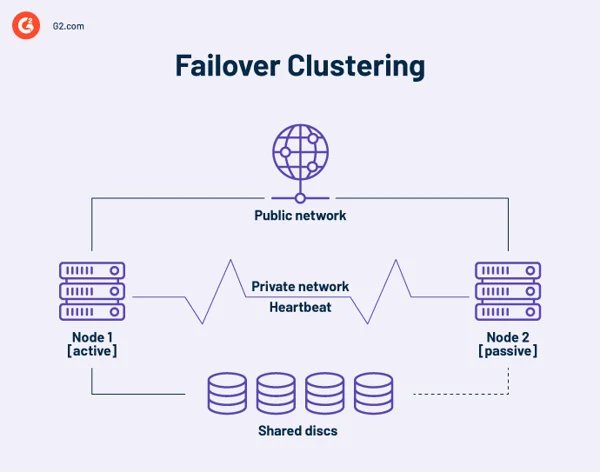
Clustere de failover de înaltă disponibilitate
Un cluster de înaltă disponibilitate este o colecție de computere independente care partajează resurse și date. Nodurile unui cluster de failover au acces la stocarea partajată. O legătură de monitorizare este, de asemenea, inclusă în clusterele de înaltă disponibilitate pentru a verifica bătăile inimii sau starea de sănătate a celorlalte servere. O bătaie de inimă este o rețea privată partajată numai de nodurile din cluster. Nu este accesibil din exterior.
În orice moment, cel puțin un nod dintr-un cluster este activ și cel puțin unul este inactiv sau pasiv.
Într-un aranjament de bază cu două noduri, dacă Nodul 1 eșuează, Nodul 2 recunoaște defecțiunea prin conexiunea heartbeat și se configurează ca nod activ. Software-ul de clusterizare pe fiecare nod garantează că clienții se conectează la un nod activ.
Instalațiile mai mari pot folosi servere dedicate pentru a administra clusterul. Un server de gestionare a clusterului trimite întotdeauna semnale de bătăi ale inimii pentru a identifica nodurile care defectează și, dacă da, pentru a spune altui nod să preia munca.
Unele instrumente software de gestionare a clusterelor gestionează HA pentru VM prin gruparea mașinilor și serverelor într-un cluster. Dacă o gazdă eșuează, o altă gazdă reia mașinile virtuale.
Ca un posibil punct de eroare unic, stocarea partajată reprezintă un risc. Cu toate acestea, combinarea unei matrice redundante de discuri independente 6 și 10 – alias RAID 6 și RAID 10 – poate ajuta la menținerea serviciului chiar dacă două hard disk-uri se defectează.
Energia electrică ar putea fi un alt punct unic de defecțiune dacă toate serverele sunt conectate la aceeași rețea. Furnizarea fiecărui nod cu propria sa sursă de alimentare neîntreruptibilă (UPS) îi menține protejat.
Clustere de failover cu disponibilitate continuă
Spre deosebire de paradigma HA, un cluster tolerant la erori cuprinde numeroase computere care partajează o singură copie a sistemului de operare (OS) al unui computer. Comenzile software date unui sistem sunt executate și pe celelalte sisteme.
CA insistă că organizația folosește echipamente informatice formatate și un UPS de rezervă. CA are nevoie de o replică permanent accesibilă și aproape perfectă a sistemului fizic sau virtual care rulează serviciul. Acest model de redundanță este cunoscut sub numele de 2N.
Sistemele CA pot compensa o gamă largă de defecțiuni. Un sistem tolerant la erori poate identifica o defecțiune a:
- Un hard disk
- O unitate de procesare într-un computer
- Un subsistem pentru intrare și ieșire (I/O)
- O sursă de energie
- O componentă a unei rețele
Punctul de defecțiune poate fi descoperit cu promptitudine, iar o componentă sau o metodă de rezervă îi poate lua locul imediat, fără a întrerupe următorul serviciu.
Software-ul de clusterizare poate conecta două sau mai multe servere pentru a se comporta ca un singur server virtual sau poate construi diverse configurații alternative ale clusterului CA failover. De exemplu, dacă unul dintre serverele virtuale eșuează, celelalte răspund prin eliminarea temporară a serverului virtual din cvorumul clusterului. Serverul virtual redistribuie apoi sarcina peste celelalte servere până când serverul prăbușit este gata să repornească.
Un server hardware dublu cu toate componentele fizice replicate este o alternativă la clusterele CA failover. Acestea calculează separat și simultan pe diverse platforme hardware și se sincronizează folosind un nod dedicat care monitorizează rezultatele de la ambele servere fizice. În timp ce această soluție oferă protecție, poate fi mai scumpă.
Funcții de clustering de failover
Multe organizații folosesc clustering de failover pentru aplicații critice. Acest lucru se datorează faptului că următoarele caracteristici fac din clusteringul de failover o tehnică semnificativă.
- Scalabilitate : Deoarece clusteringul de failover se bazează pe un grup de clustere care colaborează pentru a preveni defecțiunea serverului, puteți scala ușor și ușor, după cum este necesar, adăugând noi clustere.
- Stabilitate: serverele în cluster se conectează prin fire. Clusterele rămase pot oferi în continuare servicii chiar dacă unul sau mai multe eșuează din cauza unor factori externi.
- Monitorizare în timp real: nodurile clusterului sunt monitorizate în mod constant pentru a vă asigura că funcționează corect. Când un cluster este repornit sau transferat pe un alt nod.
- Volum partajat în cluster (CSV): Această caracteristică oferă un spațiu de nume consecvent și distribuit pentru ca nodurile să le folosească în timp ce lucrează cu spațiu de stocare partajat. Este esențial să mențineți aplicațiile server care rulează fără întrerupere de la început până la sfârșit.
Tipuri de clustere de failover
În ultimul deceniu s-au produs progrese semnificative în clusteringul de failover, multe organizații oferind acum propria versiune a soluțiilor de clustering. Unele dintre cele mai comune servicii cluster sunt detaliate aici.

clustere de failover VMware
VMware oferă numeroase tehnologii de virtualizare pentru clusterele VM. Arhitectura CA a vSphere vMotion duplică precis o mașină virtuală VMware și rețeaua acesteia între rețelele fizice ale centrelor de date.
VMware vSphere HA, un al doilea produs, oferă HA pentru VM prin gruparea acestora și a gazdelor lor într-un cluster pentru failover automat. În plus, programul nu se bazează pe componente externe, cum ar fi DNS, ceea ce reduce posibilele puncte de eșec.
Cluster de failover a serverului Windows
Metoda Windows Server failover cluster (WSFC) încurajează crearea de servere Hyper-V de failover. Între 2016 și 2019, această strategie a devenit populară în rândul utilizatorilor Microsoft Windows. WSFC permite monitorizarea clusterului și oferă automat mecanismul de failover necesar. În cazul unei pierderi de server, WFSC mută clusterele într-un nod separat sau încearcă să le repornească. În plus, tehnologia sa CSV oferă un spațiu de nume distribuit care permite mai multor noduri să partajeze memoria.
SQL Server
Acest produs Microsoft, introdus cu SQL Server 2017, are soluții HA robuste care utilizează tehnologia WSFC. Componentele serverului SQL sunt considerate resurse cluster WSFC în acest context. Sunt integrate în continuare cu alte resurse dependente de WSFC. Ca rezultat, WSFC are autoritate asupra identificării și comunicării comenzilor pentru a reporni o instanță de server SQL sau pentru a muta instanțe ca acelea într-un nod nou.
Red Hat Linux
În afară de Microsoft, alți furnizori de sisteme de operare vin cu propriile soluții de cluster de failover. De exemplu, fanii Red Hat Enterprise Linux (RHEL) pot folosi extensia HA și Red Hat Global File System (GFS/GFS2) pentru a stabili clustere de failover HA. Sunt acceptate clustere întinse cu un singur cluster care se întind în multe locații și clustere cu mai multe site-uri, tolerante la dezastre . Replicarea de stocare a datelor din rețeaua de stocare (SAN) este utilizată în mod obișnuit în clustere cu mai multe site-uri.
Aplicații de clustering de failover
Acest mecanism robust facilitează următoarele aplicații în timp real.
Disponibilitatea aplicațiilor critice pentru misiune.
Calculatoarele de procesare a tranzacțiilor online (OLTP) trebuie să aibă sisteme rezistente la erori. OLTP, care necesită disponibilitate completă, este utilizat pentru sistemele de rezervare a companiilor aeriene, tranzacționarea electronică a acțiunilor și operațiunile bancare ATM.
Multe industrii, cum ar fi producția, transportul și vânzarea cu amănuntul, folosesc clustere CA sau computere rezistente la defecțiuni pentru aplicații importante. Comerțul electronic, managementul comenzilor și sistemele de ceas al personalului sunt exemple.
Clusterele de înaltă disponibilitate sunt adesea acceptabile pentru clusteringul de aplicații și servicii care necesită doar timp de funcționare cinci-nouă.
Ajutorarea dezastrelor
Recuperarea în caz de dezastru beneficiază, de asemenea, de clusteringul de failover. Se recomandă insistent ca serverele de failover să fie găzduite pe site-uri la distanță, deoarece o calamitate, cum ar fi un incendiu sau o inundație, distruge întregul hardware și software-ul fizic.
Storage Replica, o tehnologie care dublează volumele între servere pentru recuperarea în caz de dezastru , este inclusă în Windows Server 2016 și 2019. Stretch failover este o caracteristică tehnologică care permite clusterelor de failover să se întinde pe două locații.
Organizațiile pot replica datele în diferite centre prin extinderea clusterelor de failover. Dacă o tragedie lovește într-o locație, toate datele sunt păstrate pe serverele de failover din celelalte.
Replicarea unei baze de date
Potrivit Microsoft, WSFC a fost lansat pentru prima dată în Windows Server 2016 pentru a proteja serviciile „de misiune critică”, cum ar fi baza de date a serverului SQL și serverul de comunicații Microsoft Exchange.
Pentru replicarea bazei de date , alți furnizori furnizează tehnologie cluster de failover. De exemplu, MySQL Cluster are o metodă cardiacă care permite detectarea rapidă a defecțiunilor către alte noduri din cluster, adesea în mai puțin de o secundă literală, fără întreruperi ale serviciului clienților.
Bazele de date pot fi replicate pe site-uri îndepărtate folosind capacitatea de replicare geografică.
Beneficiile clusterelor de failover
Ideea clusterelor de failover este de a se asigura că utilizatorii se confruntă cu întreruperi minime în serviciu. Cu toate acestea, alte beneficii suplimentare ale clusterării cu failover sunt discutate mai jos.
- Disponibilitate crescută a resurselor: dacă un server inteligent eșuează, ceilalți din cluster preiau sarcina. Acest lucru economisește timp și informații esențiale.
- Alocarea strategică a resurselor: puteți distribui proiecte între noduri în orice mod ați alege. Acest lucru reduce cheltuielile generale, deoarece nu toate computerele sunt necesare pentru a executa toate proiectele simultan, oferindu-vă o modalitate de a vă folosi resursele mai liber.
- Putere de procesare crescută: mai multe mașini, mai multă putere.
- Scalabilitate mai mare: pe măsură ce baza de utilizatori și complexitatea rapoartelor se extind, la fel și resursele dvs.
- Management simplificat: Clustering facilitează gestionarea sistemelor semnificative sau care se schimbă rapid.
Limitări ale clusterizării de failover
Oricât de semnificativă este clusteringul de failover, aceasta se confruntă cu următoarele limitări.
- Configurații complexe: configurația de clustering de failover pentru Windows necesită să gestionați mai multe rețele și plăci de rețea simultan. Ca urmare, implementarea acestei metode este dificilă, mai ales pentru începători.
- Integrarea instrumentelor: clustering-ul Windows failover și Hyper-V trebuie să fie mai strâns integrate. Trebuie să ajustați fiecare dintre ele pentru a finaliza cu succes gruparea de failover.
- Interfață web: nu există nicio interfață web pentru a ajusta parametrii clusterului. Pentru a accesa caracteristica de manager de cluster, trebuie să vă conectați manual la un desktop la distanță.
Soluții de clustering de failover: furnizori de DNS gestionați
Lucrând împreună cu sistemele de clustering de failover, furnizorii de DNS gestionați redirecționează traficul către servere alternative sau centre de date în timpul evenimentelor de failover, asigurând acces neîntrerupt la serviciile dvs., astfel încât să obțineți o disponibilitate ridicată și să minimizați timpul de nefuncționare.
Top cinci furnizori de DNS gestionați:
- Cloudflare DNS
- Azure DNS
- Infoblox NIOS
- WPMU DEV
- Manager DNS
* Mai sus sunt primii cinci furnizori de software DNS gestionați de top din Raportul Grid din toamna 2023 al G2.

Modernizarea fiabilității
Clusteringul de failover a apărut ca o opțiune fiabilă și esențială pentru disponibilitate ridicată și toleranță la erori în infrastructurile IT actuale. Oferă operațiuni continue în ciuda defecțiunilor hardware sau a întreținerii programate prin răspândirea automată a sarcinilor de lucru și a resurselor pe numeroase noduri din rețea. Această tehnologie vă oferă o altă modalitate de a gestiona cel mai important aspect al afacerii dvs. – făcând experiența fiecărui client sigură și fericită.
Nici întărirea rezistenței sistemului tău nu strica!
Începeți cu un ghid pentru securitatea DNS pentru o strategie robustă de sistem.