
Dezmințirea a 3 mituri comune din spatele accesării cu crawlere a site-urilor, indexării și sitemapurilor XML
Publicat: 2018-03-07Mulți dintre noi cred în mod eronat că lansarea unui site web echipat cu o hartă de site XML va avea ca toate paginile să fie accesate cu crawlere și indexate automat.
În acest sens, se formează unele mituri și concepții greșite. Cele mai frecvente sunt:
- Google accesează automat toate site-urile și o face rapid.
- Când accesează cu crawlere un site web, Google urmărește toate linkurile și vizitează toate paginile sale și le include pe toate imediat în Index.
- Adăugarea unui sitemap XML este cea mai bună modalitate de a obține accesul cu crawlere și indexarea tuturor paginilor site-ului.
Din păcate, introducerea site-ului dvs. în indexul Google este o sarcină puțin mai complicată. Citiți mai departe pentru a vă face o idee mai bună despre cum funcționează procesul de accesare cu crawlere și indexare și ce rol joacă un sitemap XML în acesta.
Înainte de a dezvălui miturile menționate mai sus, să învățăm câteva noțiuni esențiale de SEO:
Crawling -ul este o activitate implementată de motoarele de căutare pentru a urmări și a aduna URL-uri de pe tot web-ul.
Indexarea este procesul care urmează accesării cu crawlere. Practic, este vorba despre analizarea și stocarea datelor Web care sunt utilizate ulterior la difuzarea rezultatelor pentru interogările motoarelor de căutare. Indexul motorului de căutare este locul în care toate datele Web colectate sunt stocate pentru utilizare ulterioară.
Clasamentul cu crawlere este valoarea pe care Google o atribuie site-ului dvs. și paginilor acestuia. Încă nu se știe cum este calculată această valoare de către motorul de căutare. Google a confirmat de mai multe ori că frecvența de indexare nu este legată de clasare, deci nu există o corelație directă între o autoritate de clasare a site-urilor web și rangul de accesare cu crawlere.
Site-urile web de știri, site-urile cu conținut valoros și site-urile care sunt actualizate în mod regulat au șanse mai mari de a fi accesate cu crawlere în mod regulat.
Bugetul de crawling este o cantitate de resurse de crawling pe care motorul de căutare o alocă unui site web. De obicei, Google calculează această sumă pe baza rangului de accesare cu crawlere a site-ului dvs.
Adâncimea accesului cu crawlere este o măsură în care Google analizează un nivel de site web atunci când îl explorează.
Prioritatea de accesare cu crawlere este un număr ordinal atribuit unei pagini de site care indică importanța acesteia în legătură cu accesarea cu crawlere.
Acum, cunoscând toate elementele de bază ale procesului, haideți să distrugem acele 3 mituri din spatele sitemap-urilor XML, a accesării cu crawlere și a indexării!
Cuprins
- Mitul 1. Google accesează automat toate site-urile și o face rapid.
- Concluzii
- Mitul 2. Adăugarea unui sitemap XML este cea mai bună modalitate de a obține accesul cu crawlere și indexarea tuturor paginilor site-ului.
- Concluzii
- Mitul 3. Un sitemap XML poate rezolva toate problemele de crawling și indexare.
- Concluzii
Mitul 1. Google accesează automat toate site-urile și o face rapid.
Google susține că atunci când vine vorba de colectarea datelor web, este agil și flexibil.
Dar adevărul să fie spus, pentru că în acest moment există trilioane de pagini pe Web, din punct de vedere tehnic, motorul de căutare nu le poate accesa rapid pe toate.
Selectarea site-urilor web pentru care să se aloce bugetul de accesare cu crawlere
Algoritmul inteligent Google (aka Crawl Budget) distribuie resursele motorului de căutare și decide ce site-uri merită accesate cu crawlere și care nu.
De obicei, Google acordă prioritate site-urilor web de încredere care corespund cerințelor stabilite și servesc drept bază pentru definirea modului în care alte site-uri se potrivesc.
Deci, dacă aveți un site web tocmai ieșit din cuptor sau un site web cu conținut răzuit, duplicat sau subțire, șansele ca acesta să fie accesat corect cu crawlere sunt destul de mici.
Factorii importanți care pot influența și alocarea bugetului de crawling sunt:
- dimensiunea site-ului web,
- starea sa generală (acest set de valori este determinat de numărul de erori pe care le puteți avea pe fiecare pagină),
- și numărul de legături interne și interne.
Pentru a vă crește șansele de a obține un buget de accesare cu crawlere, asigurați-vă că site-ul dvs. îndeplinește toate cerințele Google menționate mai sus, precum și optimizați eficiența accesării cu crawlere (consultați secțiunea următoare din articol).
Prezicerea programului de accesare cu crawlere
Google nu își anunță planurile de accesare cu crawlere a adreselor URL web. De asemenea, este greu de ghicit periodicitatea cu care motorul de căutare vizitează unele site-uri.
Este posibil ca pentru un site să efectueze accesări cu crawlere cel puțin o dată pe zi, în timp ce pentru altul să fie vizitat o dată pe lună sau chiar mai rar.
- Periodicitatea accesărilor cu crawlere depinde de:
- calitatea conținutului site-ului,
- noutatea și relevanța informațiilor pe care le oferă un site web,
- și cât de importante sau populare consideră motorul de căutare adresele URL ale site-urilor.
Luând în considerare acești factori, puteți încerca să preziceți cât de des vă poate vizita Google site-ul web.
Rolul linkurilor externe/interne și al sitemap-urilor XML
Ca căi, Googlebots folosesc linkuri care conectează paginile site-ului și site-ul web între ele. Astfel, motorul de căutare ajunge la trilioane de pagini interconectate care există pe Web.
Motorul de căutare poate începe să scaneze site-ul dvs. din orice pagină, nu neapărat din cea de acasă. Selectarea punctului de intrare în accesare cu crawlere depinde de sursa unei legături de intrare. Să presupunem că unele dintre paginile dvs. de produse au o mulțime de link-uri care provin de la diferite site-uri web. Google conectează punctele și vizitează astfel de pagini populare în primul rând.
O hartă de site XML este un instrument excelent pentru a construi o structură de site bine gândită. În plus, poate face procesul de accesare cu crawlere a site-ului mai direcționat și mai inteligent.
Practic, harta site-ului este un hub cu toate link-urile site-ului. Fiecare link inclus în acesta poate fi echipat cu câteva informații suplimentare: data ultimei actualizări, frecvența actualizării, relația sa cu alte URL-uri de pe site etc.
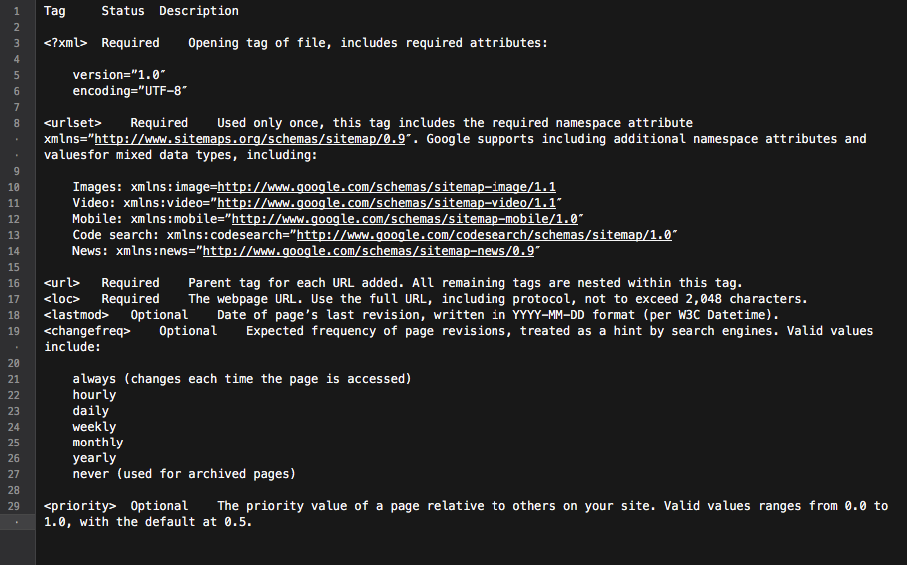 Toate acestea le oferă Googlebots o foaie de parcurs detaliată pentru accesarea cu crawlere a site-ului web și face ca accesarea cu crawlere să fie mai informată. De asemenea, toate motoarele de căutare principale acordă prioritate URL-urilor care sunt listate într-o hartă a site-ului.
Toate acestea le oferă Googlebots o foaie de parcurs detaliată pentru accesarea cu crawlere a site-ului web și face ca accesarea cu crawlere să fie mai informată. De asemenea, toate motoarele de căutare principale acordă prioritate URL-urilor care sunt listate într-o hartă a site-ului.
În concluzie, pentru a obține paginile site-ului dvs. pe radarul Googlebot, trebuie să construiți un site web cu conținut grozav și să optimizați structura internă de legături.
Concluzii
• Google nu accesează automat cu crawlere toate site-urile dvs. web.
• Periodicitatea accesării cu crawlere a site-ului depinde de cât de importante sau cât de populare sunt site-ul și paginile acestuia.
• Actualizarea conținutului face ca Google să viziteze mai des un site web.
• Este puțin probabil ca site-urile web care nu corespund cerințelor motorului de căutare să fie accesate cu crawlere corect.
• Site-urile web și paginile site-urilor care nu au link-uri interne/externe sunt de obicei ignorate de roboții motoarelor de căutare.
• Adăugarea unui sitemap XML poate îmbunătăți procesul de accesare cu crawlere a site-ului web și îl poate face mai inteligent.
Mitul 2. Adăugarea unui sitemap XML este cea mai bună modalitate de a obține accesul cu crawlere și indexarea tuturor paginilor site-ului.
Fiecare proprietar de site dorește ca Googlebot să viziteze toate paginile importante ale site-ului (cu excepția celor ascunse de indexare), precum și să exploreze instantaneu conținut nou și actualizat.
Cu toate acestea, motorul de căutare are propria sa viziune asupra priorităților de accesare cu crawlere a site-ului.
Când vine vorba de verificarea unui site web și a conținutului acestuia, Google folosește un set de algoritmi numit buget de accesare cu crawlere. Practic, permite motorului de căutare să scaneze paginile site-ului, utilizând în același timp cu inteligență propriile resurse.
Verificarea unui buget de accesare cu crawlere a site-ului
Este destul de ușor să vă dați seama cum este accesat cu crawlere site-ul dvs. și dacă aveți probleme legate de bugetul de accesare cu crawlere.
Trebuie doar să:
- numărați numărul de pagini de pe site-ul dvs. și din harta site-ului dvs. XML,
- accesați Google Search Console, accesați secțiunea Crawl -> Crawl Statistics și verificați câte pagini sunt accesate cu crawlere pe site-ul dvs. zilnic,
- împărțiți numărul total de pagini ale site-ului dvs. la numărul de pagini accesate cu crawlere pe zi.
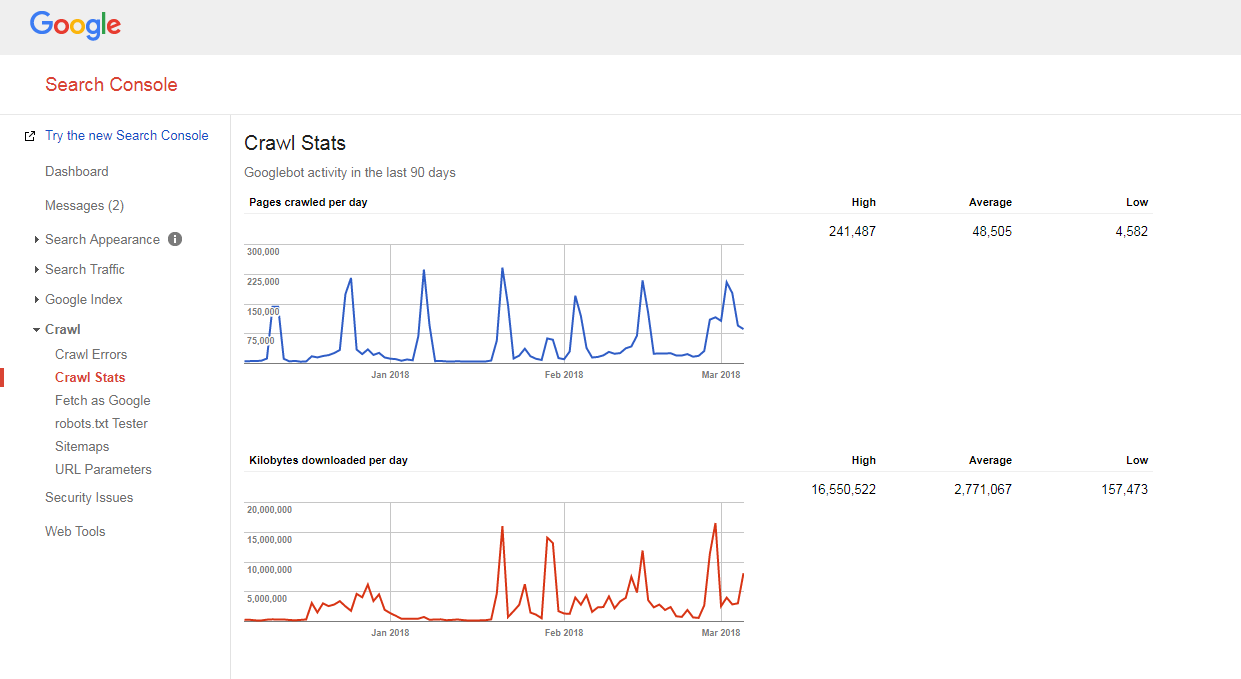 Dacă numărul pe care îl aveți este mai mare de 10 (există de 10 ori mai multe pagini pe site-ul dvs. decât ceea ce Google accesează cu crawlere zilnic), avem vești proaste pentru dvs.: site-ul dvs. are probleme de accesare cu crawlere.
Dacă numărul pe care îl aveți este mai mare de 10 (există de 10 ori mai multe pagini pe site-ul dvs. decât ceea ce Google accesează cu crawlere zilnic), avem vești proaste pentru dvs.: site-ul dvs. are probleme de accesare cu crawlere.
Dar înainte de a învăța cum să le remediați, trebuie să înțelegeți o altă noțiune, adică...
Adâncime de târăre
Profunzimea accesării cu crawlere este măsura în care Google continuă să exploreze un site web până la un anumit nivel.
În general, pagina de pornire este considerată la nivelul 1, o pagină care se află la 1 clic distanță este nivelul 2 etc.
Paginile de nivel profund au un Pagerank mai mic (sau nu îl au deloc) și sunt mai puțin probabil să fie accesate cu crawlere de Googlebot. De obicei, motorul de căutare nu caută mai mult decât nivelul 4.
În scenariul ideal, o anumită pagină ar trebui să fie la 1-4 clicuri distanță de pagina de pornire sau de categoriile principale de site. Cu cât calea către acea pagină este mai lungă, cu atât mai multe resurse trebuie să aloce motoarele de căutare pentru a ajunge la ea.
Dacă sunteți pe un site web, Google estimează că calea este mult prea lungă, se oprește accesarea cu crawlere.
Optimizarea adâncimii de accesare cu crawlere și a bugetului
Pentru a preveni încetinirea ritmului Googlebot, pentru a optimiza bugetul și profunzimea accesării cu crawlere a site-ului, trebuie să:

- remediați toate erorile 404, JS și alte pagini;
O cantitate excesivă de erori de pagină poate încetini semnificativ viteza crawler-ului Google. Pentru a găsi toate erorile principale ale site-ului, conectați-vă la panoul Instrumente pentru webmasteri Google (Bing, Yandex) și urmați toate instrucțiunile oferite aici.
- optimiza paginarea;
În cazul în care aveți liste de paginare prea lungi sau schema dvs. de paginare nu vă permite să faceți clic mai mult de câteva pagini în jos pe listă, este posibil ca crawler-ul motorului de căutare să înceteze să sape un astfel de morman de pagini.
De asemenea, dacă există puține articole pe o astfel de pagină, aceasta poate fi considerată un conținut subțire și nu va fi accesată cu crawlere.
- verifica filtrele de navigare;
Unele scheme de navigare pot veni cu mai multe filtre care generează pagini noi (de exemplu, pagini filtrate prin navigare stratificată). Deși astfel de pagini pot avea un potențial de trafic organic, ele pot crea, de asemenea, încărcare nedorită asupra crawlerelor motoarelor de căutare.
Cel mai bun mod de a rezolva acest lucru este limitarea legăturilor sistematice către listele filtrate. În mod ideal, ar trebui să utilizați maximum 1-2 filtre. De exemplu, dacă aveți un magazin cu 3 filtre LN (culoare/dimensiune/gen), ar trebui să permiteți combinarea sistematică a doar 2 filtre (de exemplu, culoare-mărime, gen-mărime). În cazul în care trebuie să adăugați combinații de mai multe filtre, ar trebui să adăugați manual link-uri către acestea.
- Optimizați parametrii de urmărire în adrese URL;
Diferiți parametri de urmărire a adreselor URL (de exemplu, „?source=thispage”) pot crea capcane pentru crawler-uri, deoarece generează o cantitate masivă de adrese URL noi. Această problemă este tipică pentru paginile cu „produse similare” sau „povestiri conexe”, în care acești parametri sunt utilizați pentru a urmări comportamentul utilizatorilor.
Pentru a optimiza eficiența accesării cu crawlere în acest caz, se recomandă să transmiteți informațiile de urmărire în spatele unui „#” la sfârșitul adresei URL. În acest fel, o astfel de adresă URL va rămâne neschimbată. În plus, este, de asemenea, posibil să redirecționați adrese URL cu parametri de urmărire către aceleași adrese URL, dar fără urmărire.
- eliminați redirecționările 301 excesive;
Să presupunem că aveți o mare parte de adrese URL la care sunt legate fără o bară oblică. Când botul motorului de căutare vizitează astfel de pagini, este redirecționat către versiunea cu o bară oblică.
Astfel, botul trebuie să facă de două ori mai mult decât ar trebui și, în cele din urmă, poate renunța și poate opri crawlerea. Pentru a evita acest lucru, încercați să actualizați toate linkurile din site-ul dvs. ori de câte ori schimbați adresele URL.
Prioritate de accesare cu crawlere
După cum s-a spus mai sus, Google acordă prioritate site-urilor web pe care să le acceseze cu crawlere. Deci nu este de mirare că face același lucru cu paginile dintr-un site web accesat cu crawlere.
Pentru majoritatea site-urilor web, pagina cu cea mai mare prioritate de accesare cu crawlere este pagina de pornire.
Cu toate acestea, după cum s-a spus anterior, în unele cazuri aceasta poate fi și cea mai populară categorie sau cea mai vizitată pagină de produs. Pentru a găsi paginile care primesc un număr mai mare de accesări cu crawlere de către Googlebot, trebuie doar să vă uitați la jurnalele de server.
Deși Google nu anunță oficial că factorii care pot influența prioritatea de accesare cu crawlere a unei pagini de site sunt:
- includerea într-un sitemap XML (și adăugați etichetele Priority* pentru cele mai importante pagini),
- numărul de link-uri de intrare,
- numărul de link-uri interne,
- popularitatea paginii (număr de vizite),
- PageRank.
Dar chiar și după ce ați deschis calea pentru ca roboții motoarelor de căutare să vă acceseze cu crawlere site-ul, ei pot să-l ignore. Citiți mai departe pentru a afla de ce.
Pentru a înțelege mai bine cum este prioritatea accesului cu crawlere, urmăriți această conferință virtuală a lui Gary Illyes.
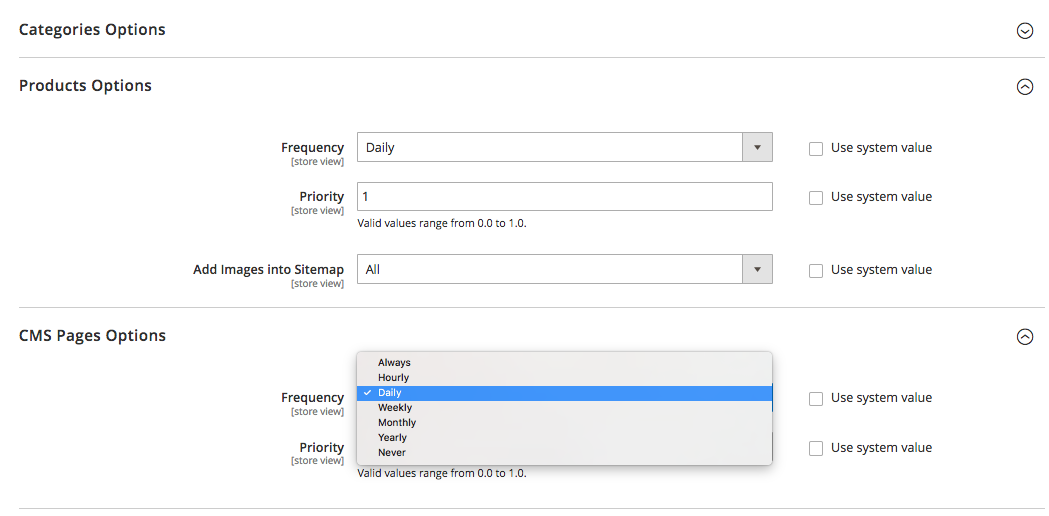
Vorbind despre etichetele Priority dintr-un sitemap XML, acestea pot fi adăugate fie manual, fie cu ajutorul funcționalității încorporate a platformei pe care se bazează site-ul tău. De asemenea, unele platforme acceptă extensii/aplicații de sitemap XML de la terțe părți care simplifică procesul.
Folosind eticheta XML Sitemap Priority, puteți atribui următoarele valori diferitelor categorii de pagini de site:
- 0.0-0.3 la pagini de utilitate, conținut învechit și orice pagini de importanță minoră,
- 0,4-0,7 la articolele de blog, întrebări frecvente și pagini cu cunoștințe, pagini de categorii și subcategorii de importanță secundară și
- 0.8-1.0 la categoriile principale de site-uri, paginile de destinație cheie și pagina de pornire.
Concluzii
• Google are propria sa viziune asupra priorităților procesului de crawling.
• O pagină care ar trebui să intre în Indexul motorului de căutare ar trebui să fie la 1-4 clicuri distanță de pagina principală, categoriile principale ale site-ului sau cele mai populare pagini ale site-ului.
• Pentru a împiedica Googlebot să încetinească și să optimizeze bugetul de accesare cu crawlere a site-ului și profunzimea accesării cu crawlere, ar trebui să găsiți și să remediați erorile 404, JS și alte pagini, să optimizați paginarea site-ului și filtrele de navigare, să eliminați redirecționările 301 excesive și să optimizați parametrii de urmărire în adrese URL.
• Pentru a spori prioritatea accesării cu crawlere a paginilor importante ale site-ului, asigurați-vă că acestea sunt incluse într-un sitemap XML (cu etichete Priority) și sunt bine legate cu alte pagini ale site-ului, au link-uri care provin de la alte site-uri web relevante și autorizate.
Mitul 3. Un sitemap XML poate rezolva toate problemele de crawling și indexare.
Deși este un instrument de comunicare bun care alertează Google despre adresele URL ale site-ului dvs. și despre modalitățile de a ajunge la ele, un sitemap XML nu oferă nicio garanție că site-ul dvs. va fi vizitat de roboții motoarelor de căutare (pentru a nu spune nimic despre includerea tuturor paginilor site-ului în Index) .
De asemenea, ar trebui să înțelegeți că sitemapurile nu vă vor ajuta să vă îmbunătățiți clasarea site-ului. Chiar dacă o pagină este accesată cu crawlere și inclusă în indexul motorului de căutare, performanța sa de clasare depinde de o mulțime de alți factori (linkuri interne și externe, conținut, calitatea site-ului etc.).
Cu toate acestea, atunci când este utilizat corect, un sitemap XML poate îmbunătăți semnificativ eficiența accesării cu crawlere a site-ului. Mai jos sunt câteva sfaturi despre cum să maximizați potențialul SEO al acestui instrument.
Fii consistent
Când creați un sitemap, rețineți că acesta va fi folosit ca foaie de parcurs pentru crawlerele Google. Prin urmare, este important să nu induceți în eroare motorul de căutare furnizând direcții greșite.
De exemplu, puteți include ocazional în harta site-ului dvs. XML câteva pagini de utilitate (pagini Contactați-ne sau TOS, pagini pentru autentificare, pagina de restabilire a parolei pierdute, pagini pentru partajarea conținutului etc.).
Aceste pagini sunt de obicei ascunse pentru indexare cu metaetichete noindex robots sau interzise în fișierul robots.txt.
Așadar, includerea lor într-o hartă XML a site-ului nu va face decât să încurce Googlebots, ceea ce poate influența negativ procesul de colectare a informațiilor despre site-ul dvs.
Actualizați regulat
Majoritatea site-urilor web de pe Web se schimbă aproape în fiecare zi. În special site-ul de comerț electronic cu produse și categorii care se amestecă în mod regulat pe și în afara site-ului.
Pentru a menține Google bine informat, trebuie să păstrați sitemap-ul XML actualizat.
Unele platforme (Magento, Shopify) fie au funcționalități încorporate care vă permit să actualizați periodic hărțile de site XML, fie să accepte unele soluții terțe care sunt capabile să îndeplinească această sarcină.
De exemplu, în Magento 2, puteți periodic periodicitatea ciclurilor de actualizare a sitemapului. Când îl definiți în setările de configurare ale platformei, semnalați crawler-ului că paginile site-ului dvs. sunt actualizate la un anumit interval de timp (o dată, săptămânal, lunar), iar site-ul dvs. are nevoie de o altă accesare cu crawlere.
Faceți clic aici pentru a afla mai multe despre el.
Dar rețineți că, deși setarea priorității și frecvenței pentru actualizările sitemapului este de ajutor, este posibil ca acestea să nu ajungă din urmă cu schimbările reale și să nu ofere uneori o imagine adevărată.
De aceea, asigurați-vă că sitemap-ul dvs. reflectă toate modificările efectuate recent.
 Segmentați conținutul site-ului și setați prioritățile potrivite de accesare cu crawlere
Segmentați conținutul site-ului și setați prioritățile potrivite de accesare cu crawlere
Google lucrează din greu pentru a măsura calitatea generală a site-ului și a afișa doar cele mai bune și mai relevante site-uri web.
Dar, așa cum se întâmplă adesea, nu toate site-urile sunt create egale și capabile să ofere valoare reală.
Să zicem, un site web poate fi format din 1.000 de pagini, iar doar 50 dintre ele au nota „A”. Celelalte sunt fie pur funcționale, au conținut învechit, fie nu există deloc.
Dacă Google începe să exploreze un astfel de site web, probabil că va decide că este destul de gunoi din cauza procentului mare de pagini cu valoare redusă, spam sau învechite.
De aceea, atunci când creați un sitemap XML, se recomandă să segmentați conținutul site-ului și să ghidați roboții motoarelor de căutare numai către zonele demne ale site-ului.
Și după cum vă amintiți, etichetele Priority, atribuite celor mai importante pagini de site din harta dvs. XML sitemap, vă pot fi, de asemenea, de mare ajutor.
Concluzii
• Când creați un sitemap, asigurați-vă că nu includeți pagini ascunse de indexare cu metaetichete noindex robots sau interzise în fișierul robots.txt.
• Actualizați hărțile de site XML (manual sau automat) imediat după ce faceți modificări în structura și conținutul site-ului web.
• Segmentați conținutul site-ului dvs. pentru a include numai pagini cu nota „A” în harta site-ului.
• Setați prioritatea de accesare cu crawlere pentru diferite tipuri de pagini.
Practic asta este.
Ai ceva de spus pe tema? Simțiți-vă liber să vă împărtășiți părerea despre accesarea cu crawlere, indexare sau sitemap-uri în secțiunea de comentarii de mai jos.