
Não perca as notícias do setor de mídia social de amanhã
Publicados: 2023-04-01Conforme prometido pelo chefe do Twitter, Elon Musk, no início deste mês, hoje, o Twitter publicou seu código de algoritmo de recomendação no GitHub para todos verem, além de publicar uma nova visão geral de como funciona o algoritmo de recomendação de tweets, fornecendo novos insights sobre o que dita a ordem. em que os tweets são exibidos.
Conforme explicado pelo Twitter:
“ No GitHub , você encontrará dois novos repositórios ( main repo , ml repo ) contendo o código-fonte de muitas partes do Twitter, incluindo nosso algoritmo de recomendações, que controla os Tweets que você vê na linha do tempo Para você. Para este lançamento, buscamos o maior grau de transparência possível, excluindo qualquer código que comprometa a segurança e a privacidade do usuário ou a capacidade de proteger nossa plataforma de malfeitores, inclusive minando nossos esforços no combate à exploração e manipulação sexual infantil.”
Também é importante observar que o Twitter não tem as informações de ponderação conectadas a cada elemento - ou seja, quanta ênfase cada fator recebe na condução dos resultados de saída finais.
Portanto, não são todos os detalhes, mas fornecem uma visão de alto nível sobre como os algoritmos do Twitter funcionam, enquanto o Twitter também fornece uma explicação mais leiga do sistema, a fim de ajudar as pessoas a entender como ele decide o que você verá em sua linha do tempo a cada vez que você abrir o aplicativo.
Conforme Twitter:
“ A base das recomendações do Twitter é um conjunto de modelos e recursos principais que extraem informações latentes de dados de tweets, usuários e engajamento. Esses modelos visam responder questões importantes sobre a rede Twitter, como: “Qual é a probabilidade de você interagir com outro usuário no futuro?” ou “Quais são as comunidades no Twitter e quais são os Tweets em alta dentro delas?”Responder a essas perguntas com precisão permite que o Twitter forneça recomendações mais relevantes.”
Esse último elemento é importante e se alinha com o que Ryan Broderick, do Garbage Day, descobriu em seus experimentos ao testar o que agora ganha força via tweet.
Conforme resumido por Broderick:
“O Twitter está usando subreddits invisíveis via Tópicos para organizar tweets algoritmicamente. Como a página Para você não é mais cronológica, os tweets virais não podem ser tão oportunos quanto costumavam ser. Eles têm que ser meio perenes. Ajuda se eles estiverem comentando sobre algo que já está se tornando viral. E ajuda muito se você postar um tópico, responder a si mesmo ou criar algum tipo de discussão nas respostas. Também parece haver uma ênfase maior no vídeo agora. ”
Acontece que Ryan estava correto - o Twitter agora está procurando promover mais tweets no feed 'Para você' com base no engajamento tópico, que o Twitter define no nível da conta, filtrando certas contas em categorias de tópicos e usando isso como um guia para categorizar o tópico provável de cada um de seus tweets.
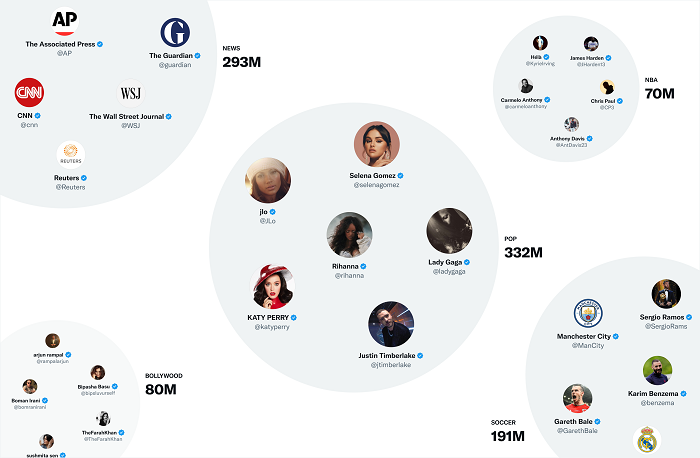
Conforme Twitter:
“ Um dos espaços de incorporação mais úteis do Twitter é o SimClusters . Os SimClusters descobrem comunidades ancoradas por um grupo de usuários influentes usando um algoritmo de fatoração de matriz personalizado . São 145 mil comunidades, que são atualizadas a cada três semanas. As comunidades variam em tamanho de alguns milhares de usuários para grupos de amigos individuais a centenas de milhões de usuários para notícias ou cultura pop. Quanto mais os usuários de uma comunidade gostarem de um Tweet, mais esse Tweet será associado a essa comunidade.”

A imagem acima mostra algumas das maiores 'comunidades' do Twitter, ou coleções de tópicos baseadas na filtragem algorítmica do Twitter.
O Twitter diz que essa abordagem se tornou um fator chave para decidir quais tweets 'fora da rede' inserir em seu feed 'Para você' ou quais tweets mostrar a você de contas que você não segue. E com mais e mais dessas recomendações sendo inseridas nos feeds dos usuários, tornou-se um grande impulsionador da exposição do tweet – embora isso mude novamente em breve, quando o Twitter restringir ainda mais as recomendações 'Para você' a apenas tweets de contas de assinantes pagantes.
Como isso afeta a experiência do Twitter é uma incógnita neste momento, mas transformará fundamentalmente o feed 'Para você', pelo menos, limitando o conjunto de tweets de origem que o Twitter pode extrair.
E se as celebridades, em particular, não pagarem ou pararem de twittar como resultado, esse impacto pode ser significativo.
Esta é a revelação mais significativa da visão geral algorítmica do Twitter, embora existam várias outras notas e pontos interessantes incluídos na documentação:
- Para cada sessão de usuário, o Twitter extrai cerca de 1.500 tweets que acredita serem potencialmente de interesse para cada pessoa, antes de classificá-los no feed 'Para você'
- Atualmente, a linha do tempo Para você consiste em 50% de tweets dentro da rede (pessoas que você segue) e 50% de tweets fora da rede, em média
- O Twitter também prevê a probabilidade de engajamento entre dois usuários. 'Quanto maior a pontuação do Real Graph entre você e o autor do Tweet, mais tweets dele incluiremos'
- Outro fator são os tweets com os quais as pessoas que você segue estão se envolvendo – o que não é uma revelação, apenas um ponto de observação
- A classificação do Tweet é conduzida por meio de uma 'rede neural de parâmetros de aproximadamente 48 milhões que é continuamente treinada nas interações do Tweet para otimizar o envolvimento positivo (por exemplo, curtidas, retuítes e respostas)'. Não há nenhuma nota, no entanto, sobre como o Twitter determina o engajamento positivo versus negativo neste contexto.
Isso fornece um contexto interessante sobre como o Twitter classifica os tweets e maximiza a exposição no feed principal 'Para você' - embora, novamente, isso mude em 15 de abril, quando o Twitter mudará para mostrar apenas tweets de usuários pagantes em suas recomendações 'Para você'.
O que, de certa forma, torna muito desse insight redundante - embora eu ache que, se a teoria de trabalho é que, eventualmente, a maioria dos usuários pagará, isso pode permanecer indicativo por algum tempo ainda.
Exceto, eles não vão.
Atualmente, menos de 1% dos usuários do Twitter estão pagando pelo Twitter Blue e, embora a decisão de remover os tiques azuis 'legados' e reverter o processo de classificação 'Para você' gere alguma aceitação adicional, parece improvável que torne o Twitter Blue uma consideração significativa para a grande maioria dos usuários do Twitter.
Eu acho que o outro elemento a considerar, a esse respeito, é que a grande maioria dos tweets vem de poucos usuários, com a maioria dos perfis do Twitter raramente tweetando a si mesmos. Talvez, então, o Twitter precise apenas de uma coleção menor de usuários para se inscrever no Blue, a fim de torná-lo um elemento mais significativo no ranking do tweet. Mas ainda parece improvável produzir melhores resultados ao destacar o conteúdo mais relevante de todo o aplicativo.
Independentemente disso, parece que o Twitter está avançando e, agora, os desenvolvedores externos têm mais informações sobre como o algoritmo do Twitter funciona, o que levará a uma nova enxurrada de ideias e dicas sobre como manipular o sistema.
A esperança do Twitter é que ele também o ajude a melhorar seus algoritmos rapidamente. Talvez isso aconteça também. Teremos que esperar para ver.