
Support Vector Machine (SVM) em aprendizado de máquina
Publicados: 2023-01-04O Support Vector Machine está entre os algoritmos de aprendizado de máquina mais populares. É eficiente e pode treinar em conjuntos de dados limitados. Mas o que é isso?
O que é uma Máquina de Vetores de Suporte (SVM)?
A máquina de vetores de suporte é um algoritmo de aprendizado de máquina que usa aprendizado supervisionado para criar um modelo para classificação binária. Isso é um bocado. Este artigo explicará o SVM e como ele se relaciona com o processamento de linguagem natural. Mas primeiro, vamos analisar como funciona uma máquina de vetores de suporte.
Como funciona o SVM?
Considere um problema de classificação simples em que temos dados com dois recursos, x e y, e uma saída – uma classificação que é vermelha ou azul. Podemos plotar um conjunto de dados imaginário que se parece com isso:
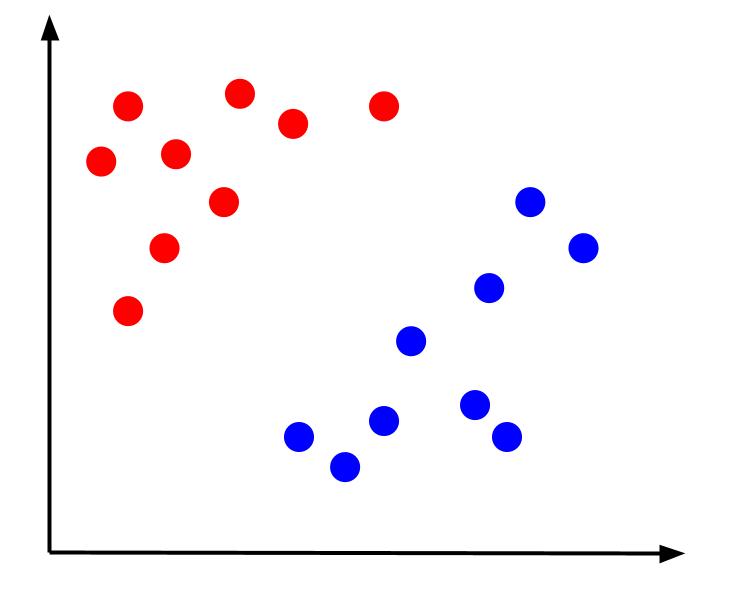
Dado dados como este, a tarefa seria criar um limite de decisão. Um limite de decisão é uma linha que separa as duas classes de nossos pontos de dados. Este é o mesmo conjunto de dados, mas com um limite de decisão:
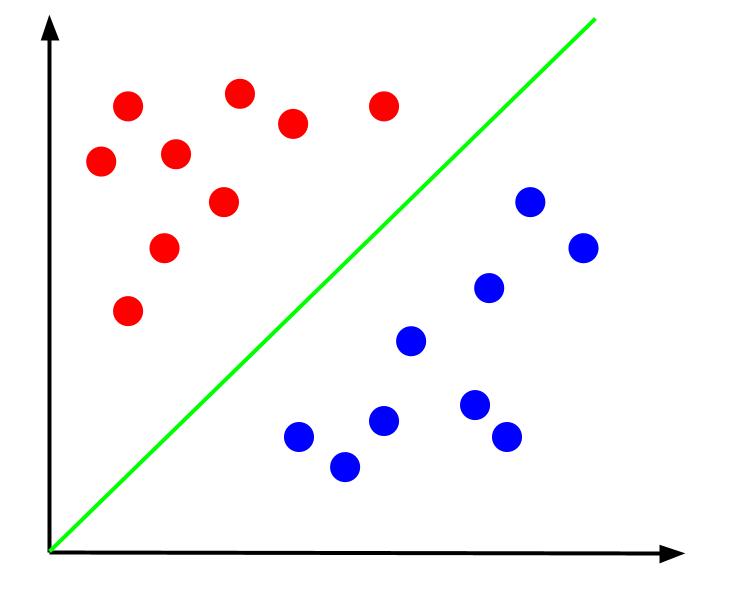
Com esse limite de decisão, podemos fazer previsões para qual classe um ponto de dados pertence, dado onde ele se encontra em relação ao limite de decisão. O algoritmo Support Vector Machine cria o melhor limite de decisão que será usado para classificar os pontos.
Mas o que queremos dizer com limite de melhor decisão?
Pode-se argumentar que o melhor limite de decisão é aquele que maximiza sua distância de qualquer um dos vetores de suporte. Os vetores de suporte são pontos de dados de qualquer classe mais próximos da classe oposta. Esses pontos de dados representam o maior risco de classificação incorreta devido à sua proximidade com a outra classe.
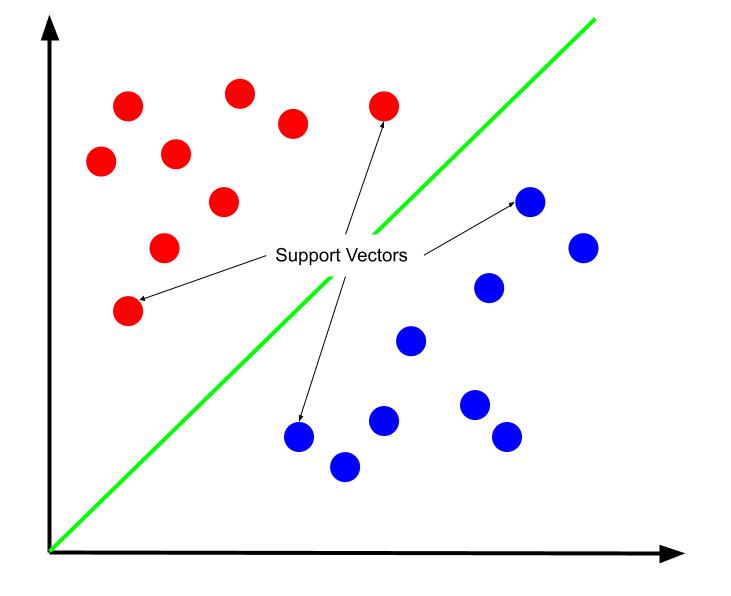
O treinamento de uma máquina de vetores de suporte, portanto, envolve tentar encontrar uma linha que maximize a margem entre os vetores de suporte.
Também é importante observar que, como o limite de decisão está posicionado em relação aos vetores de suporte, eles são os únicos determinantes da posição do limite de decisão. Os outros pontos de dados são, portanto, redundantes. E assim, o treinamento requer apenas os vetores de suporte.
Neste exemplo, o limite de decisão formado é uma linha reta. Isso ocorre apenas porque o conjunto de dados tem apenas dois recursos. Quando o conjunto de dados tem três recursos, o limite de decisão formado é um plano em vez de uma linha. E quando possui quatro ou mais recursos, o limite de decisão é conhecido como hiperplano.
Dados não linearmente separáveis
O exemplo acima considerou dados muito simples que, quando plotados, podem ser separados por um limite de decisão linear. Considere um caso diferente em que os dados são plotados da seguinte maneira:
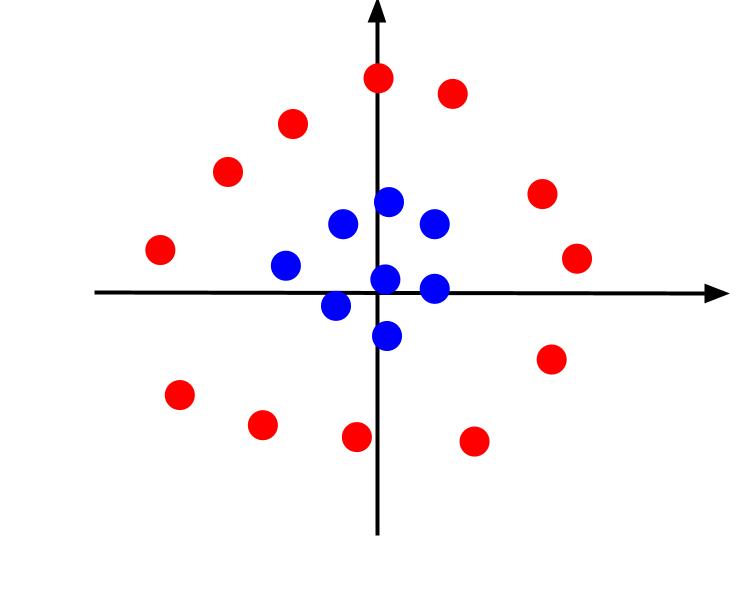
Nesse caso, é impossível separar os dados usando uma linha. Mas podemos criar outro recurso, z. E esta característica pode ser definida pela equação: z = x^2 + y^2. Podemos adicionar z como um terceiro eixo ao plano para torná-lo tridimensional.
Quando olhamos para o gráfico 3D de um ângulo tal que o eixo x é horizontal enquanto o eixo z é vertical, esta é a visão que obtemos algo como isto:
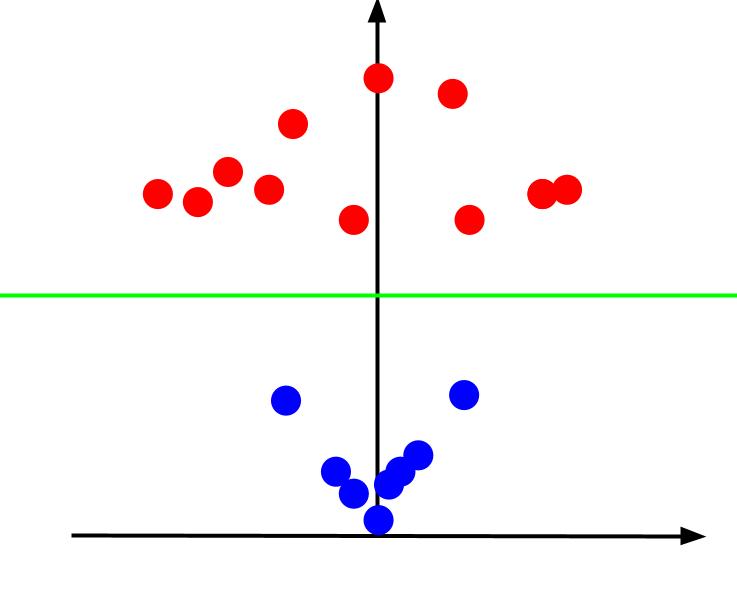
O valor z representa a distância que um ponto está da origem em relação aos outros pontos no antigo plano XY. Como resultado, os pontos azuis mais próximos da origem têm valores z baixos.
Embora os pontos vermelhos mais distantes da origem tenham valores z mais altos, plotá-los em relação aos seus valores z nos dá uma classificação clara que pode ser demarcada por um limite de decisão linear, conforme ilustrado.
Esta é uma ideia poderosa que é usada em Support Vector Machines. De forma mais geral, é a ideia de mapear as dimensões em um número maior de dimensões para que os pontos de dados possam ser separados por um limite linear. As funções responsáveis por isso são as funções do kernel. Existem muitas funções do kernel, como sigmóide, linear, não linear e RBF.
Para tornar o mapeamento desses recursos mais eficiente, o SVM usa um truque do kernel.
SVM em aprendizado de máquina
O Support Vector Machine é um dos muitos algoritmos usados no aprendizado de máquina ao lado de outros populares, como Árvores de Decisão e Redes Neurais. É favorecido porque funciona bem com menos dados do que outros algoritmos. É comumente usado para fazer o seguinte:
- Classificação de texto : classificação de dados de texto, como comentários e revisões em uma ou mais categorias
- Detecção de rosto : analisando imagens para detectar rostos para fazer coisas como adicionar filtros para realidade aumentada
- Classificação de imagens : As máquinas de vetores de suporte podem classificar imagens com eficiência em comparação com outras abordagens.
O problema de classificação de texto
A internet está cheia de muitos e muitos dados textuais. No entanto, muitos desses dados não são estruturados e não rotulados. Para melhor utilizar esses dados de texto e compreendê-los melhor, há a necessidade de classificação. Exemplos de momentos em que o texto é classificado incluem:
- Quando os tweets são categorizados em tópicos para que as pessoas possam seguir os tópicos que desejam
- Quando um e-mail é categorizado como Social, Promoções ou Spam
- Quando comentários são classificados como ofensivos ou obscenos em fóruns públicos
Como o SVM funciona com classificação de linguagem natural
O Support Vector Machine é usado para classificar o texto em texto que pertence a um tópico específico e texto que não pertence ao tópico. Isso é obtido convertendo e representando primeiro os dados de texto em um conjunto de dados com vários recursos.
Uma maneira de fazer isso é criar recursos para cada palavra no conjunto de dados. Então, para cada ponto de dados de texto, você registra o número de vezes que cada palavra ocorre. Portanto, suponha que palavras únicas estejam ocorrendo no conjunto de dados; você terá recursos no conjunto de dados.
Além disso, você fornecerá classificações para esses pontos de dados. Embora essas classificações sejam rotuladas por texto, a maioria das implementações de SVM espera rótulos numéricos.
Portanto, você terá que converter esses rótulos em números antes do treinamento. Uma vez que o conjunto de dados foi preparado, usando esses recursos como coordenadas, você pode usar um modelo SVM para classificar o texto.
Criando um SVM em Python
Para criar uma máquina de vetor de suporte (SVM) em Python, você pode usar a classe SVC da biblioteca sklearn.svm . Aqui está um exemplo de como você pode usar a classe SVC para construir um modelo SVM em Python:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) Neste exemplo, primeiro importamos a classe SVC da biblioteca sklearn.svm . Em seguida, carregamos o conjunto de dados e o dividimos em conjuntos de treinamento e teste.
Em seguida, criamos um modelo SVM instanciando um objeto SVC e especificando o parâmetro do kernel como 'linear'. Em seguida, treinamos o modelo nos dados de treinamento usando o método de fit e avaliamos o modelo nos dados de teste usando o método de score . O método score retorna a precisão do modelo, que imprimimos no console.
Você também pode especificar outros parâmetros para o objeto SVC , como o parâmetro C que controla a intensidade da regularização e o parâmetro gamma , que controla o coeficiente do kernel para determinados kernels.
Benefícios do SVM
Aqui está uma lista de alguns benefícios do uso de máquinas de vetores de suporte (SVMs):
- Eficiente : SVMs são geralmente eficientes para treinar, especialmente quando o número de amostras é grande.
- Robusto ao Ruído : SVMs são relativamente robustos ao ruído nos dados de treinamento enquanto tentam encontrar o classificador de margem máxima, que é menos sensível ao ruído do que outros classificadores.
- Memória eficiente: os SVMs exigem apenas que um subconjunto dos dados de treinamento esteja na memória a qualquer momento, tornando-os mais eficientes em termos de memória do que outros algoritmos.
- Eficaz em espaços de alta dimensão: os SVMs ainda podem ter um bom desempenho mesmo quando o número de recursos excede o número de amostras.
- Versatilidade : SVMs podem ser usados para tarefas de classificação e regressão e podem lidar com vários tipos de dados, incluindo dados lineares e não lineares.
Agora, vamos explorar alguns dos melhores recursos para aprender Support Vector Machine (SVM).

Recursos de aprendizagem
Uma introdução às máquinas de vetores de suporte
Este livro sobre Introdução ao Support Vector Machines apresenta de forma abrangente e gradual os métodos de aprendizado baseados em kernel.
| Visualização | produtos | Avaliação | Preço | |
|---|---|---|---|---|
 | Uma introdução para máquinas vetoriais de suporte e outros métodos de aprendizado baseados em kernel | $ 75,00 | Compre na Amazon |
Ele fornece uma base sólida na teoria das máquinas de vetores de suporte.
Aplicações de máquinas de vetores de suporte
Enquanto o primeiro livro enfocou a teoria de Support Vector Machines, este livro sobre Aplicações de Support Vector Machines enfoca suas aplicações práticas.
| Visualização | produtos | Avaliação | Preço | |
|---|---|---|---|---|
 | Aplicações de máquinas de vetores de suporte | $ 15,52 | Compre na Amazon |
Ele analisa como os SVMs são usados no processamento de imagens, detecção de padrões e visão computacional.
Support Vector Machines (Ciência da Informação e Estatística)
O objetivo deste livro sobre Support Vector Machines (Ciência da Informação e Estatística) é fornecer uma visão geral dos princípios por trás da eficácia das Support Vector Machines (SVMs) em várias aplicações.
| Visualização | produtos | Avaliação | Preço | |
|---|---|---|---|---|
 | Support Vector Machines (Ciência da Informação e Estatística) | $ 167,36 | Compre na Amazon |
Os autores destacam vários fatores que contribuem para o sucesso dos SVMs, incluindo sua capacidade de funcionar bem com um número limitado de parâmetros ajustáveis, sua resistência a vários tipos de erros e anomalias e seu desempenho computacional eficiente em comparação com outros métodos.
Aprendendo com Kernels
“Aprendendo com Kernels” é um livro que apresenta aos leitores o suporte a máquinas vetoriais (SVMs) e técnicas de kernel relacionadas.
| Visualização | produtos | Avaliação | Preço | |
|---|---|---|---|---|
 | Aprendendo com Kernels: Máquinas de Vetores de Suporte, Regularização, Otimização e Além (Adaptável… | $ 80,00 | Compre na Amazon |
Ele foi projetado para fornecer aos leitores uma compreensão básica da matemática e o conhecimento necessário para começar a usar algoritmos de kernel no aprendizado de máquina. O livro visa fornecer uma introdução completa, mas acessível, aos SVMs e aos métodos do kernel.
Dê suporte a máquinas vetoriais com o Sci-kit Learn
Este curso online Support Vector Machines with Sci-kit Learn da rede de projetos Coursera ensina como implementar um modelo SVM usando a popular biblioteca de aprendizado de máquina Sci-Kit Learn.

Além disso, você aprenderá a teoria por trás dos SVMs e determinará seus pontos fortes e limitações. O curso é de nível iniciante e requer cerca de 2,5 horas.
Suporte a máquinas vetoriais em Python: conceitos e código
Este curso online pago em Support Vector Machines em Python da Udemy tem até 6 horas de instrução em vídeo e vem com uma certificação.

Abrange SVMs e como eles podem ser implementados de forma sólida em Python. Além disso, abrange aplicações de negócios de Support Vector Machines.
Aprendizado de máquina e IA: Suporte a máquinas vetoriais em Python
Neste curso sobre Machine Learning e IA, você aprenderá como usar máquinas de vetores de suporte (SVMs) para várias aplicações práticas, incluindo reconhecimento de imagem, detecção de spam, diagnóstico médico e análise de regressão.

Você usará a linguagem de programação Python para implementar modelos de ML para esses aplicativos.
Palavras Finais
Neste artigo, aprendemos brevemente sobre a teoria por trás das Support Vector Machines. Aprendemos sobre sua aplicação em Machine Learning e Natural Language Processing.
Também vimos como é sua implementação usando scikit-learn . Além disso, falamos sobre as aplicações práticas e os benefícios das Support Vector Machines.
Embora este artigo seja apenas uma introdução, os recursos adicionais recomendam entrar em mais detalhes, explicando mais sobre Support Vector Machines. Por serem versáteis e eficientes, vale a pena entender os SVMs para crescer como cientista de dados e engenheiro de ML.
A seguir, você pode conferir os principais modelos de aprendizado de máquina.