
Como criar um DataFrame do Pandas [com exemplos]
Publicados: 2022-12-08Aprenda os fundamentos do trabalho com Pandas DataFrames: a estrutura básica de dados em pandas, uma poderosa biblioteca de manipulação de dados.
Se você gostaria de começar com a análise de dados em Python, pandas é uma das primeiras bibliotecas com as quais você deve aprender a trabalhar. Desde importar dados de várias fontes, como arquivos CSV e bancos de dados, até lidar com dados ausentes e analisá-los para obter insights - o pandas permite que você faça tudo o que foi dito acima.
Para começar a analisar dados com pandas, você deve entender a estrutura de dados fundamental em pandas: quadros de dados .
Neste tutorial, você aprenderá o básico dos dataframes do pandas e métodos comuns para criar dataframes. Você aprenderá como selecionar linhas e colunas do dataframe para recuperar subconjuntos de dados.
Por tudo isso e muito mais, vamos começar.
Instalando e Importando Pandas
Como o pandas é uma biblioteca de análise de dados de terceiros, você deve primeiro instalá-lo. É recomendável instalar pacotes externos em um ambiente virtual para seu projeto.
Se você usar a distribuição Anaconda do Python, poderá usar conda para gerenciamento de pacotes.
conda install pandasVocê também pode instalar pandas usando pip:
pip install pandasA biblioteca pandas requer NumPy como dependência. Portanto, se o NumPy ainda não estiver instalado, ele também será instalado durante o processo de instalação.
Depois de instalar o pandas, você pode importá-lo para o seu ambiente de trabalho. Em geral, os pandas são importados sob o alias pd :
import pandas as pdO que é um DataFrame em Pandas?

A estrutura de dados fundamental em pandas é o quadro de dados . Um quadro de dados é uma matriz bidimensional de dados com índice rotulado e colunas nomeadas . Cada coluna no quadro de dados chamada de série pandas, compartilha um índice comum.
Aqui está um exemplo de quadro de dados que criaremos do zero nos próximos minutos. Este quadro de dados contém dados sobre quanto seis alunos gastam em quatro semanas.

Os nomes dos alunos são os rótulos das linhas. E as colunas são nomeadas 'Week1' a 'Week4'. Observe que todas as colunas compartilham o mesmo conjunto de rótulos de linha, também chamado de índice .
Como criar um DataFrame Pandas
Existem várias maneiras de criar um quadro de dados do pandas. Neste tutorial, discutiremos os seguintes métodos:
- Criando um quadro de dados a partir de matrizes NumPy
- Criando um quadro de dados de um dicionário Python
- Criando um quadro de dados lendo em arquivos CSV
De matrizes NumPy
Vamos criar um quadro de dados a partir de um array NumPy.
Vamos criar a matriz de dados da forma (6,4) supondo que, em qualquer semana, cada aluno gaste algo entre US$ 0 e US$ 100. A função randint() do módulo random do NumPy retorna uma matriz de números inteiros aleatórios em um determinado intervalo, [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Para criar um quadro de dados pandas, você pode usar o construtor DataFrame e passar o array NumPy como o argumento de data , conforme mostrado:
students_df = pd.DataFrame(data=data) Agora podemos chamar a função interna type() para verificar o tipo de students_df . Vemos que é um objeto DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 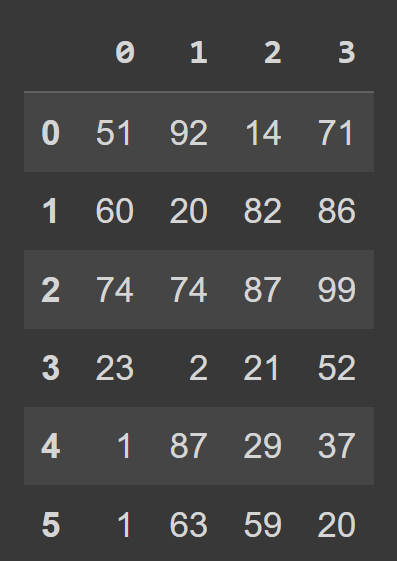
Vemos que, por padrão, temos indexação de intervalo que vai de 0 a numRows – 1, e os rótulos das colunas são 0, 1, 2, …, numCols -1. No entanto, isso reduz a legibilidade. Isso ajudará a adicionar nomes de coluna descritivos e rótulos de linha ao quadro de dados.
Vamos criar duas listas: uma para armazenar os nomes dos alunos e outra para armazenar os rótulos das colunas.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] Ao chamar o construtor DataFrame , você pode definir o index e as columns para as listas de rótulos de linha e rótulos de coluna a serem usados, respectivamente.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Agora temos o quadro de dados students_df com rótulos descritivos de linha e coluna.
print(students_df) 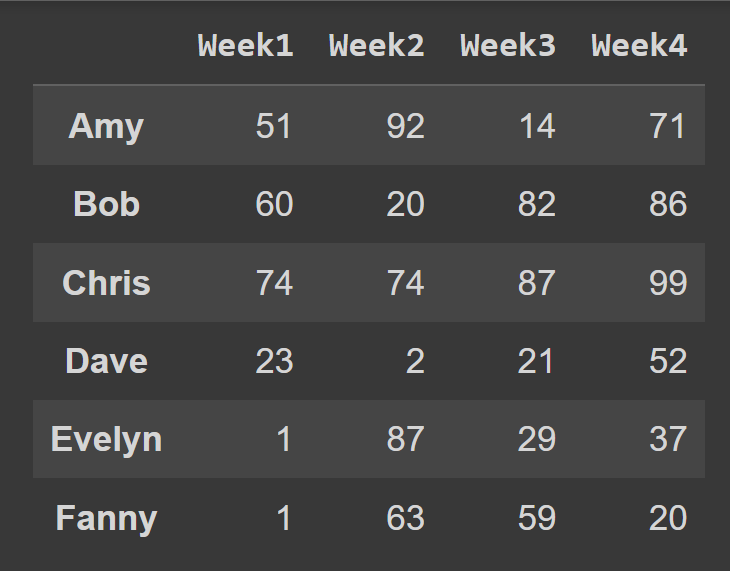
Para obter algumas informações básicas sobre o quadro de dados, como valores ausentes e tipos de dados, você pode chamar o método info() no objeto do quadro de dados.
students_df.info() 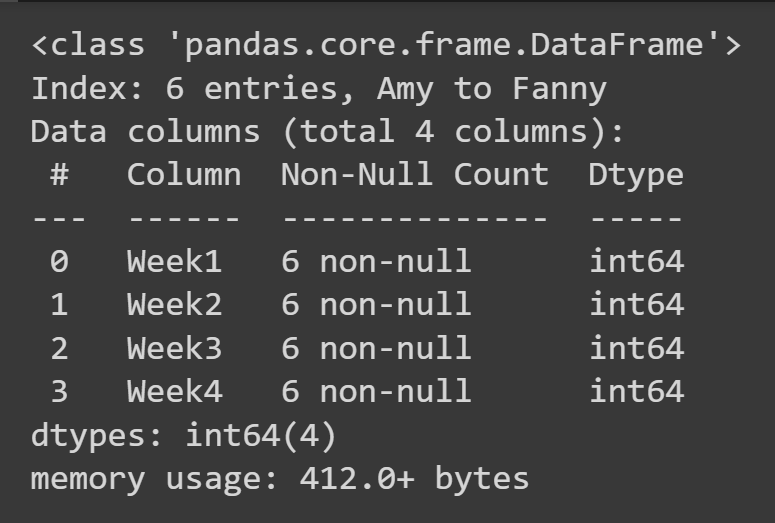
De um dicionário Python
Você também pode criar um quadro de dados pandas a partir de um dicionário Python.
Aqui, data_dict é o dicionário que contém os dados do aluno:
- Os nomes dos alunos são as chaves.
- Cada valor é uma lista de quanto cada aluno gasta da primeira à quarta semana.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Para criar um quadro de dados a partir de um dicionário Python, use from_dict , conforme mostrado abaixo. O primeiro argumento corresponde ao dicionário que contém os dados ( data_dict ). Por padrão, as chaves são usadas como os nomes das colunas do quadro de dados. Como gostaríamos de definir as chaves como rótulos de linha , defina orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 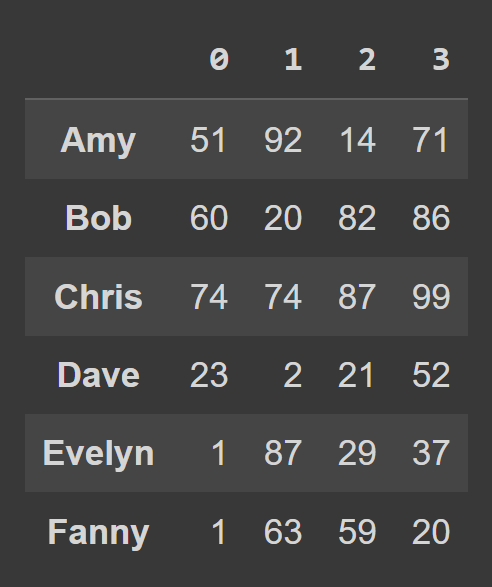
Para alterar os nomes das colunas para o número da semana, definimos as colunas para a lista de cols :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 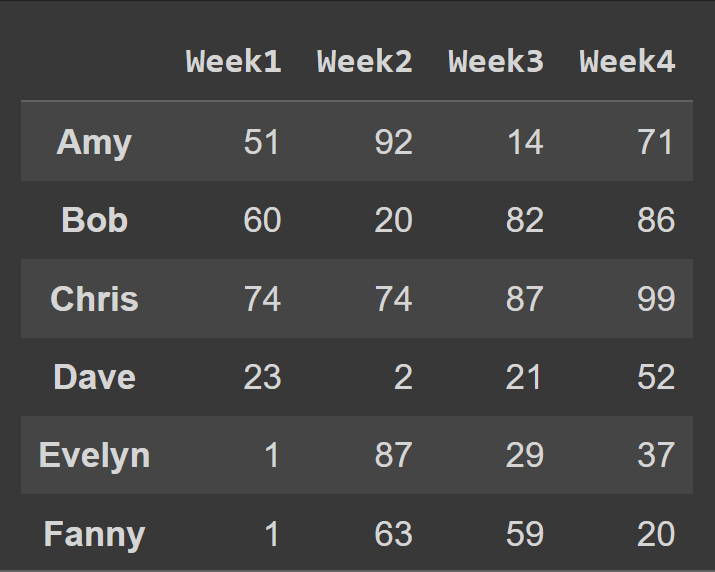
Leia em um arquivo CSV em um Pandas DataFrame
Suponha que os dados do aluno estejam disponíveis em um arquivo CSV. Você pode usar a função read_csv() para ler os dados do arquivo em um quadro de dados do pandas. pd.read_csv('file-path') é a sintaxe geral, onde file-path é o caminho para o arquivo CSV. Podemos definir o parâmetro de names para a lista de nomes de coluna a serem usados.
students_df = pd.read_csv('/content/students.csv',names=cols)Agora que sabemos como criar um quadro de dados, vamos aprender como selecionar linhas e colunas.
Selecione colunas de um Pandas DataFrame
Existem vários métodos internos que você pode usar para selecionar linhas e colunas de um quadro de dados. Este tutorial abordará as formas mais comuns de selecionar colunas, linhas e linhas e colunas de um quadro de dados.
Selecionando uma única coluna
Para selecionar uma única coluna, você pode usar df_name[col_name] onde col_name é a string que indica o nome da coluna.
Aqui, selecionamos apenas a coluna 'Week1'.
week1_df = students_df['Week1'] print(week1_df) 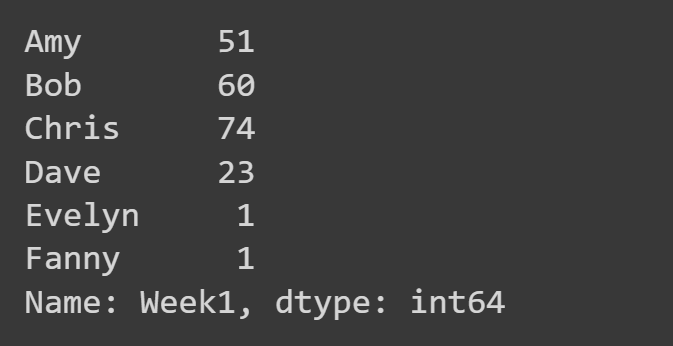
Selecionando Múltiplas Colunas
Para selecionar várias colunas do quadro de dados, passe na lista todos os nomes de colunas a serem selecionados.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 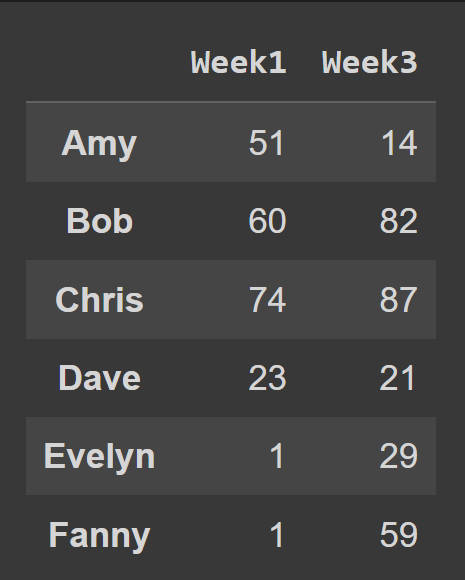
Além desse método, você também pode usar os iloc() e loc() para selecionar colunas. Codificaremos um exemplo mais tarde.
Selecione linhas de um Pandas DataFrame

Usando o método .iloc()
Para selecionar linhas usando o método iloc() , passe os índices correspondentes a todas as linhas como uma lista.
Neste exemplo, selecionamos as linhas no índice ímpar.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 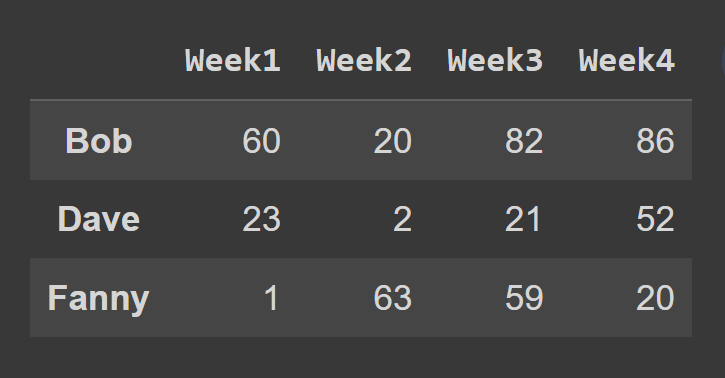
Em seguida, selecionamos um subconjunto do quadro de dados contendo as linhas no índice 0 a 2, o ponto final 3 é excluído por padrão.
slice1 = students_df.iloc[0:3] print(slice1) 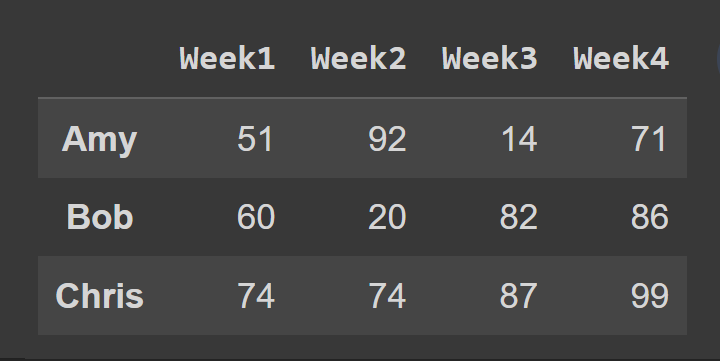
Usando o método .loc()
Para selecionar as linhas de um quadro de dados usando o método loc() , você deve especificar os rótulos correspondentes às linhas que deseja selecionar.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 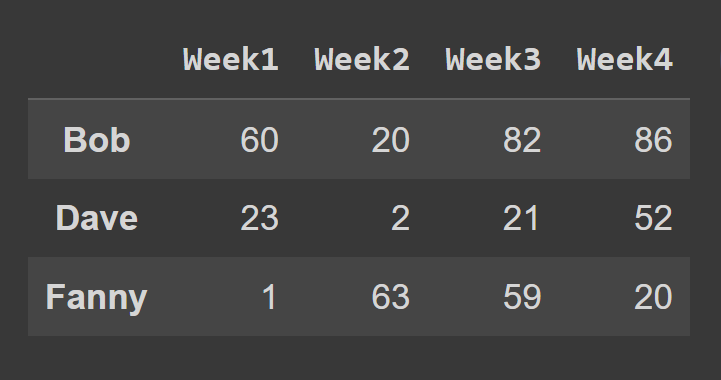
Se as linhas do quadro de dados forem indexadas usando o intervalo padrão 0, 1, 2, até
numRows-1, então usariloc()eloc()são equivalentes.
Selecione linhas e colunas de um Pandas DataFrame
Até agora, você aprendeu como selecionar linhas ou colunas de um quadro de dados do pandas. No entanto, às vezes pode ser necessário selecionar um subconjunto de linhas e colunas. Então como você faz isso? Você pode usar os iloc() e loc() que discutimos.
Por exemplo, no trecho de código abaixo, selecionamos todas as linhas e colunas nos índices 2 e 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 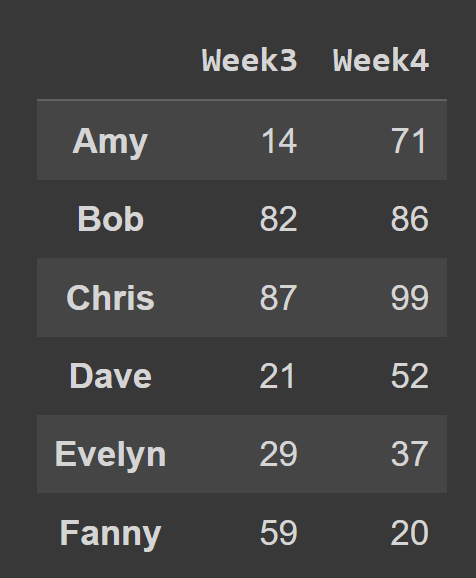
Usar start:stop cria uma fatia desde o start até, mas não incluindo stop . Portanto, quando você ignora os valores start e stop , quando ignora os valores inicial e final, a fatia começa no início - e se estende até o final do quadro de dados - selecionando todas as linhas.
Ao usar o método loc() , você deve passar os rótulos das linhas e colunas que deseja selecionar, conforme mostrado:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 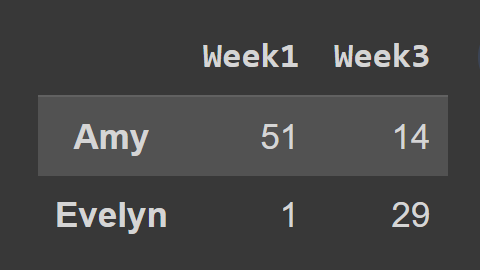
Aqui, o dataframe subset_df2 contém o registro de Amy e Evelyn para Week1 e Week3.
Conclusão
Aqui está uma revisão rápida do que você aprendeu neste tutorial:
- Depois de instalar o pandas, você pode importá-lo sob o alias
pd. Para criar um objeto de quadro de dados pandas, você pode usar opd.DataFrame(data), ondedatase referem à matriz N-dimensional ou a um iterável que contém os dados. Você pode especificar os rótulos de linha e índice e coluna definindo os parâmetros opcionais de índice e colunas, respectivamente. - O uso
pd.read_csv(path-to-the-file)lê o conteúdo do arquivo em um quadro de dados. - Você pode chamar o método
info()no objeto do quadro de dados para obter informações sobre as colunas, o número de valores ausentes, os tipos de dados e o tamanho do quadro de dados. - Para selecionar uma única coluna, use
df_name[col_name]e para selecionar várias colunas, determinada coluna,df_name[[col1,col2,...,coln]]. - Você também pode selecionar colunas e linhas usando os métodos
loc()eiloc(). - Enquanto o método
iloc()considera o índice (ou fatia de índice) das linhas e colunas a serem selecionadas, o métodoloc()considera os rótulos de linha e coluna.
Você pode encontrar os exemplos usados neste tutorial neste notebook Colab.
Em seguida, confira esta lista de notebooks de ciência de dados colaborativos.