
O caminho certo para noindex uma página
Publicados: 2022-12-02Pode parecer contra-intuitivo, mas nem todas as páginas do seu site devem aparecer nos resultados de pesquisa. A otimização do mecanismo de pesquisa (SEO) se esforça para aumentar a visibilidade da pesquisa e o tráfego orgânico – e, às vezes, você pode atingir melhor esse objetivo restringindo qual conteúdo pode aparecer nos resultados da pesquisa.
Se você está coçando a cabeça ou descobrindo meu blefe, continue lendo para descobrir o valor de não indexar uma página ou subdiretório e como implementar tags noindex.
O que significa Noindex?
O termo “noindex” é uma diretiva especial em uma metatag de robôs que informa aos rastreadores de pesquisa para excluir a página das páginas de resultados do mecanismo de pesquisa (SERPs). Isso significa que os pesquisadores não poderão acessar a página por meio da pesquisa.
Uma parte valiosa de qualquer estratégia técnica de SEO, as metatags robots permitem que você exclua páginas que não agregam valor aos pesquisadores ou que contenham informações que você não deseja que apareçam nos resultados da pesquisa, como:
- Páginas de confirmação e agradecimento
- páginas de login
- Política de privacidade ou página de termos de serviço
- conteúdo fechado
- Mensagens de erro
Metatag Robots vs. Robots.txt vs. Tag X-Robots
A metatag de robôs é frequentemente confundida com o arquivo robots.txt e a tag x-robots. Todos os três fornecem instruções para pesquisar rastreadores sobre páginas e fazem parte do protocolo de exclusão de robôs (REP). Simplificando: eles dizem ao Google o que colocar na Pesquisa do Google e o que manter fora dela, bem como quais páginas devem rastrear. No entanto, eles não podem e não devem ser usados de forma intercambiável.
Metatag de robôs
Uma meta tag robots é adicionada à seção <head> de uma determinada página da Web e apenas transmite instruções sobre essa página específica. Geralmente chamada de tag noindex ou metatag noindex, a metatag robots pode fazer mais do que apenas dizer a um rastreador de pesquisa para não indexar uma página.
Ele também pode ser usado para pedir aos rastreadores que não sigam links, traduzam uma página, bloqueiem um bot de pesquisa específico ou evitem que um link armazenado em cache apareça nas SERPs.
Diretivas comuns de meta tags de robôs incluem:
- Noindex, nofollow — <meta name=”robots” content=”noindex, nofollow”>
O Googlebot e outros rastreadores da web podem acessar a página, mas não devem indexá-la ou seguir seus links. - Noindex, siga — <meta name=”robots” content=”noindex”>
O Googlebot e outros rastreadores da web podem acessar a página e seguir os links nela, mas não devem indexar a página em si. Você não precisa incluir “seguir” na metatag, pois esse é o padrão.
Robots.txt
Robots.txt é um arquivo que permite aos proprietários de sites informar aos mecanismos de pesquisa quais partes do site eles não desejam que sejam rastreadas. É como um sinal pessoal de Não Perturbe para o seu site pendurado no diretório raiz do seu domínio ou subdomínio.
Um arquivo robots.txt é melhor para impedir que subdiretórios inteiros sejam acessados e rastreados, em vez de páginas individuais. Use-o para impedir que os rastreadores de pesquisa acessem e indexem:
- Páginas de pesquisa interna
- Parâmetros de URL
- Fóruns onde o spam gerado pelo usuário pode causar problemas
- Subdiretórios internos, como aqueles que são apenas para funcionários
Siga estas etapas para criar um arquivo robots.txt e certifique-se de vincular ao seu sitemap XML.
Se você criar um link para uma página incluída em seu arquivo robots.txt, convém adicionar uma metatag robots a ela também para garantir que ela não apareça nos resultados da pesquisa. Lembre-se: o robots.txt apenas impede que os rastreadores acessem uma página, não a indexem. Se as páginas abrangidas pelas diretivas do robots.txt receberem links externos, os mecanismos de pesquisa poderão indexá-las. Use uma meta tag robots em conjunto com o arquivo robots.txt para evitar isso.
Marca X-Robôs
Para impedir que um PDF, vídeo ou imagem apareça nas SERPs, use uma tag x-robots. As mesmas diretivas especificadas para meta tags robots são usadas para x-robots. No entanto, ao contrário da metatag robots, que reside no cabeçalho HTML de uma página, uma tag x-robots é colocada na resposta do cabeçalho HTTP.
A diretiva se parece com isso:
X-Robots-Tag: noindexQuando colocar noindex em uma página
Controle do inchaço do índice
O inchaço do índice acontece quando o Google indexa páginas com pouco ou nenhum valor para os pesquisadores. Essas páginas estranhas desviam recursos de páginas mais valiosas. Use uma metatag robots para gerenciar quais páginas aparecem nos resultados de pesquisa.
Erradicar a canibalização de palavras-chave
A canibalização de palavras-chave acontece quando duas páginas compartilham uma palavra-chave e uma intenção de pesquisa semelhantes, fazendo com que elas compitam entre si nas SERPs.
Se você tiver duas páginas canibalizando uma à outra e quiser manter ambas sem alterar seu conteúdo, noindex one. Dito isso, você só deve fazer isso se a página que você está noindexing não direcionar o tráfego de palavras-chave que a outra página não. Em uma situação como essa, pode ser necessário retrabalhar o conteúdo em uma ou ambas as páginas para resolver o problema de canibalização.
Proteger páginas de destino bloqueadas
Quando você oferece um recurso de alto valor aos clientes em troca de informações de contato, certifique-se de que não esteja acessível de nenhuma outra forma. Adicione uma meta tag robots para noindex a página e evite que ela apareça nas SERPs.
Excluir produtos impopulares da pesquisa
Os sites de comércio eletrônico geralmente oferecem produtos para atender a determinados clientes, mesmo que não haja muita demanda por eles. Por exemplo, um varejista de autopeças ou outra empresa técnica pode ter produtos para determinados modelos ou equipamentos raros. Se essas páginas de produto ou categoria não estiverem gerando tráfego orgânico, elas geralmente podem ser não indexadas.
Como Noindex uma página da Web
A meta tag noindex vai no cabeçalho do HTML de uma página. O código não diferencia maiúsculas de minúsculas e se parece com isso:
<meta name="robots" content="noindex">“Robôs” significa que a diretiva se aplica a qualquer rastreador, mas você pode destacar rastreadores substituindo “robôs” por nomes de rastreadores conhecidos, como “Googlebot” ou “bingbot”.

Os rastreadores ainda seguirão os links na página, a menos que você também adicione um comando nofollow. Você pode fazer isso para impedir que o link equity flua pela página ou para impedir que um rastreador siga um link para conteúdo fechado.
Para adicionar um valor nofollow, separe-o da diretiva noindex com uma vírgula.
<meta name="robots" content="noindex, nofollow">Observação: antes de não indexar uma página, verifique se ela possui algum tráfego orgânico de entrada no Google Search Console. Em caso afirmativo, determine como seu site pode continuar a capturar esse tráfego antes de não indexar a página.
Como adicionar uma metatag de robôs ao seu código HTML
- Abra o código-fonte da página que você deseja noindex.
- Encontre o cabeçalho no topo da página. Começa com <head> e termina com </head>. Provavelmente haverá outro código no cabeçalho também.
- Adicione a metatag robots em uma nova linha, garantindo que ela apareça entre as tags <head> e </head>.
É isso! Se sua página já estiver indexada, você pode pedir ao Google para rastreá-la novamente colando seu URL na ferramenta de inspeção de URL.
Já indexado? Use a Ferramenta de Remoção de URL
Quando você adiciona uma tag noindex a uma nova página de conteúdo, o Googlebot vê a diretiva quando rastreia a página e não a indexa.
No entanto, se você estiver adicionando a tag a uma página que já está indexada , a página continuará aparecendo nos resultados da pesquisa até que seja rastreada novamente e os bots vejam as novas instruções noindex. Você pode pedir ao Google para rastrear novamente o URL no Google Search Console por meio da Ferramenta de inspeção de URL, mas isso não removerá instantaneamente a página dos SERPs.
Se você precisar remover uma página da SERP imediatamente, use a ferramenta de remoção no Google Search Console. Isso manterá as páginas fora dos resultados de pesquisa do Google por cerca de seis meses. A essa altura, a meta tag noindex deve funcionar.
Como Noindex uma página no WordPress
Cada página no WordPress é indexada por padrão. Você pode usar o plug-in Yoast SEO para não indexar uma página no WordPress sem escrever código. Veja como.
Clique na guia 'Avançado' na caixa meta do Yoast SEO.
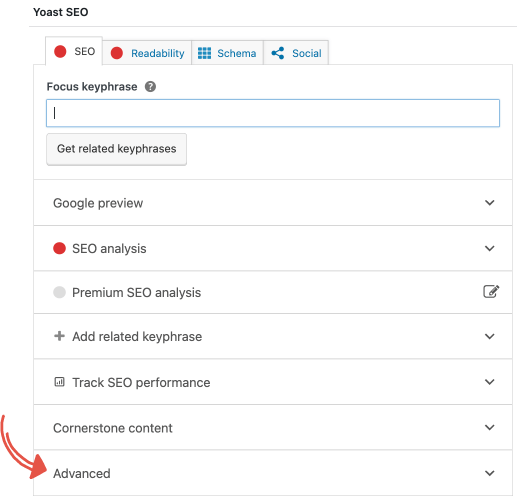
Abaixo da pergunta, 'Permitir que os mecanismos de pesquisa mostrem esta postagem nos resultados da pesquisa?' selecione 'Não' na caixa suspensa.
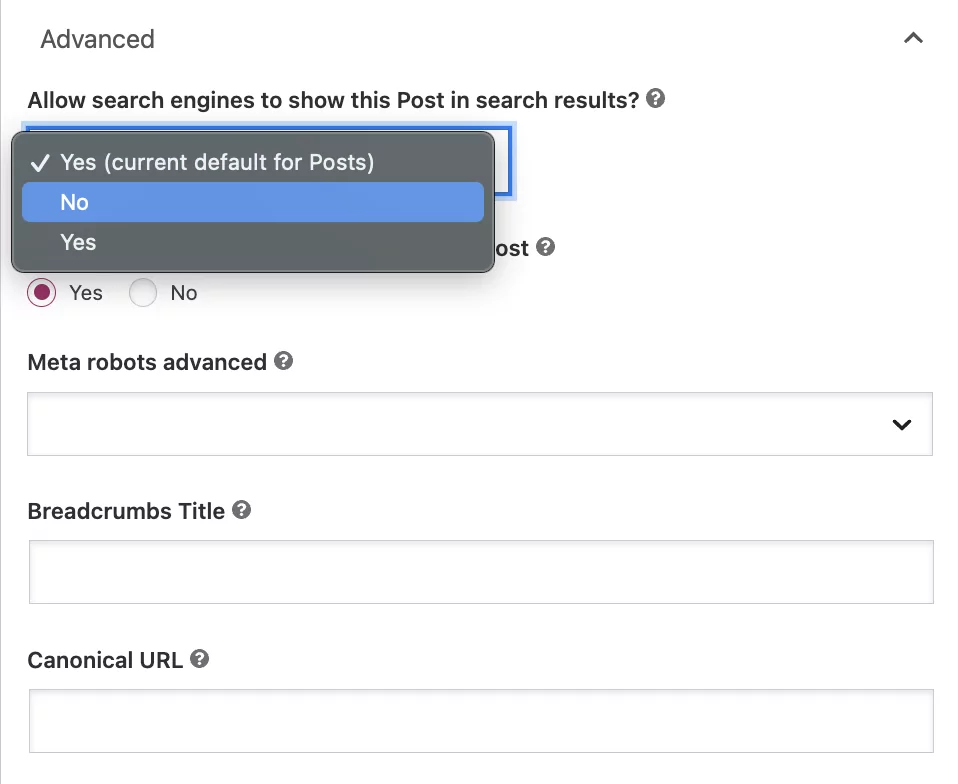
Embora essa configuração instrua o Google a não indexar a postagem, os bots ainda seguirão automaticamente os links na página para rastrear outras páginas.
Se você deseja adicionar uma diretiva nofollow, selecione o botão 'Não' abaixo da pergunta: 'Os mecanismos de pesquisa devem seguir os links neste post?'
Perguntas frequentes sobre metatags de robôs
Todos os mecanismos de pesquisa obedecem a uma diretiva noindex?
Você pode esperar que o Google, o Bing e outros mecanismos de pesquisa legítimos obedeçam a uma metatag de robôs.
Posso criar links para páginas não indexadas?
Sim. A tag noindex informa aos bots de pesquisa como tratar uma página ao rastrear e indexar. Isso não afeta sua capacidade de vincular a uma página. Isso pode ser útil para páginas de categoria em um blog, que não devem aparecer nos resultados de pesquisa, mas podem fornecer aos bots links para páginas valiosas que deveriam.
Quando devo usar uma metatag de robôs?
Se você tem uma página que não oferece nenhum valor aos pesquisadores, como uma página de agradecimento ou uma página para impressão, não a indexe com uma metatag robots para evitar que ela apareça nas SERPs.
Quando não devo usar uma diretiva noindex?
Você pode resolver tecnicamente problemas de conteúdo duplicado e alguns problemas de orçamento de rastreamento com diretivas noindex, mas essa não é a melhor maneira de fazer isso. O conteúdo duplicado é melhor tratado usando tags canônicas, que concentram o valor do link das duplicatas na página canônica. Se estiver tentando economizar o orçamento de rastreamento, você deve usar o arquivo robots.txt para impedir o rastreamento dessa seção do site.
As páginas não indexadas passam link equity?
Sim. Mesmo que uma página não seja indexada, ela ainda pode compartilhar qualquer autoridade de classificação construída. No entanto, os rastreadores de pesquisa devem ter a capacidade de seguir os links na página para que o link equity flua. Se uma página for definida como noindex e nofollow, ela não poderá transmitir o link equity.
A noindexing de uma página a remove automaticamente dos SERPs do Google?
Se sua página já estiver indexada, adicionar uma metatag robots não a removerá automaticamente dos resultados de pesquisa. Leva algum tempo para que as páginas já indexadas desapareçam das SERPs. Os bots de pesquisa precisam rastrear novamente as páginas para ver a tag noindex. Para obter resultados mais rápidos, solicite que o Google rastreie novamente a página e use a ferramenta de remoção de URL.
Descubra páginas problemáticas com uma auditoria de SEO
Não deixe que conteúdo escasso ou duplicado afete sua visibilidade de pesquisa. Certifique-se de dar às suas páginas a melhor chance de classificação. Nossa auditoria de SEO de mais de 200 pontos sinaliza problemas como conteúdo duplicado, um arquivo robots.txt ausente, metatags de robôs mal aplicadas, inchaço do índice e muito mais. Inscreva-se para uma consulta de SEO gratuita para ver como nosso serviço de auditoria de SEO pode maximizar sua visibilidade online e ajudar sua empresa a crescer.