
O que é cluster de failover? Como funciona + soluções
Publicados: 2023-09-22As empresas que precisam de transações on-line não podem se dar ao luxo de quebras de servidores. Como resultado, essas empresas buscam maneiras de criar um procedimento à prova de falhas que mantenha seus dados seguros mesmo se o servidor entrar em colapso. Um desses métodos é o clustering de failover.
O clustering de failover pode ser controlado por soluções de provedores de sistema de nomes de domínio (DNS) gerenciados; no entanto, compreender o seu mecanismo e as principais características pode ajudar a limitar quaisquer desafios de failover.
O que é cluster de failover?
O cluster de failover opera em um grupo de servidores de computador para garantir alta disponibilidade (HA) ou disponibilidade contínua (CA) para aplicativos de servidor. Essa tecnologia garante que, se um servidor ou nó falhar, outro nó do cluster estará pronto para assumir a carga de trabalho sem interrupções.
Essa abordagem mantém as cargas de trabalho do servidor escalonáveis e disponíveis. Muitos dos principais programas de servidor, como Microsoft Exchange , Microsoft SQL Server e Hyper-V , dependem de clustering de failover para se protegerem.
Alguns clusters de failover empregam servidores físicos, enquanto outros usam máquinas virtuais (VMs) . Todos selecionam o tipo de cluster necessário com base nos requisitos de seu aplicativo de servidor.
Um cluster consiste em dois ou mais nós que trocam dados e software para serem processados através de cabos físicos ou de uma rede segura especializada. Vários tipos de tecnologia de cluster podem ser usados para balanceamento de carga, armazenamento e computação simultânea ou paralela. Em alguns casos, os clusters de failover são combinados com tecnologias extras de cluster.
A principal função de um cluster de failover é fornecer CA ou HA para aplicativos e serviços. Os clusters de CA, também conhecidos como clusters tolerantes a falhas (FT), permitem que os usuários finais continuem usando aplicativos e serviços mesmo se um servidor falhar. Você poderá observar uma breve interrupção no serviço causada por clusters de alta disponibilidade, mas o sistema poderá se recuperar sem perda de dados e com pouco tempo de inatividade.
Por que o clustering de failover é importante?
Com o clustering de failover, você pode reparar nós inativos sem desligar seu banco de dados, evitando preocupações com tempo de inatividade e reparando rapidamente servidores quebrados. Além disso, no caso de falha de hardware, esta técnica encerra o banco de dados para proteger os nós ativos.
O clustering de failover também automatiza a recuperação de dados em caso de falha. Isso reduz sua dependência da equipe de tecnologia da informação (TI) e permite que seus servidores se recuperem rapidamente. Ele também oferece excelente disponibilidade de cluster de linguagem de consulta estruturada (SQL) com tempo de inatividade mínimo. A funcionalidade de failover automatizado do cluster de failover preserva a função do seu banco de dados, mesmo se houver uma falha de hardware.
Como funcionam os clusters de failover?
O clustering de failover consiste em dois processos fundamentais, HA e CA, para aplicativos de servidor.
Enquanto os clusters de failover de CA tentam atingir 100% de disponibilidade, os clusters de alta disponibilidade buscam 99,999%, comumente conhecidos como cinco noves. Esse tempo de inatividade não totaliza mais de 5,26 minutos por ano. Os clusters de CA têm maior disponibilidade, mas exigem mais hardware para operar, aumentando o custo geral.
Clusters de failover de alta disponibilidade
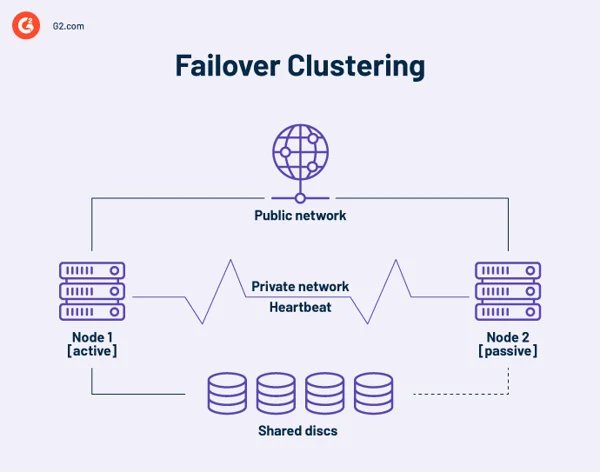
Um cluster de alta disponibilidade é uma coleção de computadores independentes que compartilham recursos e dados. Os nós de um cluster de failover têm acesso ao armazenamento compartilhado. Um link de monitoramento também está incluído em clusters de alta disponibilidade para verificar a pulsação ou a integridade de outros servidores. Uma pulsação é uma rede privada compartilhada apenas pelos nós do cluster. Não é acessível do lado de fora.
Em qualquer ponto, pelo menos um nó em um cluster está ativo e pelo menos um está inativo ou passivo.
Em um arranjo básico de dois nós, se o Nó 1 falhar, o Nó 2 reconhece a falha por meio da conexão de pulsação e se configura como o nó ativo. O software de cluster em cada nó garante que os clientes se conectem a um nó ativo.
Instalações maiores podem empregar servidores dedicados para administrar o cluster. Um servidor de gerenciamento de cluster sempre envia sinais de pulsação para identificar quaisquer nós com falha e, em caso afirmativo, para informar outro nó para assumir o trabalho.
Algumas ferramentas de software de gerenciamento de cluster lidam com HA para VMs agrupando as máquinas e servidores em um cluster. Se um host falhar, um host diferente retoma as VMs.
Como possível ponto único de falha, o armazenamento compartilhado representa um risco. No entanto, combinar uma matriz redundante de discos independentes 6 e 10 – também conhecidos como RAID 6 e RAID 10 – pode ajudar a manter o serviço mesmo se dois discos rígidos falharem.
A energia elétrica pode ser outro ponto único de falha se todos os servidores estiverem conectados à mesma rede. Fornecer a cada nó sua própria fonte de alimentação ininterrupta (UPS) os mantém protegidos.
Clusters de failover de disponibilidade contínua
Ao contrário do paradigma HA, um cluster tolerante a falhas compreende vários computadores que compartilham uma única cópia do sistema operacional (SO) de um computador. Os comandos de software fornecidos a um sistema também são executados nos outros sistemas.
A CA insiste que a organização utilize equipamento informático formatado e uma UPS de reserva. A CA precisa de uma réplica constantemente acessível e quase perfeita do sistema físico ou virtual que executa o serviço. Este modelo de redundância é conhecido como 2N.
Os sistemas CA podem compensar uma ampla gama de falhas. Um sistema tolerante a falhas pode identificar um mau funcionamento de:
- Uma unidade de disco rígido
- Uma unidade de processamento em um computador
- Um subsistema para entrada e saída (E/S)
- Uma fonte de energia
- Um componente de uma rede
O ponto de falha pode ser descoberto imediatamente e um componente ou método de backup pode substituí-lo imediatamente, sem interromper o próximo serviço.
O software de clustering pode conectar dois ou mais servidores para se comportarem como um único servidor virtual ou construir várias configurações alternativas de cluster de failover de CA. Por exemplo, se um dos servidores virtuais falhar, os outros responderão removendo temporariamente o servidor virtual do quorum do cluster. O servidor virtual então redistribui a carga entre os outros servidores até que o servidor travado esteja pronto para reiniciar.
Um servidor de hardware duplo com todos os componentes físicos replicados é uma alternativa aos clusters de failover de CA. Eles computam separadamente e simultaneamente em diversas plataformas de hardware e sincronizam usando um nó dedicado que monitora os resultados de ambos os servidores físicos. Embora esta solução forneça proteção, pode ser mais cara.
Recursos de cluster de failover
Muitas organizações usam clustering de failover para aplicativos de missão crítica. Isso ocorre porque as características a seguir tornam o clustering de failover uma técnica significativa.
- Escalabilidade : como o cluster de failover é baseado em um grupo de clusters colaborando para evitar falhas no servidor, você pode escalar fácil e prontamente conforme necessário adicionando novos clusters.
- Estabilidade: servidores em cluster se conectam por meio de fios. Os clusters restantes ainda podem oferecer serviço mesmo se um ou mais falharem devido a fatores externos.
- Monitoramento em tempo real: Os nós do cluster são monitorados constantemente para garantir que funcionem corretamente. Quando um cluster é reiniciado ou transferido para outro nó.
- Volume compartilhado de cluster (CSV): esse recurso fornece um namespace consistente e distribuído para os nós usarem ao trabalhar com armazenamento compartilhado. É crucial manter os aplicativos do servidor funcionando sem interrupção do início ao fim.
Tipos de clusters de failover
Avanços significativos no cluster de failover ocorreram na última década, com muitas organizações oferecendo agora sua própria versão de soluções de cluster. Alguns dos serviços de cluster mais comuns são detalhados aqui.

Clusters de failover VMware
A VMware fornece inúmeras tecnologias de virtualização para clusters de VMs. A arquitetura CA do vSphere vMotion duplica com precisão uma máquina virtual VMware e sua rede entre redes de data centers físicos.
VMware vSphere HA, um segundo produto, fornece HA para VMs agrupando-as e seus hosts em um cluster para failover automatizado. Além disso, o programa não depende de componentes externos como DNS, o que diminui possíveis pontos de falha.
Cluster de failover do servidor Windows
O método Windows server failover cluster (WSFC) promove a criação de servidores de failover Hyper-V. Entre 2016 e 2019, esta estratégia tornou-se popular entre os utilizadores do Microsoft Windows. O WSFC permite o monitoramento de cluster e oferece automaticamente o mecanismo de failover necessário. No caso de perda do servidor, o WFSC move os clusters para um nó separado ou tenta reiniciá-los. Além disso, sua tecnologia CSV fornece um namespace distribuído que permite que vários nós compartilhem memória.
Servidor SQL
Este produto da Microsoft, introduzido com o SQL Server 2017, possui soluções robustas de HA que usam a tecnologia WSFC. Os componentes do SQL Server são considerados recursos de cluster WSFC neste contexto. Eles estão ainda mais integrados com outros recursos dependentes do WSFC. Como resultado, o WSFC tem autoridade para identificar e comunicar ordens para reiniciar uma instância do SQL Server ou para mover instâncias como essas para um novo nó.
Red Hat Linux
Além da Microsoft, outros fornecedores de sistemas operacionais vêm com suas próprias soluções de cluster de failover. Por exemplo, os fãs do Red Hat Enterprise Linux (RHEL) podem usar a extensão HA e o Red Hat Global File System (GFS/GFS2) para estabelecer clusters de failover HA. São suportados clusters extensos de cluster único que abrangem vários locais e clusters tolerantes a desastres de vários locais. A replicação de armazenamento de dados da rede de área de armazenamento (SAN) é comumente usada em clusters de vários locais.
Aplicações de cluster de failover
Este mecanismo robusto facilita as seguintes aplicações em tempo real.
Disponibilidade de aplicativos de missão crítica.
Os computadores de processamento de transações online (OLTP) devem ter sistemas resistentes a falhas. O OLTP, que requer disponibilidade total, é usado para sistemas de reserva de companhias aéreas, negociação eletrônica de ações e serviços bancários em caixas eletrônicos.
Muitos setores, como manufatura, transporte e varejo, empregam clusters de CA ou computadores resistentes a falhas para aplicações de missão importante. Sistemas de comércio eletrônico, gerenciamento de pedidos e ponto de funcionários contam como exemplos.
Clusters de alta disponibilidade geralmente são aceitáveis para aplicativos e serviços de cluster que exigem apenas cinco noves de tempo de atividade.
Ajuda em desastres
A recuperação de desastres também se beneficia do clustering de failover. É altamente recomendável que os servidores de failover sejam hospedados em locais remotos porque uma calamidade como um incêndio ou inundação destrói todo o hardware e software físico.
A Réplica de Armazenamento, uma tecnologia que duplica volumes entre servidores para recuperação de desastres , está incluída no Windows Server 2016 e 2019. O Stretch Failover é um recurso tecnológico que permite que clusters de failover abranjam dois locais.
As organizações podem replicar dados em vários centros estendendo clusters de failover. Se ocorrer uma tragédia em um local, todos os dados serão preservados em servidores de failover nos outros.
Replicação de um banco de dados
De acordo com a Microsoft, o WSFC foi lançado pela primeira vez no Windows Server 2016 para proteger serviços de “missão crítica”, como o banco de dados do servidor SQL e o servidor de comunicações Microsoft Exchange.
Para replicação de banco de dados , outros fornecedores fornecem tecnologia de cluster de failover. Por exemplo, o MySQL Cluster possui um método de pulsação que permite a detecção rápida de falhas em outros nós do cluster, geralmente em menos de um segundo, sem interrupções de serviço para os clientes.
Os bancos de dados podem ser replicados para locais distantes usando a capacidade de replicação geográfica.
Benefícios dos clusters de failover
A ideia dos clusters de failover é garantir que os usuários experimentem interrupções mínimas no serviço. No entanto, outros benefícios adicionais do clustering de failover são discutidos abaixo.
- Maior disponibilidade de recursos: se um servidor inteligente falhar, os outros no cluster assumem a responsabilidade. Isso economiza tempo e informações cruciais.
- Alocação estratégica de recursos: você pode distribuir projetos entre nós da maneira que desejar. Isso minimiza a sobrecarga, pois nem todos os computadores são necessários para executar todos os projetos simultaneamente, proporcionando uma maneira de usar seus recursos com mais liberdade.
- Maior poder de processamento: Mais máquinas, mais potência.
- Maior escalabilidade: à medida que sua base de usuários e a complexidade do relatório aumentam, seus recursos também aumentam.
- Gerenciamento simplificado: o clustering facilita o manuseio de sistemas significativos ou que mudam rapidamente.
Limitações do cluster de failover
Por mais significativo que seja o clustering de failover, ele enfrenta as seguintes limitações.
- Configurações complexas: a configuração de cluster de failover para Windows exige que você lide com muitas redes e placas de rede ao mesmo tempo. Como resultado, a implantação deste método é difícil, especialmente para iniciantes.
- Integrações de ferramentas: O cluster de failover do Windows e o Hyper-V devem ser mais integrados. Você tem que ajustar cada um deles para concluir o clustering de failover com êxito.
- Interface da Web: não há interface da Web para ajustar os parâmetros do cluster. Para acessar o recurso gerenciador de cluster, você deve fazer login manualmente em uma área de trabalho remota.
Soluções de cluster de failover: provedores de DNS gerenciados
Ao trabalhar em conjunto com sistemas de cluster de failover, os provedores de DNS gerenciados redirecionam o tráfego para servidores ou data centers alternativos durante eventos de failover, garantindo acesso ininterrupto aos seus serviços para que você obtenha alta disponibilidade e minimize o tempo de inatividade.
Os cinco principais provedores de DNS gerenciados:
- DNS da Cloudflare
- DNS do Azure
- Infoblox NIOS
- DESENVOLVIMENTO WPMU
- Gerenciador DNS
* Acima estão os cinco principais softwares de provedores de DNS gerenciados do Relatório Grid do outono de 2023 da G2.

Modernizando a confiabilidade
O clustering de failover surgiu como uma opção confiável e essencial para alta disponibilidade e tolerância a falhas nas infraestruturas de TI atuais. Ele fornece operações contínuas apesar de falhas de hardware ou manutenção programada, distribuindo automaticamente cargas de trabalho e recursos por vários nós da rede. Essa tecnologia oferece outra maneira de lidar com o aspecto mais importante do seu negócio: tornar a experiência de cada cliente segura e feliz.
Fortificar a resiliência do seu sistema também não faz mal!
Comece com um guia de segurança DNS para uma estratégia de sistema robusta.