
Como automatizar a orquestração de direitos de acesso nos buckets S3 da AWS
Publicados: 2023-01-13Anos atrás, quando os servidores Unix locais com grandes sistemas de arquivos eram uma coisa, as empresas estavam criando extensas regras de gerenciamento de pastas e estratégias para administrar direitos de acesso a pastas diferentes para pessoas diferentes.
Normalmente, a plataforma de uma organização atende a diferentes grupos de usuários com interesses, restrições de nível de confidencialidade ou definições de conteúdo completamente distintos. No caso de organizações globais, isso pode até significar a separação de conteúdo com base na localização, basicamente, entre os usuários pertencentes a diferentes países.

Outros exemplos típicos podem incluir:
- separação de dados entre ambientes de desenvolvimento, teste e produção
- conteúdo de vendas não acessível a um público amplo
- conteúdo legislativo específico do país que não pode ser visto ou acessado de outra região
- conteúdo relacionado ao projeto em que “dados de liderança” devem ser fornecidos apenas a um grupo limitado de pessoas, etc.
Existe uma lista potencialmente interminável de tais exemplos. A questão é que sempre existe algum tipo de necessidade de orquestrar direitos de acesso a arquivos e dados entre todos os usuários aos quais a plataforma fornece acesso.
No caso de soluções locais, essa era uma tarefa rotineira. O administrador do sistema de arquivos apenas configurou algumas regras, usou uma ferramenta de sua escolha e, em seguida, as pessoas foram mapeadas em grupos de usuários, e os grupos de usuários foram mapeados em uma lista de pastas ou pontos de montagem que eles poderão acessar. Ao longo do caminho, o nível de acesso foi definido como somente leitura ou acesso de leitura e gravação.
Agora, olhando para as plataformas de nuvem da AWS, é óbvio esperar que as pessoas tenham requisitos semelhantes para restrições de acesso ao conteúdo. A solução para este problema deve ser, porém agora, diferente. Os arquivos não estão mais resistindo em servidores Unix, mas na nuvem (e potencialmente acessíveis não apenas para toda a organização, mas até para o mundo inteiro), e o conteúdo não é armazenado em pastas, mas em baldes S3.

Abaixo descrito é uma alternativa para abordar este problema. Ele é construído com base na experiência do mundo real que tive enquanto projetava essas soluções para um projeto concreto.
Abordagem simples, mas amplamente manual
Uma maneira de resolver esse problema sem nenhuma automação é relativamente direta e simples:
- Crie um novo balde para cada grupo distinto de pessoas.
- Atribua direitos de acesso ao bucket para que apenas este grupo específico possa acessar o bucket S3.
Isso certamente é possível se o requisito for uma resolução muito simples e rápida. Há, no entanto, alguns limites a serem observados.
Por padrão, somente até 100 buckets S3 podem ser criados em uma conta da AWS. Esse limite pode ser estendido para 1.000 enviando um aumento de limite de serviço para o ticket da AWS. Se esses limites não são algo com o qual seu caso de implementação específico estaria preocupado, você pode permitir que cada um de seus usuários de domínio distintos opere em um bucket S3 separado e encerre o dia.
Os problemas podem surgir se houver alguns grupos de pessoas com responsabilidades multifuncionais ou simplesmente algumas pessoas que precisam acessar o conteúdo de mais domínios ao mesmo tempo. Por exemplo:
- Analistas de dados avaliando o conteúdo de dados para várias áreas, regiões, etc.
- A equipe de teste compartilhou serviços atendendo a diferentes equipes de desenvolvimento.
- Usuários de relatórios que precisam criar análises de painel em diferentes países dentro da mesma região.
Como você pode imaginar, esta lista pode crescer novamente tanto quanto você pode imaginar, e as necessidades das organizações podem gerar todos os tipos de casos de uso.
Quanto mais complexa for essa lista, mais complexa será a orquestração de direitos de acesso necessária para conceder a todos esses diferentes grupos diferentes direitos de acesso a diferentes buckets do S3 na organização. Serão necessárias ferramentas adicionais e talvez até mesmo um recurso dedicado (administrador) precisará manter as listas de direitos de acesso e atualizá-las sempre que qualquer alteração for solicitada (o que será muito frequente, especialmente se a organização for grande).
Então, como conseguir a mesma coisa de forma mais organizada e automatizada?
Apresentar tags para baldes
Se a abordagem de bucket por domínio não funcionar, qualquer outra solução terminará com buckets compartilhados para mais grupos de usuários. Nesses casos, é necessário construir toda a lógica de atribuição de direitos de acesso em alguma área que seja fácil de alterar ou atualizar dinamicamente.
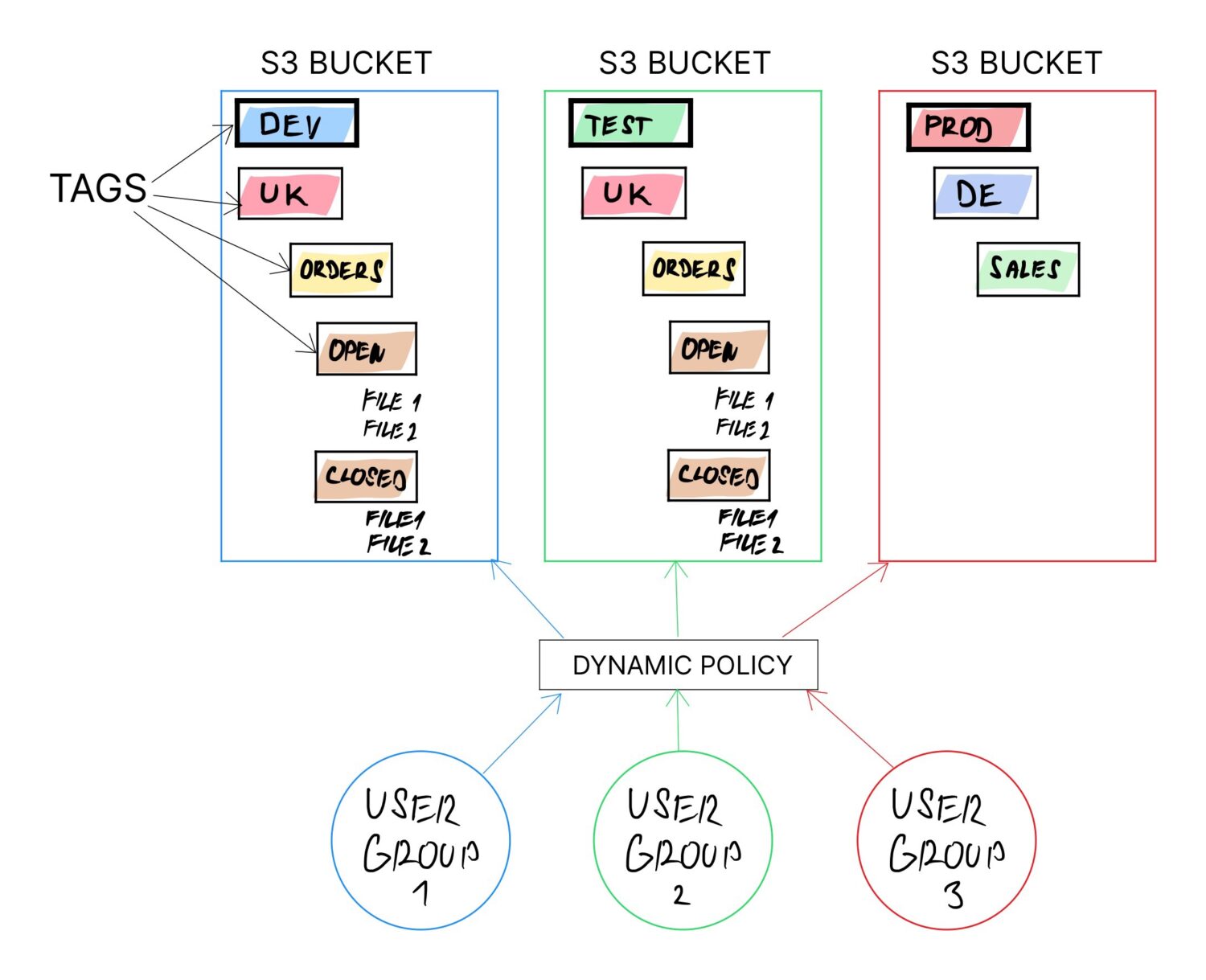
Uma das maneiras de conseguir isso é usando tags nos baldes S3. As tags são recomendadas para serem usadas em qualquer caso (pelo menos para permitir uma categorização de cobrança mais fácil). No entanto, a tag pode ser alterada a qualquer momento no futuro para qualquer bucket.
Se toda a lógica for construída com base nas tags de balde e o restante for uma configuração dependente dos valores de tag, a propriedade dinâmica é garantida, pois é possível redefinir a finalidade do balde apenas atualizando os valores de tag.
Que tipo de tags usar para fazer isso funcionar?
Isso depende do seu caso de uso concreto. Por exemplo:
- Pode ser necessário separar baldes por tipo de ambiente. Então, nesse caso, um dos nomes das tags deve ser algo como “ENV” e com possíveis valores “DEV”, “TEST”, “PROD”, etc.
- Talvez você queira separar a equipe com base no país. Nesse caso, outra tag será “PAÍS” e valorizará algum nome de país.
- Ou você pode querer separar os usuários com base no departamento funcional a que pertencem, como analistas de negócios, usuários de data warehouse, cientistas de dados, etc. Então você cria uma tag com o nome “USER_TYPE” e o respectivo valor.
- Outra opção pode ser definir explicitamente uma estrutura de pasta fixa para grupos de usuários específicos que eles devem usar (para não criar seu próprio amontoado de pastas e se perder lá com o tempo). Você pode fazer isso novamente com tags, onde você pode especificar vários diretórios de trabalho como: “data/import”, “data/processed”, “data/error”, etc.
Idealmente, você deseja definir as tags para que possam ser combinadas logicamente e formar uma estrutura de pasta inteira no bucket.

Por exemplo, você pode combinar as seguintes tags dos exemplos acima para construir uma estrutura de pasta dedicada para diferentes tipos de usuários de vários países com pastas de importação predefinidas que eles devem usar:
- /<ENV>/<USER_TYPE>/<PAÍS>/<UPLOAD>
Apenas alterando o valor <ENV>, você pode redefinir o objetivo da tag (seja para ser atribuído ao ecossistema do ambiente de teste, dev, prod, etc.)
Isso permitirá o uso do mesmo balde para muitos usuários diferentes. Os baldes não suportam pastas explicitamente, mas suportam “rótulos”. Esses rótulos funcionam como subpastas no final porque os usuários precisam passar por uma série de rótulos para acessar seus dados (da mesma forma que fariam com subpastas).
Crie políticas dinâmicas e mapeie tags de bucket internas
Depois de definir as tags de alguma forma utilizável, a próxima etapa é criar políticas de bucket do S3 que usariam as tags.
Se as políticas estiverem usando os nomes das tags, você estará criando algo chamado “políticas dinâmicas”. Isso basicamente significa que sua política se comportará de maneira diferente para depósitos com valores de tag diferentes aos quais a política se refere no formulário ou nos espaços reservados.
Esta etapa obviamente envolve alguma codificação personalizada das políticas dinâmicas, mas você pode simplificar esta etapa usando a ferramenta de edição de políticas Amazon AWS, que o guiará pelo processo.
Na própria política, você desejará codificar direitos de acesso concretos que devem ser aplicados ao bucket e o nível de acesso de tais direitos (leitura, gravação). A lógica lerá as tags nos baldes e criará a estrutura de pastas no balde (criando rótulos com base nas tags). Com base nos valores concretos das tags, as subpastas serão criadas e os direitos de acesso necessários serão atribuídos ao longo da linha.
O bom dessa política dinâmica é que você pode criar apenas uma política dinâmica e, em seguida, atribuir a mesma política dinâmica a muitos depósitos. Essa política se comportará de maneira diferente para blocos com valores de tag diferentes, mas sempre estará junto com sua expectativa de um bloco com esses valores de tag.
É uma maneira realmente eficaz de gerenciar as atribuições de direitos de acesso de maneira organizada e centralizada para um grande número de baldes, onde a expectativa é que cada balde siga algumas estruturas de modelo previamente acordadas e usadas por seus usuários dentro toda a organização.
Automatize a integração de novas entidades
Após definir políticas dinâmicas e atribuí-las aos buckets existentes, os usuários podem passar a utilizar os mesmos buckets sem o risco de usuários de diferentes grupos não acessarem conteúdos (armazenados no mesmo bucket) localizados em uma estrutura de pastas onde não possuem Acesso.
Além disso, para alguns grupos de usuários com acesso mais amplo, será fácil acessar os dados porque todos estarão armazenados no mesmo bucket.
A etapa final é tornar a integração de novos usuários, novos buckets e até novas tags o mais simples possível. Isso leva a outra codificação personalizada, que, no entanto, não precisa ser excessivamente complexa, assumindo que seu processo de integração tenha algumas regras muito claras que podem ser encapsuladas com lógica de algoritmo simples e direta (pelo menos você pode provar dessa maneira que seu processo tem alguma lógica e não é feito de forma excessivamente caótica).
Isso pode ser tão simples quanto criar um script executável pelo comando AWS CLI com os parâmetros necessários para integrar com sucesso uma nova entidade à plataforma. Pode até ser uma série de scripts CLI, executáveis em alguma ordem específica, como, por exemplo:
- create_new_bucket(<ENV>,<ENV_VALUE>,<PAÍS>,<PAÍS_VALOR>, ..)
- create_new_tag(<bucket_id>,<tag_name>,<tag_value>)
- update_existing_tag(<bucket_id>,<tag_name>,<tag_value>)
- create_user_group(<user_type>,<país>,<env>)
- etc.
Você entendeu.
Uma dica profissional
Há uma dica profissional, se você quiser, que pode ser facilmente aplicada em cima da anterior.
As políticas dinâmicas podem ser aproveitadas não apenas para atribuir direitos de acesso para locais de pasta, mas também para atribuir direitos de serviço para os depósitos e grupos de usuários automaticamente!
Tudo o que seria necessário seria estender a lista de tags nos depósitos e, em seguida, adicionar direitos de acesso de política dinâmica para usar serviços específicos para grupos concretos de usuários.
Por exemplo, pode haver algum grupo de usuários que também precise de acesso ao servidor de cluster de banco de dados específico. Isso pode, sem dúvida, ser alcançado por políticas dinâmicas que aproveitam tarefas de balde, ainda mais se os acessos aos serviços forem conduzidos por uma abordagem baseada em função. Basta adicionar ao código da política dinâmica uma parte que processará tags relacionadas à especificação do cluster de banco de dados e atribuirá os privilégios de acesso à política a esse cluster de banco de dados específico e grupo de usuários diretamente.
Desta forma, a integração de um novo grupo de usuários será executável apenas por esta única política dinâmica. Além disso, por ser dinâmico, a mesma política pode ser reutilizada para integrar muitos grupos de usuários diferentes (espera-se que sigam o mesmo modelo, mas não necessariamente os mesmos serviços).
Você também pode dar uma olhada nestes Comandos S3 da AWS para gerenciar baldes e dados.