
Jak zsynchronizować lokalną bazę danych Oracle z AWS
Opublikowany: 2023-01-11Obserwując rozwój oprogramowania korporacyjnego z pierwszego rzędu od dwóch dekad, widać niezaprzeczalny trend ostatnich kilku lat – przenoszenie baz danych do chmury.
Byłem już zaangażowany w kilka projektów migracyjnych, których celem było przeniesienie istniejącej bazy danych on-premise do bazy danych Amazon Web Services (AWS) Cloud. O ile z materiałów dokumentacji AWS dowiesz się, jakie to może być proste, o tyle powiem Ci, że realizacja takiego planu nie zawsze jest łatwa i zdarzają się przypadki, w których może się nie udać.

W tym poście omówię rzeczywiste doświadczenia w następującym przypadku:
- Źródło : Chociaż w teorii tak naprawdę nie ma znaczenia, jakie jest twoje źródło (możesz zastosować bardzo podobne podejście do większości najpopularniejszych baz danych), Oracle przez wiele lat był wybieranym systemem baz danych w dużych firmach korporacyjnych, a na tym się skupię.
- Cel : Nie ma powodu, aby być konkretnym po tej stronie. Możesz wybrać dowolną docelową bazę danych w AWS, a podejście nadal będzie pasować.
- Tryb : Możesz mieć pełne odświeżenie lub odświeżanie przyrostowe. Ładowanie danych wsadowych (stany źródłowe i docelowe są opóźnione) lub (prawie) ładowanie danych w czasie rzeczywistym. Oba zostaną tutaj poruszone.
- Częstotliwość : Możesz potrzebować jednorazowej migracji, po której następuje pełne przejście do chmury lub wymagać pewnego okresu przejściowego i jednoczesnej aktualizacji danych po obu stronach, co oznacza rozwijanie codziennej synchronizacji między lokalną a AWS. Ta pierwsza jest prostsza i ma o wiele większy sens, ale ta druga jest częściej wymagana i ma znacznie więcej punktów przerwania. Omówię tutaj oba.
opis problemu
Wymóg jest często prosty:
Chcemy zacząć rozwijać usługi wewnątrz AWS, dlatego prosimy o skopiowanie wszystkich naszych danych do bazy „ABC”. Szybko i prosto. Musimy teraz użyć danych w AWS. Później ustalimy, które części projektów DB należy zmienić, aby pasowały do naszych działań.
Zanim przejdziemy dalej, jest coś do rozważenia:
- Nie wpadaj zbyt szybko w ideę „po prostu skopiuj to, co mamy i zajmij się tym później”. To znaczy, tak, jest to najłatwiejsze, co możesz zrobić, i zostanie to zrobione szybko, ale może to stworzyć tak fundamentalny problem architektoniczny, którego później nie będzie można naprawić bez poważnej refaktoryzacji większości nowej platformy chmurowej . Wyobraź sobie, że ekosystem chmurowy jest zupełnie inny niż on-premise. Z czasem zostanie wprowadzonych kilka nowych usług. Oczywiście ludzie zaczną używać tego samego w bardzo różny sposób. Prawie nigdy nie jest dobrym pomysłem replikowanie stanu lokalnego w chmurze w skali 1:1. Może tak być w twoim konkretnym przypadku, ale pamiętaj, aby to dokładnie sprawdzić.
- Zakwestionuj wymaganie, podając kilka znaczących wątpliwości, takich jak:
- Kto będzie typowym użytkownikiem korzystającym z nowej platformy? Lokalnie może to być transakcyjny użytkownik biznesowy; w chmurze może to być analityk danych lub analityk hurtowni danych, albo głównym użytkownikiem danych może być usługa (np. Databricks, Glue, modele uczenia maszynowego itp.).
- Czy oczekuje się, że zwykłe codzienne zadania zostaną utrzymane nawet po przejściu do chmury? Jeśli nie, to jak mają się zmienić?
- Planujesz znaczny wzrost ilości danych w czasie? Najprawdopodobniej odpowiedź brzmi „tak”, ponieważ często jest to najważniejszy powód migracji do chmury. Nowy model danych powinien być na to gotowy.
- Spodziewaj się, że użytkownik końcowy pomyśli o ogólnych, przewidywanych zapytaniach, które nowa baza danych otrzyma od użytkowników. To określi, jak bardzo należy zmienić istniejący model danych, aby zachować adekwatność do wydajności.
Konfigurowanie migracji
Po wybraniu docelowej bazy danych i satysfakcjonującym omówieniu modelu danych, kolejnym krokiem jest zapoznanie się z AWS Schema Conversion Tool. Istnieje kilka obszarów, w których to narzędzie może służyć:
- Przeanalizuj i wyodrębnij źródłowy model danych. SCT odczyta, co znajduje się w aktualnej lokalnej bazie danych i na początek wygeneruje źródłowy model danych.
- Zaproponuj docelową strukturę modelu danych na podstawie docelowej bazy danych.
- Wygeneruj skrypty wdrażania docelowej bazy danych, aby zainstalować docelowy model danych (na podstawie tego, co narzędzie wykryło ze źródłowej bazy danych). Spowoduje to wygenerowanie skryptów wdrożeniowych, a po ich wykonaniu baza danych w chmurze będzie gotowa do ładowania danych z bazy on-premise.
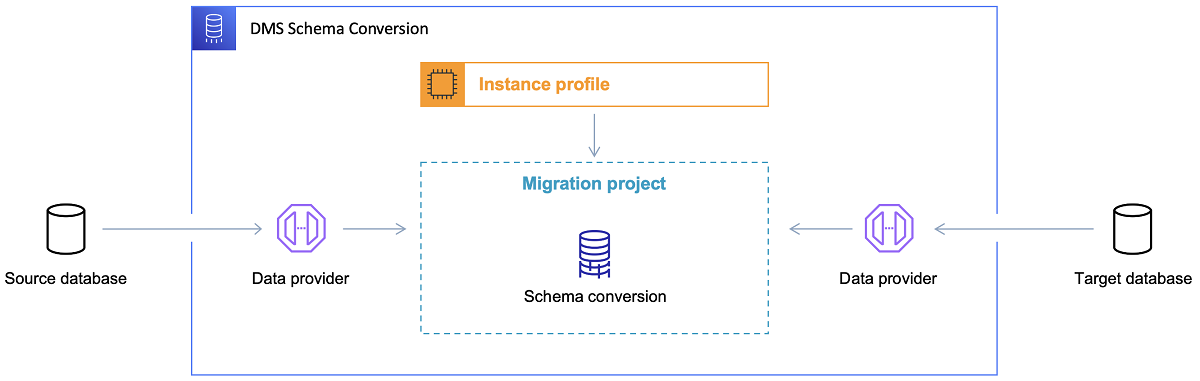
Oto kilka wskazówek dotyczących korzystania z narzędzia do konwersji schematów.
Po pierwsze, prawie nigdy nie powinno być bezpośredniego użycia danych wyjściowych. Uznałbym to bardziej za wyniki referencyjne, z których należy dokonać korekt w oparciu o zrozumienie i cel danych oraz sposób, w jaki dane będą wykorzystywane w chmurze.
Po drugie, wcześniej tabele były prawdopodobnie wybierane przez użytkowników oczekujących szybkich, krótkich wyników dotyczących jakiejś konkretnej jednostki domeny danych. Ale teraz dane mogą być wybrane do celów analitycznych. Na przykład indeksy baz danych, które wcześniej działały w bazie on-premise, będą teraz bezużyteczne i na pewno nie poprawią wydajności systemu DB związanego z tym nowym zastosowaniem. Podobnie możesz podzielić dane w inny sposób w systemie docelowym, niż miało to miejsce wcześniej w systemie źródłowym.
Warto również rozważyć wykonanie pewnych transformacji danych podczas procesu migracji, co zasadniczo oznacza zmianę docelowego modelu danych dla niektórych tabel (tak, aby nie były to już kopie 1:1). Później reguły transformacji będą musiały zostać zaimplementowane w narzędziu migracji.
Konfigurowanie narzędzia do migracji
Jeśli źródłowa i docelowa baza danych są tego samego typu (np. Oracle on-premise vs. Oracle w AWS, PostgreSQL vs. Aurora Postgresql itp.), najlepiej jest użyć dedykowanego narzędzia do migracji, które konkretna baza danych obsługuje natywnie ( np. eksport i import pomp danych, Oracle Goldengate itp.).
Jednak w większości przypadków źródłowa i docelowa baza danych nie będą kompatybilne, a wtedy oczywistym narzędziem do wyboru będzie usługa migracji bazy danych AWS.
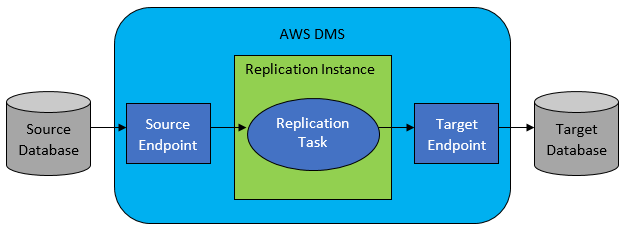
AWS DMS w zasadzie pozwala na skonfigurowanie listy zadań na poziomie tabeli, która zdefiniuje:
- Jaka jest dokładna źródłowa baza danych i tabela, z którą należy się połączyć?
- Specyfikacje instrukcji, które będą używane do uzyskiwania danych dla tabeli docelowej.
- Narzędzia transformacji (jeśli istnieją), określające sposób mapowania danych źródłowych na dane tabeli docelowej (jeśli nie 1:1).
- Jaka jest dokładna docelowa baza danych i tabela, do której mają zostać załadowane dane?
Konfiguracja zadań DMS odbywa się w jakimś przyjaznym dla użytkownika formacie, takim jak JSON.
Teraz w najprostszym scenariuszu wszystko, co musisz zrobić, to uruchomić skrypty wdrażania w docelowej bazie danych i uruchomić zadanie DMS. Ale to znacznie więcej.
Jednorazowa pełna migracja danych

Najłatwiejszym przypadkiem wykonania jest sytuacja, w której żądanie polega na jednokrotnym przeniesieniu całej bazy danych do docelowej bazy danych w chmurze. Wtedy w zasadzie wszystko, co jest konieczne do zrobienia, będzie wyglądać następująco:

- Zdefiniuj zadanie DMS dla każdej tabeli źródłowej.
- Upewnij się, że poprawnie określiłeś konfigurację zadań DMS. Oznacza to ustawienie rozsądnej równoległości, buforowanie zmiennych, konfigurację serwera DMS, określenie rozmiaru klastra DMS itp. Jest to zwykle najbardziej czasochłonna faza, ponieważ wymaga szeroko zakrojonych testów i dostrojenia optymalnego stanu konfiguracji.
- Upewnij się, że każda tabela docelowa jest utworzona (pusta) w docelowej bazie danych w oczekiwanej strukturze tabeli.
- Zaplanuj okno czasowe, w którym zostanie przeprowadzona migracja danych. Wcześniej oczywiście upewnij się (wykonując testy wydajnościowe), że okno czasowe będzie wystarczające do zakończenia migracji. Podczas samej migracji źródłowa baza danych może być ograniczona z punktu widzenia wydajności. Oczekuje się również, że źródłowa baza danych nie ulegnie zmianie w czasie trwania migracji. W przeciwnym razie migrowane dane mogą różnić się od danych przechowywanych w źródłowej bazie danych po zakończeniu migracji.
Jeśli konfiguracja DMS jest dobrze wykonana, w tym scenariuszu nic złego się nie wydarzy. Każda pojedyncza tabela źródłowa zostanie pobrana i skopiowana do docelowej bazy danych AWS. Jedynym zmartwieniem będzie wykonanie czynności i upewnienie się, że rozmiar jest odpowiedni na każdym kroku, aby nie zawiódł z powodu niewystarczającej przestrzeni dyskowej.
Przyrostowa dzienna synchronizacja

Tutaj sprawy zaczynają się komplikować. Mam na myśli, że gdyby świat był idealny, to prawdopodobnie działałby dobrze przez cały czas. Ale świat nigdy nie jest idealny.
DMS można skonfigurować do pracy w dwóch trybach:
- Pełne obciążenie – domyślny tryb opisany i używany powyżej. Zadania DMS są uruchamiane podczas ich uruchamiania lub zgodnie z harmonogramem. Po zakończeniu zadania DMS są zakończone.
- Change Data Capture (CDC) – w tym trybie zadania DMS działają w sposób ciągły. DMS skanuje źródłową bazę danych w poszukiwaniu zmian na poziomie tabeli. Jeśli nastąpi zmiana, natychmiast próbuje zreplikować zmianę w docelowej bazie danych na podstawie konfiguracji wewnątrz zadania DMS związanego ze zmienioną tabelą.
Decydując się na CDC, musisz dokonać jeszcze jednego wyboru – a mianowicie, w jaki sposób CDC wyodrębni zmiany delta ze źródłowej bazy danych.
# 1. Czytnik dzienników ponownego wykonania Oracle
Jedną z opcji jest wybranie natywnego czytnika dzienników powtórzeń bazy danych firmy Oracle, którego CDC może użyć do pobrania zmienionych danych i, w oparciu o najnowsze zmiany, zreplikować te same zmiany w docelowej bazie danych.
Chociaż może to wyglądać na oczywisty wybór, jeśli chodzi o Oracle jako źródło, jest pewien haczyk: czytnik dzienników ponownego wykonania Oracle wykorzystuje źródłowy klaster Oracle, a więc bezpośrednio wpływa na wszystkie inne działania działające w bazie danych (w rzeczywistości bezpośrednio tworzy aktywne sesje w baza danych).
Im więcej skonfigurowałeś zadań DMS (lub im więcej równolegle klastrów DMS), tym bardziej prawdopodobnie będziesz musiał rozbudować klaster Oracle – w zasadzie dostosuj skalowanie pionowe podstawowego klastra bazy danych Oracle. Z pewnością wpłynie to na całkowity koszt rozwiązania, tym bardziej, jeśli codzienna synchronizacja ma pozostać z projektem przez długi czas.
#2. Koparka dzienników AWS DMS
W przeciwieństwie do powyższej opcji, jest to natywne rozwiązanie AWS tego samego problemu. W takim przypadku DMS nie wpływa na źródłową bazę danych Oracle DB. Zamiast tego kopiuje dzienniki powtórzeń Oracle do klastra DMS i wykonuje tam całe przetwarzanie. Chociaż oszczędza zasoby Oracle, jest wolniejszym rozwiązaniem, ponieważ wymaga większej liczby operacji. A także, jak łatwo założyć, niestandardowy czytnik dzienników powtórzeń Oracle jest prawdopodobnie wolniejszy w swojej pracy niż natywny czytnik Oracle.
W zależności od rozmiaru źródłowej bazy danych i liczby codziennych zmian w niej, w najlepszym przypadku może dojść do przyrostowej synchronizacji danych z lokalnej bazy danych Oracle z bazą danych w chmurze AWS niemalże w czasie rzeczywistym.
W innych scenariuszach nadal nie będzie to synchronizacja zbliżona do czasu rzeczywistego, ale można spróbować zbliżyć się jak najbardziej do akceptowanego opóźnienia (między źródłem a celem), dostrajając konfigurację wydajności i równoległość klastrów źródłowych i docelowych lub eksperymentując z ilość zadań DMS i ich dystrybucja pomiędzy instancje CDC.
Możesz też chcieć dowiedzieć się, które zmiany tabeli źródłowej są obsługiwane przez CDC (na przykład dodanie kolumny), ponieważ nie wszystkie możliwe zmiany są obsługiwane. W niektórych przypadkach jedynym sposobem jest ręczna zmiana tabeli docelowej i ponowne uruchomienie zadania CDC od podstaw (po drodze tracąc wszystkie istniejące dane w docelowej bazie danych).
Kiedy coś pójdzie nie tak, bez względu na wszystko

Nauczyłem się tego na własnej skórze, ale jest jeden konkretny scenariusz związany z DMS, w którym obietnica codziennej replikacji jest trudna do spełnienia.
DMS może przetwarzać dzienniki powtórzeń tylko z określoną szybkością. Nie ma znaczenia, czy istnieje więcej instancji DMS wykonujących Twoje zadania. Mimo to każda instancja DMS odczytuje logi powtórzeń tylko z jedną określoną szybkością i każda z nich musi czytać je w całości. Nie ma nawet znaczenia, czy korzystasz z dzienników przeróbek Oracle, czy eksploratora dzienników AWS. Oba mają ten limit.
Jeśli źródłowa baza danych zawiera dużą liczbę zmian w ciągu jednego dnia, a dzienniki powtórzeń Oracle stają się naprawdę szalenie duże (na przykład 500 GB + duże) każdego dnia, CDC po prostu nie zadziała. Replikacja nie zostanie zakończona przed końcem dnia. Przyniesie trochę nieprzetworzonej pracy do następnego dnia, gdzie nowy zestaw zmian do replikacji już czeka. Ilość nieprzetworzonych danych będzie rosła z dnia na dzień.
W tym konkretnym przypadku CDC nie wchodziło w grę (po wielu testach wydajnościowych i próbach, które wykonaliśmy). Jedynym sposobem, aby upewnić się, że przynajmniej wszystkie zmiany delta z bieżącego dnia zostaną zreplikowane tego samego dnia, było podejście do tego w następujący sposób:
- Oddziel naprawdę duże tabele, które nie są tak często używane i powielaj je tylko raz w tygodniu (np. w weekendy).
- Skonfiguruj replikację niezbyt dużych, ale wciąż dużych tabel do podziału między kilka zadań DMS; jedna tabela została ostatecznie zmigrowana przez 10 lub więcej oddzielnych zadań DMS równolegle, zapewniając odrębny podział danych między zadaniami DMS (w tym przypadku dotyczy to niestandardowego kodowania) i wykonywanie ich codziennie.
- Dodaj więcej (w tym przypadku do 4) instancji DMS i podziel równomiernie zadania DMS między nie, co oznacza nie tylko liczbę tabel, ale także rozmiar.
Zasadniczo używaliśmy trybu pełnego obciążenia systemu DMS do codziennej replikacji danych, ponieważ był to jedyny sposób na osiągnięcie zakończenia replikacji danych co najmniej tego samego dnia.
Nie jest to idealne rozwiązanie, ale nadal istnieje i nawet po wielu latach nadal działa w ten sam sposób. Więc może wcale nie takie złe rozwiązanie.