
Obsługa maszyny wektorowej (SVM) w uczeniu maszynowym
Opublikowany: 2023-01-04Support Vector Machine to jeden z najpopularniejszych algorytmów uczenia maszynowego. Jest wydajny i może trenować w ograniczonych zestawach danych. Ale co to jest?
Co to jest maszyna wektorów nośnych (SVM)?
Maszyna wektorów nośnych to algorytm uczenia maszynowego, który wykorzystuje uczenie nadzorowane do stworzenia modelu klasyfikacji binarnej. To jest bułka z masłem. Ten artykuł wyjaśni SVM i jego związek z przetwarzaniem języka naturalnego. Ale najpierw przeanalizujmy, jak działa maszyna wektorów nośnych.
Jak działa SVM?
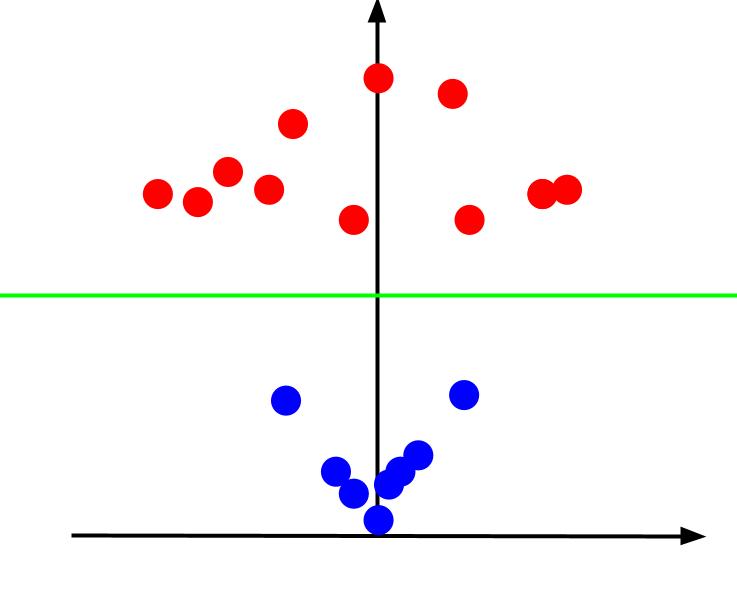
Rozważmy prosty problem klasyfikacji, w którym mamy dane, które mają dwie cechy, x i y, oraz jedno wyjście — klasyfikację, która jest albo czerwona, albo niebieska. Możemy wykreślić wyimaginowany zestaw danych, który wygląda tak:
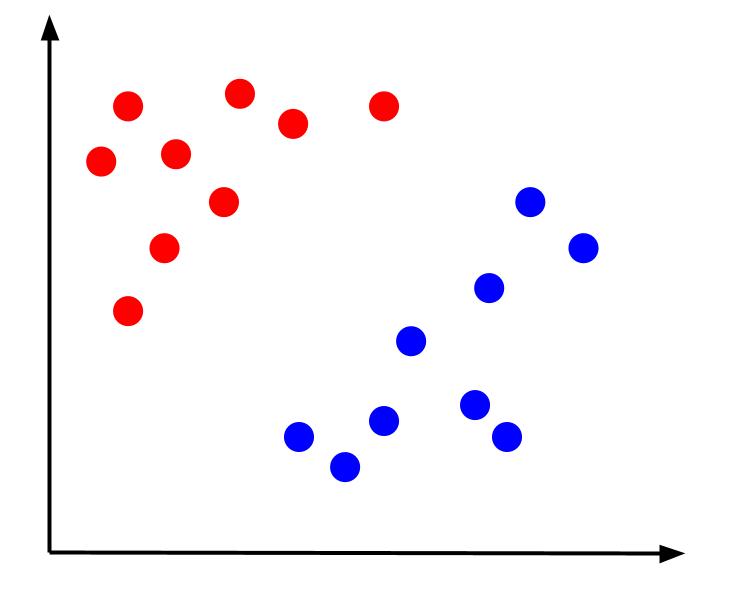
Mając takie dane, zadaniem byłoby stworzenie granicy decyzyjnej. Granica decyzyjna to linia oddzielająca dwie klasy naszych punktów danych. To jest ten sam zestaw danych, ale z granicą decyzyjną:
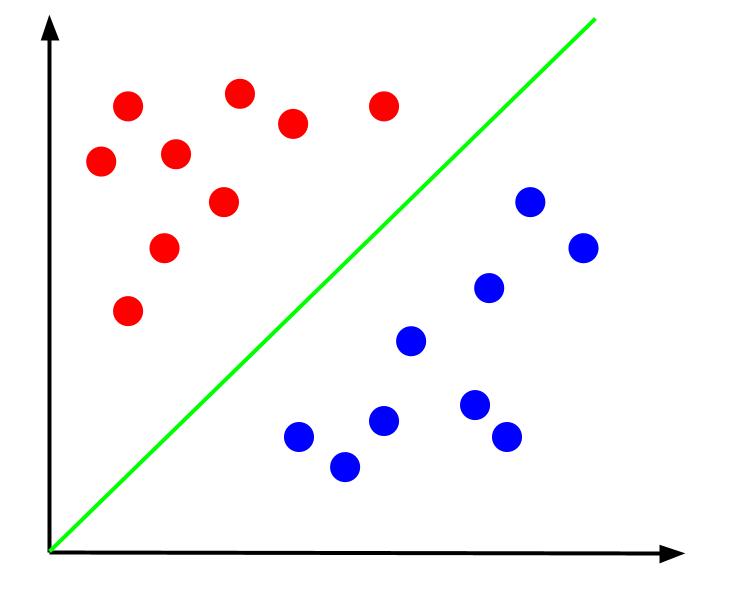
Dzięki tej granicy decyzyjnej możemy następnie przewidywać, do której klasy należy punkt danych, biorąc pod uwagę, gdzie leży względem granicy decyzyjnej. Algorytm maszyny wektorów nośnych tworzy najlepszą granicę decyzyjną, która zostanie wykorzystana do sklasyfikowania punktów.
Ale co rozumiemy przez granicę najlepszej decyzji?
Można argumentować, że najlepszą granicą decyzyjną jest ta, która maksymalizuje swoją odległość od jednego z wektorów wsparcia. Wektory nośne to punkty danych jednej z klas najbliżej klasy przeciwnej. Te punkty danych stwarzają największe ryzyko błędnej klasyfikacji ze względu na ich bliskość do innej klasy.
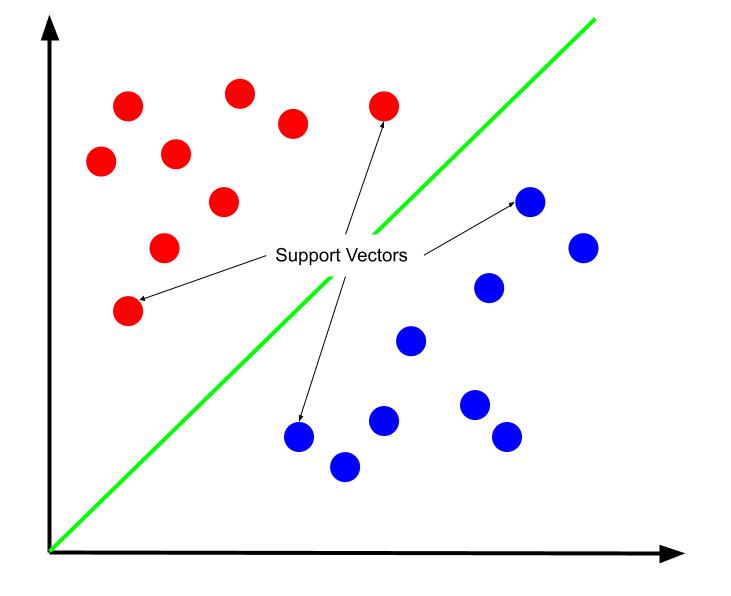
Uczenie maszyny wektorów nośnych polega zatem na próbie znalezienia linii, która maksymalizuje margines między wektorami nośnymi.
Należy również zauważyć, że ponieważ granica decyzyjna jest położona względem wektorów wsparcia, są one jedynymi wyznacznikami położenia granicy decyzyjnej. Pozostałe punkty danych są zatem zbędne. A zatem szkolenie wymaga tylko wektorów wsparcia.
W tym przykładzie utworzona granica decyzyjna jest linią prostą. Dzieje się tak tylko dlatego, że zestaw danych ma tylko dwie funkcje. Gdy zbiór danych ma trzy cechy, utworzona granica decyzyjna jest płaszczyzną, a nie linią. A kiedy ma cztery lub więcej cech, granica decyzyjna jest znana jako hiperpłaszczyzna.
Dane nierozdzielne liniowo
W powyższym przykładzie uwzględniono bardzo proste dane, które po wykreśleniu można oddzielić liniową granicą decyzyjną. Rozważmy inny przypadek, w którym dane są wykreślane w następujący sposób:
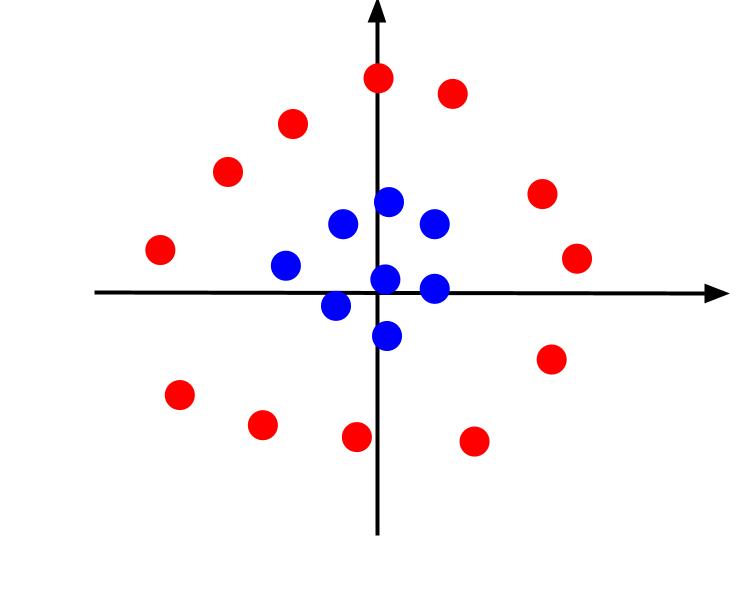
W takim przypadku oddzielenie danych za pomocą linii jest niemożliwe. Ale możemy stworzyć inną cechę, z. A cechę tę można opisać równaniem: z = x^2 + y^2. Możemy dodać z jako trzecią oś do płaszczyzny, aby uczynić ją trójwymiarową.
Kiedy spojrzymy na wykres 3D pod takim kątem, że oś x jest pozioma, a oś z pionowa, otrzymamy widok, który wygląda mniej więcej tak:
Wartość z określa, jak daleko punkt znajduje się od początku względem innych punktów na starej płaszczyźnie XY. W rezultacie niebieskie punkty bliżej początku układu mają niskie wartości z.
Podczas gdy czerwone punkty dalej od początku miały wyższe wartości z, wykreślenie ich w stosunku do ich wartości z daje nam wyraźną klasyfikację, którą można wyznaczyć liniową granicą decyzyjną, jak pokazano na ilustracji.
Jest to potężny pomysł, który jest używany w maszynach wektorów nośnych. Mówiąc bardziej ogólnie, chodzi o odwzorowanie wymiarów na większą liczbę wymiarów, tak aby punkty danych można było oddzielić liniową granicą. Funkcje, które są za to odpowiedzialne, to funkcje jądra. Istnieje wiele funkcji jądra, takich jak sigmoidalna, liniowa, nieliniowa i RBF.
Aby mapowanie tych funkcji było bardziej wydajne, SVM wykorzystuje sztuczkę jądra.
SVM w uczeniu maszynowym
Support Vector Machine to jeden z wielu algorytmów wykorzystywanych w uczeniu maszynowym obok popularnych algorytmów, takich jak drzewa decyzyjne i sieci neuronowe. Jest preferowany, ponieważ działa dobrze z mniejszą ilością danych niż inne algorytmy. Jest powszechnie używany do wykonywania następujących czynności:
- Klasyfikacja tekstu : Klasyfikacja danych tekstowych, takich jak komentarze i recenzje, w jednej lub kilku kategoriach
- Wykrywanie twarzy : analizowanie obrazów w celu wykrycia twarzy w celu na przykład dodania filtrów do rzeczywistości rozszerzonej
- Klasyfikacja obrazu : Maszyny wektorów nośnych mogą skutecznie klasyfikować obrazy w porównaniu z innymi podejściami.
Problem klasyfikacji tekstu
Internet jest wypełniony mnóstwem danych tekstowych. Jednak wiele z tych danych jest nieustrukturyzowanych i nieoznakowanych. Aby lepiej wykorzystać te dane tekstowe i lepiej je zrozumieć, istnieje potrzeba klasyfikacji. Przykłady sytuacji, w których tekst jest klasyfikowany, obejmują:
- Kiedy tweety są podzielone na tematy, aby ludzie mogli śledzić interesujące ich tematy
- Gdy e-mail zostanie sklasyfikowany jako Społeczności, Oferty lub Spam
- Kiedy komentarze są klasyfikowane jako nienawistne lub obsceniczne na forach publicznych
Jak SVM współpracuje z klasyfikacją języka naturalnego
Maszyna wektorów nośnych służy do klasyfikowania tekstu na tekst należący do określonego tematu i tekst, który nie należy do tematu. Osiąga się to najpierw poprzez konwersję i reprezentację danych tekstowych w zestaw danych z kilkoma funkcjami.
Jednym ze sposobów na to jest utworzenie funkcji dla każdego słowa w zbiorze danych. Następnie dla każdego punktu danych tekstowych rejestrujesz liczbę wystąpień każdego słowa. Załóżmy więc, że w zbiorze danych występują unikalne słowa; będziesz mieć funkcje w zbiorze danych.
Dodatkowo podasz klasyfikacje dla tych punktów danych. Chociaż te klasyfikacje są oznaczone tekstem, większość implementacji SVM wymaga etykiet numerycznych.
Dlatego przed treningiem będziesz musiał przekonwertować te etykiety na liczby. Po przygotowaniu zestawu danych przy użyciu tych funkcji jako współrzędnych można następnie użyć modelu SVM do sklasyfikowania tekstu.
Tworzenie SVM w Pythonie
Aby utworzyć maszynę wektorów nośnych (SVM) w Pythonie, możesz użyć klasy SVC z biblioteki sklearn.svm . Oto przykład wykorzystania klasy SVC do zbudowania modelu SVM w Pythonie:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) W tym przykładzie najpierw importujemy klasę SVC z biblioteki sklearn.svm . Następnie ładujemy zestaw danych i dzielimy go na zestawy treningowe i testowe.
Następnie tworzymy model SVM, tworząc instancję obiektu SVC i określając parametr kernel jako „liniowy”. Następnie szkolimy model na danych treningowych za pomocą metody fit i oceniamy model na danych testowych za pomocą metody score . Metoda score zwraca dokładność modelu, którą drukujemy na konsoli.
Możesz także określić inne parametry obiektu SVC , takie jak parametr C , który kontroluje siłę regularyzacji, oraz parametr gamma , który kontroluje współczynnik jądra dla niektórych jąder.
Korzyści z SVM
Oto lista niektórych korzyści płynących z używania maszyn wektorów nośnych (SVM):
- Wydajny : maszyny SVM są ogólnie wydajne w trenowaniu, zwłaszcza gdy liczba próbek jest duża.
- Odporny na szum : SVM są stosunkowo odporne na szum w danych treningowych, ponieważ próbują znaleźć klasyfikator maksymalnego marginesu, który jest mniej wrażliwy na szum niż inne klasyfikatory.
- Efektywne pod względem pamięci: maszyny SVM wymagają, aby w danym momencie w pamięci znajdował się tylko podzbiór danych treningowych, co czyni je bardziej wydajnymi pod względem pamięci niż inne algorytmy.
- Efektywne w przestrzeniach wielowymiarowych: maszyny SVM mogą nadal działać dobrze, nawet jeśli liczba funkcji przekracza liczbę próbek.
- Wszechstronność : maszyn SVM można używać do zadań związanych z klasyfikacją i regresją oraz obsługiwać różne typy danych, w tym dane liniowe i nieliniowe.
Teraz przyjrzyjmy się niektórym z najlepszych zasobów do nauki maszyny wektorów pomocniczych (SVM).

Zasoby edukacyjne
Wprowadzenie do maszyn wektorów nośnych
Ta książka na temat Wprowadzenie do maszyn wektorów pomocniczych kompleksowo i stopniowo wprowadza Cię w metody uczenia się oparte na jądrze.
| Zapowiedź | Produkt | Ocena | Cena | |
|---|---|---|---|---|
 | Wprowadzenie do maszyn wektorów pomocniczych i innych metod uczenia się opartych na jądrze | 75,00 $ | Kup na Amazonie |
Daje solidne podstawy w teorii maszyn wektorów nośnych.
Wsparcie aplikacji maszyn wektorowych
Podczas gdy pierwsza książka skupiała się na teorii maszyn wektorów nośnych, ta książka o zastosowaniach maszyn wektorów nośnych koncentruje się na ich praktycznych zastosowaniach.
| Zapowiedź | Produkt | Ocena | Cena | |
|---|---|---|---|---|
 | Wsparcie aplikacji maszyn wektorowych | 15,52 $ | Kup na Amazonie |
Sprawdza, w jaki sposób maszyny SVM są wykorzystywane w przetwarzaniu obrazu, wykrywaniu wzorców i wizji komputerowej.
Maszyny wektorów pomocniczych (informatyka i statystyka)
Celem tej książki o maszynach wektorów nośnych (informatyka i statystyka) jest przedstawienie przeglądu zasad leżących u podstaw skuteczności maszyn wektorów nośnych (SVM) w różnych zastosowaniach.
| Zapowiedź | Produkt | Ocena | Cena | |
|---|---|---|---|---|
 | Maszyny wektorów pomocniczych (informatyka i statystyka) | 167,36 $ | Kup na Amazonie |
Autorzy zwracają uwagę na kilka czynników, które przyczyniają się do sukcesu maszyn SVM, w tym ich zdolność do dobrego działania przy ograniczonej liczbie regulowanych parametrów, ich odporność na różnego rodzaju błędy i anomalie oraz ich wydajną wydajność obliczeniową w porównaniu z innymi metodami.
Nauka z jądrami
„Learning with Kernels” to książka, która wprowadza czytelników do obsługi maszyn wektorowych (SVM) i powiązanych technik jądra.
| Zapowiedź | Produkt | Ocena | Cena | |
|---|---|---|---|---|
 | Nauka z jądrami: maszyny wektorów pomocniczych, regularyzacja, optymalizacja i nie tylko (adaptacyjne… | 80,00 $ | Kup na Amazonie |
Został zaprojektowany, aby dać czytelnikom podstawowe zrozumienie matematyki i wiedzę potrzebną do rozpoczęcia korzystania z algorytmów jądra w uczeniu maszynowym. Książka ma na celu dostarczenie dokładnego, ale przystępnego wprowadzenia do maszyn SVM i metod jądra.
Wspieraj maszyny wektorowe za pomocą Sci-kit Learn
Ten internetowy kurs Support Vector Machines with Sci-kit Learn, prowadzony przez sieć projektów Coursera, uczy, jak zaimplementować model SVM przy użyciu popularnej biblioteki uczenia maszynowego, Sci-Kit Learn.

Dodatkowo poznasz teorię stojącą za maszynami SVM oraz określisz ich mocne strony i ograniczenia. Kurs jest na poziomie początkującym i trwa około 2,5 godziny.
Wsparcie Vector Machines w Pythonie: koncepcje i kod
Ten płatny kurs online na temat maszyn wektorów pomocniczych w Pythonie autorstwa Udemy obejmuje do 6 godzin instrukcji wideo i jest dostarczany z certyfikatem.

Obejmuje maszyny SVM i sposób, w jaki można je solidnie zaimplementować w Pythonie. Ponadto obejmuje zastosowania biznesowe maszyn wektorów nośnych.
Uczenie maszynowe i sztuczna inteligencja: obsługa maszyn wektorowych w języku Python
Na tym kursie dotyczącym uczenia maszynowego i sztucznej inteligencji nauczysz się, jak używać maszyn wektorów nośnych (SVM) do różnych praktycznych zastosowań, w tym do rozpoznawania obrazów, wykrywania spamu, diagnostyki medycznej i analizy regresji.

Będziesz używać języka programowania Python do implementacji modeli ML dla tych aplikacji.
Ostatnie słowa
W tym artykule dowiedzieliśmy się pokrótce o teorii stojącej za maszynami wektorów nośnych. Dowiedzieliśmy się o ich zastosowaniu w uczeniu maszynowym i przetwarzaniu języka naturalnego.
Zobaczyliśmy też, jak wygląda jego implementacja z wykorzystaniem scikit-learn . Ponadto rozmawialiśmy o praktycznych zastosowaniach i zaletach maszyn wektorów nośnych.
Chociaż ten artykuł był tylko wprowadzeniem, dodatkowe zasoby zalecały bardziej szczegółowe wyjaśnienie, wyjaśniając więcej o maszynach wektorów nośnych. Biorąc pod uwagę ich wszechstronność i wydajność, maszyny SVM warto zrozumieć, aby rozwijać się jako naukowiec zajmujący się danymi i inżynier ML.
Następnie możesz sprawdzić najlepsze modele uczenia maszynowego.