
Jak stworzyć Pandas DataFrame [z przykładami]
Opublikowany: 2022-12-08Poznaj podstawy pracy z pandami DataFrames: podstawową strukturą danych w pandach, potężną biblioteką do manipulacji danymi.
Jeśli chcesz rozpocząć pracę z analizą danych w Pythonie, pandas jest jedną z pierwszych bibliotek, z którymi powinieneś nauczyć się pracować. Od importowania danych z wielu źródeł, takich jak pliki CSV i bazy danych, po obsługę brakujących danych i analizowanie ich w celu uzyskania wglądu – pandy pozwalają Ci wykonać wszystkie powyższe czynności.
Aby rozpocząć analizowanie danych za pomocą pand, powinieneś zrozumieć podstawową strukturę danych w pandach: ramki danych .
W tym samouczku poznasz podstawy ramek danych Pandas i typowe metody tworzenia ramek danych. Następnie dowiesz się, jak wybierać wiersze i kolumny z ramki danych w celu pobierania podzbiorów danych.
To wszystko i więcej, zaczynajmy.
Instalowanie i importowanie Pand
Ponieważ pandas to zewnętrzna biblioteka do analizy danych, należy ją najpierw zainstalować. Zaleca się instalowanie zewnętrznych pakietów w środowisku wirtualnym dla twojego projektu.
Jeśli używasz dystrybucji Anaconda Pythona, możesz użyć conda do zarządzania pakietami.
conda install pandasMożesz także zainstalować pandy za pomocą pip:
pip install pandasBiblioteka pandas wymaga NumPy jako zależności. Więc jeśli NumPy nie jest jeszcze zainstalowany, zostanie również zainstalowany podczas procesu instalacji.
Po zainstalowaniu pandy możesz zaimportować ją do swojego środowiska pracy. Ogólnie pandy są importowane pod aliasem pd :
import pandas as pdCo to jest DataFrame w Pandach?

Podstawową strukturą danych w pandach jest ramka danych . Ramka danych to dwuwymiarowa tablica danych z indeksem i nazwanymi kolumnami . Każda kolumna w ramce danych zwanej serią pand ma wspólny indeks.
Oto przykładowa ramka danych, którą utworzymy od podstaw w ciągu najbliższych kilku minut. Ta ramka danych zawiera dane o tym, ile sześciu uczniów wydaje w ciągu czterech tygodni.

Nazwiska uczniów są etykietami wierszy. Kolumny mają nazwy od „Tydzień 1” do „Tydzień 4”. Zwróć uwagę, że wszystkie kolumny mają ten sam zestaw etykiet wierszy, zwany także indeksem .
Jak utworzyć ramkę danych Pandas
Ramkę danych pandy można utworzyć na kilka sposobów. W tym samouczku omówimy następujące metody:
- Tworzenie ramki danych z tablic NumPy
- Tworzenie ramki danych ze słownika Pythona
- Tworzenie ramki danych poprzez wczytywanie plików CSV
Z tablic NumPy
Utwórzmy ramkę danych z tablicy NumPy.
Utwórzmy tablicę danych o kształcie (6,4), zakładając, że w dowolnym tygodniu każdy uczeń wydaje od 0 do 100 USD. Funkcja randint() z random modułu NumPy zwraca tablicę losowych liczb całkowitych w zadanym przedziale [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Aby utworzyć ramkę danych pandy, możesz użyć konstruktora DataFrame i przekazać tablicę NumPy jako argument data , jak pokazano:
students_df = pd.DataFrame(data=data) Teraz możemy wywołać wbudowaną funkcję type() w celu sprawdzenia typu students_df . Widzimy, że jest to obiekt DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 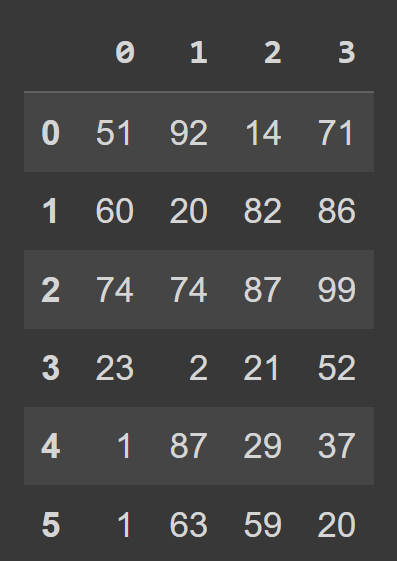
Widzimy, że domyślnie mamy indeksowanie zakresu, które przechodzi od 0 do numRows – 1, a etykiety kolumn to 0, 1, 2, …, numCols -1. Zmniejsza to jednak czytelność. Pomoże to dodać opisowe nazwy kolumn i etykiety wierszy do ramki danych.
Utwórzmy dwie listy: jedną do przechowywania nazwisk uczniów, a drugą do przechowywania etykiet kolumn.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] Podczas wywoływania konstruktora DataFrame można ustawić index i columns odpowiednio na listy etykiet wierszy i etykiet kolumn do użycia.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Mamy teraz ramkę danych students_df z opisowymi etykietami wierszy i kolumn.
print(students_df) 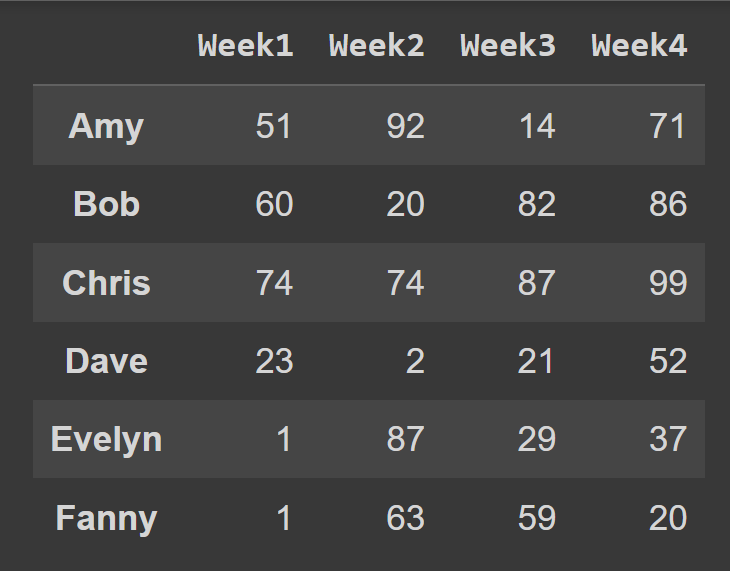
Aby uzyskać podstawowe informacje o ramce danych, takie jak brakujące wartości i typy danych, można wywołać metodę info() na obiekcie ramki danych.
students_df.info() 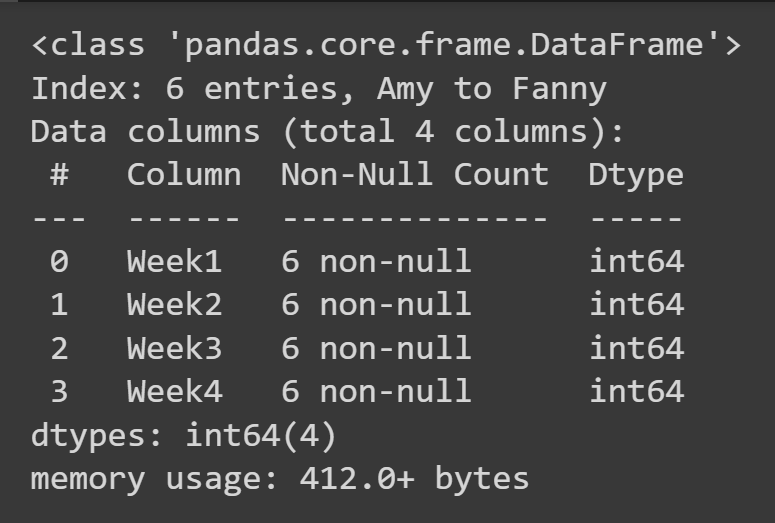
Ze słownika Pythona
Możesz także utworzyć ramkę danych pandas ze słownika Pythona.
Tutaj data_dict to słownik zawierający dane ucznia:
- Imiona uczniów są kluczami.
- Każda wartość to lista wydatków każdego ucznia od pierwszego do czwartego tygodnia.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Aby utworzyć ramkę danych ze słownika Pythona, użyj from_dict , jak pokazano poniżej. Pierwszy argument odpowiada słownikowi zawierającemu dane ( data_dict ). Domyślnie klucze są używane jako nazwy kolumn ramki danych. Ponieważ chcielibyśmy ustawić klucze jako etykiety wierszy , ustaw orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 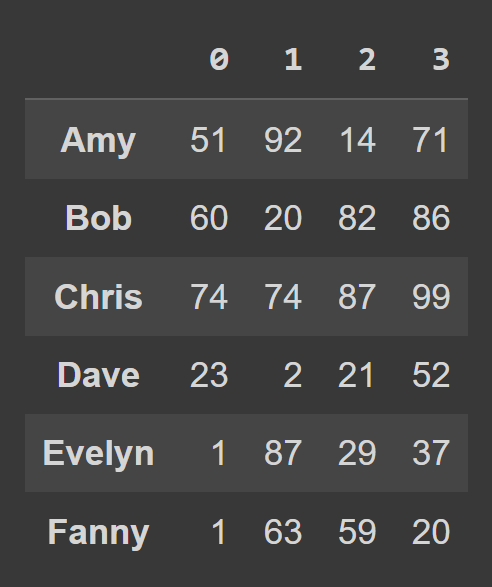
Aby zmienić nazwy kolumn na numer tygodnia, ustawiamy kolumny na listę cols :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 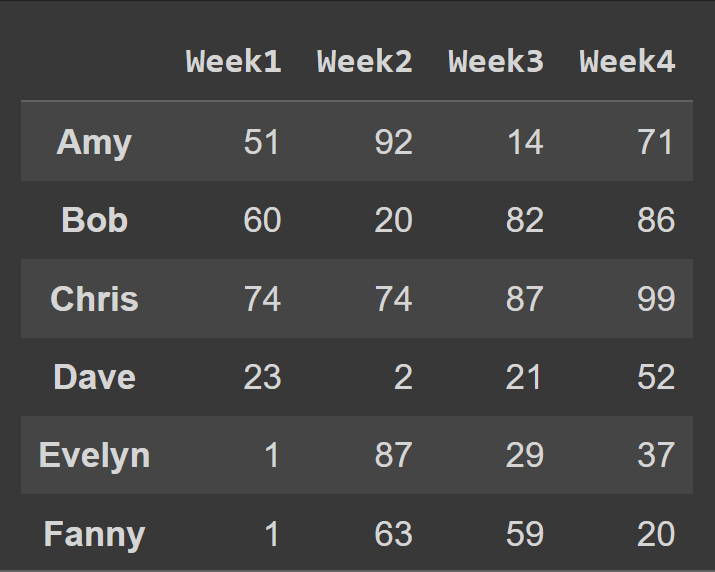
Wczytaj plik CSV do ramki danych Pandas
Załóżmy, że dane ucznia są dostępne w pliku CSV. Możesz użyć funkcji read_csv() do wczytania danych z pliku do ramki danych pandas. pd.read_csv('file-path') to ogólna składnia, gdzie file-path to ścieżka do pliku CSV. Możemy ustawić parametr names na listę nazw kolumn do użycia.
students_df = pd.read_csv('/content/students.csv',names=cols)Teraz, gdy wiemy już, jak utworzyć ramkę danych, nauczmy się zaznaczać wiersze i kolumny.
Wybierz kolumny z Pandas DataFrame
Istnieje kilka wbudowanych metod, których można użyć do wybrania wierszy i kolumn z ramki danych. W tym samouczku omówimy najczęstsze sposoby wybierania kolumn, wierszy oraz zarówno wierszy, jak i kolumn z ramki danych.
Wybór pojedynczej kolumny
Aby wybrać pojedynczą kolumnę, możesz użyć df_name[col_name] , gdzie col_name to ciąg znaków oznaczający nazwę kolumny.
Tutaj wybieramy tylko kolumnę „Tydzień 1”.
week1_df = students_df['Week1'] print(week1_df) 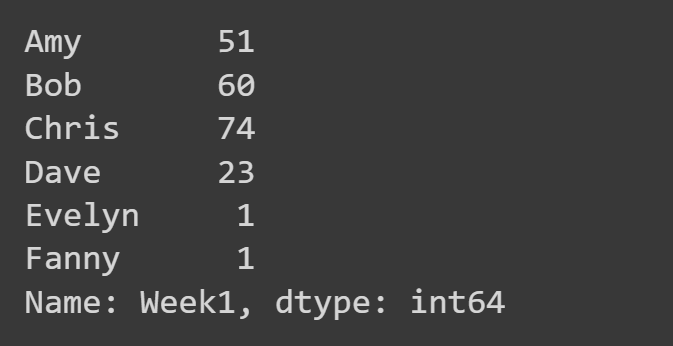
Wybieranie wielu kolumn
Aby wybrać wiele kolumn z ramki danych, przekaż listę wszystkich nazw kolumn do wybrania.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 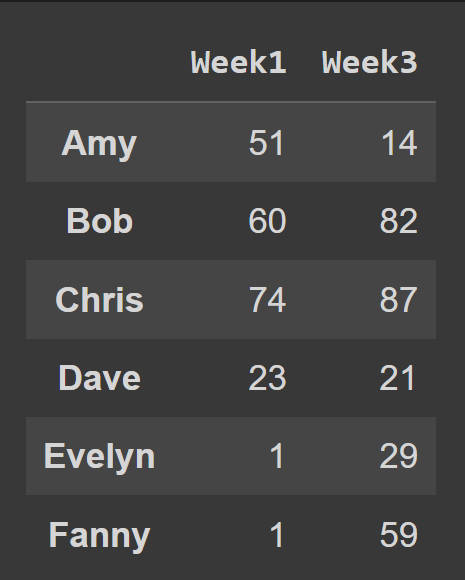
Oprócz tej metody możesz także użyć iloc() i loc() do wybierania kolumn. Później zakodujemy przykład.
Wybierz wiersze z Pandas DataFrame

Korzystanie z metody .iloc().
Aby wybrać wiersze za pomocą metody iloc() , przekaż indeksy odpowiadające wszystkim wierszom jako listę.
W tym przykładzie wybieramy wiersze o nieparzystym indeksie.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 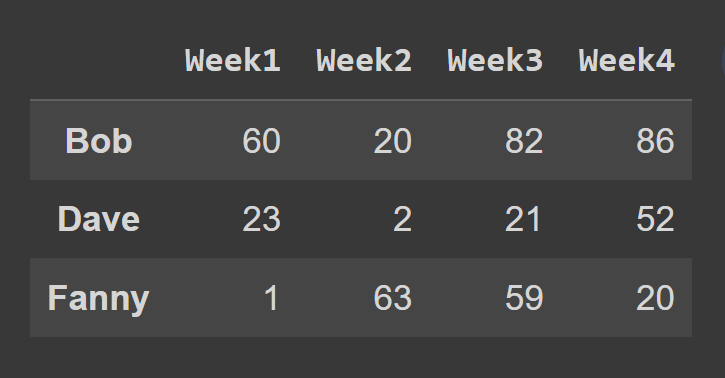
Następnie wybieramy podzbiór ramki danych zawierający wiersze o indeksach od 0 do 2, punkt końcowy 3 jest domyślnie wykluczony.
slice1 = students_df.iloc[0:3] print(slice1) 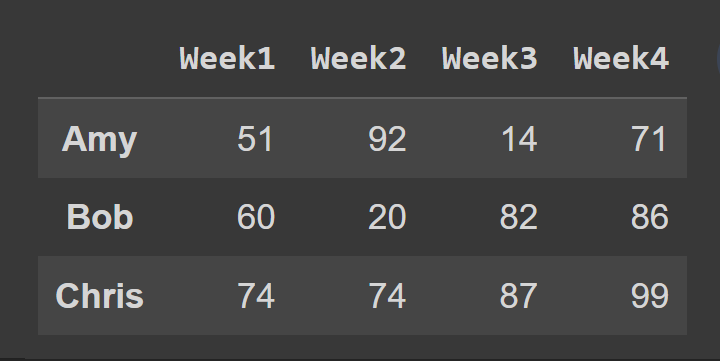
Korzystanie z metody .loc().
Aby wybrać wiersze ramki danych za pomocą metody loc() , należy określić etykiety odpowiadające wierszom, które mają zostać wybrane.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 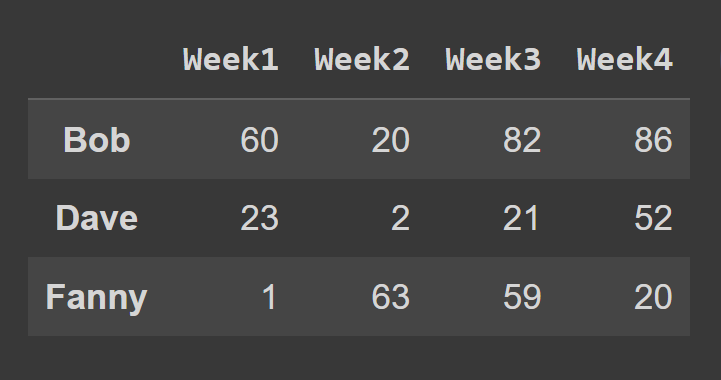
Jeśli wiersze ramki danych są indeksowane przy użyciu domyślnego zakresu 0, 1, 2, aż do
numRows-1, wówczas użycieiloc()iloc()są równoważne.
Wybierz wiersze i kolumny z Pandas DataFrame
Do tej pory nauczyłeś się, jak wybierać wiersze lub kolumny z ramki danych pandy. Jednak czasami może być konieczne wybranie podzbioru zarówno wierszy, jak i kolumn. Jak to zrobić? Możesz użyć omówionych przez nas iloc() i loc() .
Na przykład we fragmencie kodu poniżej wybieramy wszystkie wiersze i kolumny o indeksach 2 i 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 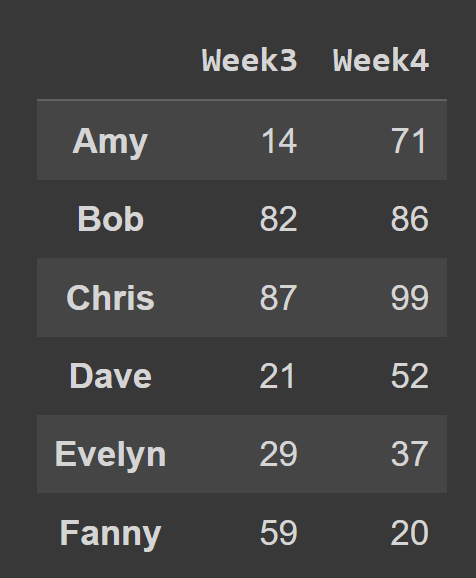
Użycie start:stop tworzy wycinek od start up do, ale bez stop . Więc jeśli zignorujesz zarówno wartości start , jak i końcowe, jeśli zignorujesz wartości początkowe i końcowe, wycinek zaczyna się od początku — i rozciąga się do stop ramki danych — zaznaczając wszystkie wiersze.
Podczas korzystania z metody loc() musisz przekazać etykiety wierszy i kolumn, które chcesz wybrać, jak pokazano na rysunku:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 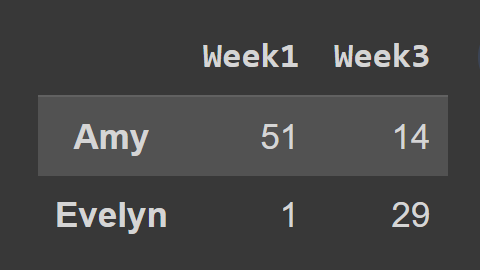
Tutaj ramka danych subset_df2 zawiera rekord Amy i Evelyn dla Tygodnia 1 i Tygodnia 3.
Wniosek
Oto krótki przegląd tego, czego nauczyłeś się w tym samouczku:
- Po zainstalowaniu pand możesz je zaimportować pod aliasem
pd. Aby utworzyć obiekt ramki danych pandas, możesz użyć konstruktorapd.DataFrame(data), gdziedataodwołują się do N-wymiarowej tablicy lub tablicy iterowalnej zawierającej dane. Możesz określić etykiety wiersza i indeksu oraz kolumny, ustawiając odpowiednio opcjonalne parametry indeksu i kolumny. - Użycie
pd.read_csv(path-to-the-file)odczytuje zawartość pliku do ramki danych. - Możesz wywołać metodę
info()na obiekcie ramki danych, aby uzyskać informacje o kolumnach, liczbie brakujących wartości, typach danych i rozmiarze ramki danych. - Aby wybrać pojedynczą kolumnę, użyj
df_name[col_name], a aby wybrać wiele kolumn, konkretną kolumnę,df_name[[col1,col2,...,coln]]. - Kolumny i wiersze można również wybierać za pomocą metod
loc()iiloc(). - Podczas gdy metoda
iloc()pobiera indeks (lub wycinek indeksu) wierszy i kolumn do wybrania, metodaloc()pobiera etykiety wierszy i kolumn.
Przykłady użyte w tym samouczku znajdziesz w tym notatniku Colab.
Następnie zapoznaj się z tą listą notatników do nauki o danych do współpracy.