
Graf wiedzy Odpowiadanie na pytania
Opublikowany: 2023-01-25Co to jest funkcja odpowiedzi na pytania Grafu wiedzy Google?
Odpowiadanie na pytania z wykresu wiedzy (KGQA) zajmuje dużo miejsca na stronach wyników wyszukiwania (SERP).
Funkcja odpowiadania na pytania Grafu wiedzy Google odpowiada na pytania użytkowników bez konieczności klikania, aby przejść do witryny internetowej.
Każda wyszukiwarka ma nadzieję, że zwróci najlepsze informacje w oparciu o intencje osoby wyszukującej. Aby być zaufanym źródłem odpowiedzi, musisz być znany w Internecie. Google rozumie strumienie zapytań i używa ich do identyfikowania tematów i wydobywania zaufanych danych z sieci w celu aktualizowania ontologii. Karty Google, wykresy wiedzy (KG) i kolekcje wiedzy to sposób interakcji użytkowników z Google. Podobnie jak „ludzie też zadają” pytania w wynikach wyszukiwania, odpowiadanie na pytania w Grafie wiedzy zatrzymuje ludzi dłużej w wynikach wyszukiwania Google.
Spis treści
- Co to jest funkcja odpowiedzi na pytania Grafu wiedzy Google?
- Jaka jest różnica między panelami wiedzy a wykresami wiedzy?
- Jaka jest różnica między panelami wiedzy a profilami firmowymi Google?
- Jaka jest różnica między panelem wiedzy Google a skarbcem wiedzy?
- Odpowiadanie na złożone pytania za pomocą uczenia maszynowego
- Jak tworzyć treści odpowiedzi na pytania, które Google uzna za pomocne
- Grafy wiedzy odpowiadają na pytania związane z danymi
- Kroki optymalizacji odpowiedzi na pytania KG
- Jak poprosić o aktualizację Panelu wiedzy Google?
- Odpowiadanie na pytania KG starają się dostarczać zweryfikowaną wiedzę
Najpierw ustalmy podstawowe słownictwo.
Jaka jest różnica między panelami wiedzy a wykresami wiedzy?
Wykresy wiedzy mogą być pozyskiwane w celu zapewnienia bogatszych paneli wiedzy w wynikach wyszukiwania i zwracania odpowiedzi na zapytania.
Pomaga postrzegać panele wiedzy jako front-endową manifestację Grafu wiedzy Google. Więcej danych kryje się za tym, co widzimy w danych wykresu panelowego. Gdy utworzysz Graf wiedzy, Google będzie na nim polegać i uzna go za kanoniczne źródło informacji. Gigant technologiczny nie wymyślił KG jako dodatku do doświadczeń użytkowników komputerów stacjonarnych; była to odpowiedź na potrzebę lepszych odpowiedzi na zapytania mobilne. Tak wiele witryn było (i nadal jest) okropnych na urządzeniach mobilnych. GKG zamierza dostarczać swoim użytkownikom dokładnych informacji; jego głównym celem nie jest kierowanie ruchu do Twojej witryny.
Wcześniej wydaje się, że Google nie klasyfikuje stron internetowych na podstawie dokładności. Obecnie osoby oceniające jakość mają więcej instrukcji dotyczących oceny doświadczenia, wiedzy fachowej, autorytatywności i wiarygodności (EEAT). Dokładność odpowiedzi jest czynnikiem zaufania, a jego wytyczne mówią nam, że zaufanie jest najważniejszym czynnikiem. Z kolei „dokładność” to czynnik, w ramach którego jednostki są wyświetlane w Panelach wiedzy.
Panele wiedzy to jeden z typów wyników z elementami rozszerzonymi na stronach wyników wyszukiwania Google. Dają wyszukiwarkom zweryfikowany przegląd informacji związanych z danym podmiotem.
Jaka jest różnica między panelami wiedzy a profilami firmowymi Google?
Profile firm Google (GBP) wyglądają prawie tak samo jak ich panele wiedzy. GBP są unikalne dla firm, które obsługują klientów w określonej lokalizacji lub w wyznaczonym obszarze usług. Dostęp w GBP pozwala właścicielom firm zarządzać swoją cyfrową obecnością w Mapach Google i wyszukiwarce. To jest bezpłatne. Z kolei Twój panel wiedzy Google (GKP) jest generowany automatycznie przez Google na podstawie informacji o Twojej jednostce online. Ma pełną kontrolę nad swoją propagacją i tym, co zdecyduje się w niej zaktualizować.
Jaka jest różnica między panelem wiedzy Google a skarbcem wiedzy?
Wyobraź sobie, że Google Knowledge Vault (GKV) jest tworzony przez algorytm generujący encyklopedię do odczytu maszynowego.
Google dodaje informacje do swojego GKV tylko wtedy, gdy ma pewność, że to, co wyświetla w panelach wiedzy, jest poprawne i przydatne. GKV opiera się wyłącznie na uczeniu maszynowym i logice maszynowej. Oddzielne jednostki z wielu domen są przenoszone do Magazynu wiedzy dopiero wtedy, gdy globalny algorytm wiedzy Google uzyska wystarczającą pewność co do zrozumienia określonej jednostki.
„…wprowadzamy Knowledge Vault, probabilistyczną bazę wiedzy na skalę internetową, która łączy ekstrakty z treści internetowych (uzyskane poprzez analizę tekstu, danych tabelarycznych, struktury strony i adnotacji ludzkich) z wcześniejszą wiedzą pochodzącą z istniejących repozytoriów wiedzy. Stosujemy nadzorowane metody uczenia maszynowego do łączenia tych różnych źródeł informacji. Magazyn wiedzy jest znacznie większy niż jakiekolwiek wcześniej opublikowane ustrukturyzowane repozytorium wiedzy i zawiera probabilistyczny system wnioskowania, który oblicza skalibrowane prawdopodobieństwa poprawności faktów”. – Skarbiec wiedzy: podejście na skalę internetową do probabilistycznego łączenia wiedzy [1]
Odpowiadanie na złożone pytania za pomocą uczenia maszynowego
Google otrzymuje codziennie 93% zapytań. Jak to tradycyjnie działa jako wyszukiwarka i kończy się na twoim produkcie lub usłudze. Aby poprawić możliwości odpowiadania na pytania, patent Google stwierdza, że: „Przetwarzanie języka naturalnego (NLP) może obejmować odpowiadanie na pytania w języku naturalnym na podstawie informacji zawartych w dokumentach w języku naturalnym”.
„Opisane techniki umożliwiają odpowiadanie na pytania w języku naturalnym przy użyciu metod opartych na uczeniu maszynowym w celu gromadzenia i analizowania dowodów z wyszukiwarek internetowych”. – [2]
Jednak przed dodaniem podmiotów do swojej bazy wiedzy Google musi najpierw algorytmicznie zrozumieć zadawane pytanie. Ma na celu zrozumienie intencji zapytania, która wywołała pytanie. W przypadku niejednoznacznych zapytań interpretacja semantyczna pomaga w udzielaniu odpowiedzi na złożone pytania i ma na celu odtworzenie ludzkiego poznania. W artykułach internetowych często nie wyświetla się data publikacji ani data ostatniej aktualizacji. Natomiast Graf wiedzy Google jest stale aktualizowany. Na przykład chciałem zacytować artykuł do tego artykułu, ale najpierw sprawdziłem i zobaczyłem „Ten artykuł ma więcej niż 3 lata”.
MarketWatch szacuje, że „branża semantycznych baz wiedzy będzie warta 33 miliardy dolarów do 2023 roku, przy wzroście rok do roku o 10% do końca dekady”. Oczekuje się, że z 18 stycznia 2023 r. Rozmiar rynku wykresów wiedzy semantycznej związany z czasem i kosztami zwiększy branżę w nadchodzących latach do 2029 r. Artykuł obejmuje wyszukiwanie semantyczne, maszynę do zadawania pytań i odpowiedzi oraz wyszukiwanie informacji.
To rozdzierające umysł, jak duży wzrost innowacji naukowych jest poświęcony lepszym KG. W równym stopniu marketerzy cyfrowi i SEO odnoszą korzyści dzięki szybkiemu dostosowaniu się.
KG są ogólnie postrzegane jako wielkoskalowe sieci semantyczne, które przechowują fakty jako trójki w postaci (podmiot, relacja, podmiot) lub (podmiot, atrybut, wartość). Krawędzie na wykresie przedstawiają relacje między tymi elementami. Większość KG jest zbudowana na różnych istniejących źródłach danych w celu łączenia danych. Dopóki GPTChat nie pojawił się w GPT3, Google nie był zagrożony przez inne KG na dużą skalę, takie jak DBpedia, Freebase i YAGO.
Nacisk na bardziej ludzkie odpowiedzi na pytania
Konkurencja na niezrównaną skalę między Goole, OpenAI, Bing i innymi firmami polega na dostarczaniu bardziej ludzkich odpowiedzi na pytania, a nie tylko linków do informacji. Google stale używa i testuje różne duże modele językowe sztucznej inteligencji, aby ulepszać swoją wyszukiwarkę i panele wiedzy.
Termin „wykres wiedzy” ma rozległą rodzinę relacyjną; obejmuje dziedziny grafów wiedzy, baz danych grafów, skarbców wiedzy, paneli wiedzy, sieci neuronowych, uczenia maszynowego, NLP, sztucznej inteligencji, połączonych danych, osadzania grafu wiedzy, transferu wiedzy, transferu uczenia się, uczenia się reprezentacji wiedzy (KRL) i innych ! Wydawanie pieniędzy na płatne wyszukiwanie i trywialne ulepszenia wydajności witryny blednie w porównaniu ze skutecznym wypełnianiem luk w treści pytań i odpowiedzi. Poniższe sugestie pochodzą z mojego własnego doświadczenia.
Oparte na danych systemy firmy są oceniane w celu uzyskania zaufania do podejścia naukowego i jego zastosowań. Jego możliwości odpowiadania na pytania (QA) Grafu wiedzy (KG) opierają się na złożonych strukturach danych, które są udostępniane za pośrednictwem interfejsów języka naturalnego.
Jak tworzyć treści odpowiedzi na pytania, które Google uzna za pomocne
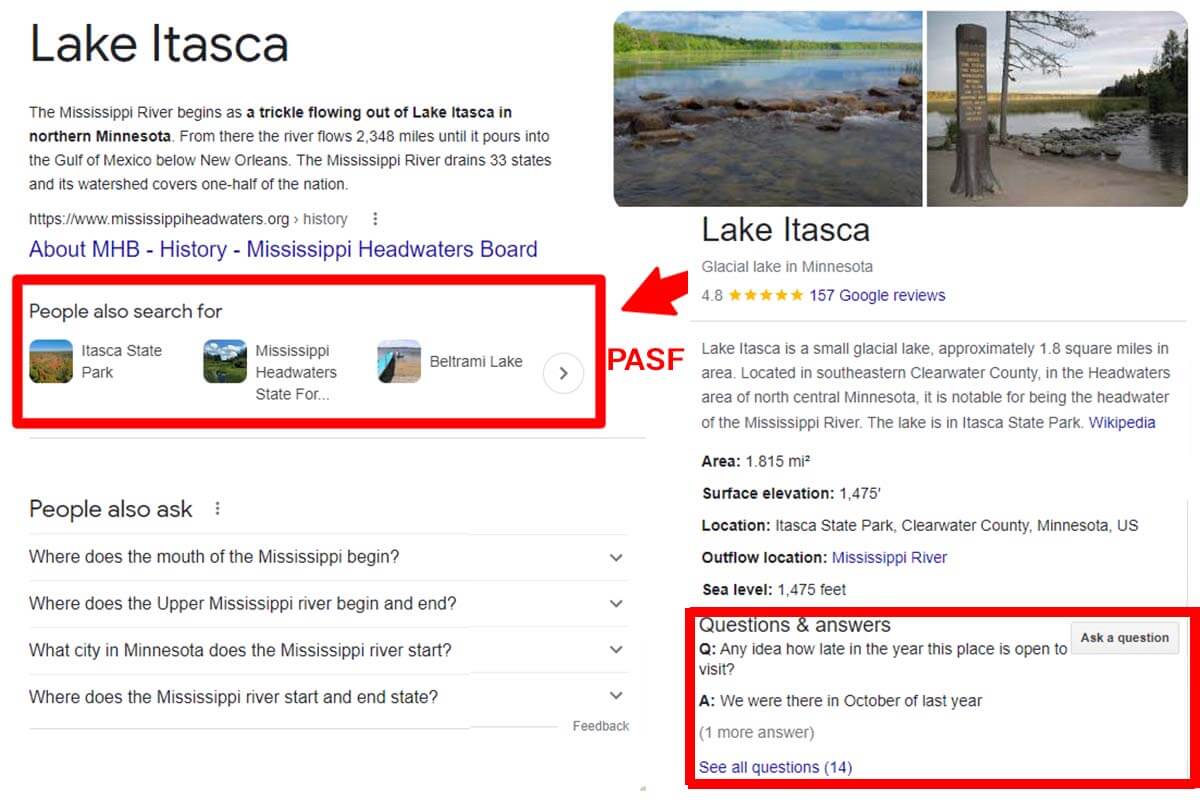
Nowe SEO rozumie, że Google jest rodzajem silnika odpowiedzi i karmi go.
Im więcej publikujesz weryfikujących danych, tym bardziej gigant technologiczny może łączyć dane. W ten sposób ułatwiasz pracę wyszukiwarce w zrozumieniu, jakie są fakty dotyczące Twojego podmiotu. Udzielasz pomocy, łącząc własne uporządkowane dane ze wszystkimi różnymi stronami trzecimi, które mówią o Tobie. Google nie preferuje tego, czy implementacja danych strukturalnych jest połączona za pomocą wykresu lub tablicy węzłów, czy ma je jako pojedyncze elementy we własnych blokach na stronie.
- Treść najczęściej zadawanych pytań: Twoja firma może tworzyć bazy danych oznaczone schematem, aby pomóc Google w indeksowaniu i przetwarzaniu stron z pytaniami i odpowiedziami. Google może zdecydować się na pozyskanie treści najczęściej zadawanych pytań dotyczących Twojej witryny.
- Klastry tematyczne witryn internetowych: Informacje z jasną ontologią mogą być używane do określenia wiedzy na dany temat. Grafy wiedzy porządkują jednostki na podstawie danych internetowych, którym Google ufa. Możesz być głównym źródłem w różnych zestawach danych. W ten sposób jesteś wydawcą danych. Jeśli zgłosiłeś prawa do swojego panelu wiedzy, może to być bardziej niezawodny i szybki sposób na uruchomienie aktualizacji panelu wiedzy.
- Dokładna baza danych produktów: tak długo, jak wykonujesz nienaganną pracę, aktualizując bazę danych produktów, pomagasz Google uzyskać wysokie zaufanie do faktów dotyczących Twoich produktów. Google z większą pewnością pokaże swoim użytkownikom dokładne i trafne informacje, jeśli Twoja marka i produkty online są jasne i spójne. Bądź konsekwentny we wszystkim, jeśli chodzi o Twoją obecność w Internecie. Używaj tej samej pisowni, tytułu, biografii autora, miejsca pracy itp.
- Prześlij zestawy danych obrazu: Obrazy wychodzące z tej konkretnej bazy danych można powiązać z Twoimi odpowiedziami i wypełnić Twój wykres wiedzy. Istnienie i dokładność Twoich zestawów danych dotyczących jakości produktów pomaga zapewnić porównywalność.
- Używaj znaczników schematu FactClaim: wyniki wyszukiwania Google są często pobierane z repozytorium Grafu wiedzy zawierającego miliardy faktów dotyczących ludzi, miejsc i rzeczy. Załączając rzeczowe, statystyczne treści, które wspierają Twoje opinie, pokazujesz swoją świadomość i znajomość odpowiednich źródeł opartych na faktach.
- Spójna nazwa, adres, telefon: w 2023 roku jest więcej sposobów zarządzania profilem firmy w Google. Jednak Twój NAP ma fundamentalne znaczenie dla tego, jak Google identyfikuje Twój podmiot. Najlepiej mieć stały adres i korzystać z przypisanego w Google Maps. Wykresy wiedzy są ściśle powiązane z Mapami Google. Opiera się na ustrukturyzowanych danych, ustrukturyzowanych informacjach w postaci spójności NAP: imię i nazwisko, adres, numer telefonu oraz to, w jaki sposób wpływają one na zapewnienie aktualizacji Map Google. Ten sam rodzaj konsystencji dostarcza GKG.
- Automatyczne odpowiedzi tekstowe na często zadawane pytania w Profilu Firmy Google: możesz dodawać automatyczne odpowiedzi na najczęściej zadawane pytania bezpośrednio w Profilu Firmy w Google. Działa jako zautomatyzowana rozmowa dwukierunkowa z odpowiadaniem na pytania.
- Wprowadź skuteczną strategię Google Post: autorzy Google Scholar, znane marki i wybrani urzędnicy ze Stanów Zjednoczonych nie wykorzystują możliwości zgłaszania praw do paneli wiedzy. To z kolei zapewnia im dostęp do Google Posts, które powinny być częścią strategii grafu wiedzy dotyczącej treści.
- Korzystaj z danych o odbiorcach i badań rynkowych: Wstępne badania rynkowe dostarczają wglądu w dane o odbiorcach, który może napędzać innowacyjne kampanie treści i strategie KG. Baza wiedzy najpierw klasyfikuje pytania na podstawie ich „istotności” w odniesieniu do intencji zapytania.
Więcej o korzystaniu z danych strukturalnych w Twojej witrynie:
Ryan Levering z Google, który pracuje głównie na danych strukturalnych, stwierdził w Mastodon: „Niezależnie od tego, jak wygląda wykres dla całej strony, jest tym, czego używamy, niezależnie od tego, skąd pochodzi. To się miesza i chociaż wiem, skąd się wzięło, zwykle nie jest to używane. Jednak zastrzeżenie polega na tym, że gdy robisz to w wielu blokach, czasami występują problemy z konfliktami/duplikacją. Ponadto z czasem bogatsza/poprawna semantyka będzie faworyzować więcej połączonych grafów. Nadal widzimy przypadki, w których ludzie rzucają niepowiązane znaczniki dotyczące rzeczy (takich jak powiązane produkty) na tym samym najwyższym poziomie co główna jednostka z różnych bloków na stronie, co powoduje głównie hałas. Czasami więc centralizacja logiki czyni ją bardziej spójną/poprawną”.

Grafy wiedzy odpowiadają na pytania związane z danymi
Celem wykresów jest zdolność do funkcjonowania jako podstawowa prawda terminologii, logiki i poprawnych odpowiedzi.
Oto cytat bezpośrednio od Google o tym, jak działa Graf wiedzy.
„Wyniki wyszukiwania Google czasami pokazują informacje pochodzące z naszego Grafu wiedzy, naszej bazy danych zawierającej miliardy faktów o ludziach, miejscach i rzeczach. Graf wiedzy pozwala nam odpowiedzieć na rzeczowe pytania, takie jak „Jak wysoka jest Wieża Eiffla?” lub „Gdzie odbyły się Letnie Igrzyska Olimpijskie 2016”. Naszym celem w przypadku Grafu wiedzy jest, aby nasze systemy odkrywały i udostępniały publicznie znane, oparte na faktach informacje, gdy uznamy je za przydatne”. – Jak działa Graf wiedzy Google
Możesz zasilić Graf wiedzy informacjami, które przedstawiają powiązane ze sobą relacje i koncepcje. Podczas gdy trwają ogromne inwestycje w sztuczną inteligencję chatbota, obecnie wiemy, że potrzebuje on modelu domeny, aby zrozumieć i odpowiedzieć na pytania. Uczenie maszynowe może generować ogromną bazę wiedzy o zdaniach i przypadkach użycia, ale statyczny chatbot ma ograniczenia.
Google zbiera informacje na określony temat lub temat, aby najpierw uzyskać pewność, zanim wpis dotyczący danych w Grafie wiedzy zostanie zaktualizowany. Wykresy pomagają nam odpowiadać na pytania dotyczące danych, dzięki czemu Google może łatwo przechowywać i pobierać informacje. Zasadniczo sprowadza się to do zrozumienia pytań, połączenia pytań z wykresem wiedzy i wywnioskowania odpowiedzi.
Sugerowane kroki optymalizacji odpowiedzi na pytania KG:
- Poszukaj, co, kto, gdzie, dlaczego, a także w jaki sposób publikacje, które kontrolujesz.
- Określ, które wewnętrzne dane dotyczące zapewniania jakości można pozyskać z zewnątrz.
- Dowiedz się, gdzie go znaleźć.
- Dowiedz się, jak jest już używany, przez kogo, jak może być używany i dlaczego.
- Użyj wykresów, aby określić, jak zapewnić większą wartość, analizując ich klastry, kohorty i grupy.
- Skonfiguruj alerty, aby pomóc w monitorowaniu sygnałów danych QA dotyczących kontekstu, sygnałów grupowych i dynamiki w relacjach między podmiotami.
- Zaplanuj czas konserwacji, aby zarządzać zawartością kontroli jakości wykresu i dostarczać ją.
Przetwarzanie języka naturalnego i zarządzanie wyrównaniem grafów ułatwiają znajdowanie przypadków sprzecznych jednostek lub definicji relacji. Panele, wykresy i przechowalnia Google służą do rozwiązywania jednostek.
Zanim odpowiesz na pytanie na platformie, którą kontrolujesz, najpierw inteligentnie zrozum pytanie. Powinieneś znać intencje osoby wyszukującej i kluczowe informacje potrzebne do pytania. Wyszukiwarki wydobywają kluczowe informacje, wyszukując nazwane jednostki, które są przydatne do włączenia grafu wiedzy. Aby im zaufać, są selektywni przed wywnioskowaniem odpowiedzi na KG.
Jak poprosić o aktualizację Panelu wiedzy Google?
Google zapewnia swoim właścicielom Grafu wiedzy sposób żądania aktualizacji i zgłaszania problemów. Łatwiej jest, gdy nabędziesz umiejętność udzielania bezpośredniej informacji zwrotnej. Jego natychmiastowe odpowiedzi są regularnie aktualizowane na podstawie indeksowania sieci i opinii użytkowników.
„Wiemy również, że podmioty, których informacje są zawarte w panelach wiedzy (takie jak wybitne osoby lub twórcy programu telewizyjnego), są autorytatywne i zapewniamy tym podmiotom sposoby przekazywania bezpośrednich informacji zwrotnych. W związku z tym niektóre wyświetlane informacje mogą również pochodzić od zweryfikowanych podmiotów, które zasugerowały zmiany faktów we własnych panelach wiedzy. – O panelach wiedzy
„Otrzymujemy również rzeczowe informacje bezpośrednio od właścicieli treści na różne sposoby, w tym od tych, którzy proponują zmiany w panelach wiedzy, do których zgłosili roszczenia”. – Jak działa Graf wiedzy Google
Wiele osób uważa, że kluczowymi korzyściami płynącymi z uzyskania semantycznego wykresu wiedzy jest to, że zapewnia on przejrzystość marki, odzyskiwanie danych i doświadczenia sprzedażowe. Ale ponieważ tak wiele osób zadaje pytania, ważne jest, aby wziąć pod uwagę również jego zdolność do integrowania danych i wykorzystywania ich do udzielania odpowiedzi. Czymże nie być sprzedawca, który okaże się wartościowy w ten sposób?
Jak działa wyszukiwanie informacji w odpowiedzi na pytania?
Google łączy treści klastrów pytań ze źródeł, których może być pewien.
Rok 2023 to era doskonalenia strategii Grafów wiedzy, ponieważ coraz więcej konwersji leadów odbywa się bezpośrednio na stronach wyników wyszukiwania (SERP). Google ocenia, komu może ufać w Twoim podmiocie, i wybiera, co zostanie uwzględnione w Twoim Grafie wiedzy, Panelach wiedzy i Skarbcu wiedzy. Wie o Twojej grupie docelowej i klientach; stara się dopasować Twoje mocne strony i wiedzę w całej sieci, aby zapewnić najlepsze odpowiedzi. Badania odbiorców i analiza SERP mogą wpłynąć na Twoje podejście do marketingu.
Gdy Google wyodrębnia informacje o podmiotach kontroli jakości ze stron internetowych, określane są wyniki powiązań między tymi podmiotami i ich relacje z innymi podmiotami. Zależy mu bardzo na rzeczowych odpowiedziach opisujących właściwości tych bytów. Po ustaleniu najlepszej strategii marketingowej nadszedł czas, aby przenieść ją do taktyki marketingowej, w której podjęto określone działania marketingowe w celu poprawy wyników SERP. Zarówno dzisiaj, jak i jeszcze bardziej w przyszłości, zrozumienie wyszukiwania informacji o QA i sposobu informowania swoich KG jest istotnym elementem skutecznego SEO.
Z patentów Google dowiadujemy się, jak model przetwarzania języka naturalnego może odpowiadać na pytania tekstowe w języku naturalnym.
„System komputerowy obejmuje model przetwarzania języka naturalnego, którego uczą się maszyny, który obejmuje model kodera wyszkolony do odbierania treści tekstu w języku naturalnym i generowania wykresu wiedzy oraz model programisty wyszkolony do odbierania pytań w języku naturalnym i generowania programu. System komputerowy zawiera czytelny dla komputera nośnik przechowujący instrukcje, które po wykonaniu powodują, że procesor wykonuje operacje. Operacje obejmują uzyskiwanie treści tekstu w języku naturalnym, wprowadzanie treści tekstu w języku naturalnym do modelu kodera, odbieranie grafu wiedzy jako wyjścia z modelu kodera, uzyskiwanie pytania w języku naturalnym, wprowadzanie pytania w języku naturalnym do modelu programisty , otrzymanie programu jako wyjścia modelu programisty i wykonanie programu na grafie wiedzy w celu uzyskania odpowiedzi na pytanie w języku naturalnym”. – Przetwarzanie języka naturalnego za pomocą maszyny N-gramowej, patent nr: WO2019083519A1, data publikacji: 2 maja 2019 r. [3]
Punktacja trafności wykresu wiedzy
Połącz uczenie się języka maszynowego i wykresy danych, aby połączyć kontekst pytania odbiorców z odpowiedziami. Ocena trafności Google KG wykorzystuje wstępnie wyszkolony LM do oceniania węzłów na KG uwarunkowanych odpowiedzią na pytanie. Google ma ogólne ramy dotyczące ważenia informacji w swoich KG. Jego uczenie maszynowe wykorzystuje wspólne rozumowanie nad tekstem i KG. W ten sposób łączy kontekst pytań z treścią odpowiedzi za pomocą LM i grafowych sieci neuronowych.
Ogólnie rzecz biorąc, Google KGs są bardziej wydajne i godne zaufania niż strony internetowe. Więc dokąd to zmierza?
Odpowiadanie na pytania KG starają się dostarczać zweryfikowaną wiedzę
Graf wiedzy Google zapewnia bezpośrednie odpowiedzi na zapytania
Fakty podane przez Graf wiedzy Google w odpowiedzi na zapytanie pochodzą początkowo z innych źródeł. (Do niedawna pochodziło to głównie z Wikipedii i Wikidanych). Google ciężko pracuje, aby ufać wszelkim informacjom zapełniającym jego KG. Dokładne zaspokojenie zapytań musi być trudne. Na przykład, aby odpowiedzieć na pytanie „Kto był założycielem Google?”, Graf wiedzy musi wyodrębnić tutaj potrójny element (podmiot-predykat-obiekt) na wzór „[Organizacja] założona przez [osobę(-y)]”
Wikipedia i Wikidata dostarczają takich dokładnych informacji.
Aaron Bradly, specjalista ds. strategii wykresów wiedzy w Electronic Arts, kilka lat temu zadał na Twitterze fascynujące pytanie. „Mówiąc o szerszym podstawowym pytaniu, czy powinniśmy uważać„ fakty ”dostarczone przez Graf wiedzy Google za zgodne ze stanem faktycznym (i czy samo Google uważa „fakty” dostarczone przez Graf za zgodne ze stanem faktycznym).”
Szybko widać, dlaczego „odpowiedzi” i „fakty” dostarczane przez Graf wiedzy muszą być zaufane przez użytkowników.
Bradley mówi dalej: „Tak więc Graph musi opierać się na wiarygodności swoich źródeł przy określaniu, jakie twierdzenia należy przedstawić. Do tego stopnia, że Google zastanawiał się nad metodami poprawy sposobu określania wiarygodności źródła. Ostatecznie podane twierdzenie brzmi „skądś”. Staje się to problematyczne, gdy ładunek odpowiedzi (zwłaszcza głos) nie zawiera informacji o pochodzeniu. Zarówno agregatorzy wiedzy (tutaj Google), jak i użytkownicy wiedzy (tutaj wyszukujący) muszą pracować nad poprawą sposobu, w jaki przetwarzamy te pytania i odpowiedzi”. [4]
Larry Page i Sergey Brin, założyciele Google, pojawili się ponownie po swoim odejściu w 2019 roku, aby przejrzeć strategię Google dotyczącą produktów sztucznej inteligencji. Zatwierdzili plany i przedstawili pomysły na dodanie nowych funkcji chatbota do wyszukiwarki Google. Masowe zwolnienia pracowników w Google w styczniu 2023 r. wynikają z odnowionego zobowiązania Google do umieszczenia sztucznej inteligencji na pierwszym miejscu w ich planach. [5]
Możesz użyć interfejsu Google Knowledge Graph Search API do wyszukiwania jednostek w Grafie wiedzy Google. Google Cloud oferuje następujący przykład kodu znaczników schematu: [6]
{
"@kontekst": {
"@vocab": "http://schema.org/"
},
"@type": "Lista pozycji",
"itemListElement": [
{
"wynik": {
"@id": "c-07xuup16g",
"nazwa": "Uniwersytet Stanforda",
"description": "Prywatny uniwersytet w Stanford, Kalifornia",
"szczegółowy opis": {
"articleBody": "Uniwersytet Stanforda, oficjalnie Leland Stanford Junior University, jest prywatnym uniwersytetem badawczym w Stanford w Kalifornii. Kampus zajmuje 8180 akrów, jeden z największych w Stanach Zjednoczonych, i kształci ponad 17 000 studentów.",
„url”: „https://en.wikipedia.org/wiki/Uniwersytet_Stanforda”,
"licencja": "https://en.wikipedia.org/wiki/Wikipedia:Text_of_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License"
},
"url": "http://www.stanford.edu/",
"obraz": {
"contentUrl": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcTfPPf-ker0y_892m1wu8-U89furQgQ67foDFncY3r9sREpeWxV",
„url”: „https://es.wikipedia.org/wiki/Archivo:Logo_of_Stanford_University.png”
},
"identyfikator": [
{
"@type": "WartośćWłaściwości",
"propertyID": "googleKgMID",
"wartość": "/m/06pwq"
},
{
"@type": "WartośćWłaściwości",
"propertyID": "googlePlaceID",
"wartość": "ChIJneqLZyq7j4ARf2j8RBrwzSk"
},
{
"@type": "WartośćWłaściwości",
"propertyID": "wikidataQID",
"wartość": "Q41506"
}
],
"@typ": [
"Miejsce",
"Organizacja",
„KinoTeatr”,
"Korporacja",
„Organizacja edukacyjna”,
"Rzecz",
„College LubUniwersytet”
]
}
}
]
}
Uważamy, że implementacja znaczników schematu jest niezwykle pomocna. Jeśli jesteś podwójna, przeczytaj nasze zalety i wady dodawania artykułów o znacznikach danych strukturalnych.
Wyszukiwanie semantyczne i GKG Forward
Jeśli ten artykuł poszerzył Twoją wiedzę na temat wyszukiwania semantycznego i technologii wykresów, a teraz chcesz skorzystać z takich możliwości, zadzwoń do Jeannie Hill pod numer 651-206-2410.
Zwiększ swój wykres wiedzy osobistej lub biznesowej, uzyskując nasz Audyt jednostek zapytań
Bibliografia:
[1] https://research.google/pubs/pub45634/
[2] https://patents.google.com/patent/WO2014008272A1/en
[3] https://patentscope.wipo.int/search/en/detail.jsf?docId=WO2019083519
[4] https://mobile.twitter.com/aaranged/status/1108444732282163200
[5] https://searchengineland.com/google-search-chatbot-features-this-year-391977
[6] https://cloud.google.com/enterprise-knowledge-graph/docs/search-api