
Jak zautomatyzować orkiestrację praw dostępu w zasobnikach AWS S3
Opublikowany: 2023-01-13Wiele lat temu, gdy istniały lokalne serwery Unix z dużymi systemami plików, firmy tworzyły rozbudowane reguły zarządzania folderami i strategie administrowania prawami dostępu do różnych folderów dla różnych osób.
Zwykle platforma organizacji obsługuje różne grupy użytkowników o zupełnie odmiennych zainteresowaniach, ograniczeniach poziomu poufności lub definicjach treści. W przypadku organizacji globalnych może to oznaczać nawet rozdzielanie treści na podstawie lokalizacji, a więc zasadniczo między użytkownikami należącymi do różnych krajów.

Dalsze typowe przykłady mogą obejmować:
- separacja danych między środowiskami programistycznymi, testowymi i produkcyjnymi
- treści sprzedażowe niedostępne dla szerokiego grona odbiorców
- treści legislacyjne specyficzne dla danego kraju, których nie można wyświetlić ani uzyskać do nich dostępu z innego regionu
- treści związane z projektami, w których „dane przywódcze” mają być udostępniane tylko ograniczonej grupie osób itp.
Istnieje potencjalnie nieskończona lista takich przykładów. Chodzi o to, że zawsze istnieje jakaś potrzeba zorganizowania praw dostępu do plików i danych między wszystkimi użytkownikami, którym platforma zapewnia dostęp.
W przypadku rozwiązań on-premise było to rutynowe zadanie. Administrator systemu plików po prostu skonfigurował pewne reguły, użył wybranego narzędzia, a następnie ludzie zostali zmapowani na grupy użytkowników, a grupy użytkowników zostały zmapowane na listę folderów lub punktów montowania, do których będą mieli dostęp. Po drodze poziom dostępu został zdefiniowany jako dostęp tylko do odczytu lub dostęp do odczytu i zapisu.
Patrząc teraz na platformy chmurowe AWS, oczywiste jest, że ludzie będą mieli podobne wymagania dotyczące ograniczeń dostępu do treści. Rozwiązanie tego problemu musi być jednak teraz inne. Pliki nie opierają się już na serwerach Unix, ale w chmurze (i potencjalnie są dostępne nie tylko dla całej organizacji, ale nawet całego świata), a zawartość nie jest przechowywana w folderach, ale w zasobnikach S3.

Poniżej opisano alternatywne podejście do tego problemu. Opiera się na rzeczywistych doświadczeniach, które zdobyłem, projektując takie rozwiązania dla konkretnego projektu.
Proste, ale bardzo ręczne podejście
Jeden ze sposobów rozwiązania tego problemu bez żadnej automatyzacji jest stosunkowo prosty:
- Utwórz nowe wiadro dla każdej odrębnej grupy ludzi.
- Przypisz prawa dostępu do zasobnika, aby tylko ta konkretna grupa miała dostęp do zasobnika S3.
Jest to z pewnością możliwe, jeśli wymagane jest bardzo proste i szybkie rozwiązanie. Istnieją jednak pewne ograniczenia, o których należy pamiętać.
Domyślnie w ramach jednego konta AWS można utworzyć maksymalnie 100 zasobników S3. Limit ten można rozszerzyć do 1000, zgłaszając zwiększenie limitu usługi do biletu AWS. Jeśli te ograniczenia nie są czymś, o co martwiłby się twój konkretny przypadek implementacji, możesz pozwolić każdemu z odrębnych użytkowników domeny działać na oddzielnym wiaderku S3 i nazwać to dniem.
Problemy mogą się pojawić, jeśli istnieją grupy osób o odpowiedzialności międzyfunkcyjnej lub po prostu niektóre osoby, które potrzebują dostępu do treści większej liczby domen w tym samym czasie. Na przykład:
- Analitycy danych oceniający zawartość danych dla kilku różnych obszarów, regionów itp.
- Zespół testujący udostępniał usługi obsługujące różne zespoły programistyczne.
- Zgłaszanie użytkowników wymagających zbudowania analizy pulpitu nawigacyjnego na podstawie różnych krajów w tym samym regionie.
Jak możesz sobie wyobrazić, ta lista może ponownie wzrosnąć tak bardzo, jak możesz sobie wyobrazić, a potrzeby organizacji mogą generować wszelkiego rodzaju przypadki użycia.
Im bardziej złożona staje się ta lista, tym bardziej złożona orkiestracja praw dostępu będzie potrzebna, aby przyznać wszystkim różnym grupom różne prawa dostępu do różnych zasobników S3 w organizacji. Potrzebne będą dodatkowe narzędzia, a być może nawet dedykowany zasób (administrator) będzie musiał utrzymywać listy praw dostępu i aktualizować je za każdym razem, gdy wymagana jest jakakolwiek zmiana (co będzie bardzo częste, zwłaszcza jeśli organizacja jest duża).
Jak więc osiągnąć to samo w bardziej zorganizowany i zautomatyzowany sposób?
Wprowadź znaczniki dla wiader
Jeśli podejście typu „wiaderko na domenę” nie zadziała, każde inne rozwiązanie zakończy się udostępnieniem zasobników dla większej liczby grup użytkowników. W takich przypadkach konieczne jest zbudowanie całej logiki nadawania praw dostępu w pewnym obszarze, który można łatwo zmieniać lub aktualizować dynamicznie.
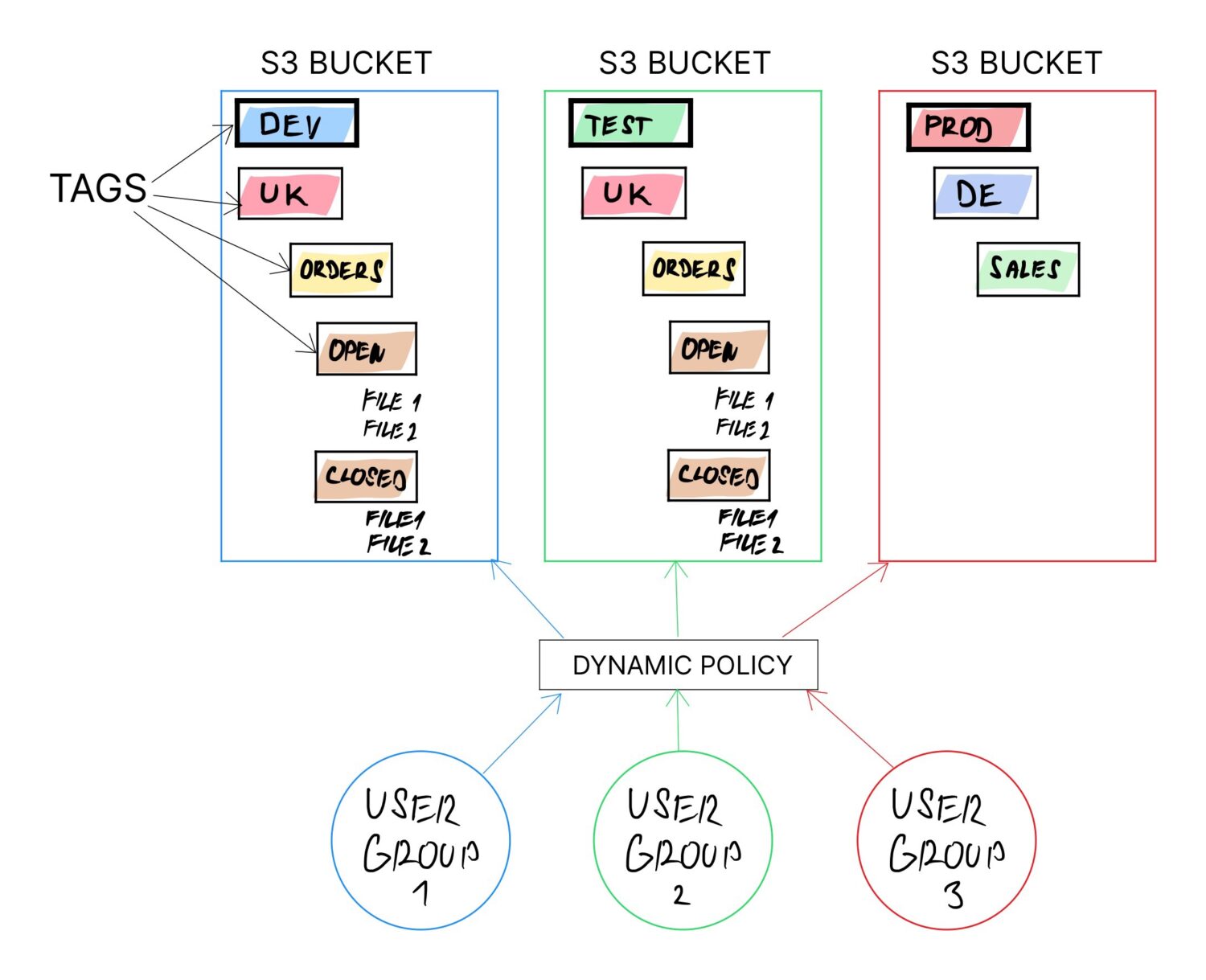
Jednym ze sposobów osiągnięcia tego jest użycie tagów na zasobnikach S3. Zaleca się stosowanie tagów w każdym przypadku (choćby w celu umożliwienia łatwiejszej kategoryzacji rozliczeń). Tag można jednak zmienić w dowolnym momencie w przyszłości dla dowolnego zasobnika.
Jeśli cała logika jest zbudowana w oparciu o znaczniki zasobnika, a reszta jest zależna od konfiguracji wartości znaczników, zapewniona jest właściwość dynamiczna, ponieważ można przedefiniować przeznaczenie zasobnika, po prostu aktualizując wartości znaczników.
Jakich tagów użyć, aby to zadziałało?
Zależy to od konkretnego przypadku użycia. Na przykład:
- Może być konieczne oddzielenie zasobników według typu środowiska. W takim przypadku jedna z nazw tagów powinna mieć postać „ENV” i zawierać możliwe wartości „DEV”, „TEST”, „PROD” itp.
- Może chcesz oddzielić zespół na podstawie kraju. W takim przypadku innym tagiem będzie „KRAJ” i wartość będzie zawierać nazwę kraju.
- Możesz też chcieć rozdzielić użytkowników na podstawie działu funkcjonalnego, do którego należą, np. analitycy biznesowi, użytkownicy hurtowni danych, naukowcy zajmujący się danymi itp. Tworzysz tag o nazwie „TYP_UŻYTKOWNIKA” i odpowiedniej wartości.
- Inną opcją może być jawne zdefiniowanie stałej struktury folderów dla określonych grup użytkowników, z których muszą korzystać (aby nie tworzyć własnego bałaganu w folderach i nie gubić się w nich z czasem). Możesz to zrobić ponownie za pomocą tagów, w których możesz określić kilka katalogów roboczych, takich jak: „dane/import”, „dane/przetworzone”, „dane/błąd” itp.
Idealnie byłoby zdefiniować tagi tak, aby można je było logicznie łączyć i tworzyć całą strukturę folderów w zasobniku.

Możesz na przykład połączyć następujące tagi z powyższych przykładów, aby utworzyć dedykowaną strukturę folderów dla różnych typów użytkowników z różnych krajów z predefiniowanymi folderami importu, których mają używać:
- /<ENV>/<TYP_UŻYTKOWNIKA>/<KRAJ>/<PRZEŚLIJ>
Po prostu zmieniając wartość <ENV>, możesz ponownie zdefiniować cel tagu (czy ma być przypisany do ekosystemu środowiska testowego, dev, prod itp.)
Umożliwi to korzystanie z tego samego zasobnika dla wielu różnych użytkowników. Zasobniki nie obsługują jawnie folderów, ale obsługują „etykiety”. Etykiety te działają ostatecznie jak podfoldery, ponieważ użytkownicy muszą przejść przez serię etykiet, aby dotrzeć do swoich danych (tak samo jak w przypadku podfolderów).
Twórz dynamiczne zasady i mapuj znaczniki zasobników w środku
Po zdefiniowaniu tagów w jakiejś użytecznej formie, następnym krokiem jest zbudowanie polityk kubełków S3, które używałyby tagów.
Jeśli zasady używają nazw znaczników, tworzysz coś, co nazywa się „zasadami dynamicznymi”. Zasadniczo oznacza to, że zasady będą zachowywać się inaczej w przypadku zasobników z różnymi wartościami znaczników, do których zasady odnoszą się w formularzu lub symbolach zastępczych.
Ten krok oczywiście obejmuje niestandardowe kodowanie zasad dynamicznych, ale możesz uprościć ten krok za pomocą narzędzia edytora zasad Amazon AWS, które przeprowadzi Cię przez ten proces.
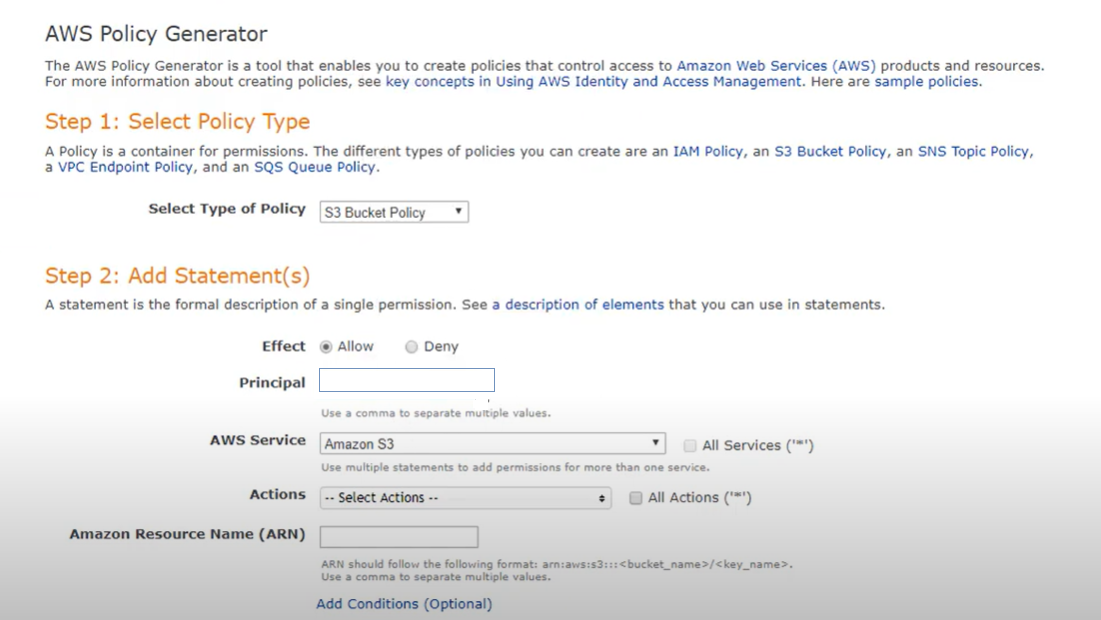
W samej polityce będziesz chciał zakodować konkretne prawa dostępu, które będą stosowane do zasobnika oraz poziom dostępu tych praw (odczyt, zapis). Logika odczyta tagi na zasobnikach i zbuduje strukturę folderów na zasobniku (tworząc etykiety na podstawie znaczników). Na podstawie konkretnych wartości znaczników zostaną utworzone podfoldery i wzdłuż linii zostaną przypisane wymagane prawa dostępu.
Zaletą takiej dynamicznej polityki jest to, że można utworzyć tylko jedną dynamiczną politykę, a następnie przypisać tę samą dynamiczną politykę do wielu zasobników. Ta zasada będzie działać inaczej w przypadku zasobników z różnymi wartościami tagów, ale zawsze będzie zgodna z Twoimi oczekiwaniami dotyczącymi zasobnika z takimi wartościami tagów.
Jest to naprawdę skuteczny sposób zarządzania przypisaniami praw dostępu w zorganizowany, scentralizowany sposób dla dużej liczby zasobników, gdzie oczekuje się, że każdy zasobnik będzie zgodny z pewnymi uzgodnionymi z góry strukturami szablonów i będzie używany przez użytkowników w ciągu cała organizacja.
Zautomatyzuj wdrażanie nowych podmiotów
Po zdefiniowaniu dynamicznych polityk i przypisaniu ich do istniejących zasobników, użytkownicy mogą zacząć korzystać z tych samych zasobników bez ryzyka, że użytkownicy z różnych grup nie będą mieli dostępu do treści (przechowywanej w tym samym zasobniku) znajdujących się w strukturze folderów, w których nie mają dostęp.
Ponadto dla niektórych grup użytkowników z szerszym dostępem dostęp do danych będzie łatwy, ponieważ wszystkie będą przechowywane w tym samym zasobniku.
Ostatnim krokiem jest jak najprostsze wprowadzanie nowych użytkowników, nowych zasobników, a nawet nowych tagów. Prowadzi to do innego niestandardowego kodowania, które jednak nie musi być zbyt skomplikowane, zakładając, że Twój proces wdrażania ma kilka bardzo jasnych reguł, które można ująć w prostą, prostą logikę algorytmu (przynajmniej możesz udowodnić w ten sposób, że Twój proces ma pewną logikę i nie jest prowadzony w przesadnie chaotyczny sposób).
Może to być tak proste, jak utworzenie skryptu wykonywalnego za pomocą polecenia AWS CLI z parametrami potrzebnymi do pomyślnego wdrożenia nowego podmiotu na platformę. Może to być nawet seria skryptów CLI, wykonywalnych w określonej kolejności, jak na przykład:
- create_new_bucket(<ENV>,<ENV_VALUE>,<KRAJ>,<KRAJ_WARTOŚĆ>, ..)
- create_new_tag(<identyfikator_zasobnika>,<nazwa_tagu>,<wartość_tagu>)
- update_existing_tag(<identyfikator_zasobnika>,<nazwa_tagu>,<wartość_tagu>)
- create_user_group(<typ_użytkownika>,<kraj>,<środowisko>)
- itp.
Dostajesz punkt.
Profesjonalna wskazówka
Jeśli chcesz, jest jedna Pro Tip, którą można łatwo zastosować na powyższym.
Polityki dynamiczne można wykorzystać nie tylko do przypisywania praw dostępu do lokalizacji folderów, ale także do automatycznego przypisywania uprawnień serwisowych dla zasobników i grup użytkowników!
Wystarczyłoby rozszerzyć listę tagów na kubełkach, a następnie dodać dynamiczne prawa dostępu do polityk, aby korzystać z określonych usług dla konkretnych grup użytkowników.
Na przykład może istnieć pewna grupa użytkowników, którzy również potrzebują dostępu do określonego serwera klastra bazy danych. Bez wątpienia można to osiągnąć za pomocą dynamicznych zasad wykorzystujących zadania kubełkowe, tym bardziej, jeśli dostęp do usług jest oparty na podejściu opartym na rolach. Wystarczy dodać do kodu polityki dynamicznej część, która będzie przetwarzać znaczniki dotyczące specyfikacji klastra bazy danych i przypisać uprawnienia dostępu do polityki bezpośrednio do tego konkretnego klastra DB i grupy użytkowników.
W ten sposób wprowadzenie nowej grupy użytkowników będzie możliwe tylko dzięki tej jednej dynamicznej polityce. Ponadto, ponieważ jest dynamiczna, ta sama polityka może być ponownie wykorzystana do wprowadzania wielu różnych grup użytkowników (oczekuje się, że będą przestrzegać tego samego szablonu, ale niekoniecznie tych samych usług).
Możesz także rzucić okiem na te polecenia AWS S3 do zarządzania zasobnikami i danymi.