
Wykorzystaj w pełni możliwości Apache Solr: techniczne badanie indeksowania wyszukiwania
Opublikowany: 2023-02-21Funkcja wyszukiwania zwiększa komfort korzystania z witryny internetowej, umożliwiając użytkownikowi łatwe i szybkie znalezienie tego, czego szuka. Bardziej w przypadku dużych witryn, witryn handlu elektronicznego i witryn z dynamiczną zawartością (witryny z wiadomościami, blogi).
Apache Solr to jedna z najpopularniejszych platform wyszukiwania używanych przez strony internetowe różnej wielkości. Jest to wyszukiwarka typu open source oparta na Javie, która umożliwia przeszukiwanie dużych ilości danych, takich jak artykuły, produkty, recenzje klientów i inne. Przyjrzyj się bliżej Apache Solr w tym artykule.
Sprawdź ten artykuł, aby dowiedzieć się, jak skonfigurować Apache Solr w Drupalu

Dlaczego Apache Solr jest tak popularny?
Apache Solr jest szybki i elastyczny i umożliwia wyszukiwanie pełnotekstowe, wyróżnianie trafień (podkreśla pasujące wyszukiwane hasło), wyszukiwanie fasetowe (bardziej precyzyjne wyszukiwanie), indeksowanie w czasie rzeczywistym (umożliwia natychmiastowe indeksowanie nowej treści), dynamiczne grupowanie ( organizuje wyniki wyszukiwania w grupy), integrację z bazą danych, funkcje NoSQL (nierelacyjna baza danych) oraz bogatą obsługę dokumentów (w celu indeksowania szerokiej gamy formatów dokumentów, takich jak PDF, MS Office, Open Office).
Kilka faktów, które warto znać o Apache Solr:
- Został początkowo opracowany przez sieci CNET, Inc. jako wyszukiwarka ich stron internetowych i artykułów. Później był open source i stał się projektem Apache najwyższego poziomu.
- Obsługuje wiele języków programowania, takich jak PHP, Java, Python i Ruby. Zapewnia również interfejsy API dla tych języków.
- Ma wbudowaną obsługę wyszukiwania geoprzestrzennego, umożliwiając wyszukiwanie treści na podstawie ich lokalizacji. Szczególnie przydatne w przypadku witryn takich jak witryny z nieruchomościami, witryny podróżnicze itp.
- Obsługuje zaawansowane funkcje wyszukiwania, takie jak sprawdzanie pisowni, autouzupełnianie i wyszukiwanie niestandardowe za pośrednictwem interfejsów API i wtyczek.
- Używa Lucene do indeksowania i wyszukiwania.
Co to jest Lucen
Apache Lucene to biblioteka wyszukiwania Java typu open source, która umożliwia łatwe dodawanie wyszukiwania lub pobierania informacji do aplikacji. Jest wszechstronny, wydajny, dokładny i działa na wydajnym algorytmie wyszukiwania.
Chociaż Lucene jest znany ze swoich możliwości wyszukiwania pełnotekstowego, może być również używany do klasyfikacji dokumentów, analizy danych i wyszukiwania informacji. Obsługuje również wiele języków innych niż angielski, takich jak niemiecki, francuski, hiszpański, chiński, japoński i inne.
Co to jest indeksowanie?
Wszystkie wyszukiwarki zaczynają się od indeksowania. Indeksowanie to przetwarzanie oryginalnych danych w wysoce wydajne wyszukiwanie odsyłaczy w celu ułatwienia szybkiego wyszukiwania.
Wyszukiwarki nie indeksują danych bezpośrednio. Teksty są najpierw dzielone na tokeny (elementy atomowe). Wyszukiwanie to proces sprawdzania indeksu wyszukiwania i pobierania dokumentu pasującego do zapytania.
Zalety indeksowania
- Szybkie i dokładne wyszukiwanie informacji (zbiera, analizuje i przechowuje)
- Bez indeksowania wyszukiwarka potrzebuje więcej czasu na zeskanowanie każdego dokumentu
Przepływ indeksowania
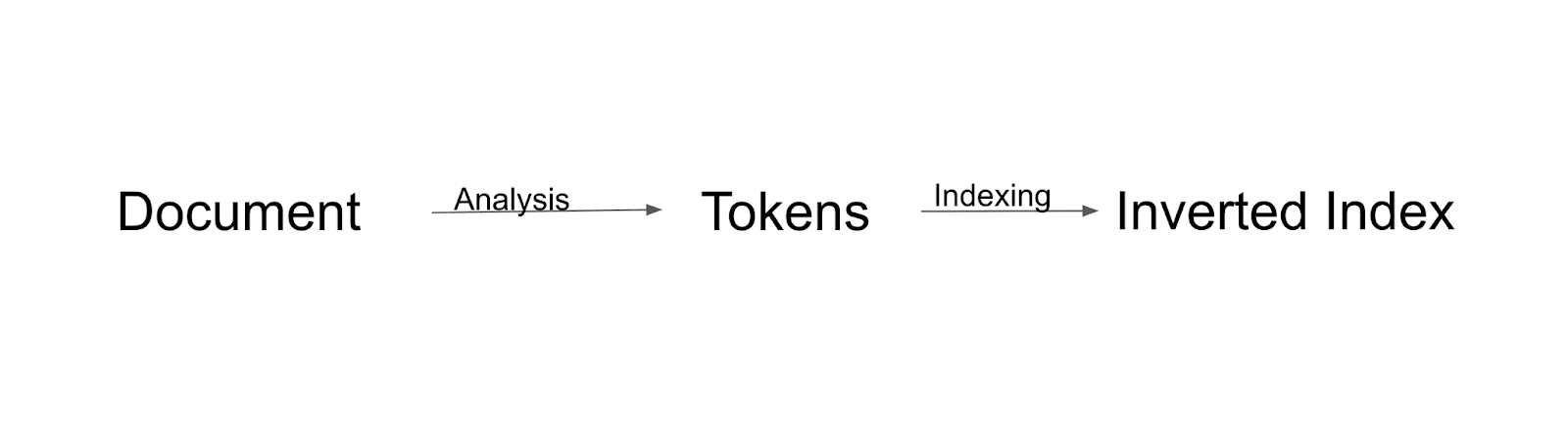
Najpierw dokument zostanie przeanalizowany i podzielony na tokeny. Wszystkie te tokeny zostaną zindeksowane do odwróconego indeksu. Odwrócony indeks to sposób, w jaki Solr buduje indeks.
Jak działa indeksowanie odwrócone
Załóżmy, że mamy 3 dokumenty:
- kocham czekoladę (D 1)
- Zamówiłem ciasto czekoladowe (D 2)
- Przygotowałam duże ciasto waniliowe (D 3)
Sposób tokenizacji pokazano w drugiej kolumnie poniższej tabeli.

„Czekolada” jest dostępna w D1 i D2
„Ciasto” jest dostępne w D2 i D3
„Duży” jest dostępny w D3
„Zamówione” jest dostępne w D2
„Przygotowany” jest dostępny w D3
„Wanilia” jest dostępna w D3
Zauważysz, że słowa takie jak „ja”, „miłość” nie są tokenizowane. Są to tak zwane słowa Stop, które nie będą indeksowane ani przeszukiwane przez Solr.
Kiedy więc ktoś wyszukuje termin „ciasto czekoladowe”, wyszukiwarka sprawdza indeks. Zamiast szukać dokumentu, najpierw sprawdza indeks, aby zobaczyć, do których dokumentów należą słowa „Czekolada” i „Ciasto”. Ułatwia to i przyspiesza pobieranie tylko określonego dokumentu. Nazywa się to indeksowaniem odwróconym.
Schemat przechowywania
Apache Solr używa schematu przechowywania opartego na dokumentach i przechowuje każdy fragment danych jako osobny dokument w kolekcji. Pozwala to na wydajne i elastyczne przechowywanie i wyszukiwanie danych.
W Drupalu każdy węzeł jest traktowany jako dokument. Więc kiedy indeksujesz swój węzeł do Apache Solr, jest on uważany za dokument. Każdy dokument może zawierać wiele pól. Lucene nie ma wspólnego schematu globalnego. Co oznacza, że w Apache Solr możesz indeksować dowolne pola w każdym dokumencie.

Jak zainstalować Apache Solr
- Najpierw upewnij się, że masz zainstalowaną Javę w swoim systemie.
- Następnie zainstalujmy Solr stąd: https://solr.apache.org/downloads.html
- Pobierz i rozpakuj Solr.
- Uruchom to polecenie w folderze Solr.
◦ bin/solr -e techproducts
Spowoduje to utworzenie fałszywego rdzenia do demonstracji, a także uruchomi serwer Solr.
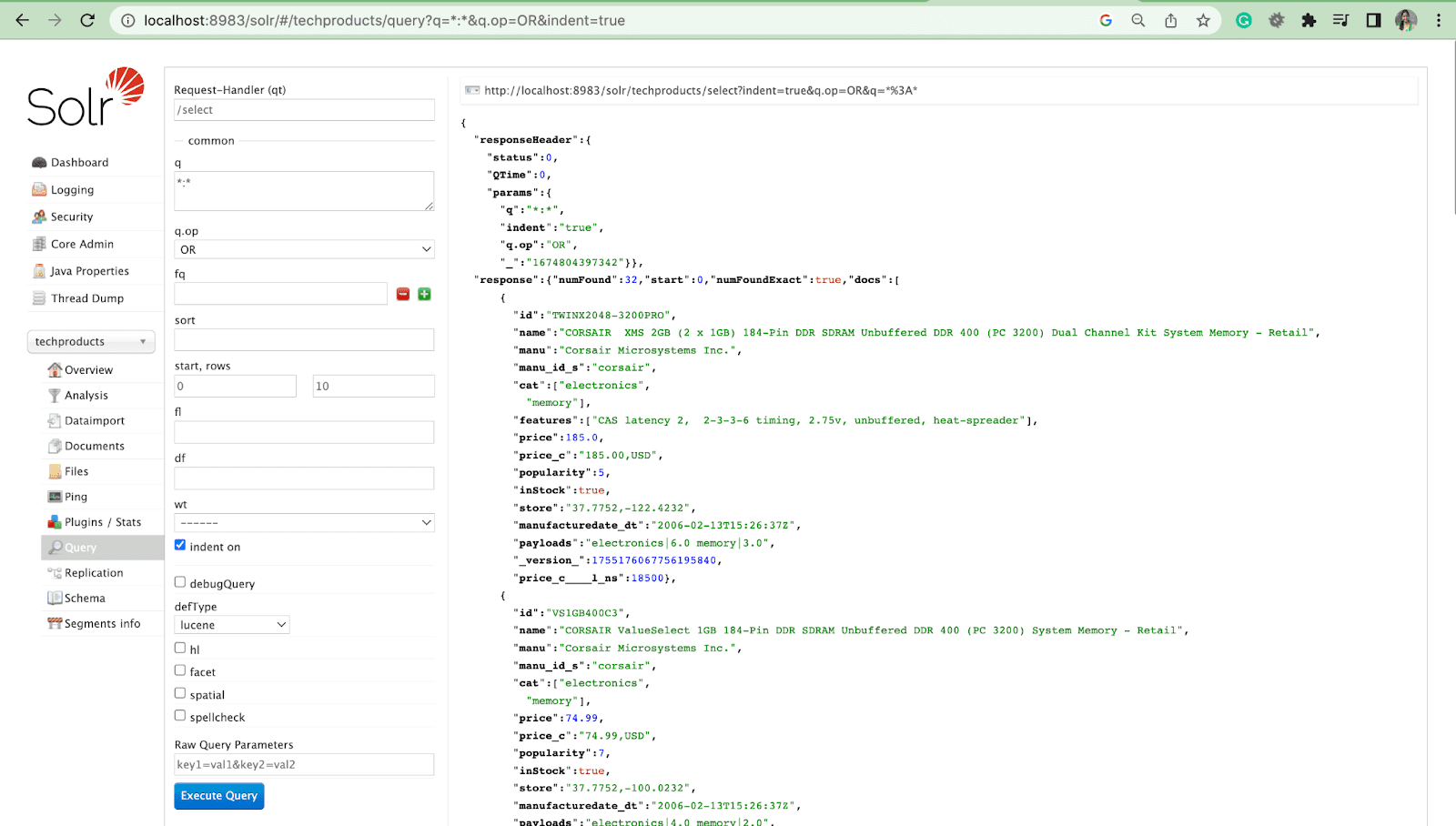
- Po uruchomieniu serwera przejdź do przeglądarki i wpisz „http://localhost:8983/”.
- Upewnij się, że Solr został pomyślnie zainstalowany z fikcyjnym rdzeniem.
Struktura katalogów
Po zainstalowaniu Solr zobaczysz wiele folderów, takich jak:

Docs - zawiera dokumentację dotyczącą Solr
Dist - główny plik .jar Solr
Contrib - zawiera dodatkowe wtyczki i wyspecjalizowane funkcje Solr
Bin - skrypty Solr
Przykład — zawiera demonstrację możliwości solr
Serwer - serce Solr. Zawiera aplikację internetową Solr, logi, rdzeń Solr
Pliki konfiguracyjne
Aby utworzyć rdzeń, potrzebujemy obowiązkowo dwóch plików.
- Schemat.xml
- Solrconfig.xml
Schemat.xml
- Będzie zawierał typy pól, które planujesz obsługiwać oraz sposób, w jaki te typy powinny być analizowane.
Solrconfig.xml
- Zawiera różne ustawienia, które kontrolują zachowanie rdzenia Solr, takie jak moduł obsługi żądań, moduł wysyłania żądań, komponenty zapytań, moduły obsługi aktualizacji itp.
Zapytanie w Solr
Zobaczmy teraz, jak wysyłać zapytania do wyników Solr w interfejsie administratora Solr.
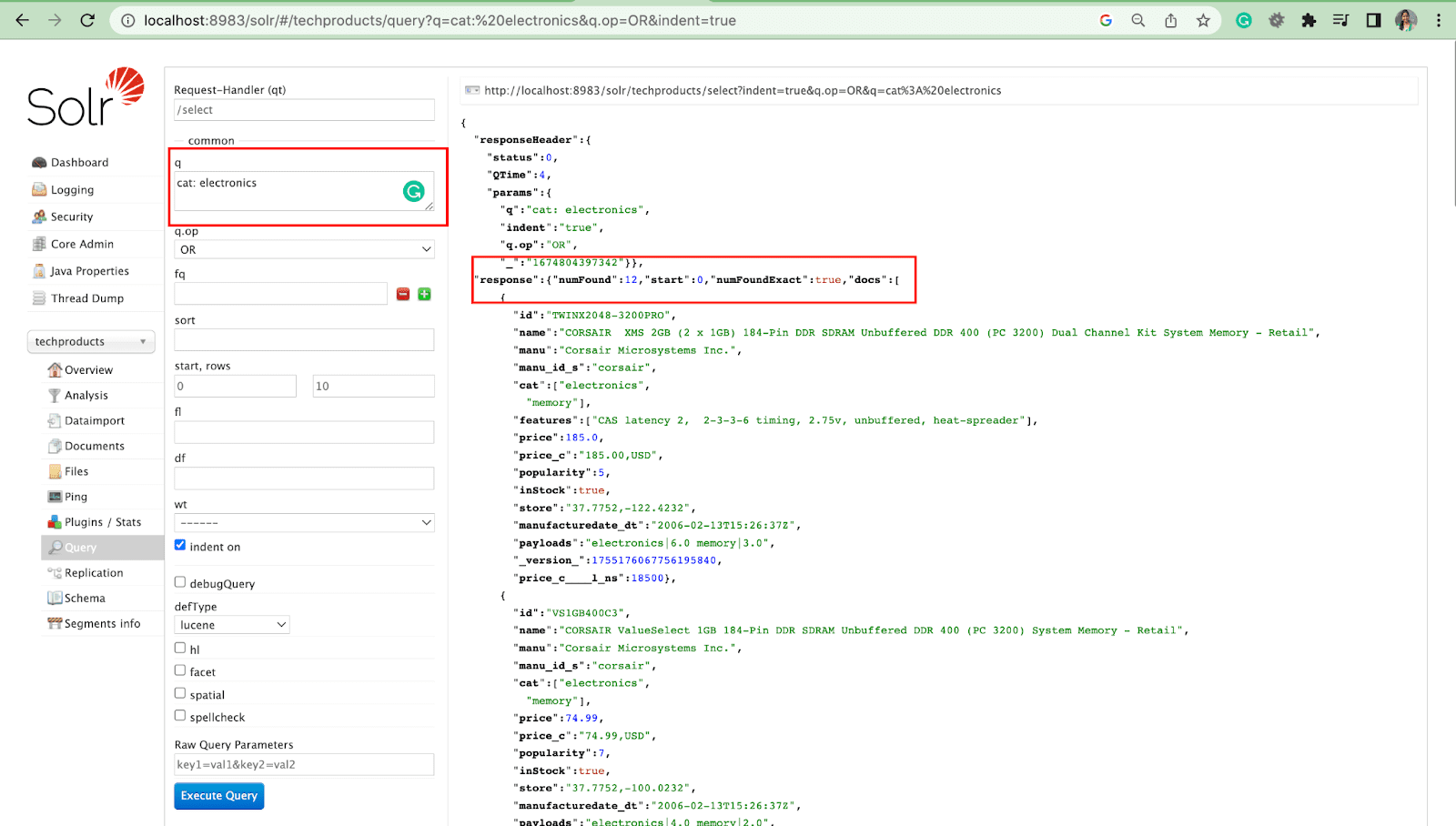
Parametr zapytania
- Parametry lokalne to argumenty w żądaniu Solr, które są specyficzne dla parametru zapytania.
Na przykład: kot: elektronika
Parametr zapytania z operacjami
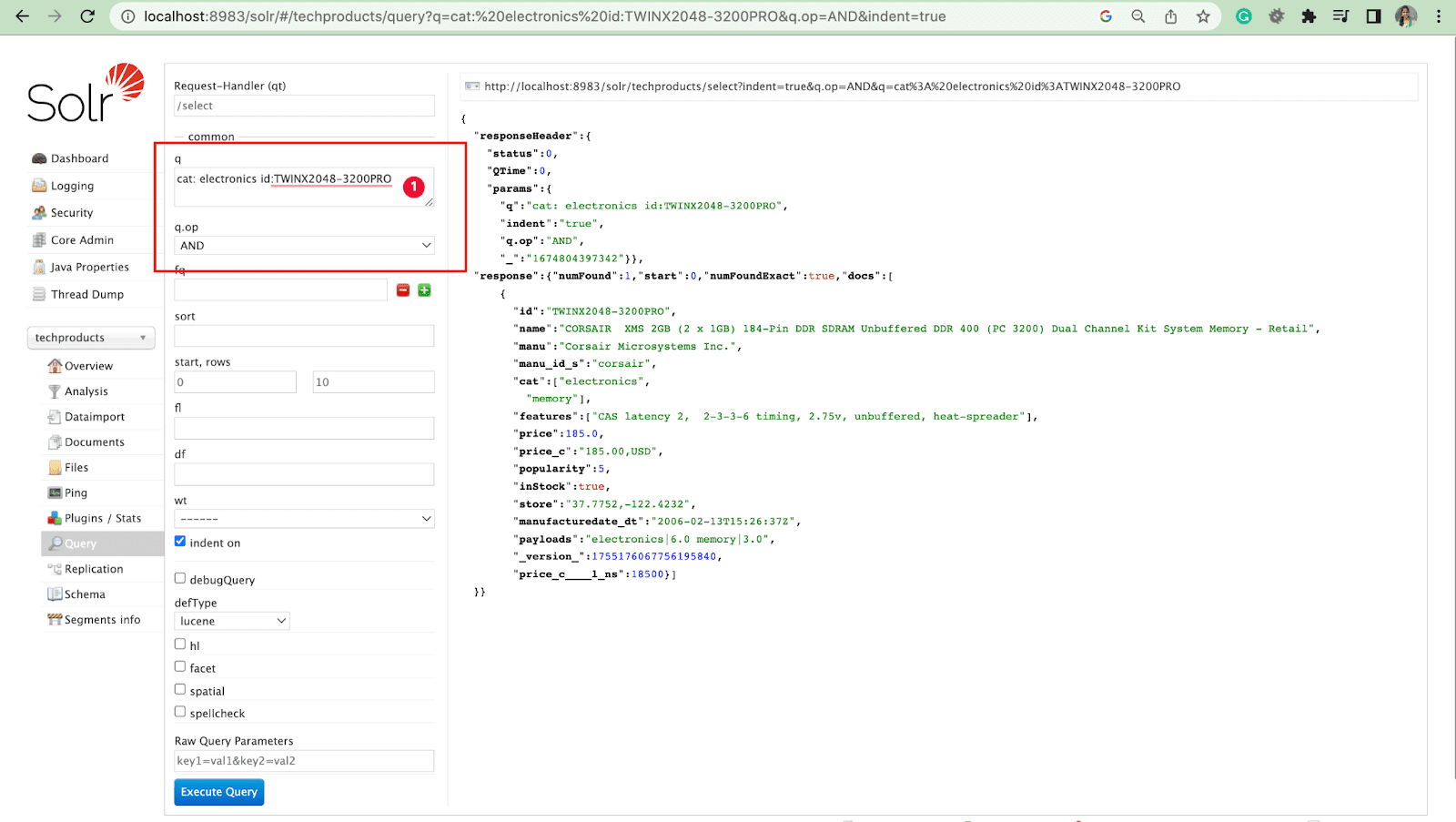
- Możemy wysyłać zapytania do wielu pól za pomocą operacji.
Na przykład: kot: identyfikator elektroniki: TWINX2048-3200PRO z q.op AND
[LUB]
kot: elektronika ORAZ id: TWINX2048-3200PRO
[LUB]
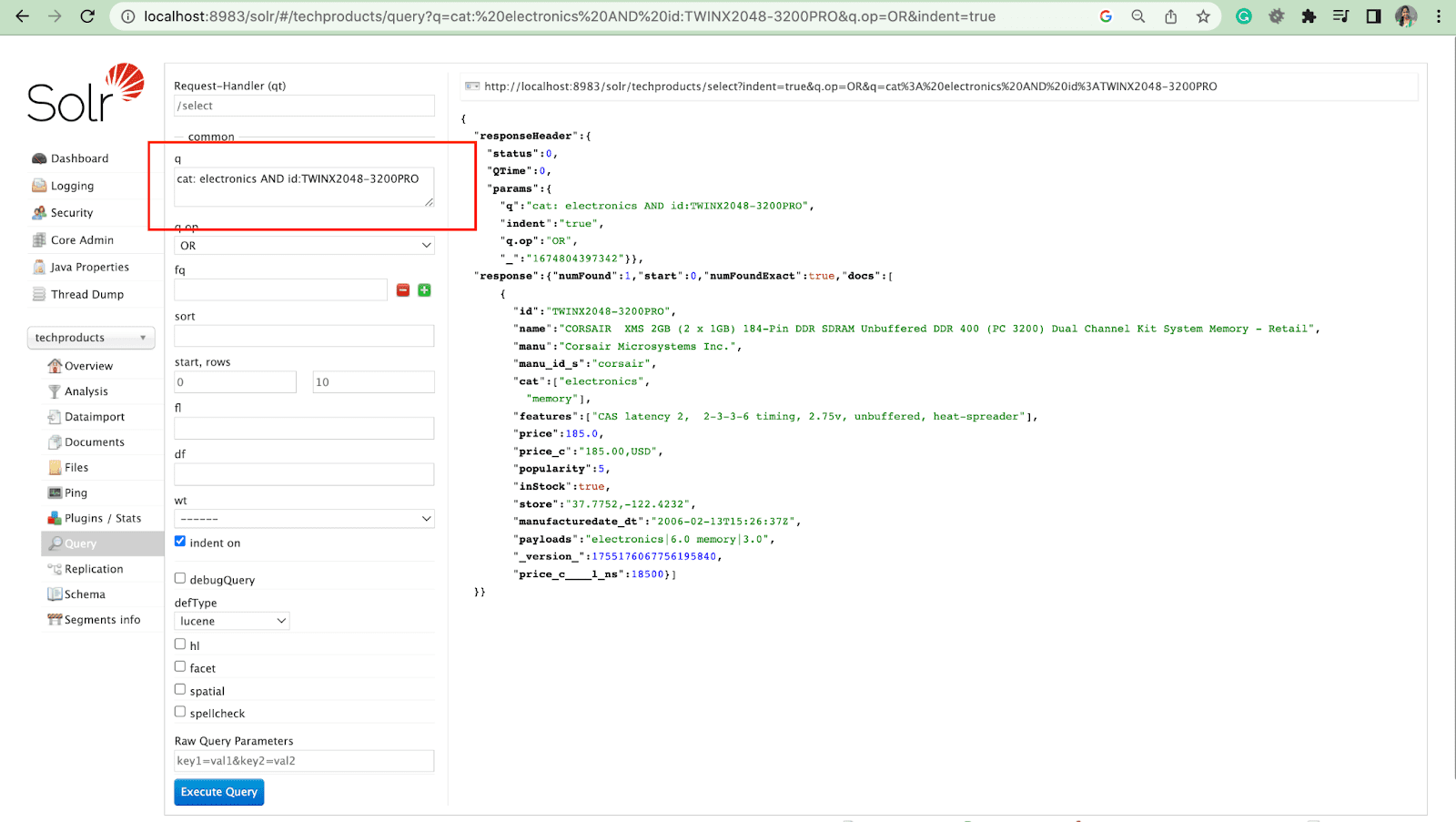
Filtruj zapytanie
Zapytanie filtrujące pomaga zawęzić wyniki wyszukiwania. Zapytanie można określić za pomocą parametru fq, aby ograniczyć, które dokumenty są zwracane w nadzbiorze, bez wpływu na wynik.
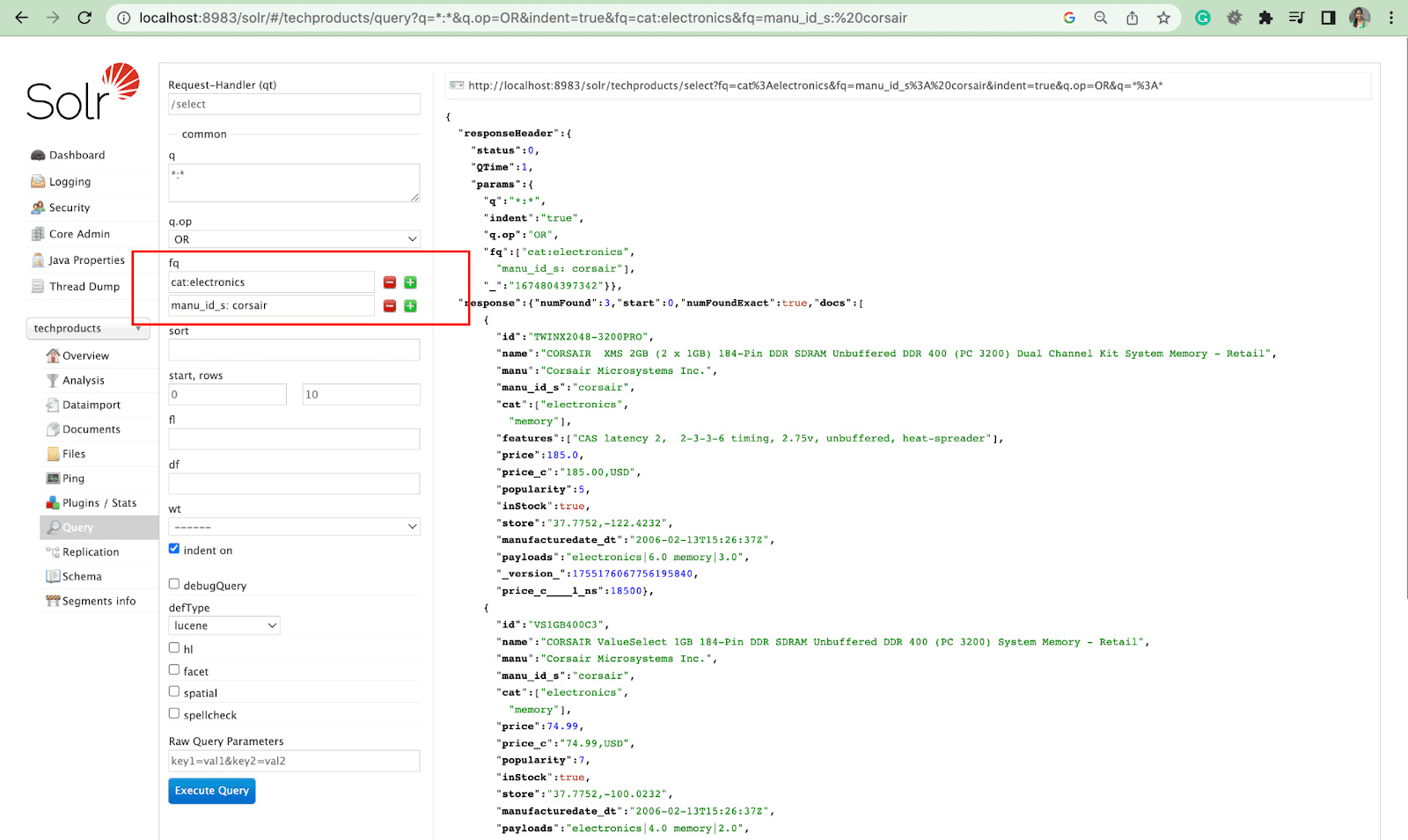
Sortuj parametr
Parametr sort porządkuje wyniki wyszukiwania w porządku rosnącym (asc) lub malejącym (desc). W zależności od zawartości, parametr może być używany numerycznie lub alfabetycznie.
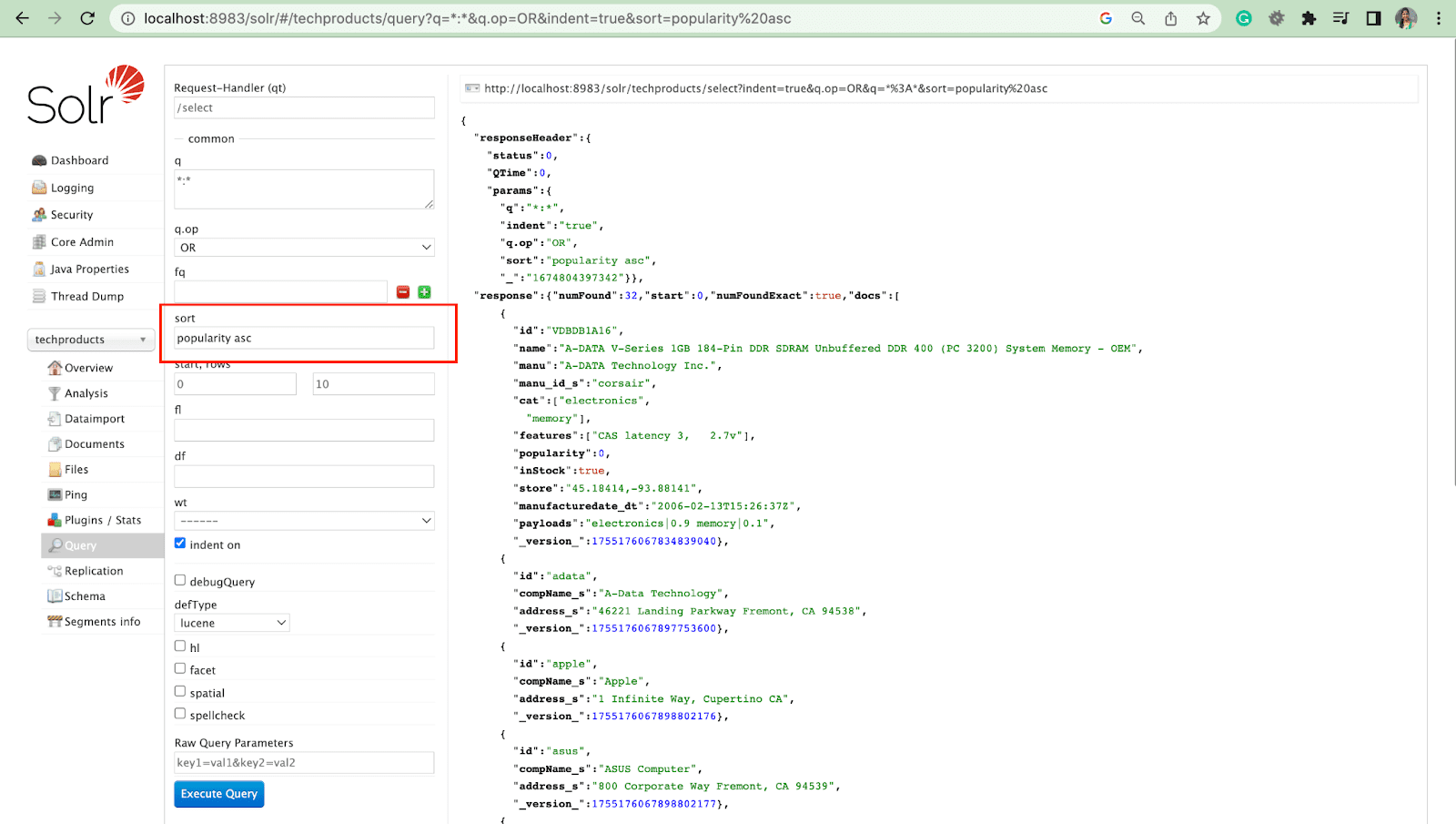
Parametr wierszy
Parametr rows umożliwia podział wyników zapytania na strony.
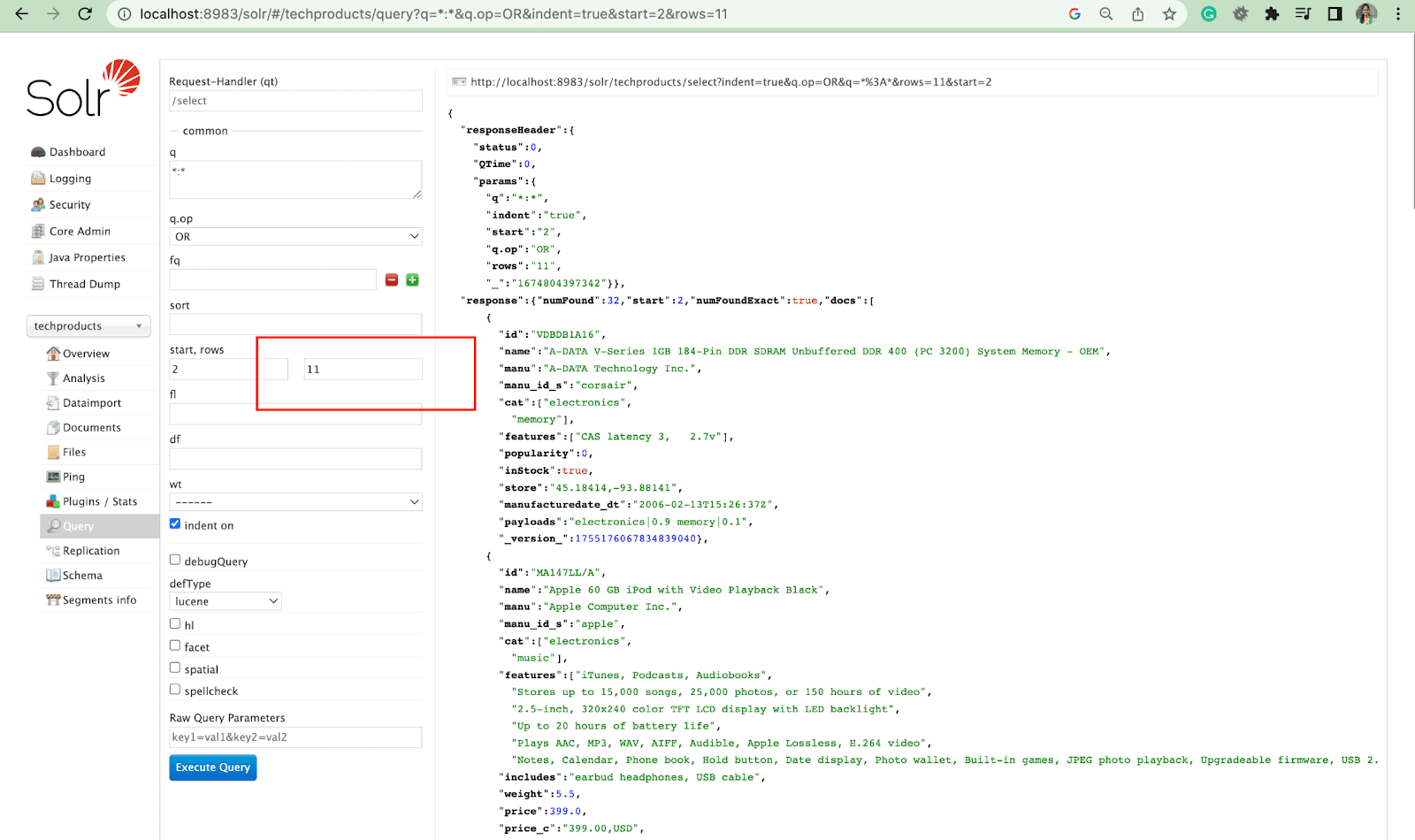
Parametr listy pól
Parametr fl ogranicza informacje zawarte w odpowiedzi na zapytanie do określonej listy pól.
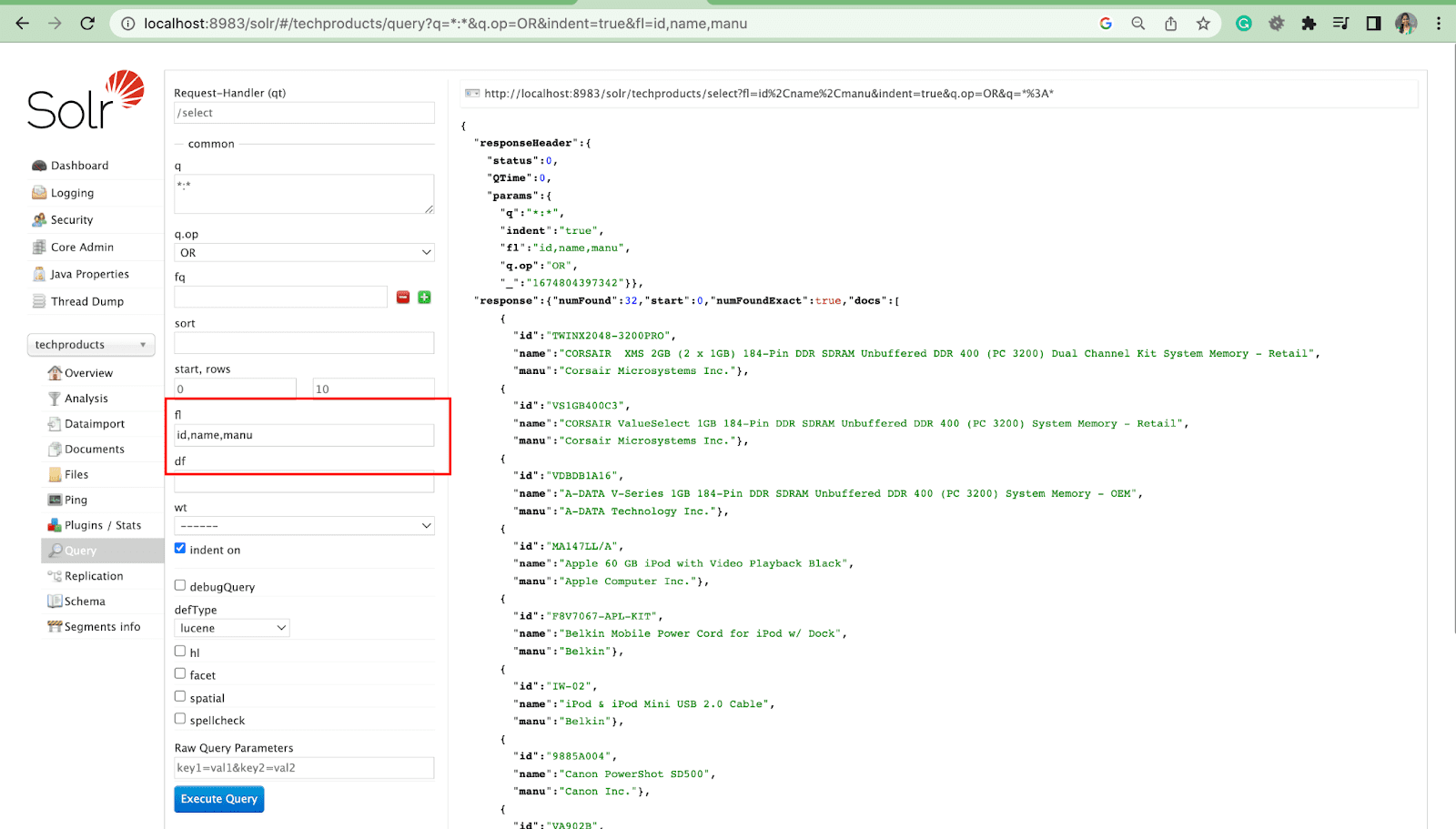
Pole domyślne Parametr
Domyślny parametr pola to domyślne pole dla parametru zapytania.
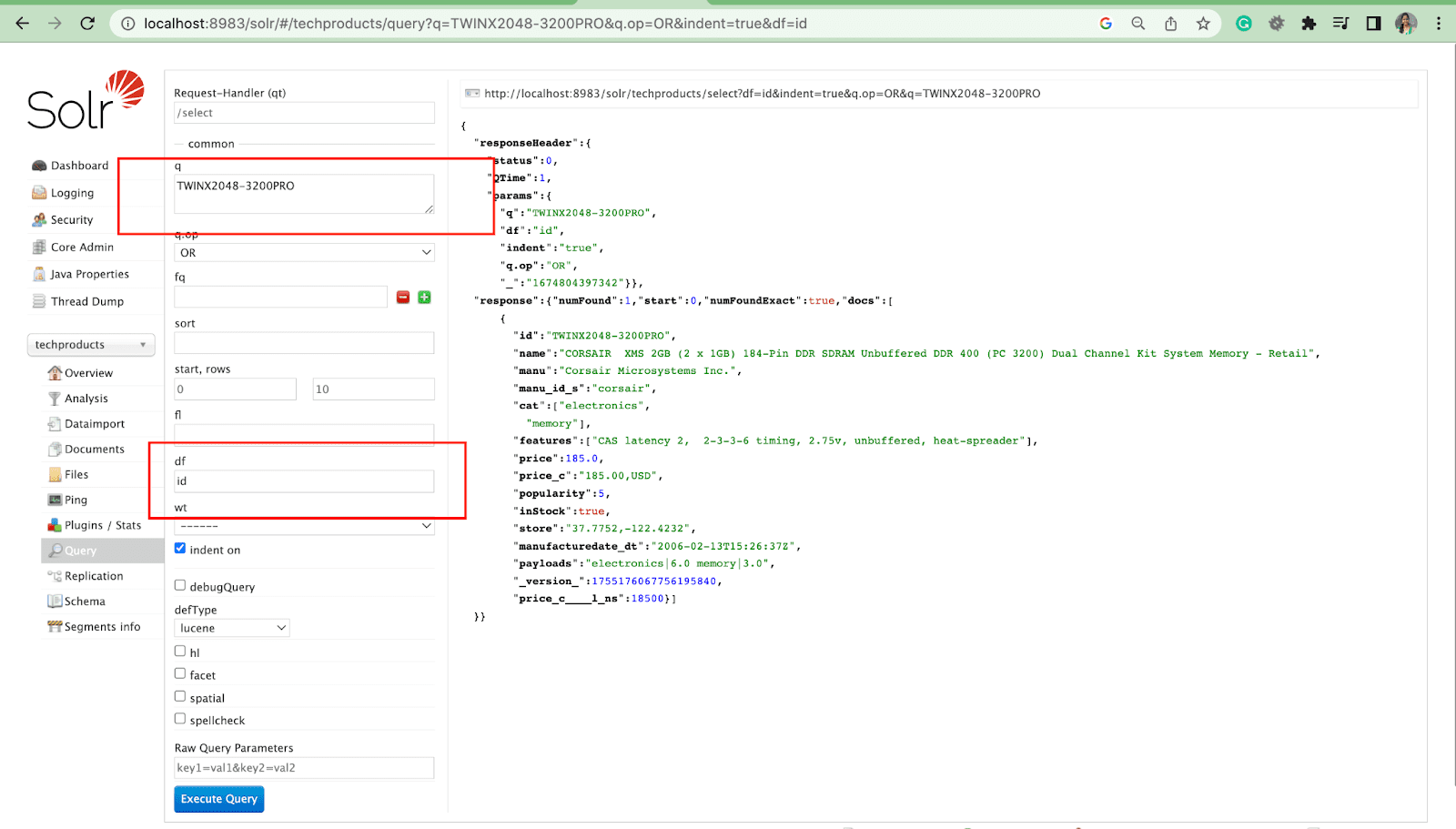
Najważniejsze parametry
Funkcja podświetlania w Solr umożliwia włączenie fragmentów dokumentów pasujących do zapytania.
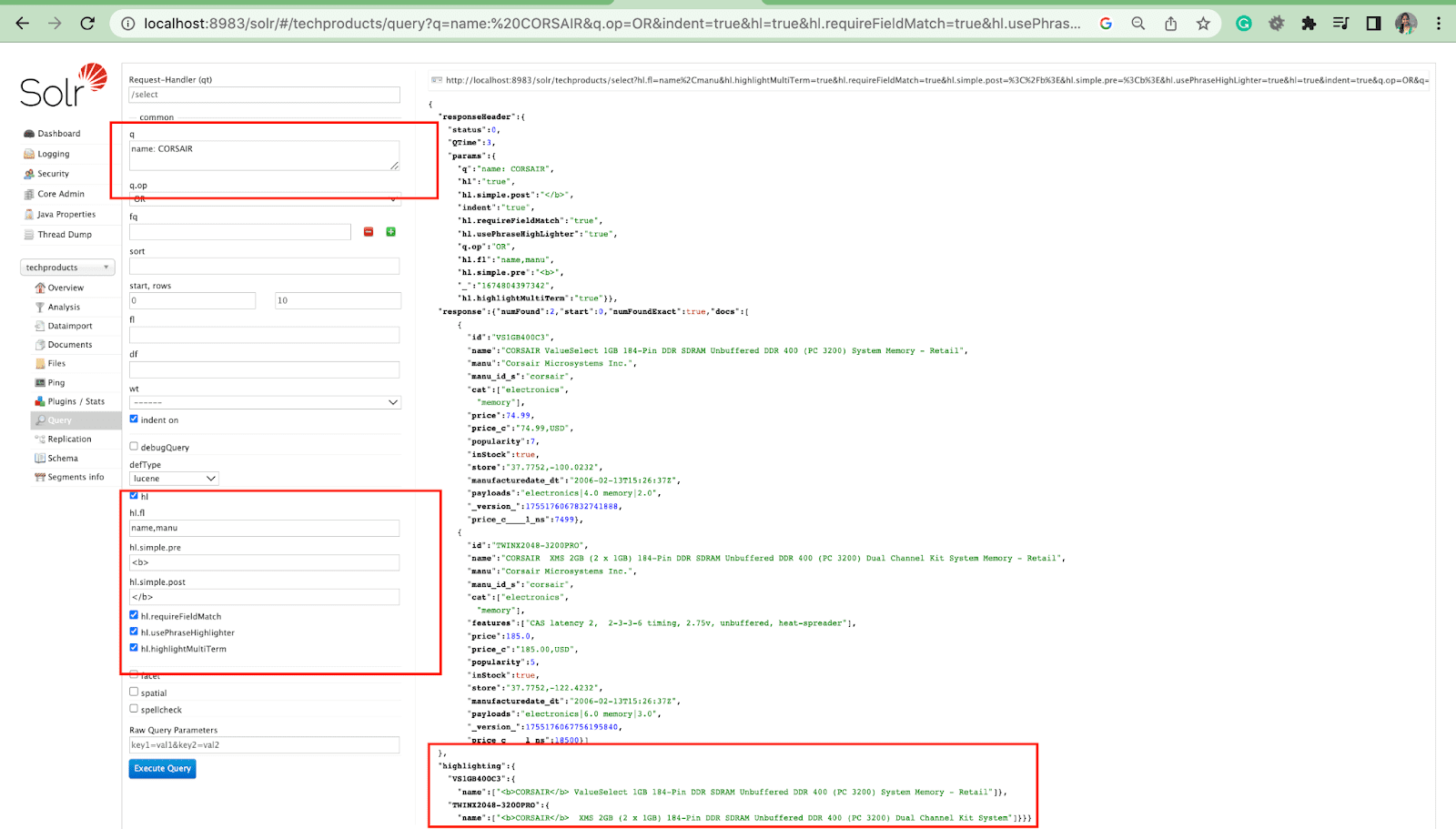
Niektóre z najczęstszych parametrów podświetlenia to:
- Hl.fl — Podświetla listę pól.
- Hl.simple.pre — określa, który „znacznik” powinien zostać użyty przed podświetlonym słowem.
- Hl.simple.post — określa, który „tag” powinien zostać użyty po wyróżnionym terminie.
- hl.highlightMultiTerm - Jeśli jest ustawiony na true , Solr podświetli zapytania wieloznaczne. Jeśli false , nie zostaną w ogóle podświetlone.
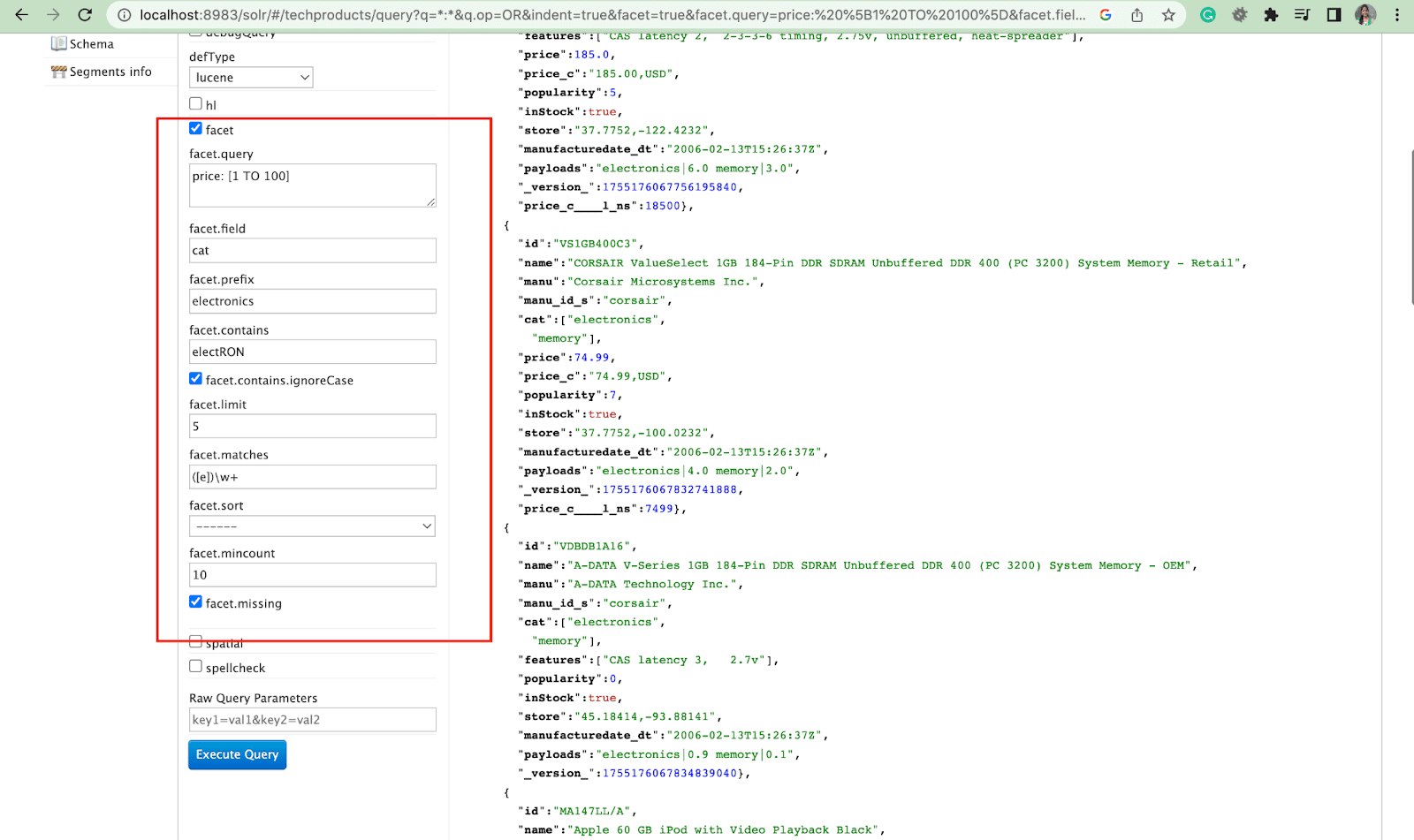
Aspekt:
Aspekty umożliwiają użytkownikom przeglądanie i udoskonalanie dużych zestawów wyników wyszukiwania. Są one wyświetlane w interfejsie użytkownika jako pola wyboru, listy rozwijane lub inne elementy sterujące. Dwa ogólne parametry kontrolujące aspekty to:
- Parametr aspektu
Korzystając z parametru facet, użytkownicy mogą generować aspekty na podstawie wartości jednego lub kilku pól w swoim indeksie wyszukiwania. W wynikach wyszukiwania można skonfigurować parametr aspektu, aby kontrolować sposób generowania i wyświetlania aspektów.
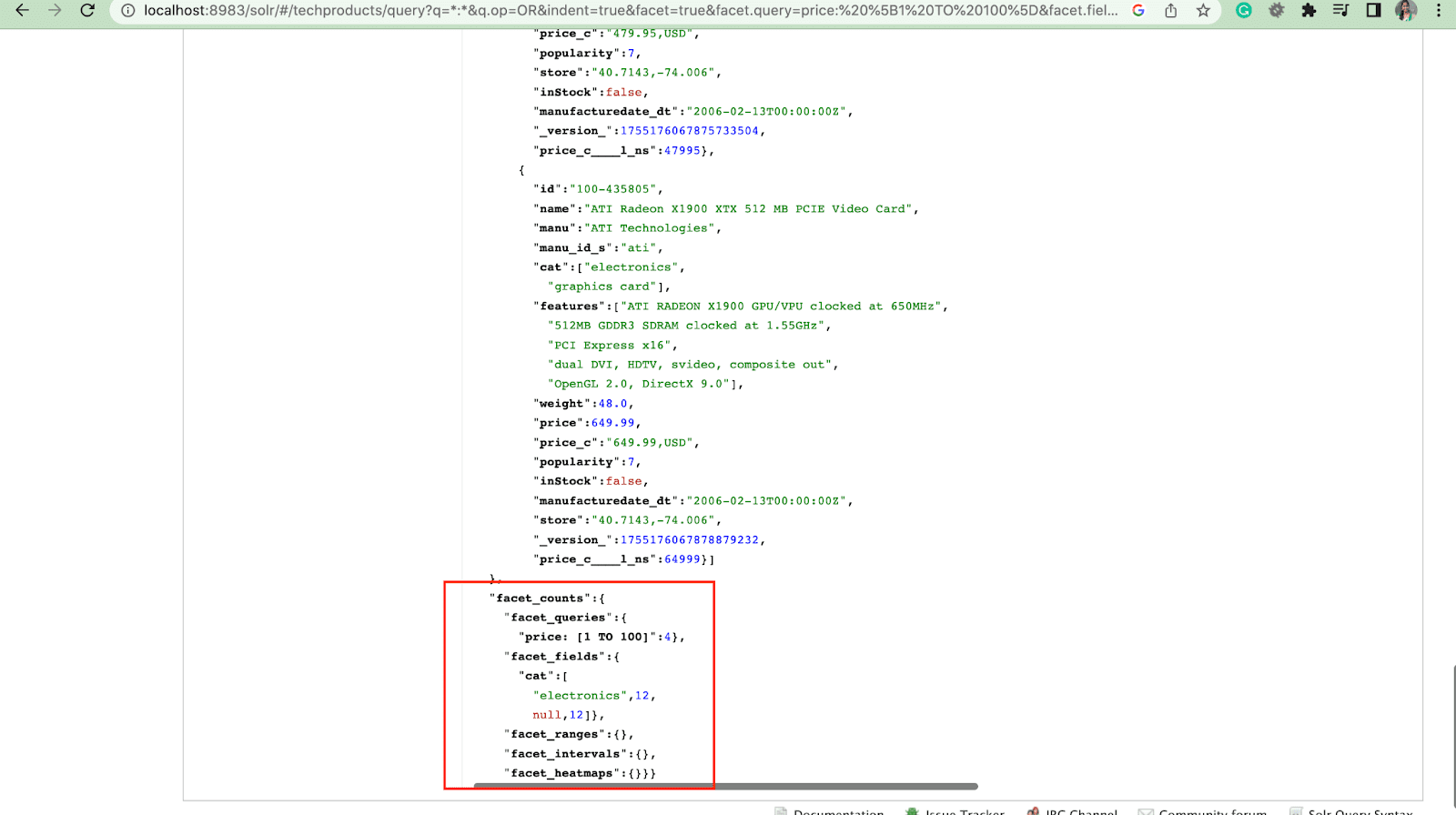
2. Parametr Facet.query
Gdy użytkownik umieści parametr facet.query w swoim zapytaniu Solr, Solr wygeneruje listę liczników aspektów odpowiadających liczbie dokumentów w indeksie pasujących do każdego zapytania. Facet.query jest przydatny, gdy chcesz generować aspekty na podstawie złożonych kryteriów wyszukiwania, których nie można łatwo przedstawić za pomocą prostej wartości pola.
Istnieje kilka innych parametrów aspektów, takich jak facet.field (do określenia pól, które powinny być użyte do generowania aspektów) , facet.limit (maksymalna liczba aspektów do wyświetlenia dla każdego pola) , facet.mincount (minimalna liczba dokumentów potrzebnych do aspekt, który ma zostać uwzględniony w odpowiedzi) , facet.sort (określa kolejność wyświetlania wartości aspektów) .
Końcowe przemyślenia
Apache Solr to bardzo wszechstronna wyszukiwarka, która oferuje wiele interesujących funkcji, które można dostosować do własnych wymagań. Drupal bardzo dobrze współpracuje z Apache Solr. Jeśli szukasz ekspertów od Drupala, którzy skonfigurują potężną wyszukiwarkę dla Twojego nowego projektu, z przyjemnością posuniemy się dalej!