
기계 학습의 SVM(Support Vector Machine)
게시 됨: 2023-01-04Support Vector Machine은 가장 널리 사용되는 기계 학습 알고리즘 중 하나입니다. 효율적이며 제한된 데이터 세트에서 훈련할 수 있습니다. 그러나 그것은 무엇입니까?
서포트 벡터 머신(SVM)이란 무엇입니까?
서포트 벡터 머신은 감독 학습을 사용하여 이진 분류를 위한 모델을 생성하는 머신 러닝 알고리즘입니다. 그것은 한 입입니다. 이 기사에서는 SVM과 이것이 자연어 처리와 어떻게 관련되는지 설명합니다. 하지만 먼저 서포트 벡터 머신이 어떻게 작동하는지 분석해 보겠습니다.
SVM은 어떻게 작동합니까?
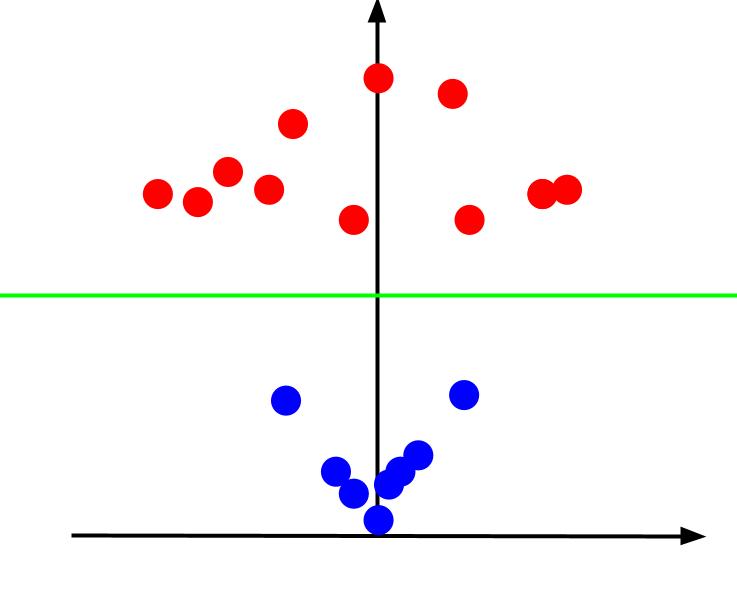
데이터에 x와 y의 두 가지 기능과 하나의 출력(빨간색 또는 파란색 분류)이 있는 간단한 분류 문제를 생각해 보십시오. 다음과 같은 가상의 데이터 세트를 그릴 수 있습니다.
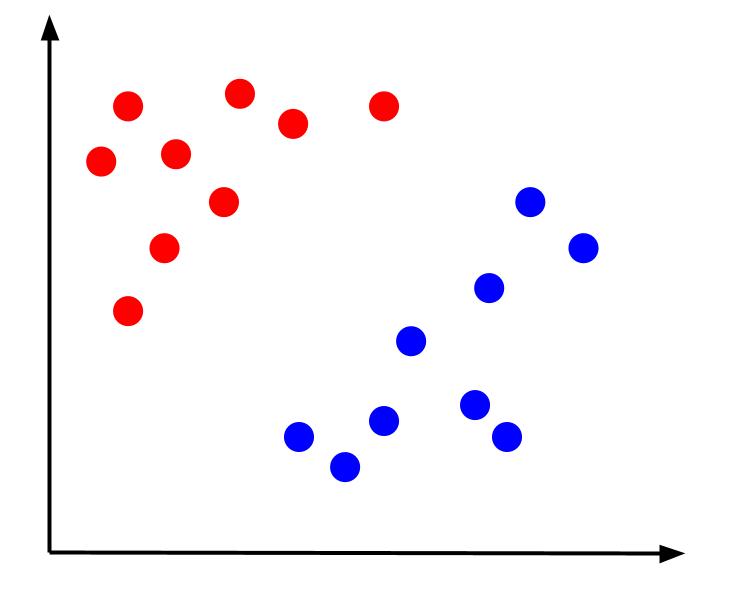
이와 같은 데이터가 주어지면 작업은 결정 경계를 만드는 것입니다. 결정 경계는 데이터 포인트의 두 클래스를 구분하는 선입니다. 이것은 동일한 데이터 세트이지만 결정 경계가 있습니다.
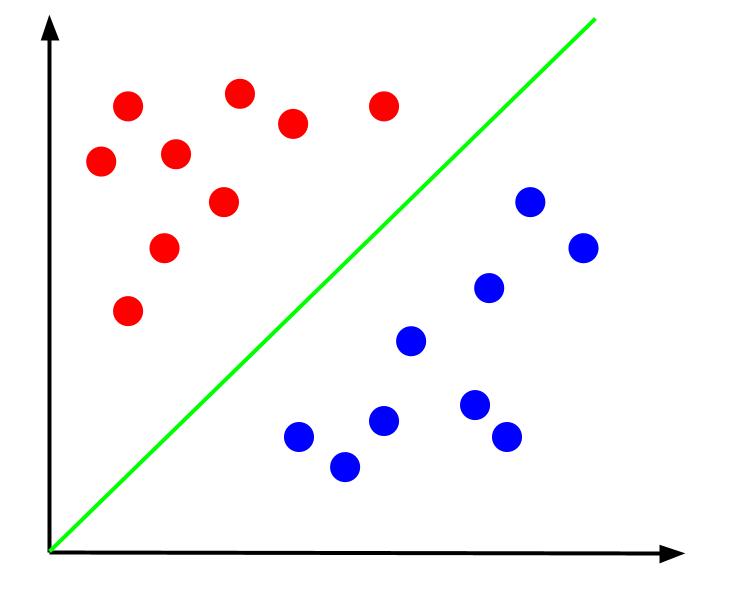
이 결정 경계를 사용하면 결정 경계와 관련하여 데이터 포인트가 속한 클래스를 예측할 수 있습니다. Support Vector Machine 알고리즘은 포인트를 분류하는 데 사용할 최상의 결정 경계를 생성합니다.
그러나 최선의 결정 경계란 무엇을 의미합니까?
최상의 결정 경계는 지원 벡터 중 하나로부터의 거리를 최대화하는 것이라고 주장할 수 있습니다. 지원 벡터는 반대 클래스에 가장 가까운 클래스의 데이터 포인트입니다. 이러한 데이터 포인트는 다른 클래스와의 근접성 때문에 오분류의 위험이 가장 큽니다.
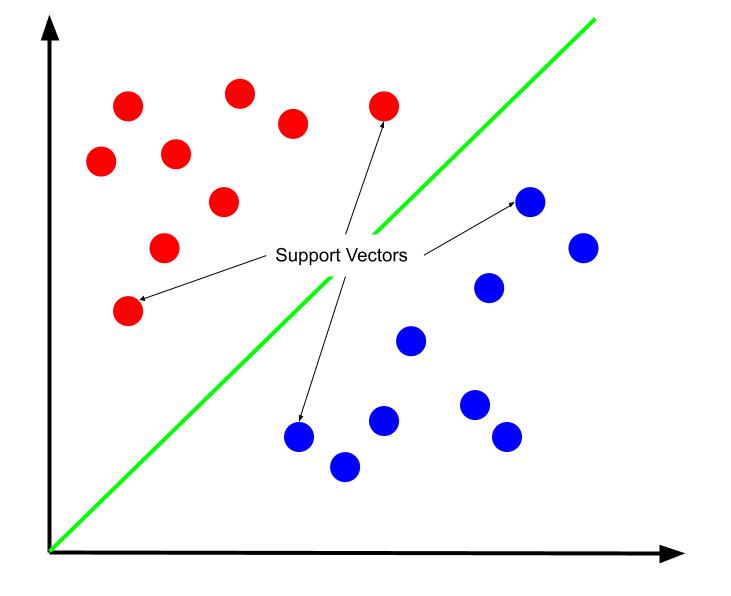
따라서 서포트 벡터 머신의 훈련에는 서포트 벡터 사이의 마진을 최대화하는 선을 찾는 것이 포함됩니다.
또한 결정 경계가 지원 벡터에 상대적으로 배치되기 때문에 결정 경계의 위치를 결정하는 유일한 요소라는 점에 유의해야 합니다. 따라서 다른 데이터 포인트는 중복됩니다. 따라서 교육에는 지원 벡터만 필요합니다.
이 예에서 형성된 결정 경계는 직선입니다. 이는 데이터 세트에 두 가지 기능만 있기 때문입니다. 데이터 세트에 세 가지 특징이 있는 경우 형성되는 결정 경계는 선이 아닌 평면입니다. 그리고 4개 이상의 특징이 있는 경우 결정 경계를 초평면이라고 합니다.
비선형적으로 분리 가능한 데이터
위의 예에서는 플로팅 시 선형 결정 경계로 구분할 수 있는 매우 간단한 데이터를 고려했습니다. 다음과 같이 데이터가 플롯되는 다른 경우를 고려하십시오.
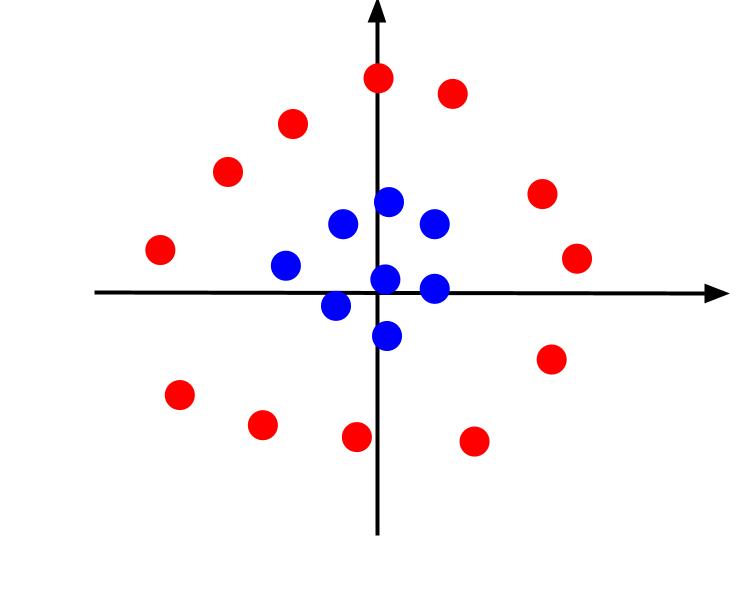
이 경우 한 줄로 데이터를 구분하는 것은 불가능합니다. 그러나 우리는 또 다른 기능인 z를 만들 수 있습니다. 그리고 이 특징은 방정식으로 정의될 수 있습니다: z = x^2 + y^2. z를 평면에 세 번째 축으로 추가하여 3차원으로 만들 수 있습니다.
x축이 수평이고 z축이 수직인 각도에서 3D 플롯을 보면 다음과 같은 것을 볼 수 있습니다.
z 값은 이전 XY 평면의 다른 점과 관련하여 점이 원점에서 얼마나 떨어져 있는지를 나타냅니다. 결과적으로 원점에 가까운 파란색 점은 z 값이 낮습니다.
원점에서 더 멀리 있는 빨간색 점은 z 값이 더 높지만 z 값에 대해 플로팅하면 그림과 같이 선형 결정 경계로 구분할 수 있는 명확한 분류가 제공됩니다.
이것은 Support Vector Machines에서 사용되는 강력한 아이디어입니다. 보다 일반적으로 데이터 포인트가 선형 경계로 분리될 수 있도록 차원을 더 높은 수의 차원으로 매핑하는 아이디어입니다. 이를 담당하는 함수가 커널 함수입니다. 시그모이드, 선형, 비선형 및 RBF와 같은 많은 커널 함수가 있습니다.
이러한 기능을 보다 효율적으로 매핑하기 위해 SVM은 커널 트릭을 사용합니다.
기계 학습의 SVM
Support Vector Machine은 Decision Trees 및 Neural Networks와 같은 인기 있는 알고리즘과 함께 기계 학습에 사용되는 많은 알고리즘 중 하나입니다. 다른 알고리즘보다 적은 데이터로 잘 작동하기 때문에 선호됩니다. 일반적으로 다음을 수행하는 데 사용됩니다.
- Text Classification : 댓글, 리뷰 등의 텍스트 데이터를 하나 이상의 카테고리로 분류
- 얼굴 인식 : 이미지를 분석하여 얼굴을 감지하여 증강현실을 위한 필터 추가 등의 작업 수행
- 이미지 분류 : 서포트 벡터 머신은 다른 접근 방식에 비해 효율적으로 이미지를 분류할 수 있습니다.
텍스트 분류 문제
인터넷은 수많은 텍스트 데이터로 가득 차 있습니다. 그러나 이 데이터의 대부분은 구조화되어 있지 않고 레이블이 지정되어 있지 않습니다. 이 텍스트 데이터를 더 잘 사용하고 더 잘 이해하려면 분류가 필요합니다. 텍스트가 분류되는 경우의 예는 다음과 같습니다.
- 사람들이 원하는 주제를 팔로우할 수 있도록 트윗을 주제별로 분류할 때
- 이메일이 소셜, 프로모션 또는 스팸으로 분류되는 경우
- 댓글이 공개된 게시판에서 혐오스럽거나 음란하다고 분류되는 경우
SVM이 자연어 분류와 작동하는 방식
Support Vector Machine은 텍스트를 특정 주제에 속하는 텍스트와 주제에 속하지 않는 텍스트로 분류하는 데 사용됩니다. 이것은 먼저 텍스트 데이터를 여러 기능이 있는 데이터 세트로 변환하고 표현함으로써 달성됩니다.
이를 수행하는 한 가지 방법은 데이터 세트의 모든 단어에 대한 기능을 만드는 것입니다. 그런 다음 모든 텍스트 데이터 포인트에 대해 각 단어가 나타나는 횟수를 기록합니다. 따라서 데이터 세트에서 고유한 단어가 발생한다고 가정합니다. 데이터 세트에 기능이 있습니다.
또한 이러한 데이터 요소에 대한 분류를 제공합니다. 이러한 분류는 텍스트로 레이블이 지정되지만 대부분의 SVM 구현에는 숫자 레이블이 필요합니다.
따라서 훈련 전에 이러한 레이블을 숫자로 변환해야 합니다. 데이터 세트가 준비되면 이러한 기능을 좌표로 사용하여 SVM 모델을 사용하여 텍스트를 분류할 수 있습니다.
Python에서 SVM 만들기
Python에서 SVM(Support Vector Machine)을 생성하려면 sklearn.svm 라이브러리의 SVC 클래스를 사용할 수 있습니다. 다음은 SVC 클래스를 사용하여 Python에서 SVM 모델을 빌드하는 방법의 예입니다.
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) 이 예에서는 먼저 sklearn.svm 라이브러리에서 SVC 클래스를 가져옵니다. 그런 다음 데이터 세트를 로드하고 훈련 및 테스트 세트로 분할합니다.
다음으로 SVC 객체를 인스턴스화하고 kernel 매개변수를 '선형'으로 지정하여 SVM 모델을 생성합니다. 그런 다음 fit 방법을 사용하여 훈련 데이터에서 모델을 훈련하고 score 방법을 사용하여 테스트 데이터에서 모델을 평가합니다. score 메서드는 콘솔에 출력되는 모델의 정확도를 반환합니다.
정규화의 강도를 제어하는 C 매개변수 및 특정 커널의 커널 계수를 제어하는 gamma 매개변수와 같은 SVC 객체에 대한 다른 매개변수를 지정할 수도 있습니다.
SVM의 이점
다음은 지원 벡터 머신(SVM)을 사용할 때 얻을 수 있는 몇 가지 이점 목록입니다.
- 효율적 : SVM은 일반적으로 특히 샘플 수가 많을 때 훈련하기에 효율적입니다.
- 노이즈 에 강인함: SVM은 다른 분류기보다 노이즈에 덜 민감한 최대 마진 분류기를 찾으려고 하기 때문에 훈련 데이터의 노이즈에 상대적으로 강합니다.
- 메모리 효율성: SVM은 주어진 시간에 교육 데이터의 하위 집합만 메모리에 있어야 하므로 다른 알고리즘보다 메모리 효율성이 높습니다.
- 고차원 공간에서 효과적: SVM은 기능 수가 샘플 수를 초과하는 경우에도 여전히 잘 작동할 수 있습니다.
- 다양성 : SVM은 분류 및 회귀 작업에 사용할 수 있으며 선형 및 비선형 데이터를 포함한 다양한 유형의 데이터를 처리할 수 있습니다.
이제 SVM(Support Vector Machine)을 배우기 위한 최고의 리소스를 살펴보겠습니다.
학습 리소스
서포트 벡터 머신 소개
서포트 벡터 머신 소개에 관한 이 책은 커널 기반 학습 방법을 포괄적이고 점진적으로 소개합니다.
| 시사 | 제품 | 평가 | 가격 | |
|---|---|---|---|---|
 | 서포트 벡터 머신 및 기타 커널 기반 학습 방법 소개 | $75.00 | 아마존에서 구매 |
서포트 벡터 머신 이론에 대한 확고한 기반을 제공합니다.

지원 벡터 머신 애플리케이션
첫 번째 책이 서포트 벡터 머신 이론에 초점을 맞추었다면 서포트 벡터 머신 응용 프로그램에 관한 이 책은 실제 적용에 중점을 둡니다.
| 시사 | 제품 | 평가 | 가격 | |
|---|---|---|---|---|
 | 지원 벡터 머신 애플리케이션 | $15.52 | 아마존에서 구매 |
이미지 처리, 패턴 감지 및 컴퓨터 비전에서 SVM이 어떻게 사용되는지 살펴봅니다.
서포트 벡터 머신(정보 과학 및 통계)
지원 벡터 기계(정보 과학 및 통계)에 관한 이 책의 목적은 다양한 응용 프로그램에서 지원 벡터 기계(SVM)의 효과 뒤에 숨겨진 원칙에 대한 개요를 제공하는 것입니다.
| 시사 | 제품 | 평가 | 가격 | |
|---|---|---|---|---|
 | 서포트 벡터 머신(정보 과학 및 통계) | $167.36 | 아마존에서 구매 |
저자는 SVM의 성공에 기여하는 몇 가지 요인을 강조합니다. 여기에는 제한된 수의 조정 가능한 매개변수로 잘 수행할 수 있는 능력, 다양한 유형의 오류 및 이상 현상에 대한 저항성, 다른 방법에 비해 효율적인 계산 성능이 포함됩니다.
커널로 배우기
“Learning with Kernels”는 벡터 머신(SVM) 및 관련 커널 기술을 지원하는 독자를 소개하는 책입니다.
| 시사 | 제품 | 평가 | 가격 | |
|---|---|---|---|---|
 | 커널을 통한 학습: 지원 벡터 머신, 정규화, 최적화 및 그 이상(적응… | $80.00 | 아마존에서 구매 |
독자에게 기계 학습에서 커널 알고리즘을 사용하기 시작하는 데 필요한 수학 및 지식에 대한 기본적인 이해를 제공하도록 설계되었습니다. 이 책은 SVM 및 커널 방법에 대한 철저하면서도 접근 가능한 소개를 제공하는 것을 목표로 합니다.
Sci-kit Learn으로 벡터 머신 지원
Coursera 프로젝트 네트워크에서 제공하는 Sci-kit Learn이 포함된 이 온라인 Support Vector Machines 과정은 널리 사용되는 기계 학습 라이브러리인 Sci-Kit Learn을 사용하여 SVM 모델을 구현하는 방법을 설명합니다.

또한 SVM의 이론을 배우고 강점과 한계를 파악합니다. 이 과정은 초급 수준이며 약 2.5시간이 소요됩니다.
Python의 서포트 벡터 머신: 개념 및 코드
Udemy가 제공하는 Python의 Support Vector Machines에 대한 이 유료 온라인 과정은 최대 6시간 분량의 비디오 기반 교육을 제공하며 인증과 함께 제공됩니다.

SVM과 Python에서 SVM을 견고하게 구현하는 방법을 다룹니다. 또한 Support Vector Machines의 비즈니스 응용 프로그램을 다룹니다.
머신 러닝 및 AI: Python에서 벡터 머신 지원
기계 학습 및 AI에 대한 이 과정에서는 이미지 인식, 스팸 감지, 의료 진단 및 회귀 분석을 비롯한 다양한 실제 응용 프로그램에 SVM(지원 벡터 머신)을 사용하는 방법을 배웁니다.

Python 프로그래밍 언어를 사용하여 이러한 애플리케이션에 대한 ML 모델을 구현합니다.
마지막 말
이 기사에서 우리는 서포트 벡터 머신의 이론에 대해 간략하게 배웠습니다. 우리는 기계 학습 및 자연어 처리에서의 응용 프로그램에 대해 배웠습니다.
우리는 또한 scikit-learn 을 사용한 구현이 어떤 모습인지 보았습니다. 또한 Support Vector Machines의 실제 응용 프로그램과 이점에 대해 이야기했습니다.
이 문서는 단지 소개에 불과했지만 추가 리소스에서는 지원 벡터 머신에 대해 자세히 설명하는 것이 좋습니다. SVM이 얼마나 다재다능하고 효율적인지를 고려할 때 SVM은 데이터 과학자 및 ML 엔지니어로 성장하기 위해 이해할 가치가 있습니다.
다음으로 최고의 기계 학습 모델을 확인할 수 있습니다.