
Apache Solr 최대한 활용하기: 검색 인덱싱의 기술 탐색
게시 됨: 2023-02-21검색 기능은 사용자가 원하는 것을 쉽고 빠르게 찾을 수 있도록 하여 웹 사이트의 사용자 경험을 향상시킵니다. 대규모 웹 사이트, 전자 상거래 사이트 및 동적 콘텐츠가 포함된 사이트(뉴스 사이트, 블로그)의 경우 더욱 그렇습니다.
Apache Solr는 모든 규모의 웹사이트에서 가장 널리 사용되는 검색 플랫폼 중 하나입니다. 기사, 제품, 고객 리뷰 등과 같은 많은 양의 데이터를 검색할 수 있는 Java 기반의 오픈 소스 검색 엔진입니다. 이 기사에서 Apache Solr에 대해 자세히 살펴보십시오.
Drupal에서 Apache Solr를 구성하는 방법을 알아보려면 이 기사를 확인하십시오.

Apache Solr이 왜 그렇게 인기가 있습니까?
Apache Solr는 빠르고 유연하며 전체 텍스트 검색, 적중 강조 표시 (일치하는 검색어 강조 표시), 패싯 검색 (보다 세분화된 검색), 실시간 인덱싱 (새 콘텐츠를 즉시 인덱싱할 수 있음), 동적 클러스터링 ( 검색 결과를 그룹으로 구성), 데이터베이스 통합, NoSQL 기능 (비관계형 데이터베이스) 및 풍부한 문서 처리 (PDF, MS Office, Open office와 같은 다양한 문서 형식 색인 생성).
Apache Solr에 대한 몇 가지 유용한 정보:
- 처음에는 CNET 네트워크, Inc.에서 개발했습니다. 그들의 웹사이트 및 기사를 위한 검색 엔진으로. 나중에 오픈 소스화되어 최상위 Apache 프로젝트가 되었습니다.
- PHP, Java, Python 및 Ruby와 같은 여러 프로그래밍 언어를 지원합니다. 또한 이러한 언어에 대한 API도 제공합니다.
- 지리 공간 검색을 기본적으로 지원하므로 위치를 기반으로 콘텐츠를 검색할 수 있습니다. 부동산 웹사이트, 여행 웹사이트 등과 같은 사이트에 특히 유용합니다.
- 맞춤법 검사, 자동 완성, API 및 플러그인을 통한 맞춤 검색과 같은 고급 검색 기능을 지원합니다.
- 인덱싱 및 검색에 Lucene을 사용합니다.
루씬이란?
Apache Lucene은 애플리케이션에 검색 또는 정보 검색을 쉽게 추가할 수 있는 오픈 소스 Java 검색 라이브러리입니다. 다재다능하고 강력하며 정확하며 효율적인 검색 알고리즘에서 작동합니다.
전체 텍스트 검색 기능으로 알려져 있지만 Lucene은 문서 분류, 데이터 분석 및 정보 검색에도 사용할 수 있습니다. 또한 독일어, 프랑스어, 스페인어, 중국어, 일본어 등과 같은 영어 이외의 많은 언어를 지원합니다.
인덱싱이란 무엇입니까?
모든 검색 엔진은 인덱싱으로 시작합니다. 인덱싱은 빠른 검색을 용이하게 하기 위해 원본 데이터를 매우 효율적인 교차 참조 조회로 처리하는 것입니다.
검색 엔진은 데이터를 직접 인덱싱하지 않습니다. 텍스트는 먼저 토큰(원자 요소)으로 나뉩니다. 검색은 검색 인덱스를 참조하고 쿼리와 일치하는 문서를 검색하는 프로세스입니다.
인덱싱의 장점
- 빠르고 정확한 정보 검색(수집, 파싱 및 저장)
- 인덱싱이 없으면 검색 엔진이 모든 문서를 스캔하는 데 더 많은 시간이 필요합니다.
인덱싱 흐름
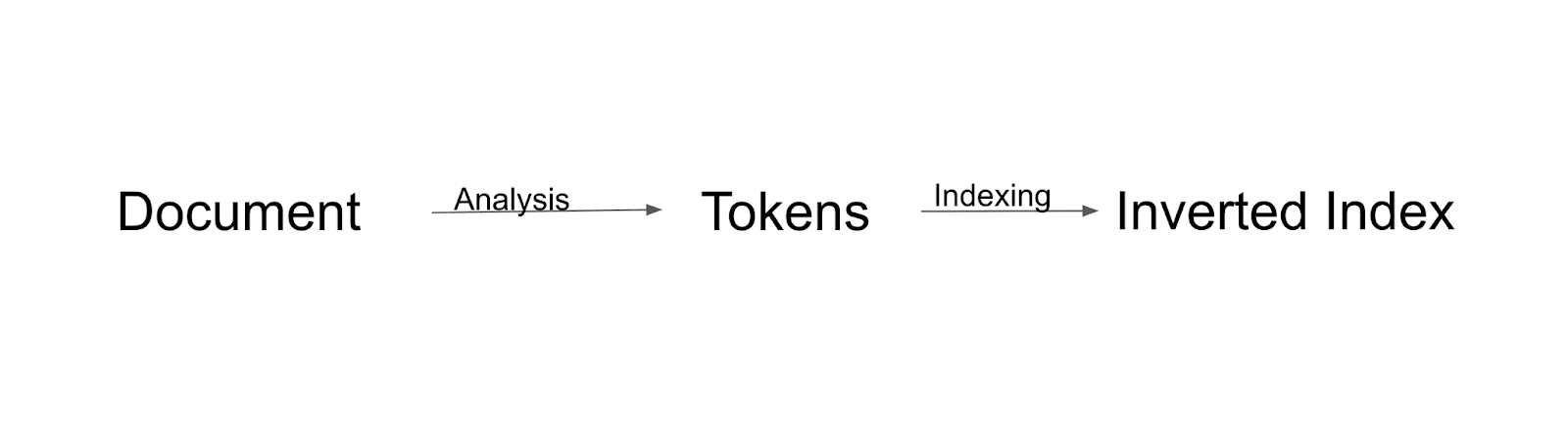
먼저 문서를 분석하고 토큰으로 분할합니다. 이러한 모든 토큰은 반전된 인덱스로 인덱싱됩니다. 반전 인덱스는 Solr가 인덱스를 빌드하는 방법입니다.
역인덱싱 작동 방식
3개의 문서가 있다고 가정해 보겠습니다.
- 나는 초콜릿을 사랑합니다 (D 1)
- 나는 초코케이크를 주문했다(D2)
- 큰 바닐라 케이크를 준비했습니다 (D 3)
토큰화 방식은 아래 표의 2번째 열과 같습니다.

"초콜릿"은 D1과 D2에서 사용할 수 있습니다.
"케이크"는 D2 및 D3에서 사용할 수 있습니다.
"Big"은 D3에서 사용할 수 있습니다.
"주문됨"은 D2에서 사용할 수 있습니다.
"준비됨"은 D3에서 사용할 수 있습니다.
"바닐라"는 D3에서 사용할 수 있습니다.
"나", "사랑"과 같은 단어가 토큰화되지 않은 것을 알 수 있습니다. Solr에서 색인화하거나 검색할 수 없는 중지 단어라고 합니다.
따라서 누군가 "초콜릿 케이크"라는 용어를 검색하면 엔진이 색인을 조사합니다. 문서를 찾는 대신 먼저 색인을 조사하여 "초콜릿" 및 "케이크"라는 단어가 어떤 문서에 속하는지 확인합니다. 이렇게 하면 특정 문서만 빠르고 쉽게 가져올 수 있습니다. 이를 역 인덱싱이라고 합니다.
스토리지 스키마
Apache Solr는 문서 기반 스토리지 스키마를 사용하고 모든 데이터를 컬렉션 내의 별도 문서로 저장합니다. 이를 통해 데이터를 효율적이고 유연하게 저장하고 검색할 수 있습니다.
Drupal에서 각 노드는 문서로 간주됩니다. 따라서 노드를 Apache Solr로 인덱싱하면 문서로 간주됩니다. 각 문서에는 여러 필드가 포함될 수 있습니다. Lucene에는 공통 글로벌 스키마가 없습니다. 즉, Apache Solr의 각 문서에서 모든 유형의 필드를 인덱싱할 수 있습니다.

Apache Solr 설치 방법
- 먼저 시스템에 Java가 설치되어 있는지 확인하십시오.
- 다음으로 https://solr.apache.org/downloads.html에서 Solr를 설치하겠습니다.
- Solr를 다운로드하고 압축을 풉니다.
- Solr 폴더에서 이 명령을 실행합니다.
◦ bin/solr -e techproducts
이렇게 하면 데모용 더미 코어가 생성되고 Solr 서버도 시작됩니다.
- 서버가 시작되면 브라우저로 이동하여 "http://localhost:8983/"을 입력합니다.
- Solr이 더미 코어와 함께 성공적으로 설치되었는지 확인하십시오.
디렉토리 구조
Solr을 설치하면 다음과 같은 많은 폴더가 표시됩니다.
문서 - Solr에 대한 문서 포함
Dist - Solr 기본 .jar 파일
Contrib - 애드온 플러그인 및 Solr의 특수 기능 포함
Bin - Solr의 스크립트
예 - solr 기능 시연 포함
서버 - Solr의 핵심. Solr 웹 애플리케이션, 로그, Solr 코어 포함

구성 파일
코어를 생성하려면 필수 파일 두 개가 필요합니다.
- Schema.xml
- Solrconfig.xml
Schema.xml
- 여기에는 지원할 계획인 필드 유형과 이러한 유형을 분석하는 방법이 포함됩니다.
Solrconfig.xml
- 요청 핸들러, 요청 디스패처, 쿼리 구성 요소, 업데이트 핸들러 등과 같은 Solr 코어의 동작을 제어하는 다양한 설정을 포함합니다.
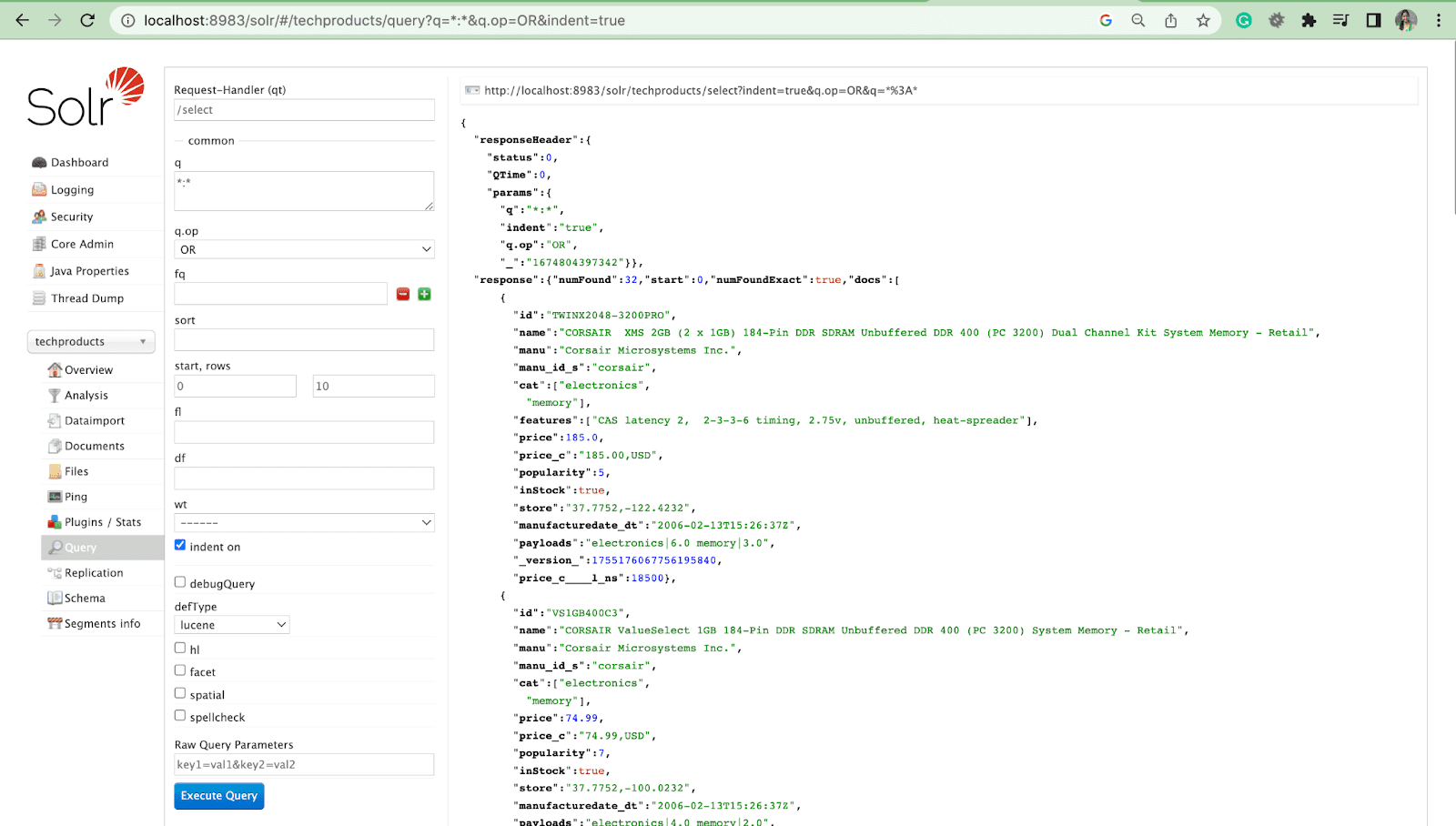
Solr에서 쿼리하기
이제 Solr 관리 UI에서 Solr 결과를 쿼리하는 방법을 살펴보겠습니다.
쿼리 매개변수
- 로컬 매개변수는 쿼리 매개변수에 특정한 Solr 요청의 인수입니다.
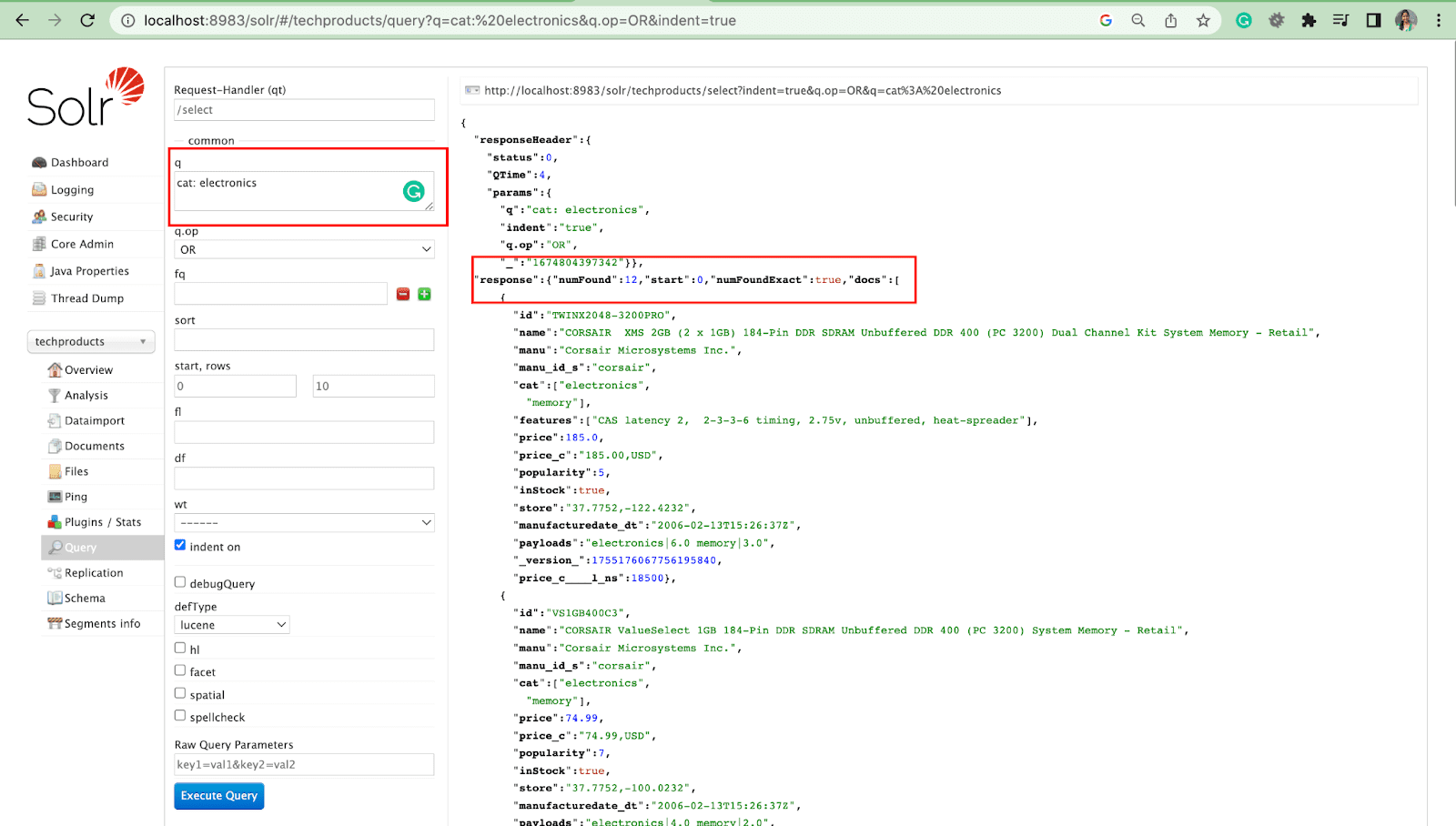
예: 고양이: 전자 제품
작업이 포함된 쿼리 매개변수
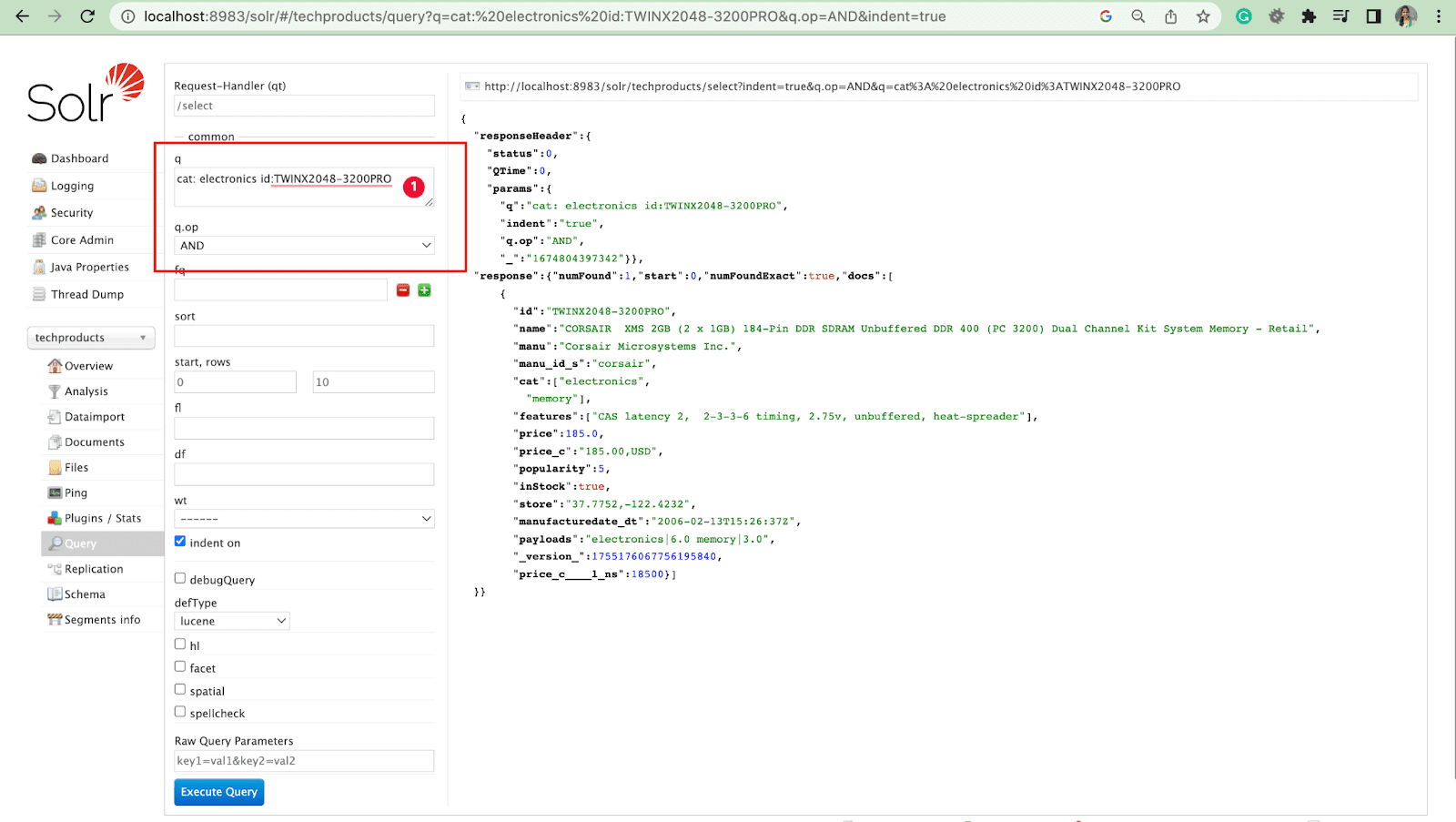
- 작업을 통해 여러 필드를 쿼리할 수 있습니다.
예: cat: electronics id:TWINX2048-3200PRO with q.op AND
[또는]
고양이: 전자 제품 및 id:TWINX2048-3200PRO
[또는]
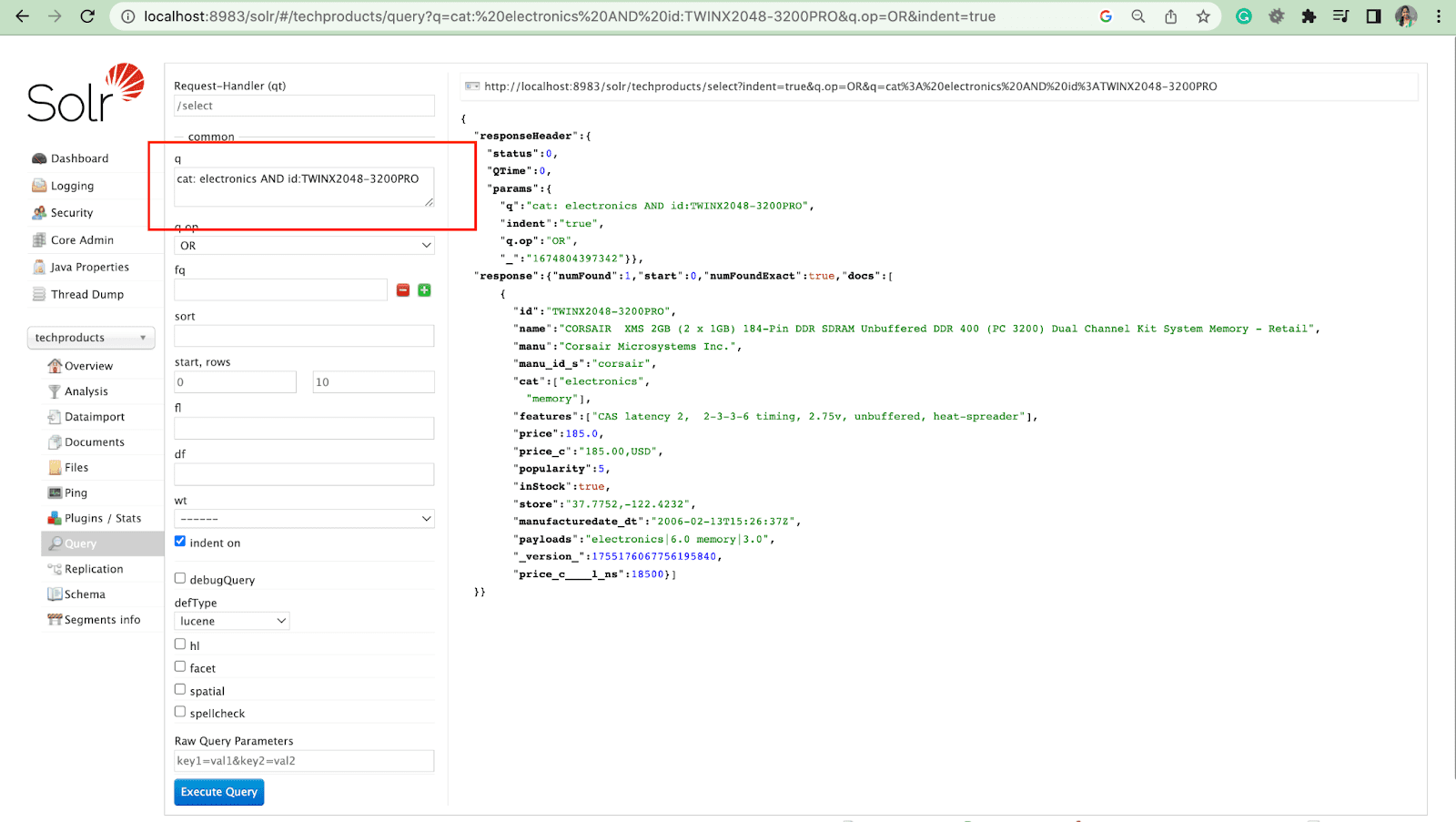
필터 쿼리
필터 쿼리는 검색 결과의 범위를 좁히는 데 도움이 됩니다. 점수에 영향을 주지 않고 상위 집합에 반환되는 문서를 제한하기 위해 fq 매개 변수로 쿼리를 지정할 수 있습니다.
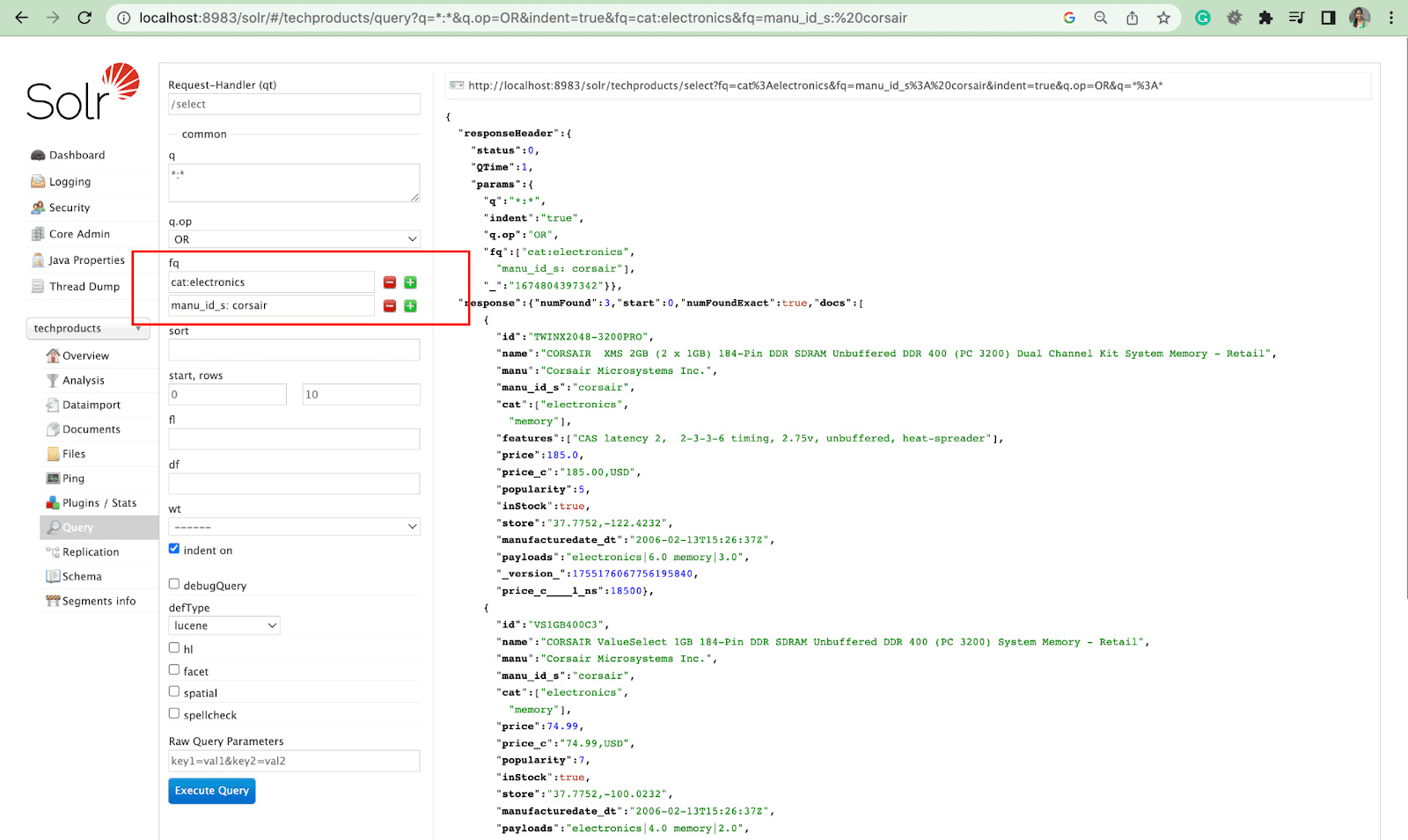
매개변수 정렬
정렬 매개변수는 오름차순(asc) 또는 내림차순(desc)으로 검색 결과를 정렬합니다. 내용에 따라 매개변수를 숫자 또는 알파벳순으로 사용할 수 있습니다.
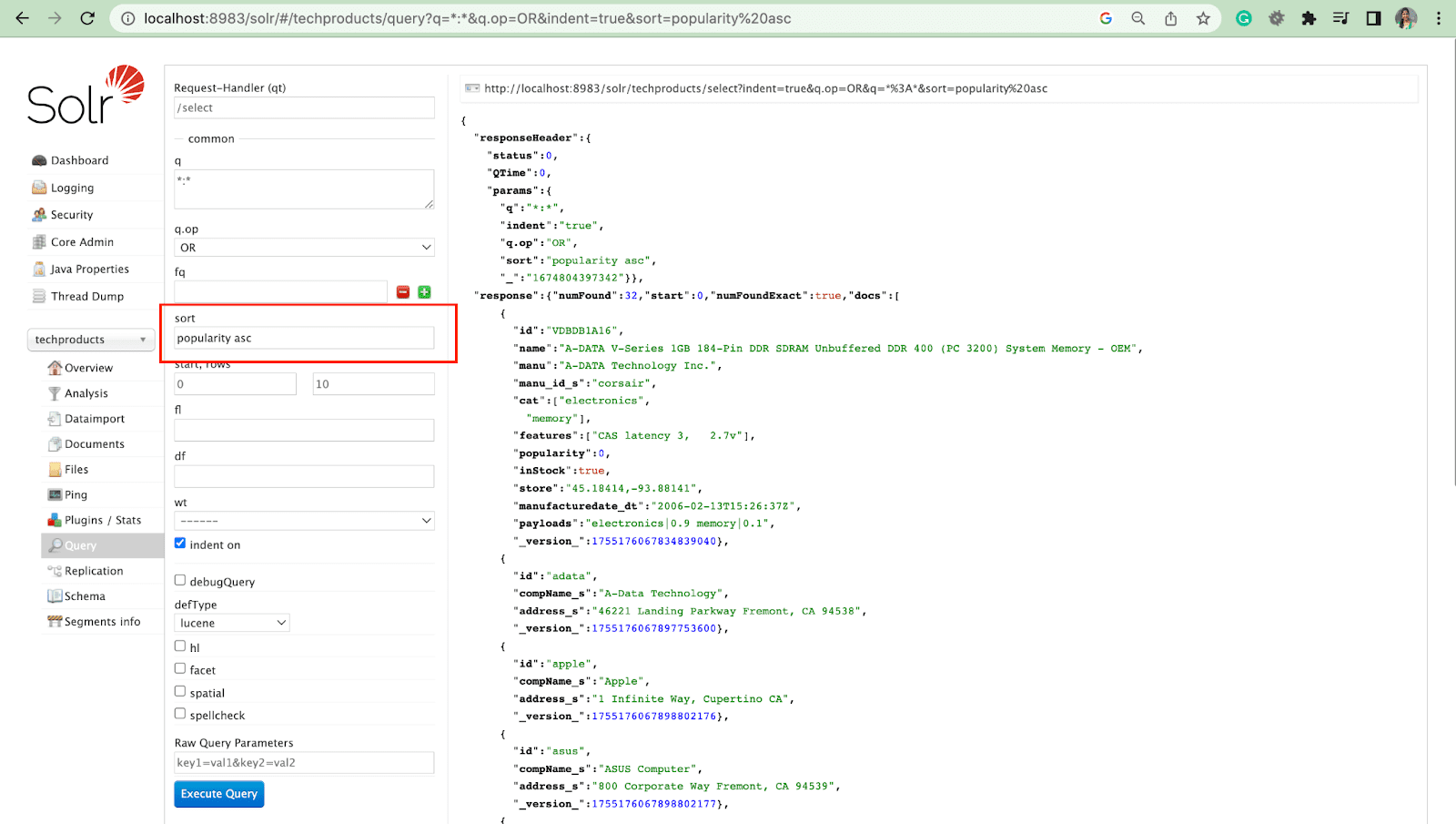
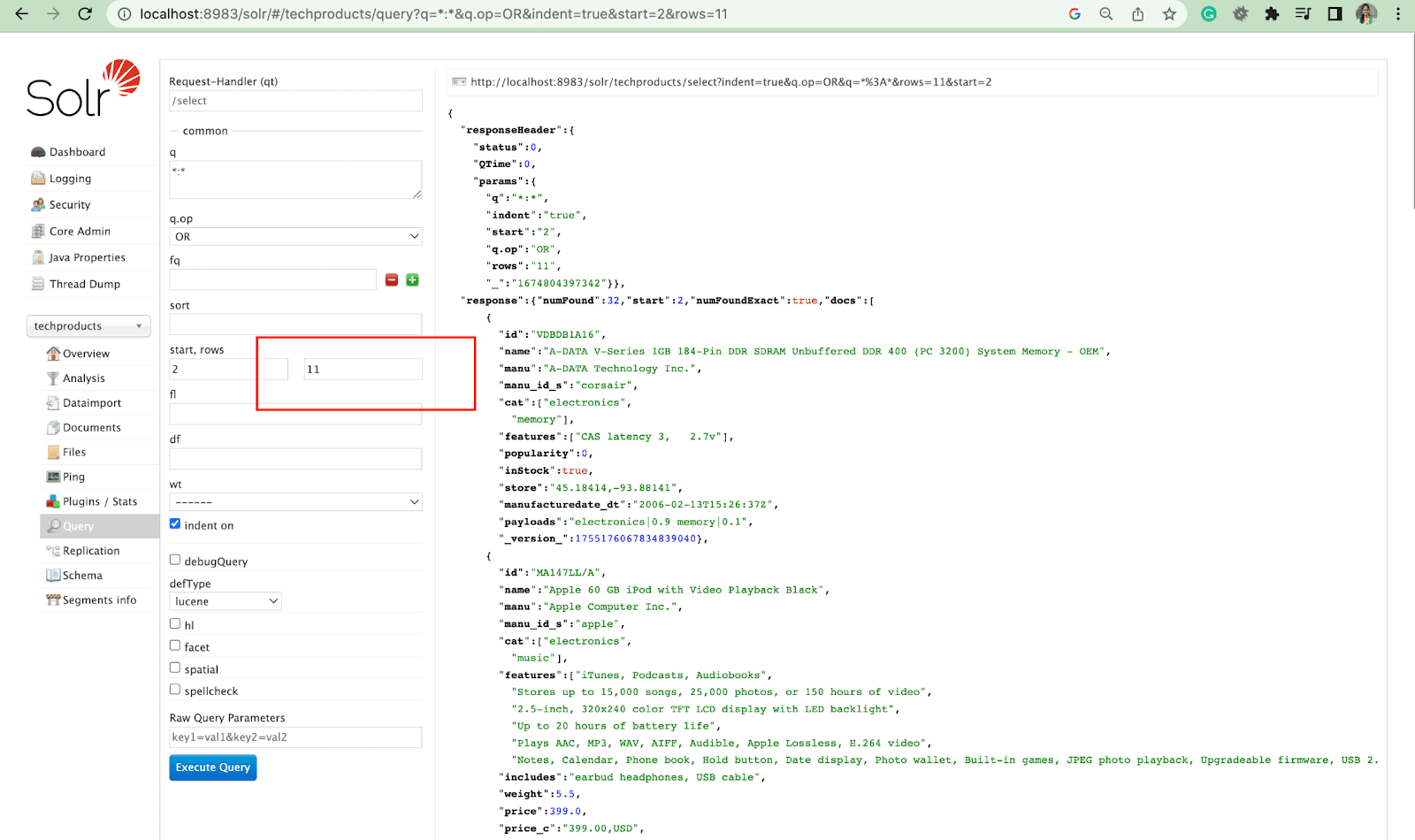
행 매개변수
행 매개변수를 사용하면 쿼리 결과를 페이지로 나눌 수 있습니다.
필드 목록 매개변수
fl 매개변수는 쿼리 응답에 포함된 정보를 지정된 필드 목록으로 제한합니다.
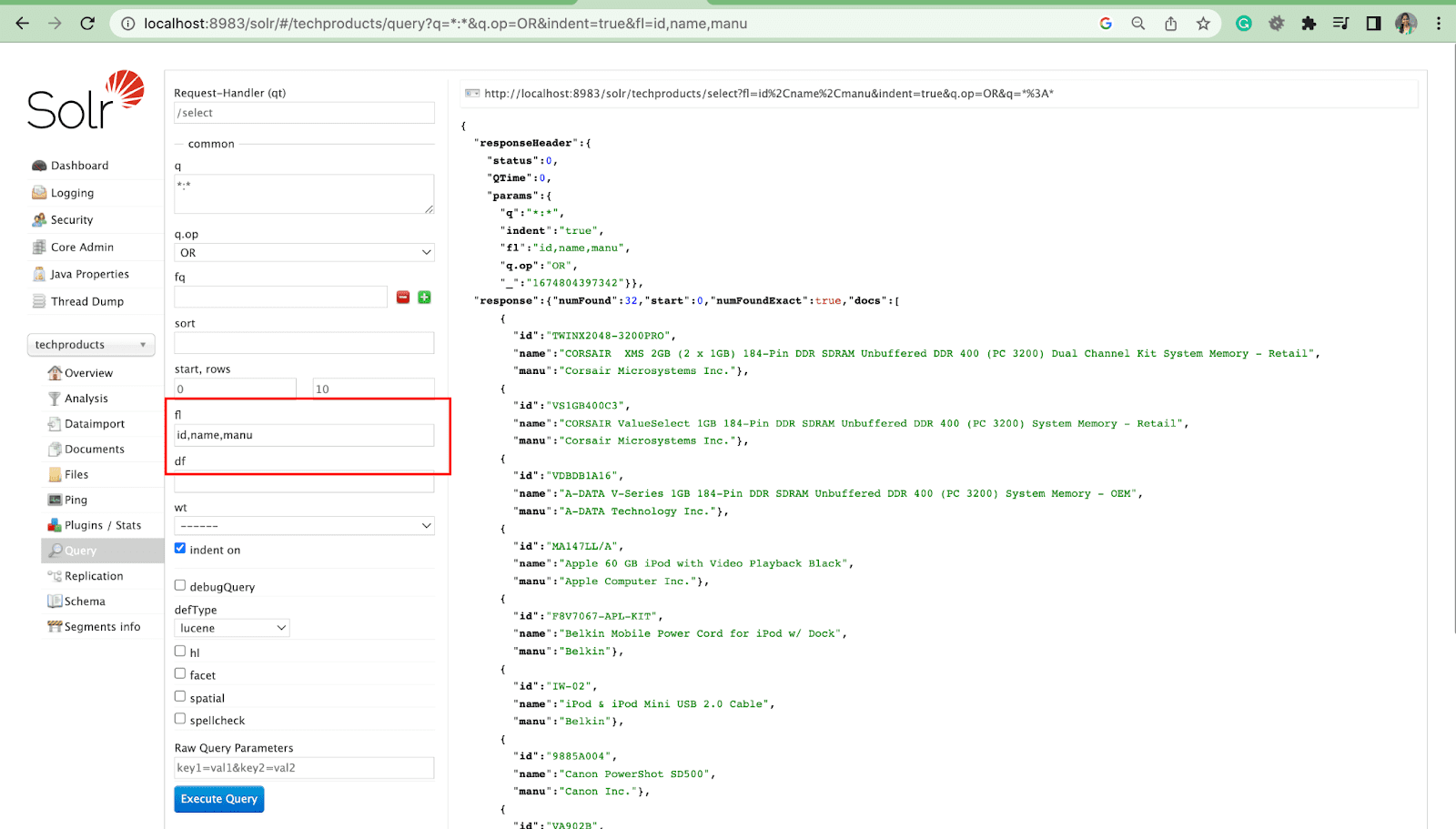
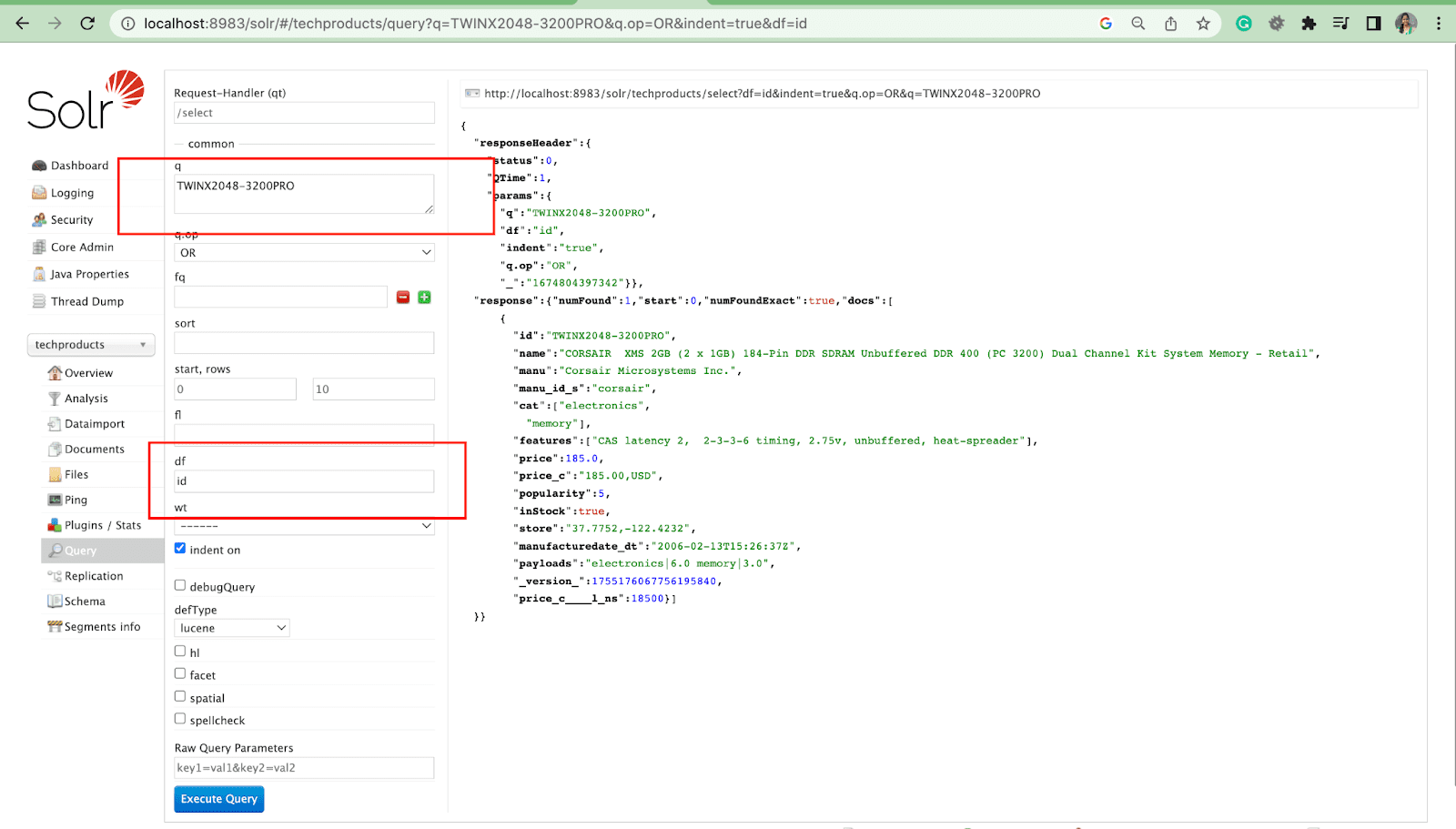
기본 필드 매개변수
기본 필드 매개변수는 쿼리 매개변수의 기본 필드입니다.
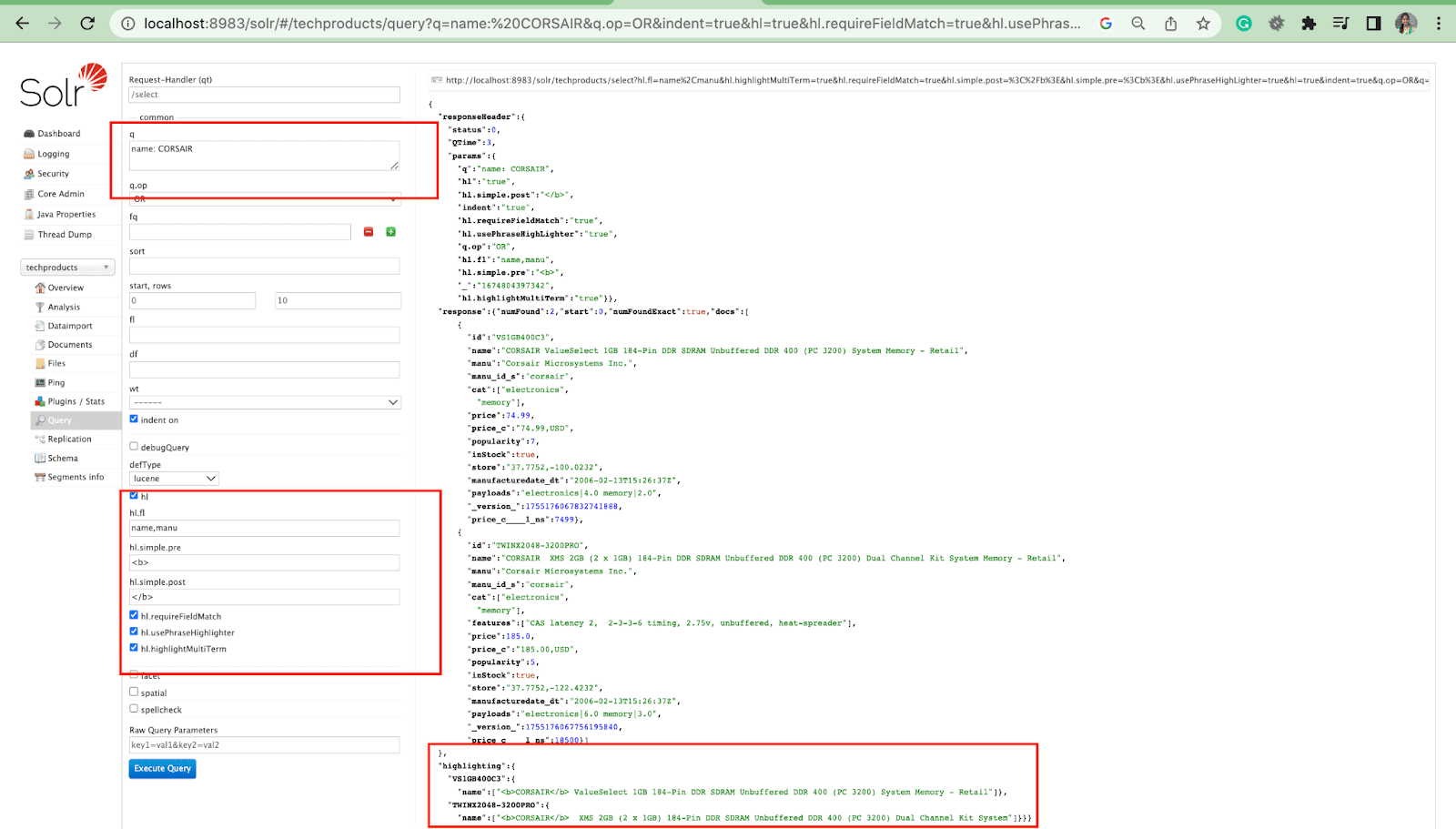
하이라이트 매개변수
Solr의 하이라이트 기능을 사용하면 쿼리와 일치하는 문서 조각을 포함할 수 있습니다.
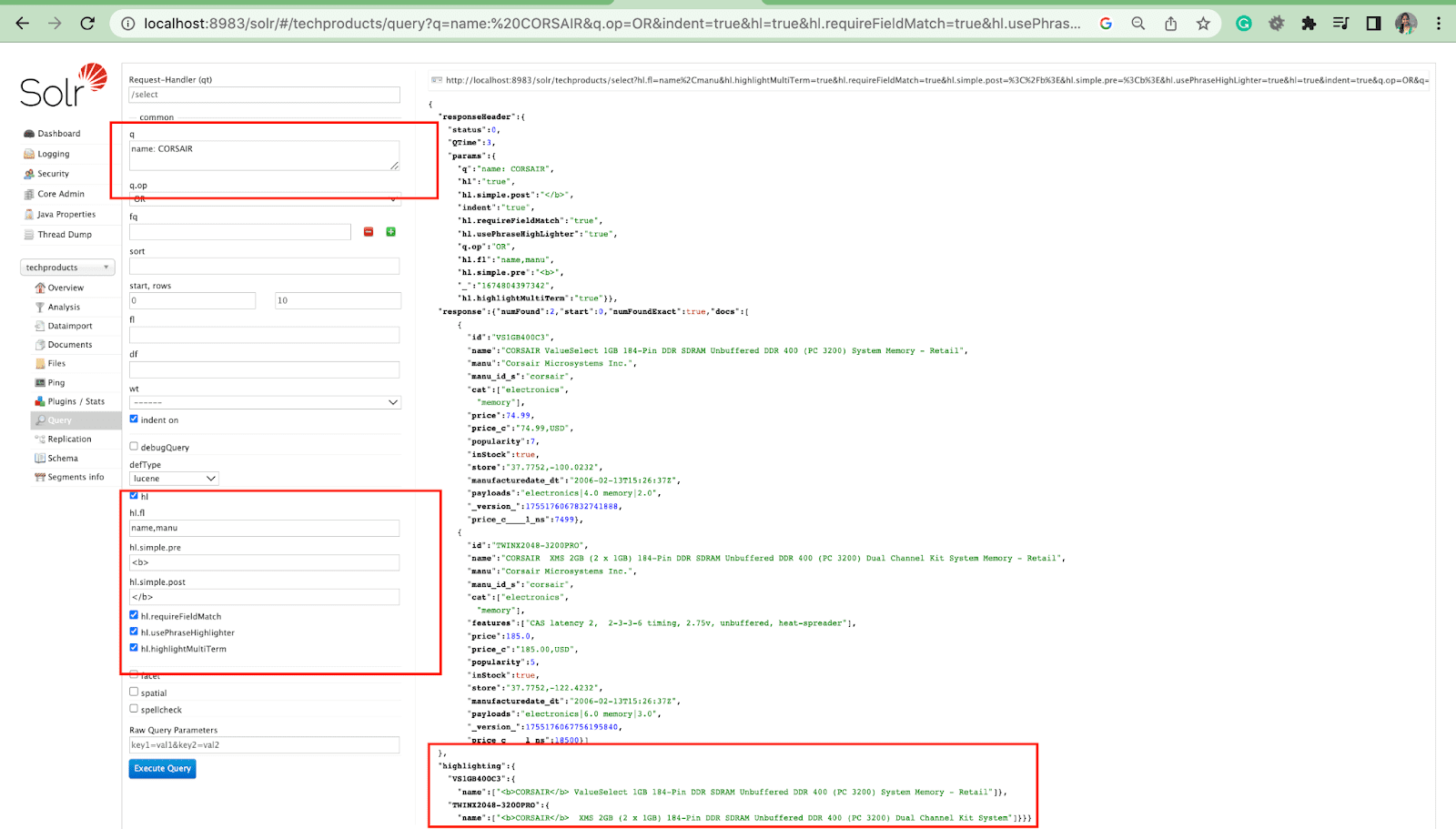
가장 일반적인 하이라이트 매개변수는 다음과 같습니다.
- Hl.fl - 필드 목록을 강조 표시합니다.
- Hl.simple.pre - 강조 표시된 단어 앞에 사용해야 하는 "태그"를 지정합니다.
- Hl.simple.post - 강조 표시된 용어 다음에 사용해야 하는 "태그"를 지정합니다.
- hl.highlightMultiTerm - true 로 설정되면 Solr는 와일드카드 쿼리를 강조 표시합니다. false 이면 전혀 강조 표시되지 않습니다.
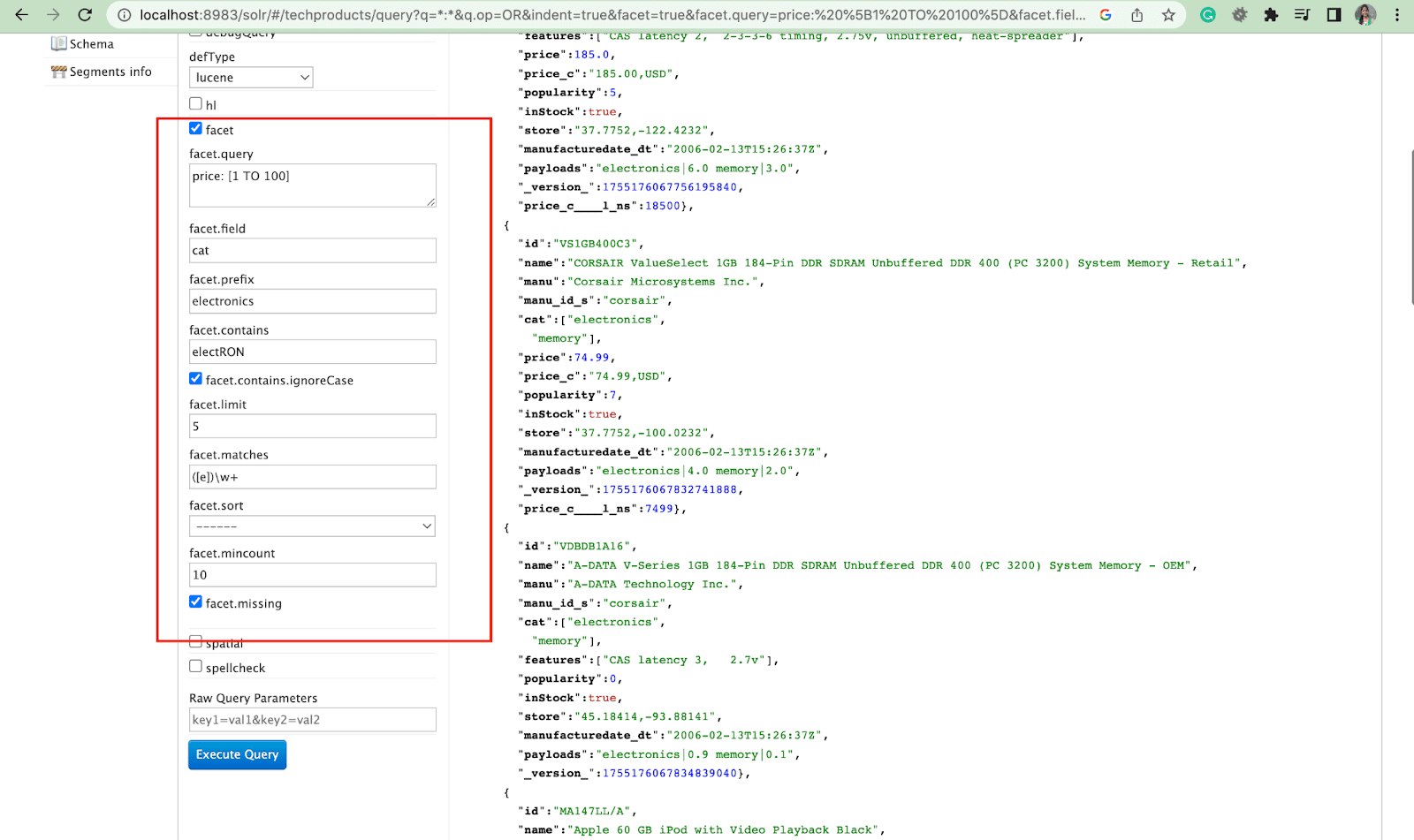
한 면:
패싯을 사용하면 사용자가 대규모 검색 결과 집합을 탐색하고 구체화할 수 있습니다. 체크박스, 드롭다운 또는 기타 컨트롤로 UI에 표시됩니다. 패싯을 제어하는 두 가지 일반 매개변수는 다음과 같습니다.
- 패싯 매개변수
패싯 매개변수를 사용하여 사용자는 검색 색인에 있는 하나 이상의 필드 값을 기반으로 패싯을 생성할 수 있습니다. 검색 결과에서 패싯 매개변수를 구성하여 패싯이 생성되고 표시되는 방식을 제어할 수 있습니다.
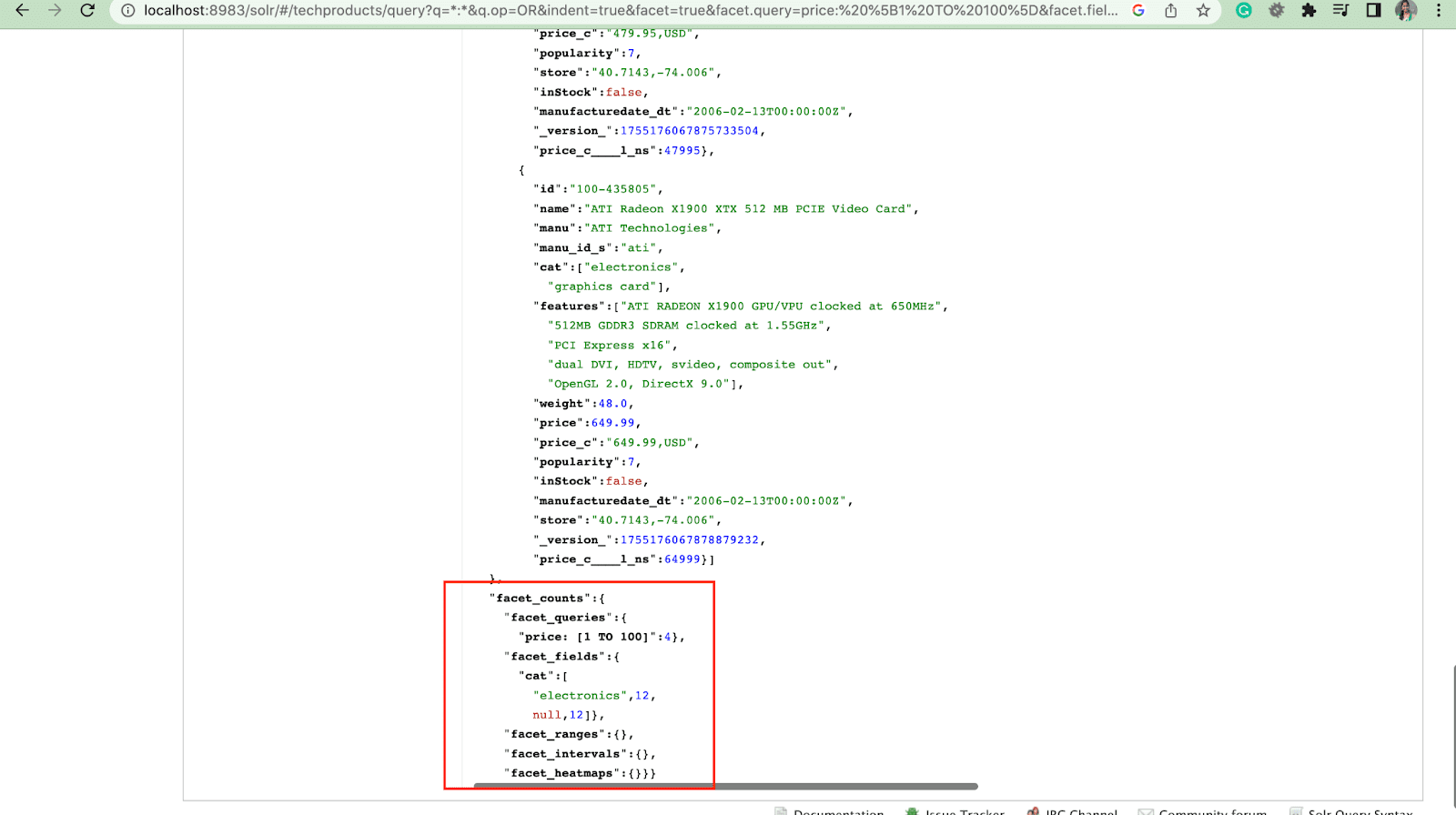
2. Facet.query 매개변수
사용자가 Solr 쿼리에 facet.query 매개변수를 포함하면 Solr는 각 쿼리와 일치하는 인덱스의 문서 수에 해당하는 패싯 수 목록을 생성합니다. Facet.query는 간단한 필드 값을 사용하여 쉽게 나타낼 수 없는 복잡한 검색 기준을 기반으로 패싯을 생성하려는 경우에 유용합니다.
facet.field (패싯을 생성하는 데 사용해야 하는 필드 지정) , facet.limit (각 필드에 표시할 최대 패싯 수) , facet.mincount (필요한 문서의 최소 수)와 같은 몇 가지 다른 패싯 매개변수가 있습니다. 응답에 포함될 패싯) , facet.sort (패싯 값이 표시되어야 하는 순서 지정) .
마지막 생각들
Apache Solr는 귀하의 요구 사항에 따라 사용자 정의할 수 있는 많은 흥미로운 기능과 함께 제공되는 고도로 다재다능한 검색 엔진입니다. Drupal은 Apache Solr와 매우 잘 작동합니다. 새 프로젝트를 위한 강력한 검색 엔진을 구성할 Drupal 전문가를 찾고 있다면 더 나아가고 싶습니다!