
データ品質の責任者は誰ですか? 分析チームの責任マトリックス
公開: 2022-06-11データの品質が低いと、それ以上のアクション(アトリビューションの計算、広告サービスへの入札の送信、レポートの作成など)が役に立たなくなる可能性があるため、データの品質を保証することは、デジタル分析における最大の課題であり続けます。 アナリストはすべてのデータ関連の問題に責任があると言うのが一般的です。 しかし、これは本当ですか?
会社のデータ品質の責任者は誰ですか? 一般に信じられていることとは反対に、それはアナリストだけではありません。 たとえば、マーケターはUTMタグを使用し、エンジニアは追跡コードを適用します。したがって、データを処理するときに混乱が発生するのは当然です。各従業員には多くのタスクがあり、誰が何をしているのか、誰が何を担当しているのか、結果を誰に尋ねるべきか。
この記事では、各段階でデータ品質の責任者とその管理方法を理解しようとしています。
目次
- データワークフロー
- 1.一次データの収集
- 2.データウェアハウスへのデータのインポート
- 3.SQLビューの準備
- 4.ビジネス対応データの準備
- 5.データマートの準備
- 6.データの視覚化
- 重要なポイント
- 便利なリンク
データワークフロー
1つの企業内でさえ、データの世界は矛盾や誤解で満たされる可能性があります。 ビジネスユーザーに質の高いデータを提供し、貴重なデータの欠落を防ぐには、必要なすべてのマーケティングデータの収集を計画する必要があります。 データワークフローを準備することで、すべての部門の同僚とデータがどのように関連しているかを示し、点を簡単に結び付けることができます。 ただし、これは最初のステップにすぎません。 レポートとダッシュボードのデータを準備する他の手順を見てみましょう。
- 一次データ収集を設定します。
- 生データをデータストレージまたはデータベースに収集します。
- 生データを、マークアップを使用して、クリーンアップされ、ビジネスに理解できる構造で、ビジネスに対応したデータに変換します。
- データマートを準備します—データを視覚化するためのデータソースとして機能するフラットな構造です。
- ダッシュボードのデータを視覚化します。
それでも、すべての準備に関係なく、意思決定者は、質の低いデータを含むレポートまたはダッシュボードに遭遇することがよくあります。 そして、彼らが最初に行うことは、アナリストに質問を投げかけることです。なぜ矛盾があるのでしょうか。 またはデータはここに関連していますか?
ただし、実際には、さまざまなスペシャリストがこれらのプロセスに関与しています。データエンジニアは分析システムのセットアップに従事し、マーケターはUTMタグを追加し、ユーザーはデータを入力します。 ユーザーに高品質のデータを提供するために、どの段階を経て、どのように実装する必要があるかを詳しく見ていきましょう。
我々の顧客
育つ 22%高速
マーケティングで最も効果的なものを測定することで、より速く成長します
マーケティング効率を分析し、成長分野を見つけ、ROIを向上させます
デモを入手1.一次データの収集
この手順は最も簡単に見えますが、いくつかの隠れた障害があります。 まず、すべての顧客のタッチポイントを考慮して、すべてのソースからすべてのデータを収集することを計画する必要があります。 この計画ステップがスキップされることもありますが、そうすることは不合理で危険です。 非構造化アプローチを採用すると、不完全または不正確なデータが取得されます。
主な課題は、使用しているさまざまな広告プラットフォームやサービスから断片化されたデータを収集する必要があることです。 大量のデータ配列を可能な限り短い時間で処理することは複雑でリソースを大量に消費するため、考えられるボトルネックを見てみましょう。
- すべてのページにGTMコンテナがインストールされているわけではないため、データはGoogleアナリティクスに送信されません。
- 広告プラットフォームに新しいアカウントが作成されますが、アナリストには通知されず、そこからデータが収集されません。
- APIはUTMタグの動的パラメーターをサポートしておらず、それらを収集または転送しません。
- GoogleCloudプロジェクトに接続されているカードの資金またはクレジットが不足しています。
- ユーザーが入力したデータの検証が正しくありません。
このステップでは、他のすべての課題の中でも、データへのアクセスを制御することを検討する必要があります。 このために、プロセスの役割を定義し、誰が何を実行、制御、管理、および責任を負うかを強調する従来のRACIマトリックスを使用することをお勧めします。 可能な役割は次のとおりです。
- R (Responsible)—特定のプロセスの責任者であり実行者である人
- C (相談済み)—プロセスを実装するために必要なデータを相談して提供する人
- A (説明責任者または承認者)—作業の結果に責任を持つ人
- I (情報提供)—作業の進捗状況を通知する必要がある人
RACIマトリックスによると、データ収集の役割と責任は次のようになります。

2.データウェアハウスへのデータのインポート
次のステップは、取得したすべてのデータをどこに保存するかを決定することです。 生データを変更せずに完全に制御したい場合は、自動データインポートを備えた単一のストレージを使用することをお勧めします。 データのすべてのバイトを保存するために独自のサーバーを使用すると大金がかかるため、リソースを節約し、あらゆる場所のデータへのアクセスを提供するクラウドソリューションを使用することをお勧めします。
このタスクに最適なオプションは、マーケターのニーズを考慮し、ウェブサイト、CRMシステム、広告プラットフォームなどからの生データを保存するために使用できるGoogle BigQueryです。今日、マーケティングソフトウェアソリューションはたくさんあります。 さまざまなサービスやWebサイトからデータウェアハウス(またはデータレイク)にデータを自動的に収集するOWOXBIをお勧めします。
生データを収集するときに発生する可能性のある従来のエラーを見てみましょう。
- 広告サービスのAPIが変更されました。 これに伴い、データ形式も変更されました。
- 外部サービスAPIは利用できません。 利害関係者は個人アカウントに特定の番号を表示しますが、同じ広告サービスのAPIは他のデータを提供します。 他の分散システムと同様に、広告サービスAPIのデータソースはWebポータルのデータソースとは異なるため、このデータは一致しません。
- 外部サービスのWebインターフェースとAPIのデータは異なります。 ドキュメントとデータ処理の形式は異なる場合があります。 たとえば、人気のある広告サービスの1つでの興味深い間違いは、費用が存在しない場合と実際にゼロの場合の両方で費用がゼロになることです。 すべてのデータエンジニアとアナリストは、ゼロとヌルが異なる値であり、処理が異なることを知っています。 ある場合には、これらの費用が表示され、再度要求する必要があります。ゼロは、実際には存在せず、ゼロとしてカウントされることを意味します。
- 外部サービスのAPIが誤ったデータを提供します。
マトリックスによると、このプロセスでは、マーケティング担当者はコンサルタントであり、知識のソースです。たとえば、データをダウンロードする必要のあるアカウント、UTMタグ、および広告キャンペーンのマークアップに関する知識です。

また、Google Tag Managerを使用した場合にコンテナにどのような変更が加えられるかを知りたい開発者もいます。これは、Webサイトのダウンロード速度に責任があるためです。
この時点で、データエンジニアはデータパイプラインを構成しているため、すでに責任ある役割を果たしています。 そして、アナリストは作業の結果に責任があります。 1人の従業員がこれらの機能を実行する場合でも、実際には2つの役割があります。 したがって、会社にアナリストが1人しかいない場合でも、役割ごとにマトリックスを実装することをお勧めします。 次に、会社の成長に伴い、新しい同僚の職務記述書が作成され、特定の役割の責任が明確になります。
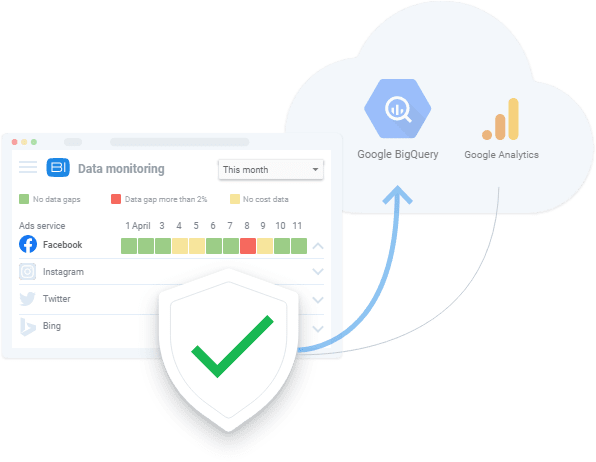
この段階の利害関係者は、データの収集を目的とした優先順位とリソースを特定するため、利用可能なデータとその品質にどのような問題があるかを知ることに関心があります。 たとえば、OWOX BIデータ監視機能は、クライアントによって広く適用されています。
3.SQLビューの準備
次のステップはデータの準備です。 これは、データマートの準備と呼ばれることがよくあります。これは、ダッシュボードに表示されるパラメーターとメトリックを含むフラットな構造です。 ツール、予算、時間に限りがあるアナリストは、ビジネスデータを準備する段階をスキップして、すぐにデータマートを準備することがよくあります。 データウェアハウスで収集された生データのように見えます。 次に、PythonおよびRスクリプトとともに数百万の異なるSQLクエリがあります。この混乱により、ダッシュボードに何かが表示されます。
すぐに使えるデータの準備をスキップし続けると、各ソースで修正する必要のあるエラーが繰り返されることになります。 うまくいかない可能性のある他の事柄は次のとおりです。
- 一次データの定期的なエラー
- すべてのSQLクエリで複製されているビジネスロジック
- データの不一致の原因を見つけるのに多くの時間が必要
- リクエストを書き換える時間に匹敵する既存のデータマートを改良する時間
- 顧客に理解できないレポートロジック

間違いの最も単純で最も一般的な例は、新しいユーザーと返されたユーザーの定義です。 ほとんどの企業は、GoogleAnalyticsと同じようにこの区別をしていません。 したがって、ユーザータイプ定義のロジックは、多くの場合、異なるレポートで重複しています。 頻繁なエラーには、理解できないレポートロジックも含まれます。 レポートを見るときにビジネス顧客が最初に尋ねるのは、レポートがどのように作成されたか、どのような仮定に基づいているか、データが使用された理由などです。 したがって、ビジネスデータの準備は絶対にスキップしてはならない段階です。 生データからデータマートを構築することは、野菜や果物を食べる前に洗わないようなものです。
マトリックスに従って責任を割り当てると、データの準備のために、次のようになります。

4.ビジネス対応データの準備
ビジネス対応データは、ビジネスモデルに対応するクリーンな最終データセットです。 これは、任意のデータ視覚化サービス(Power BI、Tableau、Google Data Studioなど)に送信できる既製のデータです。
当然、さまざまなビジネスがさまざまなモデルで運営されています。 たとえば、「ユーザー」、「B2Bユーザー」、「トランザクション」、「リード」などの定義は、企業ごとに異なる意味を持ちます。 これらのビジネスオブジェクトは、実際には、ビジネスがデータの観点からビジネスモデルについてどのように考えているかという質問に答えます。 これは、Google Analyticsのイベントの構造ではなく、中核となるビジネスの説明です。
データモデルを使用すると、すべての従業員が同期して、データの使用方法とデータについての一般的な理解を得ることができます。 したがって、生データをすぐに使えるデータに変換することは、スキップできない重要な段階です。
この段階で何がうまくいかない可能性があります:
- 会社が持っている/使用しているデータモデルが明確でない
- シミュレーションデータの準備と維持が難しい
- 変換ロジックの変更を制御するのが難しい
ここでは、選択するデータモデルと、データ変換のロジックの変更を制御する方法を決定する必要があります。 したがって、これらは変更プロセスの参加者の役割です。

利害関係者はもはや単に通知されるだけでなく、コンサルタントになります。 彼らは、新規またはリピーターとして何を理解すべきかなどの決定を下します。 この段階でのアナリストのタスクは、これらの決定を行う際に可能な限り利害関係者を関与させることです。 それ以外の場合、発生する可能性のある最善のことは、アナリストがレポートをやり直すように求められることです。
私たちの経験では、一部の企業はまだビジネス対応データを準備しておらず、生データに関するレポートを作成していません。 このアプローチの主な問題は、SQLクエリの無限のデバッグと書き換えです。 長期的には、同じことを何度も繰り返す生データを実行するよりも、準備されたデータを操作する方が安価で簡単です。
OWOX BIは、さまざまなソースから生データを自動的に収集し、レポートに適した形式に変換します。 その結果、マーケターにとって重要なニュアンスを考慮して、目的の構造に自動的に変換される既製のデータセットを受け取ります。 複雑な変換の開発とサポートに時間を費やしたり、データ構造を詳しく調べたり、不一致の原因を探すために何時間も費やしたりする必要はありません。

無料のデモを予約して、OWOX BIがビジネスデータの準備をどのように支援するか、そして今日の完全に自動化されたデータ管理からどのように利益を得ることができるかを確認してください。
5.データマートの準備
次の段階は、データマートの準備です。 簡単に言えば、これは特定の部門の特定のユーザーが必要とする正確なデータを含む準備されたテーブルであり、適用がはるかに簡単になります。
アナリストがデータマートを必要とするのはなぜですか。また、この段階をスキップしないのはなぜですか。 分析スキルのないマーケターやその他の従業員は、生データを扱うのが難しいと感じています。 アナリストの仕事は、すべての従業員に最も便利な形式のデータへのアクセスを提供することです。これにより、毎回複雑なSQLクエリを作成する必要がなくなります。
データマートは、この問題の解決に役立ちます。 確かに、有能な充填により、特定の部門の作業に必要なデータスライスが正確に含まれます。 また、同僚はそのようなデータベースの使用方法を正確に理解し、データベースに表示されるパラメーターとメトリックのコンテキストを理解します。
データマートの準備時に問題が発生する可能性がある主なケースは次のとおりです。
- データマージロジックは理解できません。 たとえば、モバイルアプリケーションとウェブサイトからのデータがあり、それをどのようにマージするか、どのキーを使用するかを決定するか、広告キャンペーンをモバイルアプリのアクティビティとマージする方法を決定する必要があります。 たくさんの質問があります。 ビジネスデータを作成するときにこれらの決定を行うことにより、一度決定するだけで、その価値は、現在ここにある特定のレポートに対してその場で行われる決定よりも大きくなります。 このような臨時の決定は繰り返し行う必要があります。
- データウェアハウスの技術的制限により、SQLクエリは実行されません。 ビジネスデータの準備は、データをクリーンアップしてシミュレートされた構造にする1つの方法であり、クエリの処理と高速化をより安価に行うことができます。
- データ品質を確認する方法が明確ではありません。
マトリックスに従って、この段階で誰が何に責任があるかを見てみましょう。

データの準備は、プロセスのコンサルタントである利害関係者やデータエンジニアとともに、データアナリストの責任であることは明らかです。 OWOXBIアナリストがこのタスクを処理できることに注意してください。 データを収集してマージし、ビジネスモデルに合わせてモデル化し、ビルドロジックの説明を含む詳細な手順を伴うデータマートを準備して、必要に応じて変更(たとえば、新しいフィールドの追加)を行うことができます。
6.データの視覚化
レポートとダッシュボードにデータを視覚的に表示することは、すべてが実際に開始された最終段階です。 明らかに、データは有益でユーザーフレンドリーな方法で提示する必要があります。 自動化され適切に構成された視覚化により、リスクゾーン、問題、および成長の可能性を見つける時間が大幅に短縮されることは言うまでもありません。
すぐに使えるデータとデータマートを用意しておけば、視覚化に問題はありません。 ただし、次のような間違いも発生する可能性があります。
- データマート内の無関係なデータ。 企業がデータ品質について確信が持てない場合、たとえデータが高品質であっても、最初のステップは、ビジネス顧客がアナリストにすべてを再確認するように依頼することです。 これは非効率的です。 ビジネスが間違いから保護され、結論を急がないことを望んでいることは明らかです。 したがって、高品質のデータは、誰かが後でそれを使用することを保証します。
- 誤ったデータ視覚化方法を選択する。
- メトリックおよびパラメーター計算のロジックを顧客に適切に説明していません。 多くの場合、SQLとメトリックに精通していないビジネス顧客がデータを正しく解釈するには、レポートのコンテキストで各メトリックが何を意味するのか、どのように計算されるのか、そしてその理由を確認する必要があります。 アナリストは、レポートを使用する人は誰でも、レポートの背後にあるもの、レポートの中心にある仮定などの説明にアクセスできる必要があることを忘れてはなりません。
RACIマトリックスによると、アナリストにはすでに承認者と責任という2つの役割があります。 利害関係者はここではコンサルタントであり、ほとんどの場合、彼らはどのような決定を下す予定であり、どのような仮説をテストしたいのかという質問に事前に回答しています。 これらの仮説は、アナリストが作業する視覚化の設計の基礎を形成します。

重要なポイント
RACIマトリックスは、データの操作に関して考えられるすべての質問に対する答えではありませんが、会社でのデータフローの実装と適用を確実に容易にすることができます。
さまざまな役割の人々がデータフローのさまざまな段階に関与しているため、アナリストがデータ品質に単独で責任を負っていると考えるのは誤りです。 データ品質は、データのマークアップ、配信、準備、または管理の決定に関与するすべての同僚の責任でもあります。
すべてのデータは常に低品質であり、データの不一致を恒久的に取り除き、データの一貫性を保ち、ノイズや重複を取り除くことは不可能です。 これは常に発生します。特に、マーケティングのように高速で動的に変化するデータの現実ではそうです。 ただし、これらの問題を事前に特定し、データ品質を知らせるための目標を設定することができます。 たとえば、次のような質問に対する回答を得ることができます。データはいつ更新されましたか。 データはどの程度の粒度で利用できますか? データのどのようなエラーについて知っていますか? とどのようなメトリックを使用できますか?
会社のデータ品質の向上に貢献したい場合は、次の3つの簡単な手順をお勧めします。
- データフロースキーマを作成します。 たとえば、Miroを使用して、会社がデータをどのように使用するかをスケッチします。 1つの会社内でこのスキーマについて多くの異なる意見があることに驚かれることでしょう。
- 責任マトリックスをまとめ、少なくとも紙面では、誰が何に対して責任を負うかについて合意します。
- ビジネスデータモデルを説明します。
長年の専門知識を持つOWOXBIチームは、責任をどのように割り当てるか、およびアナリストが何を必要としているかを知っています。 この知識に基づいて、アナリストチーム向けの責任割り当てマトリックステンプレートを用意しました。
行列を取得する
さらに、OWOX BIチームは、この記事で説明されているすべてのデータステップの構成と自動化を支援します。 これらのタスクのいずれかについてサポートが必要な場合、または分析とデータ品質システムを監査したい場合は、デモを予約してください。
便利なリンク
- ダークデータ:なぜあなたが知らないことが重要なのかDavid J. Hand
- シグナル・アンド・ノイズ:なぜこれほど多くの予測が失敗するのか-しかし、ネイト・シルバーが失敗しないものもある
- ダン・アリエリー博士による予想どおりに不合理
- 不合理な類人猿:なぜ私たちは情報の乱れ、陰謀論、そして宣伝に陥るのかDavid Robert Grimes
- AntrikshGoelによる「データエコシステム」の体験