
機械学習における回帰と分類の説明
公開: 2022-12-19回帰と分類は、機械学習の最も基本的で重要な分野の 2 つです。
機械学習を始めたばかりの場合、回帰アルゴリズムと分類アルゴリズムを区別するのは難しい場合があります。 これらのアルゴリズムがどのように機能し、いつ使用するかを理解することは、正確な予測と効果的な意思決定を行うために重要です。
まず、機械学習について見てみましょう。
機械学習とは

機械学習は、明示的にプログラムすることなく、コンピュータに学習と意思決定を教える方法です。 これには、データセットでのコンピューター モデルのトレーニングが含まれ、モデルがデータ内のパターンと関係に基づいて予測または決定を下せるようになります。
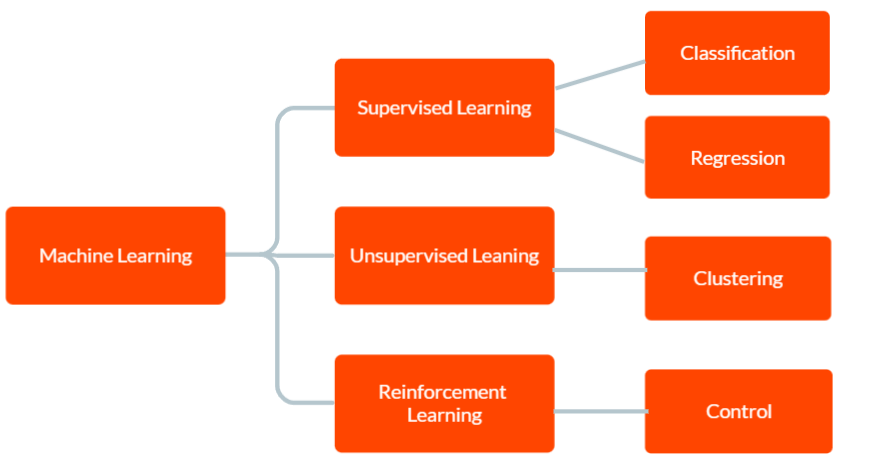
機械学習には主に、教師あり学習、教師なし学習、強化学習の 3 種類があります。
教師あり学習では、入力データと対応する正しい出力を含むラベル付きトレーニング データがモデルに提供されます。 目標は、モデルがトレーニング データから学習したパターンに基づいて、新しい目に見えないデータの出力について予測を行うことです。
教師なし学習では、モデルにラベル付きトレーニング データは与えられません。 代わりに、データのパターンと関係を個別に発見する必要があります。 これは、データ内のグループまたはクラスターを識別したり、異常や異常なパターンを見つけたりするために使用できます。
また、強化学習では、エージェントは環境と対話して報酬を最大化することを学習します。 これには、環境から受け取るフィードバックに基づいて決定を下すようにモデルをトレーニングすることが含まれます。
機械学習は、画像および音声認識、自然言語処理、不正検出、自動運転車など、さまざまなアプリケーションで使用されています。 多くのタスクを自動化し、さまざまな業界での意思決定を改善する可能性があります。
この記事では主に、教師あり機械学習に含まれる分類と回帰の概念に焦点を当てています。 始めましょう!
機械学習における分類

分類は、特定の入力にクラス ラベルを割り当てるようにモデルをトレーニングする機械学習手法です。 これは教師あり学習タスクです。つまり、入力データの例と対応するクラス ラベルを含むラベル付きデータセットでモデルがトレーニングされることを意味します。
このモデルの目的は、入力データとクラス ラベルの関係を学習して、新しい目に見えない入力のクラス ラベルを予測することです。
ロジスティック回帰、デシジョン ツリー、サポート ベクター マシンなど、分類に使用できるさまざまなアルゴリズムがあります。 アルゴリズムの選択は、データの特性とモデルの望ましいパフォーマンスによって異なります。
一般的な分類アプリケーションには、スパム検出、センチメント分析、不正検出などがあります。 いずれの場合も、入力データにはテキスト、数値、または両方の組み合わせが含まれる場合があります。 クラス ラベルは、バイナリ (例: スパムかそうでないか) またはマルチクラス (例: 肯定的、中立的、否定的な感情) にすることができます。
たとえば、製品のカスタマー レビューのデータセットを考えてみましょう。 入力データはレビューのテキストである場合があり、クラス ラベルは評価 (肯定的、中立的、否定的など) である場合があります。 このモデルは、ラベル付けされたレビューのデータセットでトレーニングされ、これまでに見たことのない新しいレビューの評価を予測できるようになります。
ML 分類アルゴリズムの種類
機械学習には、いくつかのタイプの分類アルゴリズムがあります。
ロジスティック回帰
これは、バイナリ分類に使用される線形モデルです。 特定のイベントが発生する確率を予測するために使用されます。 ロジスティック回帰の目標は、予測された確率と観察された結果の間の誤差を最小限に抑える最適な係数 (重み) を見つけることです。
これは、勾配降下などの最適化アルゴリズムを使用して、モデルがトレーニング データにできるだけ適合するまで係数を調整することによって行われます。
決定木
これらは、特徴値に基づいて決定を行うツリー状のモデルです。 これらは、バイナリ分類とマルチクラス分類の両方に使用できます。 決定木には、単純さと相互運用性など、いくつかの利点があります。
また、トレーニングと予測が高速で、数値データとカテゴリ データの両方を処理できます。 ただし、特にツリーが深く、多くの枝がある場合は、過適合になりがちです。
ランダム フォレスト分類
ランダム フォレスト分類は、複数の決定木の予測を組み合わせて、より正確で安定した予測を行うアンサンブル手法です。 個々のツリーの予測が平均化され、モデルの分散が減少するため、単一の決定ツリーよりも過剰適合する傾向が低くなります。
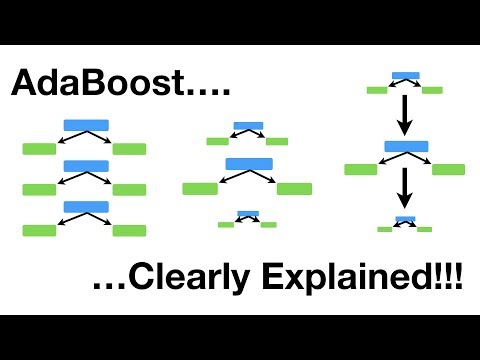
アダブースト
これは、トレーニング セット内の誤分類された例の重みを適応的に変更するブースティング アルゴリズムです。 バイナリ分類によく使用されます。
単純ベイズ
Naive Bayes は、新しい証拠に基づいてイベントの確率を更新する方法である Bayes の定理に基づいています。 これは、テキスト分類やスパム フィルタリングによく使用される確率的分類器です。
K 最近傍
K 最近傍 (KNN) は、分類および回帰タスクに使用されます。 これは、最近傍のクラスに基づいてデータ ポイントを分類するノンパラメトリック手法です。 KNN には、その単純さと実装が容易であるという事実など、いくつかの利点があります。 数値データとカテゴリ データの両方を処理することもでき、基になるデータ分布については何も仮定しません。
勾配ブースティング
これらは、各モデルが前のモデルの間違いを修正しようとして、順次トレーニングされる弱学習器の集合です。 これらは、分類と回帰の両方に使用できます。
機械学習における回帰
機械学習では、回帰は教師あり学習の一種であり、目標は 1 つ以上の入力特徴 (予測変数または独立変数とも呼ばれます) に基づいて ac 従属変数を予測することです。

回帰アルゴリズムは、入力と出力の間の関係をモデル化し、その関係に基づいて予測を行うために使用されます。 回帰は、連続従属変数とカテゴリ従属変数の両方に使用できます。
一般に、回帰の目標は、入力フィーチャに基づいて出力を正確に予測できるモデルを構築し、入力フィーチャと出力の間の基本的な関係を理解することです。
回帰分析は、さまざまな変数間の関係を理解し、予測するために、経済学、金融、マーケティング、心理学などのさまざまな分野で使用されています。 これは、データ分析と機械学習の基本的なツールであり、予測を行い、傾向を特定し、データを駆動する根本的なメカニズムを理解するために使用されます。
たとえば、単純な線形回帰モデルでは、家のサイズ、場所、およびその他の機能に基づいて家の価格を予測することが目標になる場合があります。 家の大きさとその場所が独立変数になり、家の価格が従属変数になります。
モデルは、いくつかの家のサイズと場所、および対応する価格を含む入力データでトレーニングされます。 モデルがトレーニングされると、そのサイズと場所に基づいて家屋の価格を予測するために使用できます。
ML 回帰アルゴリズムの種類
回帰アルゴリズムはさまざまな形で利用でき、各アルゴリズムの使用法は、属性値の種類、近似曲線のパターン、独立変数の数などのパラメーターの数によって異なります。 よく使用される回帰手法には、次のものがあります。
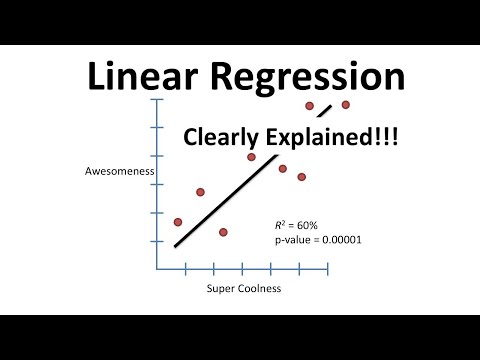
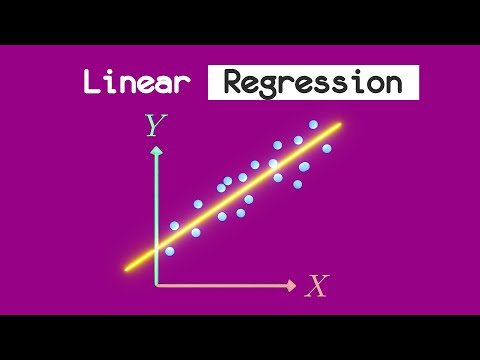
線形回帰
この単純な線形モデルは、一連の特徴に基づいて連続値を予測するために使用されます。 線をデータに適合させることにより、特徴とターゲット変数の間の関係をモデル化するために使用されます。
多項式回帰
これは、曲線をデータに適合させるために使用される非線形モデルです。 関係が線形でない場合に、特徴とターゲット変数の間の関係をモデル化するために使用されます。 これは、線形モデルに高次の項を追加して、従属変数と独立変数の間の非線形関係を捉えるという考えに基づいています。
リッジ回帰
これは、線形回帰における過剰適合に対処する線形モデルです。 これは、コスト関数にペナルティ項を追加してモデルの複雑さを軽減する、線形回帰の正則化バージョンです。
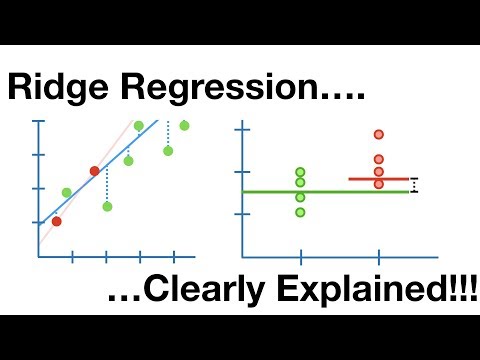
サポート ベクター回帰
SVM と同様に、サポート ベクター回帰は、従属変数と独立変数の間のマージンを最大化する超平面を見つけることによってデータを適合させようとする線形モデルです。
ただし、分類に使用される SVM とは異なり、SVR は、クラス ラベルではなく連続値を予測することが目標である回帰タスクに使用されます。
ラッソ回帰
これは、線形回帰でオーバーフィッティングを防ぐために使用されるもう 1 つの正則化された線形モデルです。 係数の絶対値に基づいてコスト関数にペナルティ項を追加します。
ベイジアン線形回帰
ベイジアン線形回帰は、ベイズの定理に基づく線形回帰への確率論的アプローチであり、新しい証拠に基づいてイベントの確率を更新する方法です。
この回帰モデルは、与えられたデータのモデル パラメーターの事後分布を推定することを目的としています。 これは、パラメーターの事前分布を定義し、ベイズの定理を使用して、観測されたデータに基づいて分布を更新することによって行われます。
回帰と分類
回帰と分類は 2 種類の教師あり学習です。つまり、一連の入力機能に基づいて出力を予測するために使用されます。 ただし、この 2 つにはいくつかの重要な違いがあります。
| 回帰 | 分類 | |
| 意味 | 連続値を予測する教師あり学習の一種 | カテゴリ値を予測する教師あり学習の一種 |
| 出力タイプ | 連続 | 離散 |
| 評価指標 | 平均二乗誤差 (MSE)、二乗平均平方根誤差 (RMSE) | 精度、適合率、再現率、F1 スコア |
| アルゴリズム | 線形回帰、投げ縄、リッジ、KNN、決定木 | ロジスティック回帰、SVM、単純ベイズ、KNN、デシジョン ツリー |
| モデルの複雑さ | 複雑でないモデル | より複雑なモデル |
| 仮定 | 特徴とターゲットの間の線形関係 | 機能とターゲットの間の関係に関する特定の仮定はありません |
| クラスの不均衡 | 適用できない | 問題になる可能性があります |
| 外れ値 | モデルのパフォーマンスに影響を与える可能性があります | 通常は問題ありません |
| 機能の重要性 | 機能は重要度によってランク付けされます | 機能は重要度でランク付けされていません |
| 応用例 | 価格、気温、数量の予測 | 迷惑メールかどうかの予測、顧客離れの予測 |
学習リソース
機械学習の概念を理解するための最適なオンライン リソースを選択するのは難しい場合があります。 信頼できるプラットフォームが提供する人気のあるコースを調べて、回帰と分類に関するトップ ML コースの推奨事項を提示しました。
#1。 Python での機械学習分類ブートキャンプ
これは、Udemy プラットフォームで提供されるコースです。 デシジョン ツリーやロジスティック回帰など、さまざまな分類アルゴリズムと手法をカバーし、ベクター マシンをサポートします。

オーバーフィッティング、バイアスと分散のトレードオフ、モデル評価などのトピックについても学習できます。 このコースでは、sci-kit-learn や pandas などの Python ライブラリを使用して、機械学習モデルを実装および評価します。 そのため、このコースを開始するには基本的な Python の知識が必要です。
#2。 Python での機械学習回帰マスタークラス
この Udemy コースでは、線形回帰、多項式回帰、Lasso & Ridge 回帰手法など、さまざまな回帰アルゴリズムの基本と基礎となる理論について説明します。
このコースの終わりまでに、回帰アルゴリズムを実装し、さまざまな重要業績評価指標を使用してトレーニング済みの機械学習モデルのパフォーマンスを評価できるようになります。
まとめ
機械学習アルゴリズムは、多くのアプリケーションで非常に役立ち、多くのプロセスを自動化および合理化するのに役立ちます。 ML アルゴリズムは、統計手法を使用してデータのパターンを学習し、それらのパターンに基づいて予測または決定を行います。
それらは大量のデータでトレーニングすることができ、人間が手動で行うのが困難または時間のかかるタスクを実行するために使用できます。
各 ML アルゴリズムには長所と短所があり、アルゴリズムの選択はデータの性質とタスクの要件によって異なります。 解決しようとしている特定の問題に対して、適切なアルゴリズムまたはアルゴリズムの組み合わせを選択することが重要です。
間違ったタイプのアルゴリズムを使用すると、パフォーマンスが低下し、予測が不正確になる可能性があるため、問題に適したタイプのアルゴリズムを選択することが重要です。 どのアルゴリズムを使用すればよいかわからない場合は、回帰アルゴリズムと分類アルゴリズムの両方を試して、データセットでのパフォーマンスを比較すると役立つ場合があります。
この記事が、機械学習における回帰と分類の学習に役立つことを願っています。 トップの機械学習モデルについて学ぶことにも興味があるかもしれません。