
Pandas DataFrame の作成方法 [例付き]
公開: 2022-12-08pandas DataFrames の操作の基本を学びます。これは、強力なデータ操作ライブラリである pandas の基本的なデータ構造です。
Python でデータ分析を開始したい場合、pandas は最初に学習する必要があるライブラリの 1 つです。 CSV ファイルやデータベースなどの複数のソースからデータをインポートすることから、不足しているデータを処理して洞察を得るための分析まで、上記のすべてを行うことができます。
pandas でデータの分析を開始するには、pandas の基本的なデータ構造であるデータ フレームを理解する必要があります。
このチュートリアルでは、pandas データフレームの基本と、データフレームを作成するための一般的な方法について学習します。 次に、データのサブセットを取得するためにデータフレームから行と列を選択する方法を学習します。
これらすべてについて、始めましょう。
パンダのインストールとインポート
pandas はサードパーティのデータ分析ライブラリであるため、最初にインストールする必要があります。 プロジェクトの仮想環境に外部パッケージをインストールすることをお勧めします。
Python の Anaconda ディストリビューションを使用している場合は、パッケージ管理にcondaを使用できます。
conda install pandaspip を使用して pandas をインストールすることもできます。
pip install pandaspandas ライブラリには依存関係として NumPy が必要です。 したがって、NumPy がまだインストールされていない場合は、インストール プロセス中にインストールされます。
pandas をインストールしたら、作業環境にインポートできます。 一般に、pandas はエイリアスpdでインポートされます。
import pandas as pdPandas のデータフレームとは?

pandas の基本的なデータ構造はデータ フレームです。 データ フレームは、ラベル付きのインデックスと名前付きの列を持つデータの 2 次元配列です。 pandas seriesと呼ばれるデータ フレームの各列は、共通のインデックスを共有します。
次の数分間でゼロから作成するデータ フレームの例を次に示します。 このデータ フレームには、6 人の学生が 4 週間で費やした金額に関するデータが含まれています。

学生の名前は行ラベルです。 また、列には「Week1」から「Week4」という名前が付けられています。 すべての列が、 indexとも呼ばれる同じ行ラベルのセットを共有していることに注意してください。
Pandas DataFrame を作成する方法
pandas データ フレームを作成するには、いくつかの方法があります。 このチュートリアルでは、次の方法について説明します。
- NumPy 配列からデータ フレームを作成する
- Python 辞書からのデータ フレームの作成
- CSV ファイルを読み込んでデータ フレームを作成する
NumPy 配列から
NumPy 配列からデータ フレームを作成しましょう。
任意の週に、各学生が $0 から $100 の間のどこかで支出すると仮定して、形状 (6,4) のデータ配列を作成しましょう。 NumPy のrandomモジュールのrandint()関数は、指定された間隔[low,high)でランダムな整数の配列を返します。
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) pandas データ フレームを作成するには、次に示すように、 DataFrameコンストラクターを使用して NumPy 配列をdata引数として渡します。
students_df = pd.DataFrame(data=data) これで、組み込みのtype()関数を呼び出して、 students_dfの型を確認できます。 これがDataFrameオブジェクトであることがわかります。
type(students_df) # pandas.core.frame.DataFrame print(students_df) 
デフォルトでは、0 からnumRows – 1 までの範囲インデックスがあり、列ラベルは 0、1、2、…、 numCols –1 です。 ただし、これにより可読性が低下します。 わかりやすい列名と行ラベルをデータ フレームに追加すると役立ちます。
2 つのリストを作成してみましょう。1 つは学生の名前を格納するリストで、もう 1 つは列ラベルを格納するリストです。
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] DataFrameコンストラクターを呼び出すときに、使用する行ラベルと列ラベルのリストにそれぞれindexとcolumnsを設定できます。
students_df = pd.DataFrame(data = data,index = students,columns = cols) これで、説明的な行と列のラベルが付いたstudents_dfデータ フレームができました。
print(students_df) 
欠損値やデータ型など、データ フレームに関する基本的な情報を取得するには、データ フレーム オブジェクトでinfo()メソッドを呼び出します。
students_df.info() 
Python 辞書から
Python ディクショナリから pandas データ フレームを作成することもできます。
ここで、 data_dictは学生データを含む辞書です。
- 生徒の名前がキーです。
- 各値は、各学生が第 1 週から第 4 週までに費やした金額のリストです。
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Python ディクショナリからデータ フレームを作成するには、以下に示すようにfrom_dictを使用します。 最初の引数は、データ ( data_dict ) を含む辞書に対応します。 デフォルトでは、キーはデータ フレームの列名として使用されます。 キーを行ラベルとして設定したいので、 orient= 'index'を設定します。
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 
列名を週番号に変更するには、列をcolsリストに設定します。

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 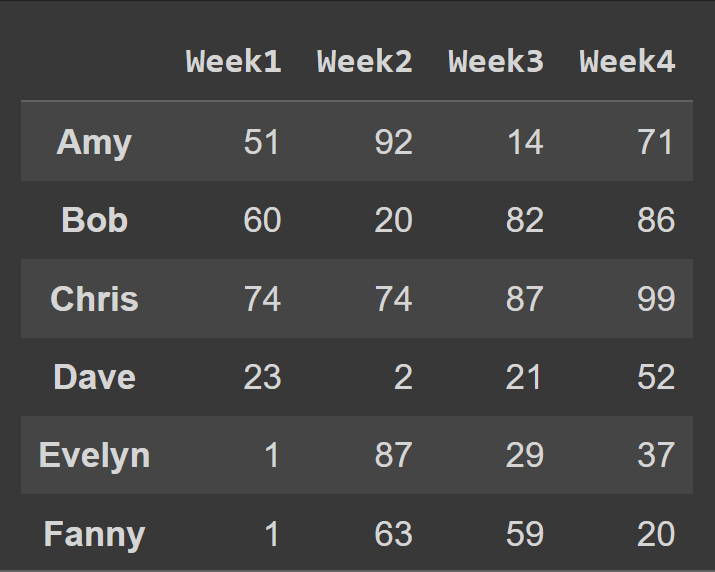
CSV ファイルを Pandas DataFrame に読み込む
生徒のデータが CSV ファイルで利用できるとします。 read_csv()関数を使用して、ファイルからデータを pandas データ フレームに読み込むことができます。 pd.read_csv('file-path')は一般的な構文で、 file-pathは CSV ファイルへのパスです。 使用する列名のリストにnamesパラメータを設定できます。
students_df = pd.read_csv('/content/students.csv',names=cols)データ フレームを作成する方法がわかったので、行と列を選択する方法を学びましょう。
Pandas DataFrame から列を選択する
データ フレームから行と列を選択するために使用できる組み込みメソッドがいくつかあります。 このチュートリアルでは、データ フレームから列、行、および行と列の両方を選択する最も一般的な方法について説明します。
単一の列の選択
単一の列を選択するには、 df_name[col_name]を使用できます。ここで、 col_nameは列の名前を示す文字列です。
ここでは、「Week1」列のみを選択します。
week1_df = students_df['Week1'] print(week1_df) 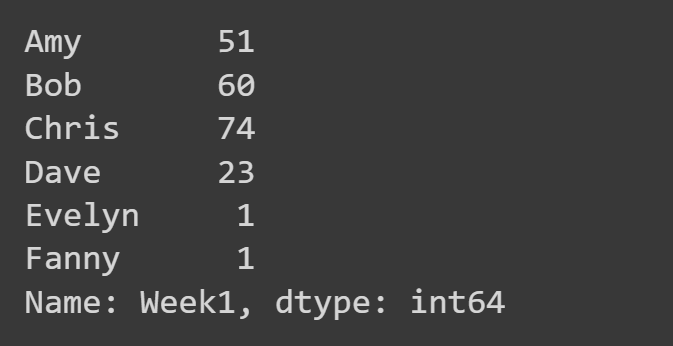
複数の列の選択
データ フレームから複数の列を選択するには、選択するすべての列名のリストを渡します。
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 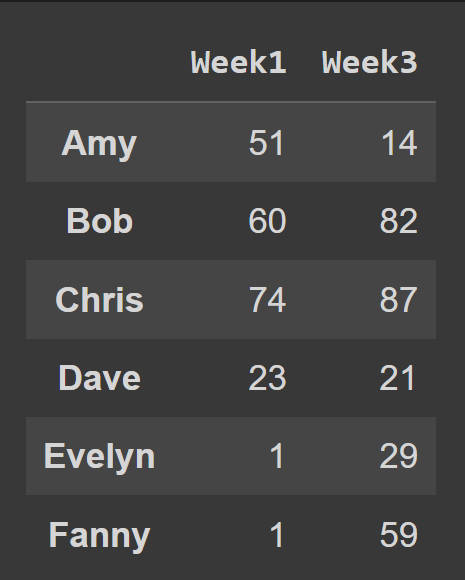
このメソッドに加えて、 iloc()およびloc()メソッドを使用して列を選択することもできます。 後で例をコーディングします。
Pandas DataFrame から行を選択

.iloc() メソッドの使用
iloc()メソッドを使用して行を選択するには、すべての行に対応するインデックスをリストとして渡します。
この例では、奇数インデックスの行を選択します。
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 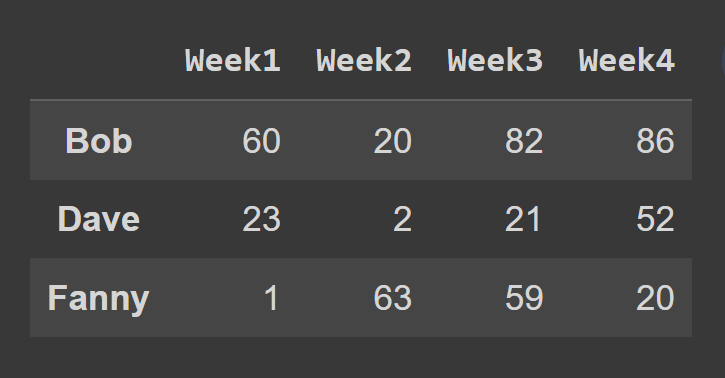
次に、インデックス 0 から 2 の行を含むデータ フレームのサブセットを選択します。エンド ポイント 3 はデフォルトで除外されます。
slice1 = students_df.iloc[0:3] print(slice1) 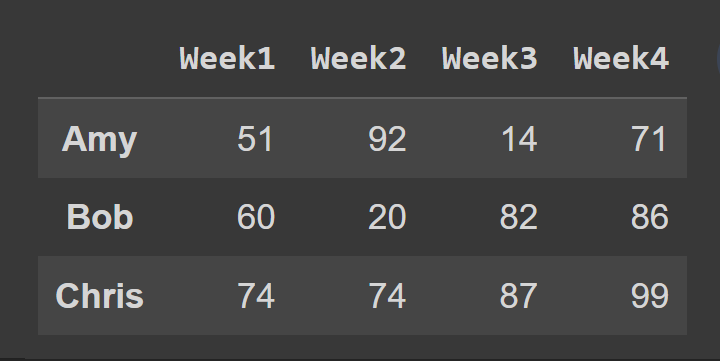
.loc() メソッドの使用
loc()メソッドを使用してデータ フレームの行を選択するには、選択する行に対応するラベルを指定する必要があります。
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 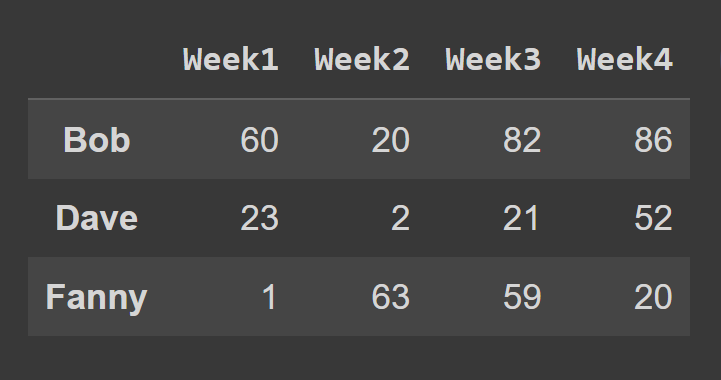
データ フレームの行が
numRows-1 までのデフォルト範囲 0、1、2 を使用してインデックス付けされている場合、iloc()とloc()の使用はどちらも同等です。
Pandas DataFrame から行と列を選択する
ここまでで、pandas データ フレームから行または列を選択する方法を学習しました。 ただし、行と列の両方のサブセットを選択する必要がある場合があります。 それで、あなたはそれをどのようにしますか? 説明したiloc()およびloc()メソッドを使用できます。
たとえば、以下のコード スニペットでは、インデックス 2 と 3のすべての行と列を選択しています。
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 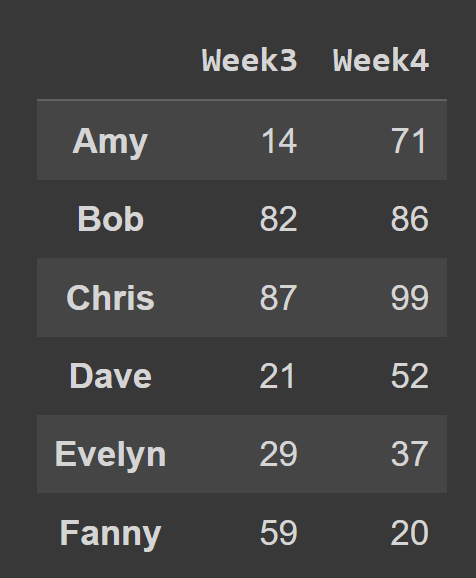
start:stopを使用すると、 startから stop までのスライスが作成されますが、 stopは含まれません。 したがって、 start stop値を無視すると、スライスは最初から始まり、データ フレームの最後まで拡張され、すべての行が選択されます。
loc()メソッドを使用する場合、次のように、選択する行と列のラベルを渡す必要があります。
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 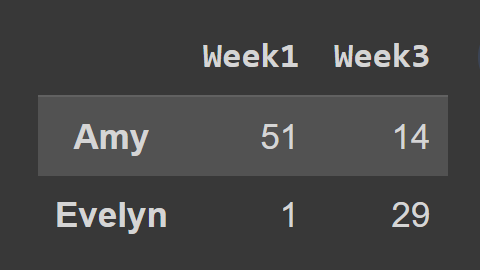
ここで、データフレームsubset_df2には、Week1とWeek3のAmyとEvelynのレコードが含まれています。
結論
このチュートリアルで学んだことの簡単な復習は次のとおりです。
- pandas をインストールしたら、エイリアス
pdでインポートできます。 pandas データ フレーム オブジェクトを作成するには、pd.DataFrame(data)コンストラクターを使用できます。ここで、dataは N 次元配列またはデータを含む iterable を参照します。 オプションのindex パラメータと columns パラメータをそれぞれ設定することで、行とインデックス、および列のラベルを指定できます。 -
pd.read_csv(path-to-the-file)使用すると、ファイルの内容がデータ フレームに読み込まれます。 - データ フレーム オブジェクトで
info()メソッドを呼び出して、列、欠損値の数、データ型、およびデータ フレームのサイズに関する情報を取得できます。 - 単一の列を選択するには
df_name[col_name]を使用し、複数の列、特定の列を選択するにはdf_name[[col1,col2,...,coln]]します。 -
loc()およびiloc()メソッドを使用して列と行を選択することもできます。 -
iloc()メソッドは選択する行と列のインデックス (またはインデックス スライス) を受け取りますが、loc()メソッドは行と列のラベルを受け取ります。
このチュートリアルで使用されている例は、この Colab ノートブックにあります。
次に、共同データ サイエンス ノートブックのリストを確認してください。