
孤立したページ: SEO のためにそれらを修正する必要がある理由とその方法
公開: 2022-09-30サイトの訪問者があなたの Web ページを見つけられない場合、そのコンテンツはあなた (または彼ら) にとって何の役にも立ちません。 Web ページの作成に投資した後は、訪問者や検索エンジンのクローラーがアクセスできることを確認して、孤立したページになってしまわないようにします。
孤立したページとは?
孤立したページは、それを指し示す内部リンクを持たない Web ページです。 Web クローラーは通常、内部リンクをクロールしてコンテンツを「見つける」ため、サイトマップに含まれるか、検索エンジンに直接送信されない限り、孤立したページを発見することはできません。
それを指し示すリンクがなければ、サイトの訪問者は孤立したページにアクセスできません。 コンバージョンに向けた優れたコンテンツを作成できます。 ただし、それを指すリンクがない場合、サイトの訪問者はそれを見つけることができません.
場合によっては、孤立したページが他の孤立したページにリンクし、オーガニック トラフィックを引き付けることさえあります。 ただし、サイトの残りの部分からアクセスできないため、内部リンクから渡されるリンク エクイティの恩恵を受けないため、ランキングの可能性を最大限に発揮できない可能性があります。
孤立したページが存在する理由
孤立したページは、次のようなさまざまな理由で発生します。
リンク戦略なし。 孤立したページを誤って作成することは非常に簡単です。 サイト メニューに新しいページが自動的に含まれていない場合、内部リンク戦略を実施していない限り、どのページも孤立したページになる可能性があります。
削除またはリダイレクトの失敗。 一部の孤立したページは、期間限定のキャンペーンの結果です。 キャンペーンが終了すると、キャンペーンのランディング ページへのリンクが削除される場合があります。 ただし、ランディング ページ自体がリダイレクトまたは削除されない場合、孤立したページになります。
サイト移行エラー。 一部の孤立したページは、以前のサイトの反復からの「残り物」である可能性があり、サイト移行中の見落としです。
内部リンクと QA プロセスを実装することで、孤立したページの可能性を減らし、すべてのページを確実にクロールできるようにすることができます。
孤立したページは SEO にどのように影響しますか?
孤立したページは Googlebot が見つけてクロールするのが難しいため、ランク付けがうまくいかない可能性があります。
検索エンジンのクローラーは、サイトの内部リンク構造または XML サイトマップに基づいて、すべてのページを見つけます。 特定のページへのリンクがない場合、ユーザーはそのページを見つけることができません (Google に直接送信されていない限り)。 クローラーがページにアクセスできない場合、ページをインデックスに登録して検索結果に表示することはできません。
孤立したページが XML サイトマップに表示される場合でも、問題が発生する可能性があります。 サイトマップはクローラーがサイトを見つけるのに役立ちますが、内部リンクがなければページはリンク エクイティを受け取りません。 サイトの信頼できるページから内部リンクを追加すると、そのリンク エクイティの一部を孤立したページと共有するのに役立ち、多くの場合、検索ランキングでのページのパフォーマンスが向上します。
最終的に、サイトに孤立したページが多数ある場合は、それらを見つけて修正し、Web ページの作成に費やした時間と労力を最大限に活用する必要があります。
Screaming Frog で孤立したページを見つける方法
孤立したページを特定する 1 つの方法は、Screaming Frog のようなクローラー ツールを使用することです。
Screaming Frog は、Web サイト上のクロール可能なすべてのページをスキャンし、3 つの異なるソース (XML サイトマップ、Google アナリティクス、Google サーチ コンソール) から孤立したページを特定するのに役立ちます。 これら 3 つのソースから孤立したページを見つけるように Screaming Frog を構成する方法を紹介します。 孤立したページを見つける可能性を最大限に高めるために、3 つすべてを設定することをお勧めします。 ただし、ソースを 1 つまたは 2 つしか設定しない場合でも、クロール分析を実行できます。 (注: これを行うには、Screaming Frog ライセンスが必要です。)
1 – XML サイトマップをリンクする
サイトマップを追加するには、トップ メニューの [構成] に移動し、ドロップダウンから [スパイダー] を選択します。
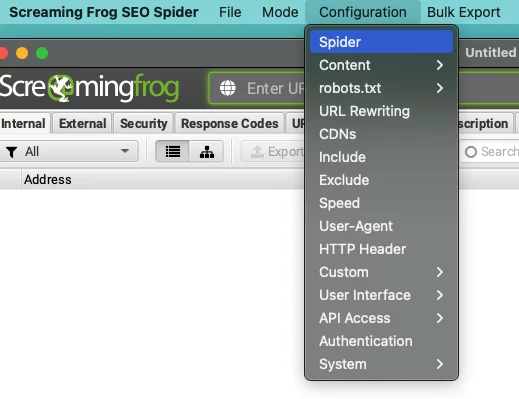
[クロール] タブに設定ボックスが表示されます。 下にスクロールして、サイトマップの URL をテキスト ボックスに貼り付けます。 [リンクされた XML サイトマップをクロールする] と [これらのサイトマップをクロールする] の横にあるボックスをオンにします。 サイトマップをテキスト ボックスに貼り付けて、[OK] をクリックします。
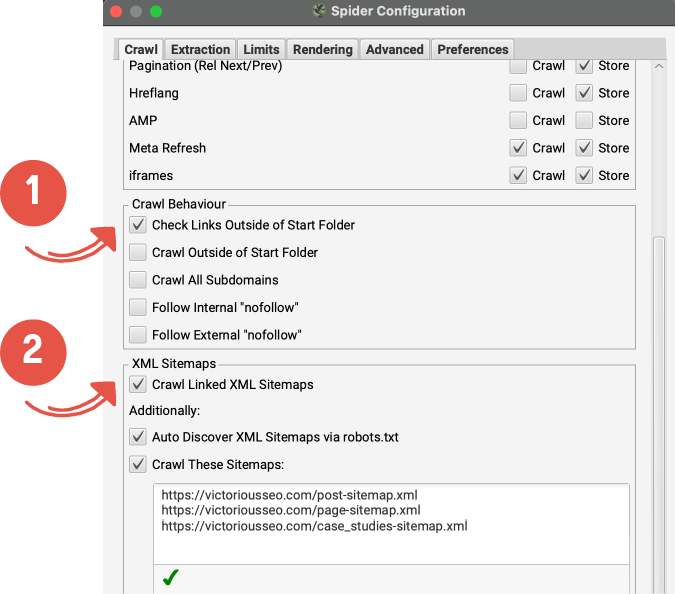
2- Google アナリティクスに接続する
「構成」→「API アクセス」に進み、Google アナリティクス API に接続します。
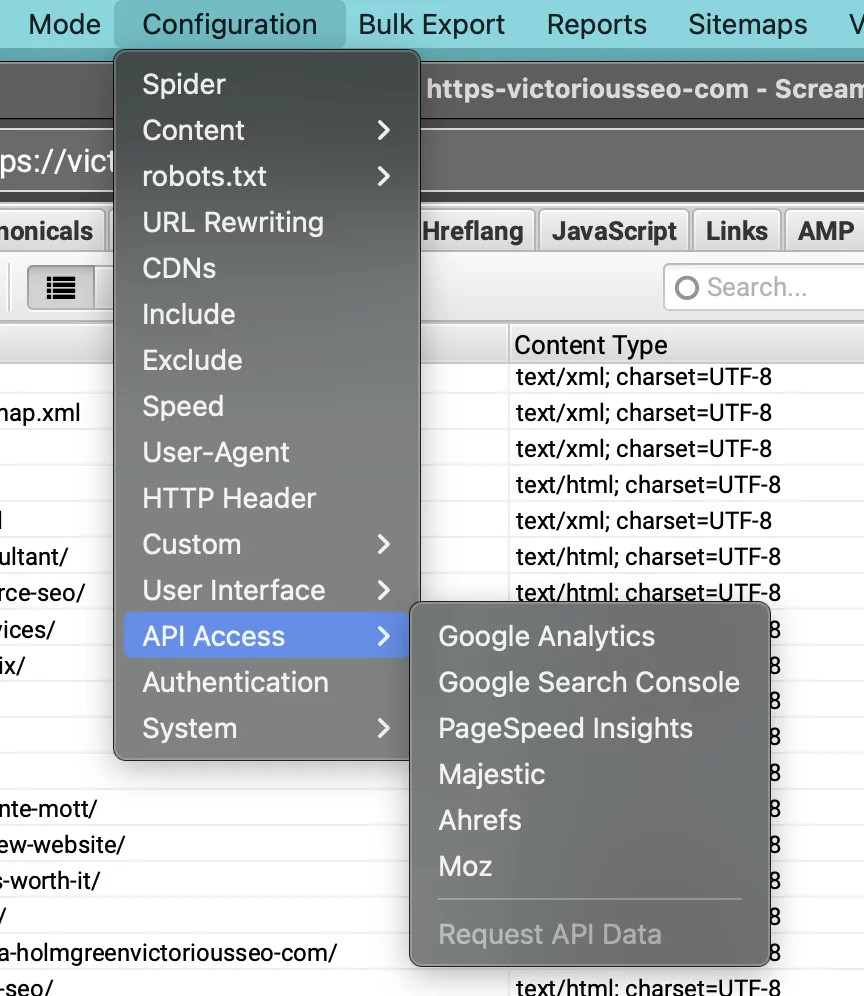
以前に Google アナリティクス アカウントを接続していない場合は、[新しいアカウントに接続] をクリックします。
これにより、Google ログイン ページが表示されます。 Screaming Frog に GA データへのアクセスを許可するには、Google アナリティクス アカウントに関連付けられているユーザー アカウントを選択します。 クロール分析が完了したら、この接続を簡単に削除できます。
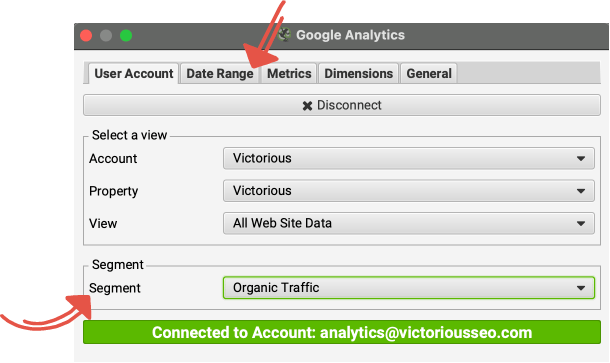
セグメント フィルターを使用すると、分析するトラフィックのソースを選択できます。 Google のオーガニック検索中に表示される孤立したページを見つけたい場合は、セグメント セクションの下から [オーガニック トラフィック] を選択します。 有料検索中に表示される可能性のある孤立したページを検出する場合は、[有料トラフィック] を選択し、すべてのトラフィック ソースを表示する場合は、[すべてのユーザー] を選択します。 [すべてのユーザー] を選択すると、最も広いネットワークがキャストされるため、孤立したページを見つけようとしている場合は、一般的にこれが適しています。
トップメニューの「日付範囲」タブから日付パラメータを設定することもできます。 デフォルトの日付範囲は 30 日ですが、必要に応じてこれを増やすことができます。 12 か月の範囲を設定すると、季節的なページを見つけるのに役立ちます。
Google アナリティクスで発見された新しい URL をクロール キューに追加して、ユーザー インターフェース内で表示できるようにするには、[一般] タブの [Google アナリティクスで発見された新しい URL をクロールする] オプションをオンにする必要があります。
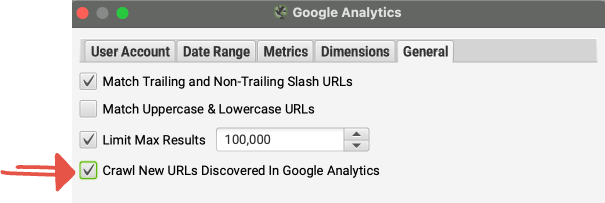
すべての設定が完了したら、[OK] をクリックします。
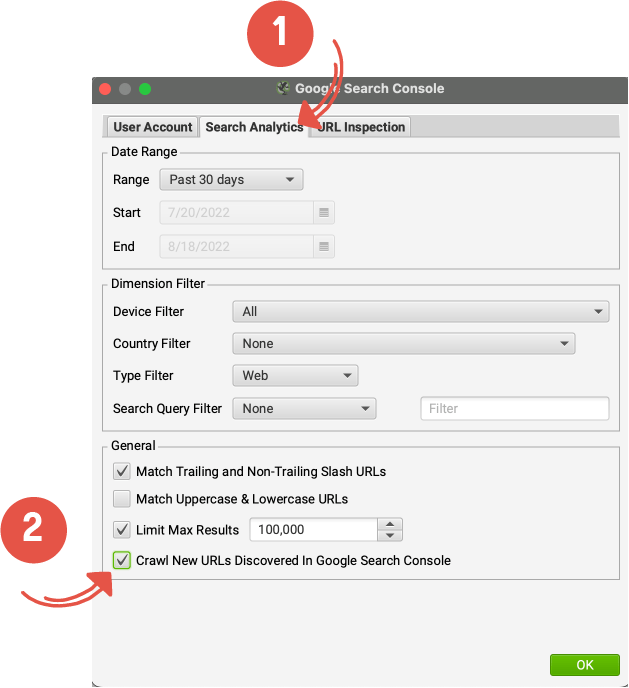
3 – Googleサーチコンソールに接続
Google Search Console に接続すると、検索でインプレッションを獲得しているが内部リンクがないページを特定するのに役立ちます。 クロールのために Google Search Console からデータを取得するには、Google アナリティクスの場合と同様に、Search Analytics API に接続する必要があります。
接続したら、適切なプロパティを選択します。
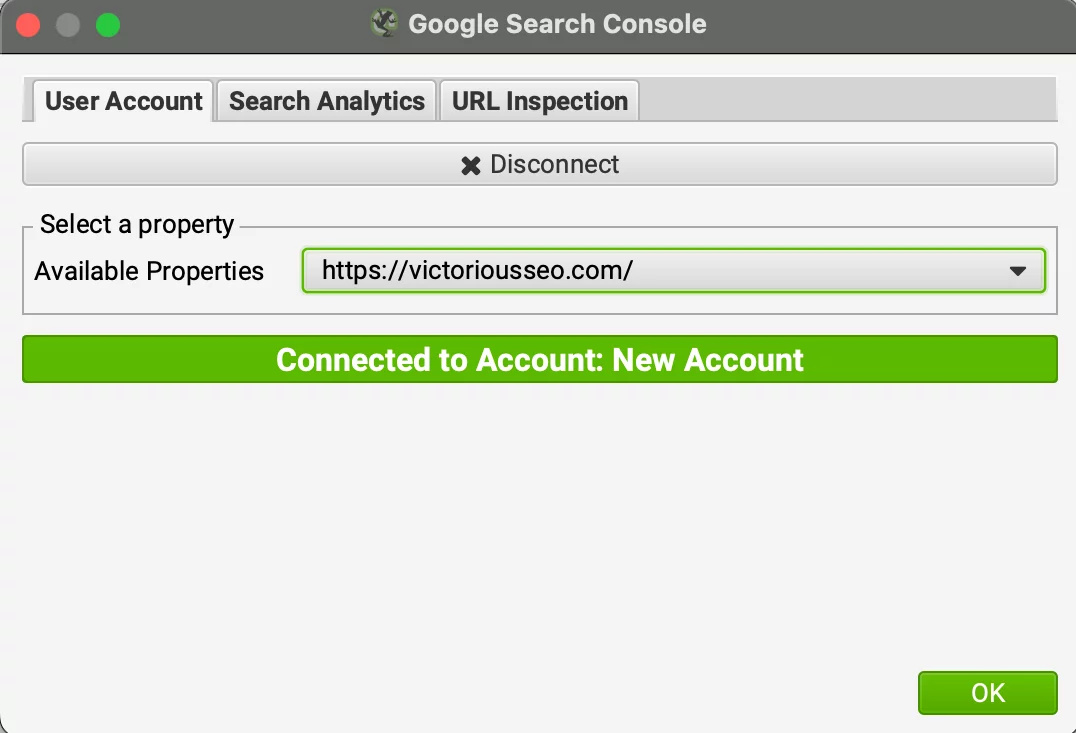
[検索アナリティクス] タブに切り替えます。 [Google Search Console で検出された新しい URL をクロールする] をオフにします。 必要に応じてデータ範囲を変更し、[OK] をクリックします。

4 – Screaming Frog でサイトをクロールする
すごい! すべてが接続されているので、サイトをクロールできるようになりました。 クロールする URL を上部のボックスに入力し、[開始] をクリックします。

5 – クロール分析の構成と実行
クロールが完了したら、トップ メニューの [クロール分析] をクリックしてから [構成] をクリックして、クロール分析を構成します。
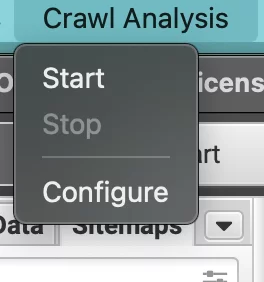
私は現在孤立した URL にのみ関心があるので、特定のオプションのチェックを外しました。 ただし、さらにデータが必要な場合は、すべてのボックスをオンにすることができます。 Sitemaps、Analytics、および Search Console のボックスがオンになっていることを確認してください。 それらのいずれにも接続していない場合は、そのボックスをオフのままにします。 [OK] をクリックします。

[クロール分析] メニューに戻り、[開始] をクリックします。
6 –孤立したページを見つける
クロール分析が完了したら、上部にある [サイトマップ] タブ、[アナリティクス] タブ、または [Search Console] タブに切り替えます。
URL を入力した場所の下に表示されない場合は、タブの横にある下向き矢印をクリックして、ドロップダウン メニューで見つけます。 [サイトマップ]、[アナリティクス]、[サーチ コンソール] がオンになっていることを確認します。 表示したくないタブのチェックを外すこともできます。
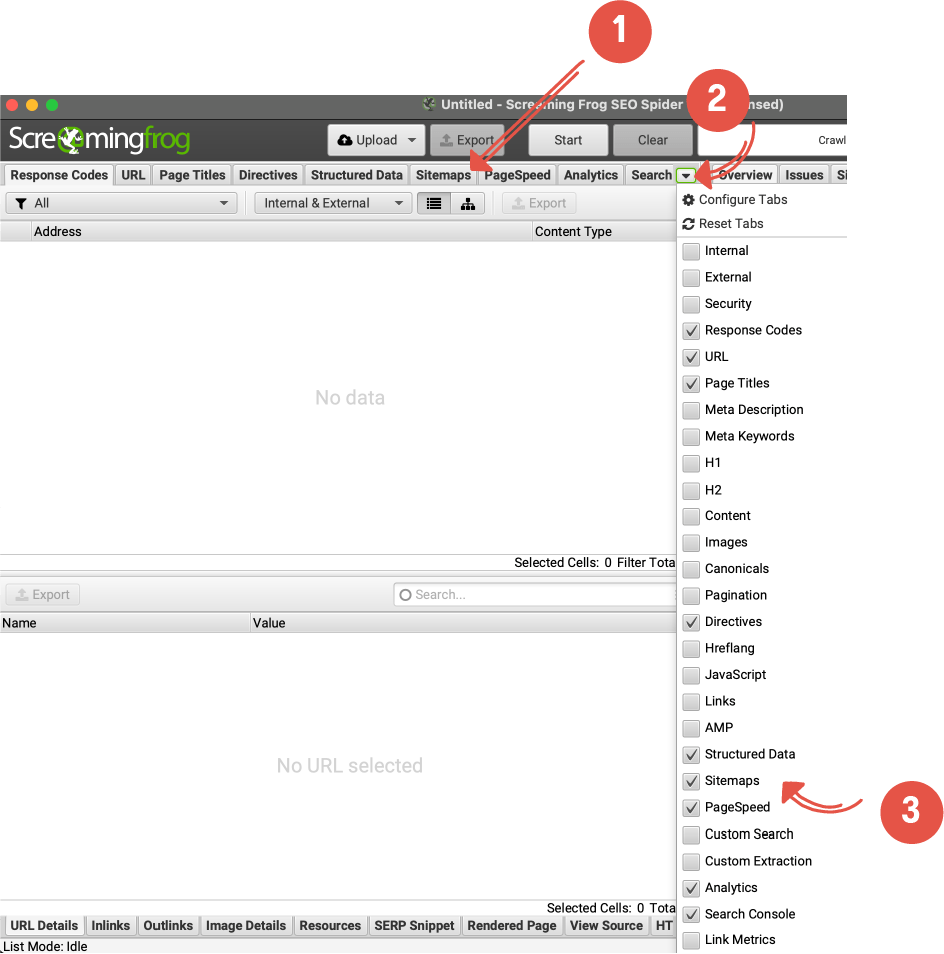
サイトマップ タグに移動します。 クロール結果をフィルタリングして孤立したページを特定できるようになりました。 クロール分析タブの下にあるじょうごをクリックし、[孤立した URL] を選択します。
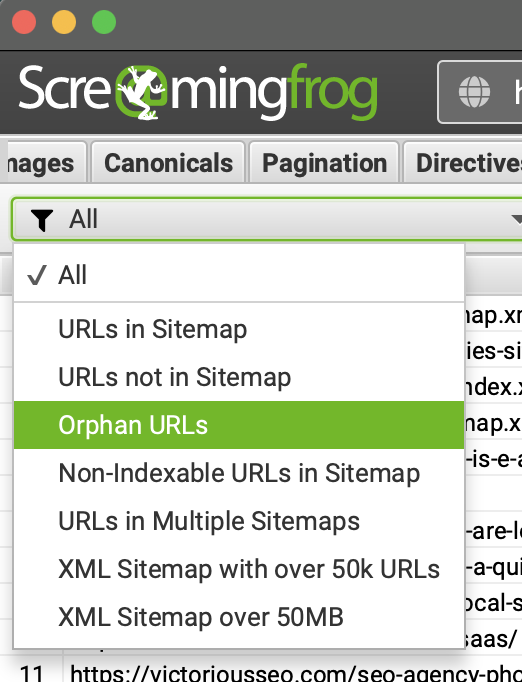
サイトマップ、Analytics、および Search Console のタブを同じ方法でフィルタリングする必要があります。これにより、これらのソースのいずれかから発見された、それらを指す内部リンクを持たない URL のみが表示されます。
孤立した URL が表示された場合は、ステータス コードをチェックして、それらがライブ ページかどうかを判断します。 Screaming Frog フィルタを使用して特定のステータス コードを含めることもできるため、[ステータス コード] 列をフィルタリングすることで、ライブ ページとリダイレクトまたはエラー ページに個別にアクセスできます。 ページを既にリダイレクトまたは削除している場合は、問題ありません。 サイトマップからも必ず削除してください。
私たちのサイトで分析を行ったところ、孤立している可能性のあるページが 1 つだけ見つかりました。 さらに調べてみると、ページがすでにリダイレクトされていることがわかりました。
検出された URL を保存する必要がある場合は、[エクスポート] をクリックします。
これにより、その 1 つのタブからのデータのみがエクスポートされます。 タブの下に異なる URL が表示される場合は、それらを個別にエクスポートする必要があります。
孤立したページを修正する方法
ほとんどの孤立したページは不適切なリンク方法の結果ですが、自然に発生し、短期間しか存在しないページもあります。 これらのページは最終的には解決されるため、何もする必要はありません。
たとえば、ステータス コード 400 のページが URL としてサイトに残っている可能性があります。 Google は既にそれらをクロールしてインデックスに登録しているため、技術的に孤立したページのままです。 これらの 400 ステータスの孤立したページがサイトマップ タブからのものである場合は、サイトマップから URL を削除して、Googlebot がこれらのエラー ページのクロールに時間を浪費しないようにします。 それらが [アナリティクス] または [サーチ コンソール] タブからのものである場合、Google は、既に削除されたリンクまたは外部リンクからページを発見した可能性があります。 いずれにせよ、彼らは最終的に 400 ステータスのために URL を無視することを学びます。
それ以外の場合は、Web サイトの孤立したページをクリーンアップするためにできることがいくつかあります。
1. 必要ですか?
孤立したページに出くわすことは、そのページの重要性を考える機会でもあります。 孤立してしまった場合、それは本当に保持したいページですか? そうでない場合は、ページをリダイレクトまたは削除します。
ページを保持したいが、Google にインデックスしてほしくない場合は、内部でリンクすることを控え、noindex robots メタ タグを実装して、インデックスに登録しないことを検索エンジンに知らせます。
インデックスを作成したいページについては、次の 3 つの手順に従います。
2. サイトマップに追加する
[アナリティクス] または [サーチ コンソール] タブで孤立したページを発見し、それがサイトマップにない場合は、追加します。 ページに内部リンクを追加するまでは、技術的に孤立したページのままですが、サイトマップは Googlebot がページをクロールするのに役立ちます。
動的に生成されたサイトマップがある場合、作成したインデックス可能なページは自動的にサイトマップに追加されます。 それ以外の場合は、インデックスを作成する各ページをサイトマップに追加する必要があります。 不注意で孤立したページが作成されるのを避けるために、これを定期的に実行してください。
3. リンクする
孤立したページの明らかな修正は、インバウンドリンクです。 Web サイトの関連ページからそのページへの内部リンクを作成すると、検索クローラーとサイト訪問者の両方がそのページを見つけられるようになります。
価値があると思われる孤立したページは、内部リンク戦略に統合する必要があります。 サイト全体をよく見て、リンクを配置するのに適切なページを少なくとも 1 つ見つけます。理想的には、説明的なアンカー テキストを使用します。
4. Googleサーチコンソールに送信
孤立したページをインデックスに登録したい場合は、内部的にリンクした後、時間をかけて Google Search Console の URL 検査ツールに送信し、インデックスに登録する必要があります。
ページの現在のインデックス ステータスに関する貴重な情報を提供するだけでなく、URL 検査ツールを使用すると、Google に特定の URL のクロールを直接リクエストできます。 リクエストを送信すると、Googlebot が独自に新しい内部リンクを見つけるのを待たずに、ページをクロール、インデックス登録、ランク付けする必要があることを Google に認識させることができます。
内部リンク戦略で孤立したページを防ぐ
孤立したページを防ぐ最善の方法は、明確なサイト構造を維持し、強固な内部リンク戦略に従うことです。 優れたサイト構造では、コンテンツをさまざまなセクションとカテゴリに分割し、ユーザー トラフィックを各セクションにより深く誘導するリンクを使用します。 ウェブサイトを拡大する際は、サイトの構造を念頭に置いて、リンクの機会を慎重に作成してください。
認定パートナーと一緒に SEO の問題に取り組みましょう
孤立したページのような SEO の問題と格闘する必要はありません。資格のあるパートナーの助けを借りて、正面から取り組みましょう。 ビクトリアスの SEO 監査サービスは、ランキングの可能性に影響を与える可能性のあるさまざまなオンページおよびオフページの問題を明らかにするのに役立ちます。 サイトの SEO を次のレベルに引き上げたい場合は、無料の SEO コンサルティングをスケジュールして開始してください。