
ページをインデックスに登録しない正しい方法
公開: 2022-12-02直感に反するように思えるかもしれませんが、Web サイトのすべてのページが検索結果に表示されるわけではありません。 検索エンジン最適化 (SEO) は、検索の可視性とオーガニック トラフィックを増やすことを目的としています。検索結果に表示されるコンテンツを制限することで、その目標を最もよく達成できる場合があります。
頭を悩ませているか、私のはったりを呼んでいる場合は、読み進めて、ページまたはサブディレクトリを noindexing することの価値と、noindex タグを実装する方法を発見してください。
Noindex とは何ですか?
「noindex」という用語は、検索エンジンの結果ページ (SERP) からページを除外するように検索クローラーに指示する、ロボット メタ タグ内の特別なディレクティブです。 つまり、検索者は検索からページにアクセスできなくなります。
技術的な SEO 戦略の重要な部分であるロボット メタ タグを使用すると、検索者に価値を提供しないページや、検索結果に表示したくない情報を保持するページを除外できます。たとえば、次のようなものです。
- 確認ページとお礼ページ
- ログインページ
- プライバシー ポリシーまたは利用規約のページ
- ゲート付きコンテンツ
- エラーメッセージ
Robots Meta タグ vs. Robots.txt vs. X-Robots タグ
robots メタ タグは、robots.txt ファイルや x-robots タグと混同されることがよくあります。 3 つすべてが、ページに関するクローラーを検索するよう指示を出し、ロボット排除プロトコル (REP) の一部です。 もっと簡単に言えば、Google 検索に何を入力し、何を除外するか、クロールする必要があるページを Google に指示します。 ただし、これらを同じ意味で使用することはできませんし、使用すべきではありません。
ロボット メタ タグ
robots メタ タグは、特定の Web ページの <head> セクションに追加され、その特定のページに関する指示のみを渡します。 多くの場合、noindex タグまたは noindex メタ タグと呼ばれる robots メタ タグは、ページをインデックスに登録しないように検索クローラーに指示するだけではありません。
また、リンクをたどらないようクローラーに依頼したり、ページを翻訳したり、特定の検索ボットをブロックしたり、キャッシュされたリンクが SERP に表示されないようにしたりするためにも使用できます。
一般的なロボット メタ タグ ディレクティブには、次のものがあります。
- noindex, nofollow — <meta name="robots" content="noindex, nofollow">
Googlebot やその他のウェブ クローラーはページにアクセスできますが、インデックスに登録したり、リンクをたどったりすることはできません。 - Noindex, follow — <meta name="robots" content="noindex">
Googlebot やその他のウェブ クローラーがページにアクセスしてリンクをたどることはできますが、ページ自体をインデックスに登録することはできません。 「follow」がデフォルトであるため、meta タグに「follow」を含める必要はありません。
ロボット.txt
robots.txt は、サイト所有者がサイトのどの部分をクロールしてほしくないかを検索エンジンに伝えるためのファイルです。 これは、ドメインまたはサブドメインのルート ディレクトリにぶら下がっている Web サイトの個人的な Do Not Disturb サインのようなものです。
robots.txt ファイルは、個々のページではなく、サブディレクトリ全体へのアクセスとクロールをブロックするのに最適です。 これを使用して、検索クローラーによるアクセスとインデックス作成をブロックします。
- 内部検索ページ
- URL パラメータ
- ユーザー生成のスパムが問題を引き起こす可能性があるフォーラム
- 従業員専用のような内部サブディレクトリ
次の手順に従って robots.txt ファイルを作成し、必ず XML サイトマップにリンクしてください。
robots.txt ファイルに含まれるページにリンクする場合は、検索結果に表示されないように、robots メタ タグを追加することもできます。 覚えておいてください - robots.txt は、クローラーがページにアクセスするのをブロックするだけで、インデックスを作成するのをブロックしません。 robots.txt ディレクティブの対象となるページが外部リンクを受け取った場合、検索エンジンはそれらをインデックスに登録することがあります。 これを回避するには、robots.txt ファイルと一緒に robots メタ タグを使用します。
Xロボットタグ
PDF、ビデオ、または画像が SERP に表示されないようにするには、x-robots タグを使用します。 robots メタ タグに指定された同じディレクティブが x-robots に使用されます。 ただし、ページの HTML ヘッダーに存在する robots メタ タグとは異なり、x-robots タグは HTTP ヘッダー レスポンスに配置されます。
ディレクティブは次のようになります。
X-Robots-Tag: noindexページをインデックスに登録しない場合
縁石指数の膨張
インデックスの肥大化は、Google が検索者にとってほとんどまたはまったく価値のないページをインデックスに登録したときに発生します。 これらの無関係なページは、より価値のあるページからリソースを奪います。 robots メタ タグを使用して、検索結果に表示されるページを管理します。
キーワードのカニバリゼーションを根絶する
キーワードのカニバリゼーションは、2 つのページが同様のキーワードと検索意図を共有している場合に発生し、SERP で互いに競合します。
互いに共食いしている 2 つのページがあり、コンテンツを変更せずに両方を維持したい場合は、noindex one. とはいえ、これは、インデックスに登録していないページが、他のページでは行わないキーワードからのトラフィックを誘導しない場合にのみ行う必要があります。 このような状況では、カニバリゼーションの問題を解決するために、ページの一方または両方のコンテンツを作り直す必要がある場合があります。
ゲート付きランディング ページを保護する
連絡先情報と引き換えに価値の高いリソースを顧客に提供する場合は、他の方法でアクセスできないようにしてください。 robots メタ タグを追加して、ページのインデックスを作成せず、SERP に表示されないようにします。
人気のない商品を検索から除外する
多くの場合、e コマース サイトでは、需要がそれほど多くないにもかかわらず、特定の顧客にサービスを提供するために商品を扱っています。 たとえば、自動車部品の小売業者や別の技術会社が、特定のモデルや希少な機器向けの製品を持っている場合があります。 これらの商品ページまたはカテゴリ ページがオーガニック トラフィックを促進していない場合、通常はインデックスに登録されていない可能性があります。
Web ページのインデックスを削除する方法
noindex メタ タグは、ページの HTML のヘッダーに挿入されます。 コードは大文字と小文字を区別せず、次のようになります。
<meta name="robots" content="noindex">「ロボット」は、ディレクティブがすべてのクローラーに適用されることを意味しますが、「ロボット」を「Googlebot」や「bingbot」などの既知のクローラー名に置き換えることで、クローラーを選択できます。

nofollow コマンドも追加しない限り、クローラーは引き続きページ上のリンクをたどります。 これは、リンク エクイティがページを通過するのを防ぐため、またはクローラーがゲート付きコンテンツへのリンクをたどるのを防ぐために行う場合があります。
nofollow 値を追加するには、noindex ディレクティブからカンマで区切ります。
<meta name="robots" content="noindex, nofollow">注:ページをインデックスに登録しない前に、Google Search Console で受信オーガニック トラフィックがあるかどうかを確認してください。 含まれている場合は、ページのインデックスを作成しない前に、サイトがこのトラフィックを引き続き獲得する方法を決定してください。
ロボット メタ タグを HTML コードに追加する方法
- noindex にしたいページのソースコードを開きます。
- ページの上部にあるヘッダーを見つけます。 <head> で始まり、</head> で終わります。 ヘッダーには他のコードも含まれている可能性があります。
- robots メタ タグを新しい行に追加し、<head> タグと </head> タグの間に表示されるようにします。
それでおしまい! ページがすでにインデックスに登録されている場合は、その URL を URL 検査ツールに貼り付けて、再クロールするよう Google に依頼できます。
すでにインデックスされていますか? URL 削除ツールを使用する
コンテンツの新しいページに noindex タグを追加すると、Googlebot はページをクロールするときにディレクティブを確認し、インデックスに登録しません。
ただし、既にインデックスに登録されているページにタグを追加する場合、そのページは、再クロールされてボットが新しい noindex 命令を確認するまで、引き続き検索結果に表示されます。 URL Inspection Tool を使用して、Google Search Console で URL を再クロールするよう Google に依頼できますが、SERP からページがすぐに削除されるわけではありません。
すぐに SERP からページを削除する必要がある場合は、Google Search Console の削除ツールを使用してください。 これにより、ページが Google 検索結果に約 6 か月表示されなくなります。 それまでに、noindex メタ タグが機能するはずです。
WordPressでページをNoindexする方法
WordPress のすべてのページは、デフォルトでインデックスされます。 Yoast SEO プラグインを使用すると、コードを記述せずに WordPress でページのインデックスを作成できません。 方法は次のとおりです。
Yoast SEO メタ ボックスの [詳細] タブをクリックします。
質問の下に、「検索エンジンがこの投稿を検索結果に表示することを許可しますか?」 ドロップダウン ボックスから [いいえ] を選択します。
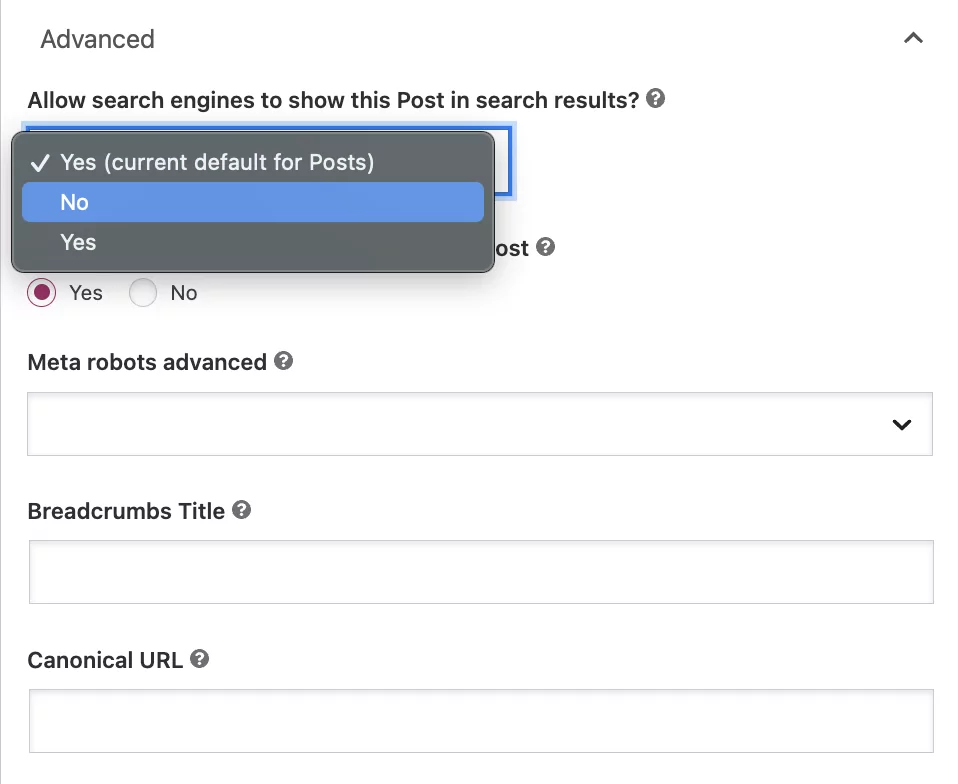
この設定は、投稿をインデックスに登録しないよう Google に指示しますが、ボットはページ上のリンクを自動的にたどって他のページをクロールします。
nofollow ディレクティブを追加する場合は、「検索エンジンはこの投稿のリンクをたどるべきですか?」という質問の下にある「いいえ」ボタンを選択します。
ロボット メタ タグに関するよくある質問
すべての検索エンジンは noindex ディレクティブに従いますか?
Google、Bing、およびその他の正当な検索エンジンが robots メタ タグに従うことを期待できます。
インデックスされていないページにリンクできますか?
はい。 noindex タグは、クロールおよびインデックス作成時にページを処理する方法を検索ボットに指示します。 ページにリンクする機能には影響しません。 これは、検索結果に表示されるべきではないブログのカテゴリ ページに役立ちますが、検索結果に表示される価値のあるページへのリンクをボットに提供できます。
robots メタ タグはいつ使用する必要がありますか?
お礼のページや印刷に適したページなど、検索者に何の価値も提供しないページがある場合は、ロボット メタ タグを使用してインデックスを作成し、SERP に表示されないようにします。
noindex ディレクティブを使用してはいけない場合は?
技術的には、noindex ディレクティブを使用してコンテンツの重複の問題や一部のクロール バジェットの問題を解決できますが、これは最善の方法ではありません。 重複したコンテンツは、canonical タグを使用して処理するのが最適です。これにより、重複からのリンク エクイティが正規ページに集中します。 クロールの予算を節約しようとしている場合は、robots.txt ファイルを使用して、サイトのそのセクションのクロールを禁止する必要があります。
インデックスされていないページはリンク エクイティを渡しますか?
はい。 ページがインデックスに登録されていなくても、構築されたランキング オーソリティを共有できます。 ただし、検索クローラーは、リンク エクイティが流れるように、ページ上のリンクをたどることができなければなりません。 ページが noindex および nofollow に設定されている場合、リンク エクイティを渡すことはできません。
ページをインデックスに登録しないと、そのページは Google SERP から自動的に削除されますか?
ページが既にインデックスに登録されている場合、robots メタ タグを追加しても、検索結果から自動的にヒットすることはありません。 すでにインデックスされているページが SERP から消えるには、しばらく時間がかかります。 検索ボットは、ページを再クロールして noindex タグを確認する必要があります。 より迅速に結果を得るには、Google にページの再クロールをリクエストし、URL 削除ツールを使用してください。
SEO監査で問題のあるページを発見
内容の薄いコンテンツや重複したコンテンツが検索の可視性に影響を与えないようにしてください。 ページがランク付けされる可能性が最も高いことを確認してください。 当社の 200 以上のポイント SEO 監査は、コンテンツの重複、robots.txt ファイルの欠落、ロボットのメタ タグの不適切な適用、インデックスの肥大化などの問題にフラグを立てます。 無料の SEO コンサルティングにサインアップして、当社の SEO 監査サービスがオンラインでの可視性を最大化し、ビジネスの成長にどのように役立つかを確認してください。