
検索エンジン クローラー向けにウェブサイトを最適化する方法
公開: 2023-04-27Web クローラーは、常に Web サイトを調べて、各ページの内容を判断します。 データは、ユーザーがリクエストを送信したときに、インデックスを作成して変更し、見つけることができます。 一部の Web サイトでは、Web クロール ロボットを使用して Web サイトのコンテンツを更新しています。
Google や Bing などの検索エンジンは、検索エンジンを Web クローラーによる情報収集と組み合わせて使用し、ユーザーの検索結果として関連する Web サイトや関連情報を表示します。
ウェブデザインなら 会社またはサイトの所有者が自分の Web サイトを検索結果に表示したい場合は、クロールしてインデックスを作成する必要があります。 サイトがクロールまたはインデックス化されていない場合、検索エンジンはサイトを有機的に見つけることができません。
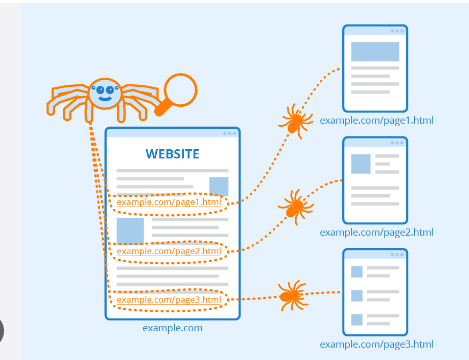
Web クローラーは、まず特定のページをクロールし、ページ上のハイパーリンクをたどって新しいページに移動します。
検索エンジンによるクロールまたは発見を望まない Web サイトは、robots.txt ファイルにあるようなツールを使用して、ロボットに Web サイトをインデックスに登録しないように、またはその一部のみをインデックスに登録するように指示することができます。
クロール ツールを使用してサイト検査を実施すると、Web サイトの所有者は、壊れたハイパーリンクや重複したコンテンツを特定するのに役立ちます。 タイトルがない、またはタイトルが長すぎる、または短すぎる。
目次
Web クロールにおける検索エンジンの役割:
1. クランチング:インターネットで情報を探してから、遭遇した各 URL のソース コード/コンテンツを調べます。
2. インデックス作成:クロール プロセスで収集された情報を管理および保存します。 ページがインデックスに含まれた後、適切な検索の結果としてそれを表示することは、継続的なプロセスになる可能性があります。
3. ランキング:ユーザーの要件を満たす可能性が最も高い情報の部分を提示します。
Google でのクロールとは正確には何ですか?
クロールとは、検索エンジンが一連のロボット (スパイダーとクローラー) を配布して新鮮で更新されたコンテンツを見つける方法です。
コンテンツは、画像、Web ページまたはビデオ、PDF など、さまざまな形式である可能性があります。形式の種類に関係なく、コンテンツはハイパーリンクを介して見つかります。
Googlebot は特定の Web サイトを検索することから始めます。 その後、ページのハイパーリンクをスキャンして新しい URL を見つけます。
クローラーは、ハイパーリンクをたどっているときに、Caffeine と呼ばれるインデックスに含めることができる新しいコンテンツを発見できます。
最近発見された URL の大規模なデータベースであり、コンテンツ URL が完全に一致するサイトの情報を誰かが検索しているときに取得できます。
検索エンジンのランキング:
誰かが Google 検索を行っているとき、検索エンジンはインデックスをスキャンして適切なコンテンツを見つけ、コンテンツを並べ替えて質問を解決します。
関連性に従って検索結果が並べられる順序は、ランキングと呼ばれます。
検索エンジンのクローラーがサイトの特定の部分またはすべてをクロールするのをブロックしたり、特定の Web サイトをインデックスに含めないように検索エンジンに指示したりできます。
検索エンジンの結果にインデックスされたウェブサイトを確認したい場合は、クローラーがアクセスでき、インデックス可能であることを確認する必要があります。
クロール検索エンジン:
これまで見てきたように、サイトが検索結果に表示されるためには、サイトがクロールされ、インデックスに登録され、クロールされていることを確認することが不可欠です。 あなたの会社の場合 サイトはあなたが見ているサイトのインデックスにあるので、検索結果内のページ数を見ることから始めることをお勧めします.

これにより、Google がウェブサイトをどのようにクロールして、リンクしたいページを見つけたが、リンクしていないページを発見しなかったかについての優れた洞察を得ることができます。
結果: Google が表示する結果の数は正確ではありません。 ただし、サイトで見つかったページと、それらが検索結果ページにどのように表示されるかを理解するのに役立ちます。
このツールを使用すると、Web デザインのトレンドがサイトにサイトマップをアップロードし、送信されたページ数を追跡して Google のインデックスやその他の側面に追加することができます。
検索結果ページにサイトが表示されない場合は、次のような理由が考えられます。
- あなたのサイトは新しく、まだクロールされていません。
- あなたのサイトのナビゲーションは、クローラーがサイトを効率的にナビゲートするのを難しくしています。
- Web サイトには、検索エンジンからのクローラーの指示をブロックするクローラー ディレクティブと呼ばれる要素コードがあります。
- あなたのサイトは、スパム行為を使用していたため、Google によってリストから削除されました。
検索エンジンにサイトへのアクセス方法を知らせます:
Google Search Console または「site: domain.com」高度な検索エンジンを試してみたところ、重要なページの一部がインデックスに登録されていない、またはそれほど重要でない特定のページが適切にインデックス登録されていないことがわかった場合の場合、ウェブサイトのコンテンツをクロールする方法で Googlebot を管理する方法がいくつかあります。
多くのサイトは、Google が最も重要な Web サイトを確実に見つけられるようにすることに重点を置いていますが、Googlebot が見つけないようにしたいいくつかのページである可能性が最も高いものを見落としがちです。
これらは、情報のない古い URL や多数の URL (e コマースのフィルターや並べ替えパラメーターなど)、プロモーション コード、ステージング ページまたはテスト ページなどである可能性があります。
結論:
Google は、Web サイトの正しい URL を判断する優れた仕事をしています。
ただし、Search Console 内でこの機能を利用して、ウェブサイトの処理方法を Google に正確に伝えることもできます。
この機能を利用して Googlebot に「パラメーター ____ を含まない URL をクロールして見つける」ように指示すると、Googlebot はこの情報を Googlebot から遠ざけ、検索結果からこれらのページを削除するよう説得しようとします。
これらのパラメーターが重複ページにつながる場合、それがあなたが求めているものです。 ただし、これらのページを含めたい場合は、これに代わるより良い方法があります。
よくある質問:
ログインフォームを使用すると、ウェブサイトのコンテンツが消えますか?
特定の Web サイトにアクセスする前に、サインアップしてフォームやアンケートに記入することをユーザーに要求すると、検索エンジンは保護されたページにアクセスできなくなります。 クローラーは、ログイン時に支援を必要とするに違いありません。
Google の検索ページを使用する必要がありますか?
ロボットは検索フォームにアクセスできません。 一部の人々は、自分のサイトに検索オプションを含めれば、検索エンジンはユーザーが探しているものを見つけることができると信じています。
検索エンジンはあなたのサイトの方向性に従うことができますか?
クローラーは、他の Web サイトへのハイパーリンクを介して Web サイトを見つけ、ユーザーをあるページから別のページに誘導するリンクのリストを要求する必要があります。 検索エンジンに見つけてもらいたいページがあるが、それが別のページに接続されていない場合は、気付かれないよりもはるかに効果的です。