
異常検出: ネットワークへの侵入を防止するためのガイド
公開: 2023-01-09データは企業や組織にとって不可欠な要素であり、適切に構造化され、効率的に管理された場合にのみ価値があります。
統計によると、今日の企業の 95% が、非構造化データの管理と構造化に問題を感じています。
ここでデータ マイニングの出番です。これは、大量の非構造化データから意味のあるパターンと価値のある情報を発見、分析、抽出するプロセスです。
企業は、ソフトウェアを使用して大規模なデータ バッチのパターンを特定し、顧客やターゲット ユーザーについて詳しく学び、売り上げを伸ばしてコストを削減するためのビジネスおよびマーケティング戦略を開発します。
この利点に加えて、詐欺と異常の検出は、データ マイニングの最も重要なアプリケーションです。
この記事では、異常検出について説明し、データ侵害やネットワークへの侵入を防止してデータ セキュリティを確保する方法について詳しく説明します。
異常検出とその種類とは?

データ マイニングには、相互に関連するパターン、相関関係、および傾向を見つけることが含まれますが、ネットワーク内の異常または外れ値のデータ ポイントを見つける優れた方法です。
データ マイニングの異常とは、データセット内の他のデータ ポイントとは異なり、データセットの通常の動作パターンから逸脱したデータ ポイントです。
異常は、次のような異なるタイプとカテゴリに分類できます。
- イベントの変化:以前の正常な動作からの突然または体系的な変化を指します。
- 外れ値:データ収集において非体系的に現れる小さな異常なパターン。 これらは、グローバル、コンテキスト、および集合的な外れ値にさらに分類できます。
- ドリフト:データ セットの漸進的で方向性のない長期的な変化。
したがって、異常検出は、不正なトランザクションの検出、高度な不均衡を伴うケース スタディの処理、および堅牢なデータ サイエンス モデルを構築するための病気の検出に非常に役立つデータ処理手法です。
たとえば、会社はキャッシュ フローを分析して、不明な銀行口座への異常なトランザクションや定期的なトランザクションを見つけて、詐欺を検出し、さらに調査を行うことができます。
異常検出の利点
ユーザー行動の異常検出は、セキュリティ システムを強化し、より正確で正確なものにするのに役立ちます。
ネットワーク内の脅威と潜在的なリスクを特定するために、セキュリティ システムが提供するさまざまな情報を分析して理解します。
企業にとっての異常検出の利点は次のとおりです。
- 人工知能 (AI) アルゴリズムが常にデータをスキャンして異常な動作を検出するため、サイバーセキュリティの脅威とデータ侵害をリアルタイムで検出します。
- 手動による異常検出よりも迅速かつ簡単に異常なアクティビティとパターンを追跡できるため、脅威の解決に必要な労力と時間が削減されます。
- 突然のパフォーマンス低下などの運用上のエラーを発生前に特定することで、運用上のリスクを最小限に抑えます。
- 異常検出システムがなければ、企業は潜在的な脅威を特定するのに数週間から数か月かかる可能性があるため、異常を迅速に検出することで、ビジネス上の重大な損害を排除するのに役立ちます。
したがって、異常検出は、成長の機会を見つけ、セキュリティの脅威と運用上のボトルネックを排除するために、大規模な顧客およびビジネス データ セットを格納する企業にとって大きな資産です。
異常検出の手法
異常検出では、いくつかの手順と機械学習 (ML) アルゴリズムを使用して、データを監視し、脅威を検出します。
主な異常検出手法は次のとおりです。
#1。 機械学習技術

機械学習技術では、ML アルゴリズムを使用してデータを分析し、異常を検出します。 異常検出のためのさまざまな種類の機械学習アルゴリズムには、次のものがあります。
- クラスタリング アルゴリズム
- 分類アルゴリズム
- 深層学習アルゴリズム
また、異常と脅威の検出に一般的に使用される ML 手法には、サポート ベクター マシン (SVM)、k-means クラスタリング、およびオートエンコーダーが含まれます。
#2。 統計手法
統計手法では、統計モデルを使用してデータ内の異常なパターン (特定のマシンのパフォーマンスの異常な変動など) を検出し、期待値の範囲を超える値を検出します。
一般的な統計的異常検出手法には、仮説検定、IQR、Z スコア、修正 Z スコア、密度推定、箱ひげ図、極値分析、およびヒストグラムが含まれます。
#3。 データマイニング技術

データ マイニング技術では、データの分類とクラスタリングの技術を使用して、データ セット内の異常を見つけます。 一般的なデータ マイニングの異常手法には、スペクトル クラスタリング、密度ベースのクラスタリング、主成分分析などがあります。
クラスタリング データ マイニング アルゴリズムを使用して、さまざまなデータ ポイントを類似性に基づいてクラスタにグループ化し、これらのクラスタの外にあるデータ ポイントと異常を検出します。
一方、分類アルゴリズムは、データ ポイントを特定の定義済みクラスに割り当て、これらのクラスに属さないデータ ポイントを検出します。
#4。 ルールベースの手法
名前が示すように、ルールベースの異常検出手法では、事前に定義された一連のルールを使用して、データ内の異常を検出します。
これらの手法は比較的簡単に設定できますが、柔軟性に欠ける場合があり、データの動作やパターンの変化に効率的に適応できない場合があります。
たとえば、ルールベースのシステムを簡単にプログラムして、特定の金額を超える取引に不正としてフラグを立てることができます。
#5。 ドメイン固有の手法
ドメイン固有の手法を使用して、特定のデータ システムの異常を検出できます。 ただし、特定のドメインでの異常の検出には非常に効率的である可能性がありますが、指定されたドメイン以外の他のドメインでは効率が低下する可能性があります。
たとえば、ドメイン固有の手法を使用して、特に金融取引の異常を検出する手法を設計できます。 ただし、マシンの異常やパフォーマンスの低下を検出するためには機能しない場合があります。
異常検出のための機械学習の必要性
機械学習は非常に重要であり、異常検出に非常に役立ちます。
今日、外れ値の検出を必要とするほとんどの企業や組織は、テキスト、顧客情報、トランザクションから、画像やビデオ コンテンツなどのメディア ファイルに至るまで、膨大な量のデータを扱っています。
毎秒手動で生成されるすべての銀行取引とデータを調べて、有意義な洞察を引き出すことはほとんど不可能です。 さらに、ほとんどの企業は、構造化されていないデータを構造化し、データ分析のために意味のある方法でデータを整理するという課題と大きな困難に直面しています。
これは、機械学習 (ML) などのツールと技術が、膨大な量の非構造化データの収集、クリーニング、構造化、配置、分析、保存において大きな役割を果たす場所です。
機械学習の手法とアルゴリズムは、大規模なデータ セットを処理し、さまざまな手法とアルゴリズムを使用および組み合わせて最適な結果を提供する柔軟性を提供します。
さらに、機械学習は、実世界のアプリケーションの異常検出プロセスを合理化し、貴重なリソースを節約するのにも役立ちます。
異常検出における機械学習のその他の利点と重要性を次に示します。
- 明示的なプログラミングを必要とせずにパターンと異常の識別を自動化することで、異常検出のスケーリングを容易にします。
- 機械学習アルゴリズムは、変化するデータ セット パターンに高度に適応できるため、時間の経過とともに非常に効率的で堅牢になります。
- 大規模で複雑なデータセットを簡単に処理できるため、データセットが複雑であっても異常検出を効率的に行うことができます。
- 異常が発生したときにそれを特定することで、異常の早期特定と検出を保証し、時間とリソースを節約します。
- 機械学習ベースの異常検出システムは、従来の方法と比較して異常検出の精度を向上させるのに役立ちます。
したがって、機械学習と組み合わせた異常検出は、異常をより迅速かつ早期に検出して、セキュリティの脅威や悪意のある侵害を防ぐのに役立ちます。
異常検出のための機械学習アルゴリズム
分類、クラスタリング、またはアソシエーション ルールの学習のためのさまざまなデータ マイニング アルゴリズムを利用して、データの異常や外れ値を検出できます。
通常、これらのデータ マイニング アルゴリズムは、教師あり学習アルゴリズムと教師なし学習アルゴリズムの 2 つの異なるカテゴリに分類されます。

教師あり学習
教師あり学習は、サポート ベクター マシン、ロジスティックおよび線形回帰、マルチクラス分類などのアルゴリズムで構成される一般的なタイプの学習アルゴリズムです。 このアルゴリズム タイプはラベル付きデータでトレーニングされます。つまり、そのトレーニング データ セットには、予測モデルを構築するための通常の入力データと対応する正しい出力または異常な例の両方が含まれます。
したがって、その目標は、トレーニング データ セットのパターンに基づいて、目に見えない新しいデータの出力予測を行うことです。 教師あり学習アルゴリズムのアプリケーションには、画像および音声認識、予測モデリング、自然言語処理 (NLP) などがあります。
教師なし学習
教師なし学習 ラベル付きデータでトレーニングされていません。 代わりに、トレーニング アルゴリズムのガイダンスを提供したり、特定の予測を行ったりすることなく、複雑なプロセスと基礎となるデータ構造を発見します。
教師なし学習アルゴリズムのアプリケーションには、異常検出、密度推定、およびデータ圧縮が含まれます。
それでは、一般的な機械学習ベースの異常検出アルゴリズムをいくつか見ていきましょう。
ローカル外れ値係数 (LOF)
Local Outlier Factor (LOF) は、ローカル データ密度を考慮してデータ ポイントが異常かどうかを判断する異常検出アルゴリズムです。
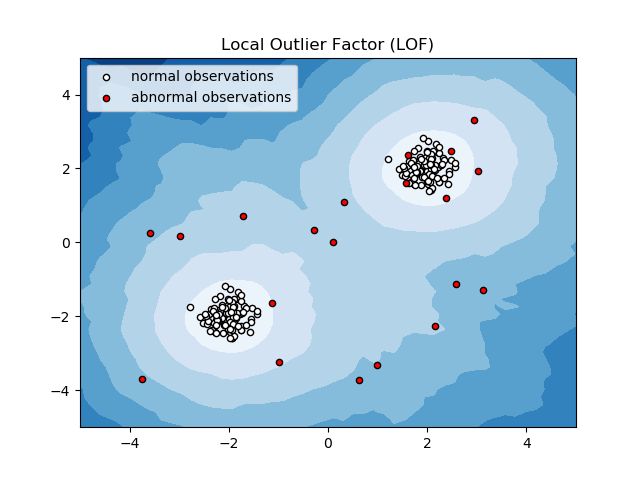
アイテムの局所密度をその近傍の局所密度と比較して、同様の密度の領域と、近傍よりも密度が比較的低いアイテム (異常または異常値に他ならない) を分析します。
したがって、簡単に言えば、外れ値または異常な項目を囲む密度は、その近傍の密度とは異なります。 したがって、このアルゴリズムは、密度ベースの外れ値検出アルゴリズムとも呼ばれます。
K 最近傍 (K-NN)
K-NN は、実装が簡単な最も単純な分類および監視付き異常検出アルゴリズムであり、使用可能なすべての例とデータを保存し、距離メトリックの類似性に基づいて新しい例を分類します。
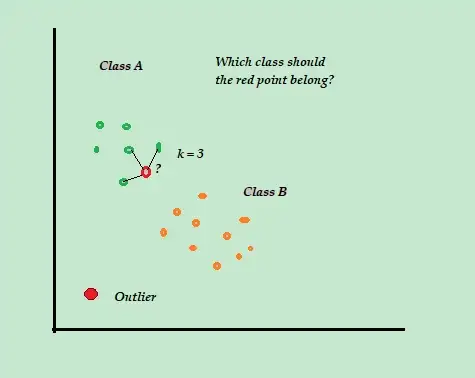
この分類アルゴリズムは、トレーニング プロセス中に他に何もせずに、ラベル付けされたトレーニング データのみを保存するため、遅延学習器とも呼ばれます。
新しいラベルのないトレーニング データ ポイントが到着すると、アルゴリズムは K 最近傍または最も近いトレーニング データ ポイントを調べて、それらを使用して新しいラベルのないデータ ポイントのクラスを分類および決定します。
K-NN アルゴリズムは、次の検出方法を使用して、最も近いデータ ポイントを決定します。
- 連続データの距離を測定するためのユークリッド距離。
- 離散データの 2 つのテキスト文字列の近接性または「近さ」を測定するためのハミング距離。
たとえば、トレーニング データ セットが A と B の 2 つのクラス ラベルで構成されているとします。新しいデータ ポイントが到着すると、アルゴリズムは新しいデータ ポイントとデータ セット内の各データ ポイントの間の距離を計算し、ポイントを選択します。これは、新しいデータ ポイントに最も近い数の最大値です。
したがって、K=3 で、3 つのデータ ポイントのうち 2 つが A としてラベル付けされていると仮定すると、新しいデータ ポイントはクラス A としてラベル付けされます。
したがって、K-NN アルゴリズムは、頻繁にデータを更新する必要がある動的な環境で最適に機能します。
これは、不正なトランザクションを検出し、不正検出率を高めるために、金融やビジネスのアプリケーションで人気のある異常検出およびテキスト マイニング アルゴリズムです。
サポート ベクター マシン (SVM)
サポート ベクター マシンは、主に回帰および分類の問題で使用される、教師あり機械学習ベースの異常検出アルゴリズムです。
多次元超平面を使用して、データを 2 つのグループ (新規および通常) に分離します。 したがって、超平面は、通常のデータ観測と新しいデータを分離する決定境界として機能します。
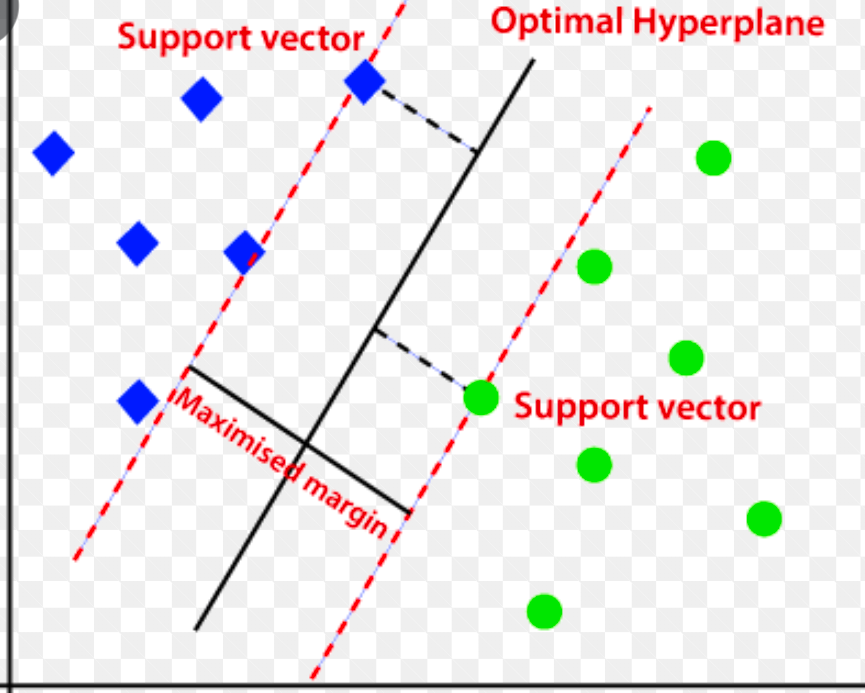
これら 2 つのデータ ポイント間の距離は、マージンと呼ばれます。
目標は 2 点間の距離を大きくすることであるため、SVM は、2 つのクラス間の距離ができるだけ広くなるように、マージンが最大の最適な超平面を決定します。
異常検出に関しては、SVM は超平面から新しいデータ ポイント観測のマージンを計算して分類します。
マージンが設定されたしきい値を超えると、新しい観測が異常として分類されます。 同時に、マージンがしきい値よりも小さい場合、観測は正常に分類されます。
したがって、SVM アルゴリズムは、高次元で複雑なデータ セットを非常に効率的に処理できます。
孤立の森
Isolation Forest は、ランダム フォレスト分類子の概念に基づく教師なし機械学習異常検出アルゴリズムです。
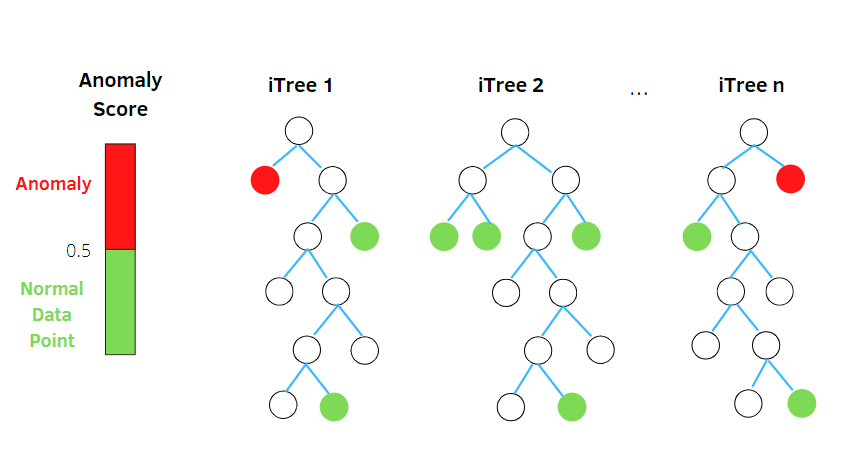
このアルゴリズムは、ランダムな属性に基づいて、ツリー構造のデータ セット内のランダムにサブサンプリングされたデータを処理します。 観測を分離するためにいくつかの決定木を構築します。 また、特定の観察結果が汚染率に基づいて少数の木に分離されている場合、その観察結果を異常と見なします。
したがって、簡単に言えば、アイソレーション フォレスト アルゴリズムはデータ ポイントを異なる決定木に分割し、各観測が別の観測から分離されるようにします。
通常、異常はデータ ポイント クラスターから離れているため、通常のデータ ポイントに比べて異常を簡単に特定できます。
分離フォレスト アルゴリズムは、カテゴリ データと数値データを簡単に処理できます。 その結果、トレーニングが高速になり、高次元で大規模なデータセットの異常を非常に効率的に検出できます。
四分位範囲
四分位範囲または IQR を使用して、統計的変動性または統計的分散を測定し、データ セットを四分位に分割して異常点を見つけます。
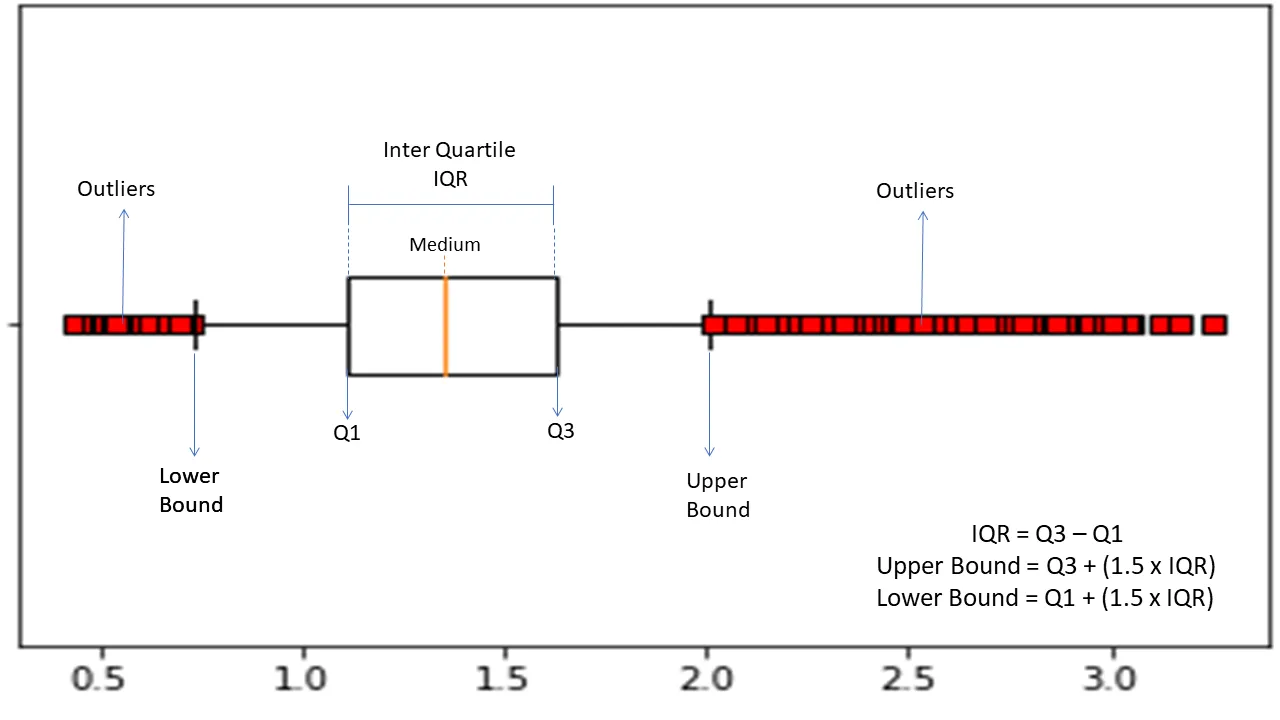
アルゴリズムはデータを昇順に並べ替え、セットを 4 つの等しい部分に分割します。 これらの部分を区切る値は、Q1、Q2、および Q3 (第 1、第 2、および第 3 四分位数) です。
これらの四分位数のパーセンタイル分布は次のとおりです。
- Q1 は、データの 25 パーセンタイルを意味します。
- Q2 は、データの 50 パーセンタイルを意味します。
- Q3 は、データの 75 パーセンタイルを意味します。
IQR は、3 番目 (75 番目) と 1 番目 (25 番目) のパーセンタイル データ セットの差であり、データの 50% を表します。
異常検出に IQR を使用するには、データセットの IQR を計算し、データの下限と上限を定義して異常を検出する必要があります。
- 下限: Q1 – 1.5 * IQR
- 上限: Q3 + 1.5 * IQR
通常、これらの境界の外にある観測は異常と見なされます。
IQR アルゴリズムは、データが不均一に分散し、その分布がよくわかっていないデータセットに効果的です。
最後の言葉
サイバーセキュリティのリスクとデータ侵害は、今後数年間抑制されないようです。このリスクの高い業界は 2023 年にさらに成長すると予想され、IoT サイバー攻撃だけでも 2025 年までに 2 倍になると予想されています。
さらに、サイバー犯罪は、2025 年までにグローバル企業や組織に年間推定 10.3 兆ドルの損害を与えると予測されています。
これが、異常検出技術の必要性がより一般的になり、今日、詐欺の検出とネットワークへの侵入の防止のために必要になっている理由です。
この記事は、データ マイニングにおける異常とは何か、さまざまな種類の異常、および ML ベースの異常検出技術を使用してネットワークへの侵入を防ぐ方法を理解するのに役立ちます。
次に、機械学習における混同行列に関するすべてを調べることができます。