
Come sincronizzare il tuo database Oracle on-premise in AWS
Pubblicato: 2023-01-11Osservando lo sviluppo del software aziendale dalla prima fila per due decenni, l'innegabile tendenza degli ultimi anni è chiara: spostare i database nel cloud.
Ero già coinvolto in alcuni progetti di migrazione, in cui l'obiettivo era quello di portare il database locale esistente nel database Amazon Web Services (AWS) Cloud. Mentre dai materiali della documentazione AWS imparerai quanto può essere facile, sono qui per dirti che l'esecuzione di un tale piano non è sempre facile e ci sono casi in cui può fallire.

In questo post tratterò l'esperienza del mondo reale per il seguente caso:
- La fonte : anche se in teoria non importa quale sia la tua fonte (puoi utilizzare un approccio molto simile per la maggior parte dei DB più popolari), Oracle è stato il sistema di database preferito nelle grandi aziende per molti anni e è lì che sarà la mia attenzione.
- L'obiettivo : Non c'è motivo per essere specifici su questo lato. Puoi scegliere qualsiasi database di destinazione in AWS e l'approccio si adatterà comunque.
- La modalità : puoi avere un aggiornamento completo o un aggiornamento incrementale. Un caricamento di dati batch (gli stati di origine e di destinazione sono ritardati) o un caricamento di dati (quasi) in tempo reale. Entrambi saranno toccati qui.
- La frequenza : potresti volere una migrazione una tantum seguita da un passaggio completo al cloud o richiedere un periodo di transizione e avere i dati aggiornati su entrambi i lati contemporaneamente, il che implica lo sviluppo di una sincronizzazione giornaliera tra on-premise e AWS. Il primo è più semplice e ha molto più senso, ma il secondo è più spesso richiesto e ha molti più punti di rottura. Tratterò entrambi qui.
Descrizione del problema
Il requisito è spesso semplice:
Vogliamo iniziare a sviluppare servizi all'interno di AWS, quindi copia tutti i nostri dati nel database "ABC". Rapidamente e semplicemente. Dobbiamo utilizzare i dati all'interno di AWS ora. Successivamente, capiremo quali parti dei progetti DB modificare per adattarle alle nostre attività.
Prima di andare oltre, c'è qualcosa da considerare:
- Non saltare troppo in fretta all'idea di "copiare ciò che abbiamo e occuparcene in seguito". Voglio dire, sì, questo è il modo più semplice che puoi fare e sarà fatto rapidamente, ma questo ha il potenziale per creare un problema architettonico così fondamentale che sarà impossibile da risolvere in seguito senza un serio refactoring della maggior parte della nuova piattaforma cloud . Immagina solo che l'ecosistema cloud sia completamente diverso da quello on-premise. Diversi nuovi servizi verranno introdotti nel tempo. Naturalmente, le persone inizieranno a usare lo stesso in modo molto diverso. Non è quasi mai una buona idea replicare lo stato on-premise nel cloud in modo 1:1. Potrebbe essere nel tuo caso particolare, ma assicurati di ricontrollare questo.
- Metti in discussione il requisito con alcuni dubbi significativi come:
- Chi sarà l'utente tipico che utilizza la nuova piattaforma? Mentre è on-premise, può essere un utente aziendale transazionale; nel cloud, può essere un data scientist o un analista di data warehouse, oppure l'utente principale dei dati potrebbe essere un servizio (ad esempio, Databricks, Glue, modelli di machine learning, ecc.).
- I normali lavori quotidiani dovrebbero rimanere anche dopo la transizione al cloud? In caso contrario, come dovrebbero cambiare?
- Prevedi una crescita sostanziale dei dati nel tempo? Molto probabilmente, la risposta è sì, poiché questo è spesso il motivo più importante per migrare nel cloud. Un nuovo modello di dati sarà pronto per questo.
- Aspettatevi che l'utente finale pensi ad alcune query generali e anticipate che il nuovo database riceverà dagli utenti. Questo definirà quanto il modello di dati esistente deve cambiare per rimanere rilevante per le prestazioni.
Impostazione della migrazione
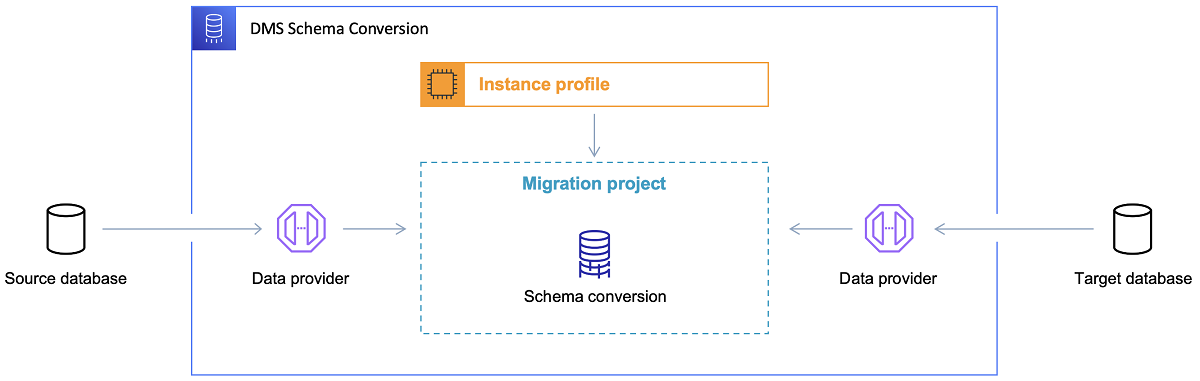
Una volta scelto il database di destinazione e discusso in modo soddisfacente il modello di dati, il passaggio successivo consiste nell'acquisire familiarità con AWS Schema Conversion Tool. Ci sono diverse aree in cui questo strumento può servire:
- Analizza ed estrai il modello di dati di origine. SCT leggerà ciò che è presente nel database on-premise corrente e genererà un modello di dati di origine con cui iniziare.
- Suggerisci una struttura del modello di dati di destinazione basata sul database di destinazione.
- Genera script di distribuzione del database di destinazione per installare il modello di dati di destinazione (in base a ciò che lo strumento ha rilevato dal database di origine). Ciò genererà script di distribuzione e, dopo la loro esecuzione, il database nel cloud sarà pronto per il caricamento dei dati dal database locale.
Ora ci sono alcuni suggerimenti per l'utilizzo dello Schema Conversion Tool.
In primo luogo, non dovrebbe essere quasi mai il caso di utilizzare direttamente l'output. Lo considererei più come risultati di riferimento, da cui dovrai apportare le modifiche in base alla tua comprensione e allo scopo dei dati e al modo in cui i dati verranno utilizzati nel cloud.
In secondo luogo, in precedenza, le tabelle sono state probabilmente selezionate dagli utenti che si aspettavano risultati rapidi e brevi su qualche entità di dominio dati concreta. Ma ora, i dati potrebbero essere selezionati per scopi analitici. Ad esempio, gli indici del database che prima funzionavano nel database on-premise ora saranno inutili e sicuramente non miglioreranno le prestazioni del sistema DB relativo a questo nuovo utilizzo. Allo stesso modo, potresti voler partizionare i dati in modo diverso sul sistema di destinazione, come era prima sul sistema di origine.
Inoltre, potrebbe essere utile considerare di eseguire alcune trasformazioni dei dati durante il processo di migrazione, il che significa sostanzialmente modificare il modello di dati di destinazione per alcune tabelle (in modo che non siano più copie 1:1). Successivamente, le regole di trasformazione dovranno essere implementate nello strumento di migrazione.
Configurazione dello strumento di migrazione
Se i database di origine e di destinazione sono dello stesso tipo (ad esempio, Oracle on-premise vs. Oracle in AWS, PostgreSQL vs. Aurora Postgresql, ecc.), allora è meglio utilizzare uno strumento di migrazione dedicato che il database concreto supporti in modo nativo ( ad esempio, esportazioni e importazioni di data pump, Oracle Goldengate, ecc.).
Tuttavia, nella maggior parte dei casi, il database di origine e quello di destinazione non saranno compatibili e quindi lo strumento di scelta ovvio sarà AWS Database Migration Service.
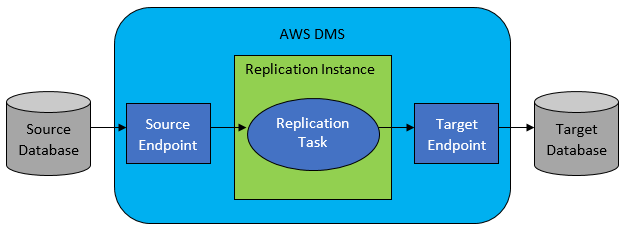
AWS DMS consente sostanzialmente di configurare un elenco di attività a livello di tabella, che definirà:
- Qual è il DB e la tabella di origine esatti a cui connettersi?
- Specifiche dell'istruzione che verranno utilizzate per ottenere i dati per la tabella di destinazione.
- Strumenti di trasformazione (se presenti), che definiscono come i dati di origine devono essere mappati nei dati della tabella di destinazione (se non 1:1).
- Qual è il database e la tabella di destinazione esatti in cui caricare i dati?
La configurazione delle attività DMS viene eseguita in un formato intuitivo come JSON.
Ora, nello scenario più semplice, è sufficiente eseguire gli script di distribuzione nel database di destinazione e avviare l'attività DMS. Ma c'è molto di più in questo.
Migrazione completa dei dati una tantum

Il caso più semplice da eseguire è quando la richiesta consiste nello spostare l'intero database una volta nel database cloud di destinazione. Quindi, in pratica, tutto ciò che è necessario fare sarà simile al seguente:

- Definire l'attività DMS per ogni tabella di origine.
- Assicurarsi di specificare correttamente la configurazione dei lavori DMS. Ciò significa impostare un parallelismo ragionevole, variabili di memorizzazione nella cache, configurazione del server DMS, dimensionamento del cluster DMS, ecc. Questa è in genere la fase che richiede più tempo in quanto richiede test approfonditi e messa a punto dello stato di configurazione ottimale.
- Assicurarsi che ogni tabella di destinazione venga creata (vuota) nel database di destinazione nella struttura della tabella prevista.
- Pianifica un intervallo di tempo entro il quale verrà eseguita la migrazione dei dati. Prima di ciò, ovviamente, assicurati (eseguendo test delle prestazioni) che la finestra temporale sia sufficiente per il completamento della migrazione. Durante la migrazione stessa, il database di origine potrebbe essere limitato dal punto di vista delle prestazioni. Inoltre, si prevede che il database di origine non cambierà durante il periodo di esecuzione della migrazione. In caso contrario, i dati migrati potrebbero essere diversi da quelli archiviati nel database di origine al termine della migrazione.
Se la configurazione di DMS viene eseguita correttamente, non accadrà nulla di male in questo scenario. Ogni singola tabella di origine verrà prelevata e copiata nel database di destinazione AWS. Le uniche preoccupazioni saranno le prestazioni dell'attività e assicurarsi che il dimensionamento sia corretto in ogni passaggio in modo che non fallisca a causa di spazio di archiviazione insufficiente.
Sincronizzazione giornaliera incrementale

È qui che le cose iniziano a complicarsi. Voglio dire, se il mondo fosse l'ideale, probabilmente funzionerebbe sempre bene. Ma il mondo non è mai ideale.
DMS può essere configurato per funzionare in due modalità:
- Pieno carico : modalità predefinita descritta e utilizzata sopra. Le attività DMS vengono avviate quando vengono avviate o quando è pianificato per l'avvio. Una volta terminato, le attività DMS sono terminate.
- Change Data Capture (CDC) : in questa modalità, l'attività DMS è in esecuzione continua. DMS esegue la scansione del database di origine per una modifica a livello di tabella. Se la modifica si verifica, tenta immediatamente di replicare la modifica nel database di destinazione in base alla configurazione all'interno dell'attività DMS correlata alla tabella modificata.
Quando scegli CDC, devi fare ancora un'altra scelta, vale a dire come CDC estrarrà le modifiche delta dal DB di origine.
#1. Lettore di registri di ripristino Oracle
Un'opzione è scegliere il lettore dei registri di ripristino del database nativo da Oracle, che CDC può utilizzare per ottenere i dati modificati e, in base alle ultime modifiche, replicare le stesse modifiche sul database di destinazione.
Sebbene questa possa sembrare una scelta ovvia se si ha a che fare con Oracle come origine, c'è un problema: il lettore dei redo log di Oracle utilizza il cluster Oracle di origine e quindi influisce direttamente su tutte le altre attività in esecuzione nel database (in realtà crea direttamente sessioni attive in la banca dati).
Più attività DMS hai configurato (o più cluster DMS in parallelo), più probabilmente avrai bisogno di aumentare le dimensioni del cluster Oracle, in pratica regolare il ridimensionamento verticale del tuo cluster di database Oracle primario. Questo influenzerà sicuramente i costi totali della soluzione, ancora di più se la sincronizzazione giornaliera sta per rimanere con il progetto per un lungo periodo di tempo.
#2. Estrattore di log AWS DMS
A differenza dell'opzione sopra, questa è una soluzione AWS nativa per lo stesso problema. In questo caso, DMS non influisce sul database Oracle di origine. Al contrario, copia i redo log di Oracle nel cluster DMS e vi esegue tutta l'elaborazione. Sebbene consenta di risparmiare risorse Oracle, è la soluzione più lenta, poiché sono coinvolte più operazioni. Inoltre, come si può facilmente supporre, il lettore personalizzato per i redo log di Oracle è probabilmente più lento nel suo lavoro come lettore nativo di Oracle.
A seconda delle dimensioni del database di origine e del numero di modifiche giornaliere, nella migliore delle ipotesi potresti ritrovarti con una sincronizzazione incrementale quasi in tempo reale dei dati dal database Oracle locale al database cloud AWS.
In qualsiasi altro scenario, non sarà ancora vicino alla sincronizzazione in tempo reale, ma puoi provare ad avvicinarti il più possibile al ritardo accettato (tra origine e destinazione) ottimizzando la configurazione e il parallelismo delle prestazioni dei cluster di origine e destinazione o sperimentando la quantità di attività DMS e la loro distribuzione tra le istanze CDC.
E potresti voler sapere quali modifiche alla tabella di origine sono supportate da CDC (come l'aggiunta di una colonna, ad esempio) perché non tutte le possibili modifiche sono supportate. In alcuni casi, l'unico modo è modificare manualmente la tabella di destinazione e riavviare l'attività CDC da zero (perdendo lungo il percorso tutti i dati esistenti nel database di destinazione).
Quando le cose vanno male, non importa cosa

L'ho imparato a mie spese, ma c'è uno scenario specifico connesso a DMS in cui la promessa della replica giornaliera è difficile da raggiungere.
Il DMS può elaborare i redo log solo con una certa velocità definita. Non importa se ci sono più istanze di DMS che eseguono le tue attività. Tuttavia, ogni istanza DMS legge i redo log solo con un'unica velocità definita e ognuna di esse deve leggerli per intero. Non importa nemmeno se utilizzi i log di ripristino Oracle o il minatore di log AWS. Entrambi hanno questo limite.
Se il database di origine include un numero elevato di modifiche in un giorno in cui i registri di ripristino di Oracle diventano davvero pazzeschi (come 500 GB + grandi) ogni singolo giorno, CDC non funzionerà. La replica non sarà completata prima della fine della giornata. Porterà del lavoro non elaborato al giorno successivo, dove è già in attesa una nuova serie di modifiche da replicare. La quantità di dati non elaborati crescerà solo di giorno in giorno.
In questo caso particolare, CDC non era un'opzione (dopo molti test delle prestazioni e tentativi che abbiamo eseguito). L'unico modo per garantire che almeno tutte le modifiche delta del giorno corrente vengano replicate nello stesso giorno era affrontarlo in questo modo:
- Separa tabelle molto grandi che non vengono utilizzate così spesso e replicale solo una volta alla settimana (ad esempio, durante i fine settimana).
- Configurare la replica di tabelle non così grandi ma ancora grandi da suddividere tra diverse attività DMS; una tabella è stata infine migrata da 10 o più attività DMS separate in parallelo, assicurando che la suddivisione dei dati tra le attività DMS sia distinta (codifica personalizzata coinvolta qui) e che vengano eseguite quotidianamente.
- Aggiungi più (fino a 4 in questo caso) istanze di DMS e suddividi le attività DMS tra loro equamente, il che significa non solo per il numero di tabelle ma anche per le dimensioni.
Fondamentalmente, abbiamo utilizzato la modalità di caricamento completo di DMS per replicare i dati giornalieri perché era l'unico modo per ottenere almeno il completamento della replica dei dati nello stesso giorno.
Non è una soluzione perfetta, ma è ancora lì e, anche dopo molti anni, funziona ancora allo stesso modo. Quindi, forse non è poi così male una soluzione dopo tutto.