
Supporta Vector Machine (SVM) nell'apprendimento automatico
Pubblicato: 2023-01-04Support Vector Machine è tra gli algoritmi di Machine Learning più popolari. È efficiente e può essere addestrato in set di dati limitati. Ma cos'è?
Cos'è una Support Vector Machine (SVM)?
Support vector machine è un algoritmo di apprendimento automatico che utilizza l'apprendimento supervisionato per creare un modello per la classificazione binaria. Questo è un boccone. Questo articolo spiegherà SVM e come si collega all'elaborazione del linguaggio naturale. Ma prima, analizziamo come funziona una macchina vettoriale di supporto.
Come funziona SVM?
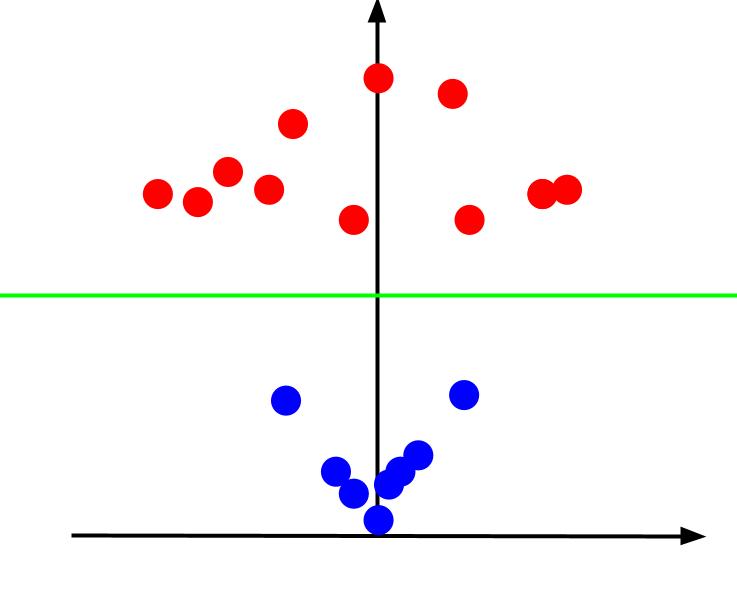
Considera un semplice problema di classificazione in cui disponiamo di dati con due caratteristiche, x e y, e un output: una classificazione rossa o blu. Possiamo tracciare un set di dati immaginario simile a questo:
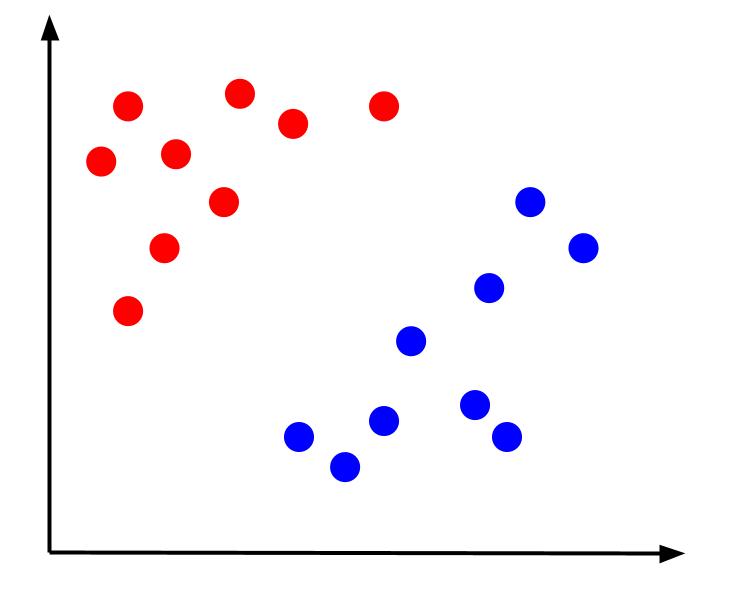
Dati dati come questi, il compito sarebbe quello di creare un confine decisionale. Un confine decisionale è una linea che separa le due classi dei nostri punti dati. Questo è lo stesso set di dati ma con un limite di decisione:
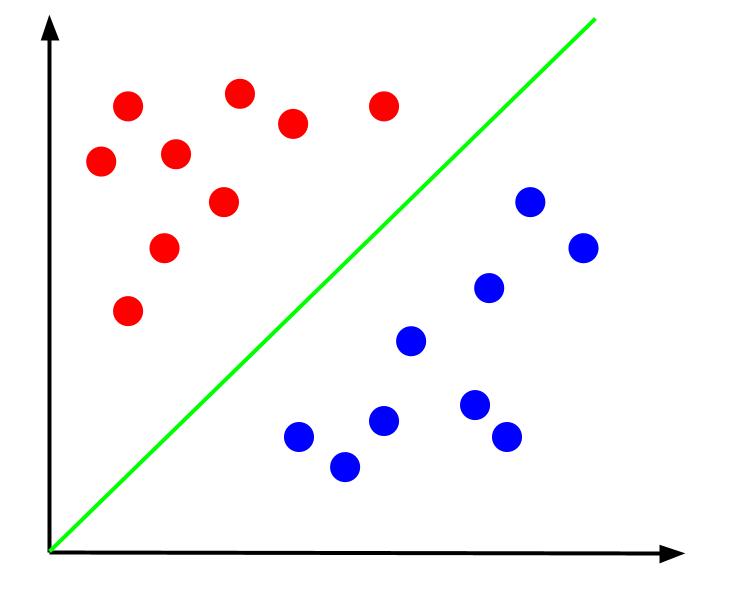
Con questo limite decisionale, possiamo quindi fare previsioni per la classe a cui appartiene un punto dati, dato dove si trova rispetto al limite decisionale. L'algoritmo Support Vector Machine crea il miglior limite decisionale che verrà utilizzato per classificare i punti.
Ma cosa intendiamo per miglior confine decisionale?
Si può sostenere che il miglior confine decisionale sia quello che massimizza la sua distanza da uno dei vettori di supporto. I vettori di supporto sono punti dati di entrambe le classi più vicini alla classe opposta. Questi punti dati rappresentano il rischio maggiore di classificazione errata a causa della loro vicinanza all'altra classe.
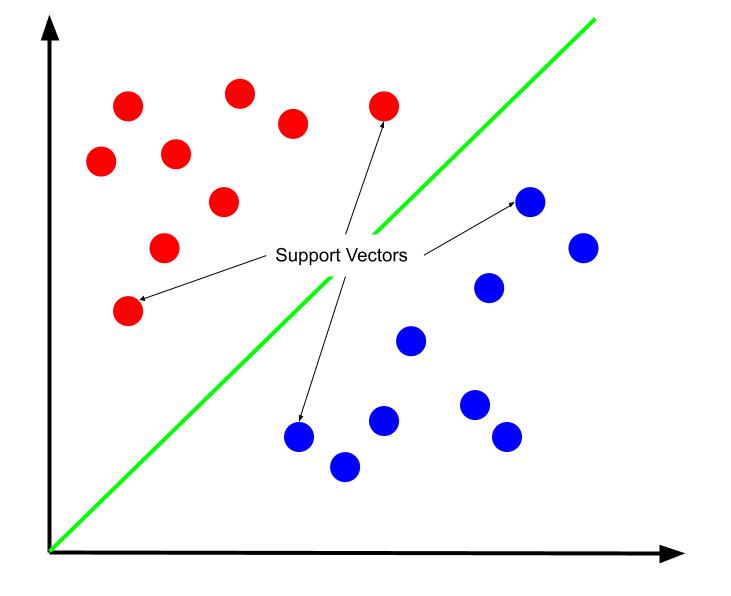
L'addestramento di una macchina a vettori di supporto, quindi, comporta il tentativo di trovare una linea che massimizzi il margine tra i vettori di supporto.
È anche importante notare che poiché il confine decisionale è posizionato rispetto ai vettori di supporto, questi sono gli unici determinanti della posizione del confine decisionale. Gli altri punti dati sono, quindi, ridondanti. E quindi, la formazione richiede solo i vettori di supporto.
In questo esempio, il confine decisionale formato è una linea retta. Questo è solo perché il set di dati ha solo due funzionalità. Quando il set di dati ha tre caratteristiche, il limite decisionale formato è un piano anziché una linea. E quando ha quattro o più caratteristiche, il confine decisionale è noto come iperpiano.
Dati non linearmente separabili
L'esempio sopra considerato dati molto semplici che, una volta tracciati, possono essere separati da un limite di decisione lineare. Si consideri un caso diverso in cui i dati vengono tracciati come segue:
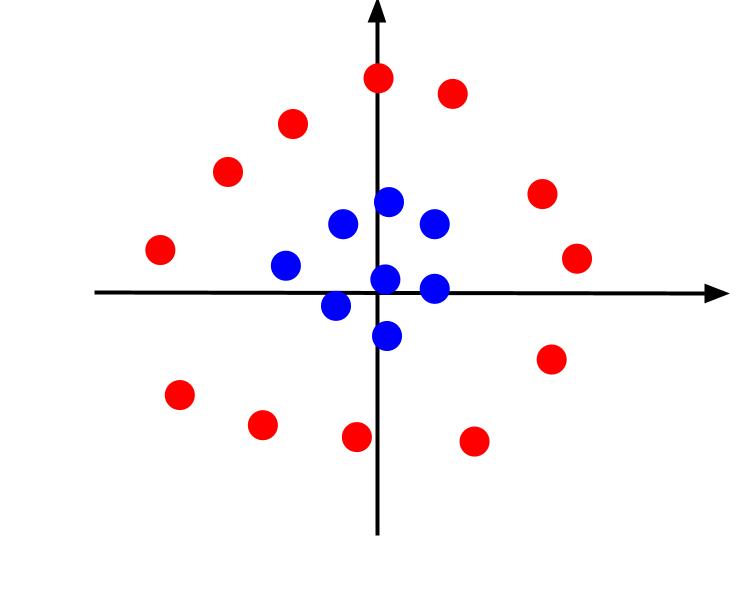
In questo caso, è impossibile separare i dati utilizzando una linea. Ma potremmo creare un'altra caratteristica, z. E questa caratteristica può essere definita dall'equazione: z = x^2 + y^2. Possiamo aggiungere z come terzo asse al piano per renderlo tridimensionale.
Quando guardiamo il grafico 3D da un angolo tale che l'asse x è orizzontale mentre l'asse z è verticale, questa è la vista che otteniamo qualcosa che assomiglia a questo:
Il valore z rappresenta la distanza di un punto dall'origine rispetto agli altri punti nel vecchio piano XY. Di conseguenza, i punti blu più vicini all'origine hanno valori z bassi.
Mentre i punti rossi più lontani dall'origine avevano valori z più alti, tracciarli rispetto ai loro valori z ci dà una chiara classificazione che può essere delimitata da un confine decisionale lineare, come illustrato.
Questa è un'idea potente che viene utilizzata in Support Vector Machines. Più in generale, è l'idea di mappare le dimensioni in un numero maggiore di dimensioni in modo che i punti dati possano essere separati da un confine lineare. Le funzioni responsabili di ciò sono funzioni del kernel. Esistono molte funzioni del kernel, come sigmoid, lineare, non lineare e RBF.
Per rendere più efficiente la mappatura di queste funzionalità, SVM utilizza un trucco del kernel.
SVM nell'apprendimento automatico
Support Vector Machine è uno dei tanti algoritmi utilizzati nell'apprendimento automatico insieme a quelli popolari come Decision Trees e Neural Networks. È favorito perché funziona bene con meno dati rispetto ad altri algoritmi. È comunemente usato per fare quanto segue:
- Classificazione del testo : classificazione di dati di testo come commenti e recensioni in una o più categorie
- Face Detection : analisi delle immagini per rilevare i volti per fare cose come aggiungere filtri per la realtà aumentata
- Classificazione delle immagini : le macchine vettoriali di supporto possono classificare le immagini in modo efficiente rispetto ad altri approcci.
Il problema della classificazione del testo
Internet è pieno di un sacco di dati testuali. Tuttavia, molti di questi dati non sono strutturati e non sono etichettati. Per utilizzare meglio questi dati di testo e comprenderli meglio, è necessaria una classificazione. Esempi di volte in cui il testo è classificato includono:
- Quando i tweet sono classificati in argomenti in modo che le persone possano seguire gli argomenti che desiderano
- Quando un'e-mail è classificata come Social, Promozioni o Spam
- Quando i commenti sono classificati come odiosi o osceni nei forum pubblici
Come funziona SVM con la classificazione del linguaggio naturale
Support Vector Machine viene utilizzato per classificare il testo in testo che appartiene a un particolare argomento e testo che non appartiene all'argomento. Ciò si ottiene prima convertendo e rappresentando i dati di testo in un set di dati con diverse funzionalità.
Un modo per farlo è creare caratteristiche per ogni parola nel set di dati. Quindi, per ogni punto dati di testo, registri il numero di volte in cui ogni parola ricorre. Supponiamo quindi che nel set di dati siano presenti parole univoche; avrai funzionalità nel set di dati.
Inoltre, fornirai classificazioni per questi punti dati. Mentre queste classificazioni sono etichettate dal testo, la maggior parte delle implementazioni SVM prevede etichette numeriche.
Pertanto, dovrai convertire queste etichette in numeri prima dell'allenamento. Una volta preparato il set di dati, utilizzando queste caratteristiche come coordinate, è possibile utilizzare un modello SVM per classificare il testo.
Creazione di un SVM in Python
Per creare una macchina vettoriale di supporto (SVM) in Python, puoi utilizzare la classe SVC dalla libreria sklearn.svm . Ecco un esempio di come utilizzare la classe SVC per creare un modello SVM in Python:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) In questo esempio, per prima cosa importiamo la classe SVC dalla libreria sklearn.svm . Quindi, carichiamo il set di dati e lo suddividiamo in set di addestramento e test.
Successivamente, creiamo un modello SVM istanziando un oggetto SVC e specificando il parametro del kernel come 'linear'. Quindi addestriamo il modello sui dati di addestramento utilizzando il metodo di fit e valutiamo il modello sui dati di test utilizzando il metodo del score . Il metodo del score restituisce l'accuratezza del modello, che viene stampata sulla console.
Puoi anche specificare altri parametri per l'oggetto SVC , come il parametro C che controlla la forza della regolarizzazione e il parametro gamma , che controlla il coefficiente del kernel per alcuni kernel.
Vantaggi di SVM
Ecco un elenco di alcuni vantaggi dell'utilizzo di macchine a vettori di supporto (SVM):
- Efficiente : gli SVM sono generalmente efficienti da addestrare, specialmente quando il numero di campioni è elevato.
- Robusto al rumore : gli SVM sono relativamente robusti al rumore nei dati di addestramento poiché cercano di trovare il classificatore del margine massimo, che è meno sensibile al rumore rispetto ad altri classificatori.
- Efficienza della memoria: le SVM richiedono che solo un sottoinsieme dei dati di addestramento sia in memoria in un dato momento, rendendole più efficienti in termini di memoria rispetto ad altri algoritmi.
- Efficace in spazi ad alta dimensione: le SVM possono comunque funzionare bene anche quando il numero di funzionalità supera il numero di campioni.
- Versatilità : gli SVM possono essere utilizzati per attività di classificazione e regressione e possono gestire vari tipi di dati, inclusi dati lineari e non lineari.
Ora, esploriamo alcune delle migliori risorse per apprendere Support Vector Machine (SVM).

Risorse di apprendimento
Un'introduzione alle macchine vettoriali di supporto
Questo libro sull'introduzione alle macchine vettoriali di supporto ti introduce in modo completo e graduale ai metodi di apprendimento basati sul kernel.
| Anteprima | Prodotto | Valutazione | Prezzo | |
|---|---|---|---|---|
 | Un'introduzione alle macchine vettoriali di supporto e altri metodi di apprendimento basati sul kernel | $ 75,00 | Acquista su Amazon |
Ti dà una solida base sulla teoria delle Support Vector Machines.
Supporta le applicazioni di macchine vettoriali
Mentre il primo libro si concentrava sulla teoria delle macchine a vettori di supporto, questo libro sulle applicazioni delle macchine a vettori di supporto si concentra sulle loro applicazioni pratiche.
| Anteprima | Prodotto | Valutazione | Prezzo | |
|---|---|---|---|---|
 | Supporta le applicazioni di macchine vettoriali | $ 15,52 | Acquista su Amazon |
Esamina come gli SVM vengono utilizzati nell'elaborazione delle immagini, nel rilevamento dei modelli e nella visione artificiale.
Supporto macchine vettoriali (scienza dell'informazione e statistica)
Lo scopo di questo libro sulle Support Vector Machines (Information Science and Statistics) è fornire una panoramica dei principi alla base dell'efficacia delle Support Vector Machines (SVM) in varie applicazioni.
| Anteprima | Prodotto | Valutazione | Prezzo | |
|---|---|---|---|---|
 | Supporto macchine vettoriali (scienza dell'informazione e statistica) | $ 167,36 | Acquista su Amazon |
Gli autori evidenziano diversi fattori che contribuiscono al successo degli SVM, inclusa la loro capacità di funzionare bene con un numero limitato di parametri regolabili, la loro resistenza a vari tipi di errori e anomalie e le loro prestazioni computazionali efficienti rispetto ad altri metodi.
Imparare con i kernel
"Imparare con i kernel" è un libro che introduce i lettori al supporto delle macchine vettoriali (SVM) e alle relative tecniche del kernel.
| Anteprima | Prodotto | Valutazione | Prezzo | |
|---|---|---|---|---|
 | Apprendimento con i kernel: supporta macchine vettoriali, regolarizzazione, ottimizzazione e oltre (adattivo... | $ 80,00 | Acquista su Amazon |
È progettato per fornire ai lettori una comprensione di base della matematica e le conoscenze di cui hanno bisogno per iniziare a utilizzare gli algoritmi del kernel nell'apprendimento automatico. Il libro mira a fornire un'introduzione completa ma accessibile agli SVM e ai metodi del kernel.
Supporta le macchine vettoriali con Sci-kit Learn
Questo corso online Support Vector Machines with Sci-kit Learn della rete del progetto Coursera insegna come implementare un modello SVM utilizzando la popolare libreria di machine learning, Sci-Kit Learn.

Inoltre, imparerai la teoria alla base degli SVM e ne determinerai i punti di forza e i limiti. Il corso è di livello principiante e richiede circa 2,5 ore.
Supportare le macchine vettoriali in Python: concetti e codice
Questo corso online a pagamento su Support Vector Machines in Python di Udemy ha fino a 6 ore di istruzioni basate su video e viene fornito con una certificazione.

Copre gli SVM e come possono essere solidamente implementati in Python. Inoltre, copre le applicazioni aziendali di Support Vector Machines.
Apprendimento automatico e intelligenza artificiale: supporta le macchine vettoriali in Python
In questo corso sull'apprendimento automatico e l'intelligenza artificiale, imparerai come utilizzare le macchine vettoriali di supporto (SVM) per varie applicazioni pratiche, tra cui il riconoscimento delle immagini, il rilevamento dello spam, la diagnosi medica e l'analisi della regressione.

Utilizzerai il linguaggio di programmazione Python per implementare modelli ML per queste applicazioni.
Parole finali
In questo articolo, abbiamo appreso brevemente la teoria alla base delle Support Vector Machines. Abbiamo appreso della loro applicazione nell'apprendimento automatico e nell'elaborazione del linguaggio naturale.
Abbiamo anche visto come appare la sua implementazione usando scikit-learn . Inoltre, abbiamo parlato delle applicazioni pratiche e dei vantaggi delle Support Vector Machines.
Mentre questo articolo era solo un'introduzione, le risorse aggiuntive consigliavano di entrare più nel dettaglio, spiegando di più su Support Vector Machines. Data la loro versatilità ed efficienza, vale la pena comprendere le SVM per crescere come data scientist e ingegnere ML.
Successivamente, puoi dare un'occhiata ai migliori modelli di machine learning.