
Il modo giusto per non indicizzare una pagina
Pubblicato: 2022-12-02Può sembrare controintuitivo, ma non tutte le pagine del tuo sito web dovrebbero apparire nei risultati di ricerca. L'ottimizzazione per i motori di ricerca (SEO) si sforza di aumentare la visibilità della ricerca e il traffico organico e, a volte, puoi raggiungere al meglio tale obiettivo limitando i contenuti che possono essere visualizzati nei risultati di ricerca.
Se ti stai grattando la testa o stai vedendo il mio bluff, continua a leggere per scoprire il valore di noindexing di una pagina o di una sottodirectory e come implementare i tag noindex.
Cosa significa Noindex?
Il termine "noindex" è una direttiva speciale in un meta tag robots che indica ai crawler di ricerca di escludere la pagina dalle pagine dei risultati dei motori di ricerca (SERP). Ciò significa che gli utenti non saranno in grado di accedere alla pagina tramite la ricerca.
Una parte preziosa di qualsiasi strategia SEO tecnica, i meta tag robots ti consentono di escludere le pagine che non forniscono valore agli utenti che effettuano ricerche o che contengono informazioni che non desideri vengano visualizzate nei risultati di ricerca, come:
- Pagine di conferma e di ringraziamento
- Pagine di accesso
- Informativa sulla privacy o pagina dei termini di servizio
- Contenuto recintato
- Messaggio di errore
Robots Meta Tag vs. Robots.txt vs. X-Robots Tag
Il meta tag Robots viene spesso confuso con il file robots.txt e il tag x-robots. Tutti e tre danno istruzioni ai crawler di ricerca sulle pagine e fanno parte del protocollo di esclusione dei robot (REP). Più semplicemente: dicono a Google cosa inserire nella Ricerca Google e cosa tenerne fuori, nonché quali pagine devono scansionare. Tuttavia, non possono e non devono essere usati in modo intercambiabile.
Meta-tag dei robot
Un meta tag robots viene aggiunto alla sezione <head> di una particolare pagina Web e trasmette solo istruzioni su quella pagina specifica. Spesso chiamato tag noindex o meta tag noindex, il meta tag robots può fare molto di più che dire a un crawler di ricerca di non indicizzare una pagina.
Può anche essere utilizzato per chiedere ai crawler di non seguire i collegamenti, tradurre una pagina, bloccare uno specifico bot di ricerca o impedire che un collegamento memorizzato nella cache appaia nelle SERP.
Le direttive comuni sui meta tag dei robot includono:
- Noindex, nofollow — <meta name=”robots” content=”noindex, nofollow”>
Googlebot e altri web crawler possono accedere alla pagina, ma non devono indicizzarla o seguirne i collegamenti. - Noindex, segui — <meta name=”robots” content=”noindex”>
Googlebot e altri web crawler possono accedere alla pagina e seguire i link in essa contenuti, ma non devono indicizzare la pagina stessa. Non è necessario includere "follow" nel meta tag poiché è l'impostazione predefinita.
Robots.txt
Robots.txt è un file che consente ai proprietari di siti di indicare ai motori di ricerca quali parti del loro sito non vogliono sottoporre a scansione. È come un cartello personale Non disturbare per il tuo sito web che si trova nella directory principale del tuo dominio o sottodominio.
Un file robots.txt è l'ideale per bloccare l'accesso e la scansione di intere sottodirectory piuttosto che singole pagine. Usalo per impedire ai crawler di ricerca di accedere e indicizzare:
- Pagine di ricerca interne
- Parametri dell'URL
- Forum in cui lo spam generato dagli utenti può causare problemi
- Sottodirectory interne, come quelle riservate ai soli dipendenti
Segui questi passaggi per creare un file robots.txt e assicurati di collegarti alla tua mappa del sito XML.
Se ti colleghi a una pagina inclusa nel tuo file robots.txt, potresti voler aggiungere anche un meta tag robots per assicurarti che non venga visualizzato nei risultati di ricerca. Ricorda: robots.txt impedisce solo ai crawler di accedere a una pagina, non di indicizzarla. Se le pagine coperte dalle tue direttive robots.txt ricevono link esterni, i motori di ricerca potrebbero indicizzarle. Utilizza un meta tag robots insieme al file robots.txt per evitarlo.
Etichetta X-Robot
Per impedire che un PDF, un video o un'immagine appaia nelle SERP, utilizza un tag x-robots. Le stesse direttive specificate per i meta tag robots vengono utilizzate per x-robots. Tuttavia, a differenza del meta tag robots, che risiede nell'intestazione HTML di una pagina, un tag x-robots viene inserito nella risposta dell'intestazione HTTP.
La direttiva si presenta così:
X-Robots-Tag: noindexQuando non indicizzare una pagina
Indice di marciapiede gonfio
Il gonfiamento dell'indice si verifica quando Google indicizza le pagine con un valore minimo o nullo per gli utenti che effettuano ricerche. Queste pagine estranee sottraggono risorse a pagine più preziose. Utilizza un meta tag robots per gestire quali pagine vengono visualizzate nei risultati di ricerca.
Sradicare la cannibalizzazione delle parole chiave
La cannibalizzazione delle parole chiave si verifica quando due pagine condividono una parola chiave e un intento di ricerca simili, facendole quindi competere l'una contro l'altra nelle SERP.
Se hai due pagine che si cannibalizzano a vicenda e vuoi mantenerle entrambe senza modificarne il contenuto, noindex one. Detto questo, dovresti farlo solo se la pagina che stai noindexing non indirizza il traffico da parole chiave che l'altra pagina non ha. In una situazione come questa, potrebbe essere necessario rielaborare il contenuto di una o entrambe le pagine per risolvere il problema della cannibalizzazione.
Proteggi le pagine di destinazione recintate
Quando offri una risorsa di alto valore ai clienti in cambio di informazioni di contatto, assicurati che non sia accessibile in altro modo. Aggiungi un meta tag robots a noindex della pagina e impedisci che appaia nelle SERP.
Escludi i prodotti impopolari dalla ricerca
I siti di e-commerce spesso portano prodotti per servire determinati clienti anche se non c'è troppa richiesta per loro. Ad esempio, un rivenditore di ricambi auto o un'altra azienda tecnica potrebbe avere prodotti per modelli particolari o attrezzature rare. Se queste pagine di prodotti o categorie non generano traffico organico, generalmente non possono essere indicizzate.
Come non indicizzare una pagina web
Il meta tag noindex va nell'intestazione dell'HTML di una pagina. Il codice non fa distinzione tra maiuscole e minuscole e si presenta così:
<meta name="robots" content="noindex">"Robot" significa che la direttiva si applica a qualsiasi crawler, ma puoi individuare i crawler sostituendo "robot" con nomi di crawler noti, come "Googlebot" o "bingbot".

I crawler continueranno a seguire i link sulla pagina a meno che tu non aggiunga anche un comando nofollow. Puoi farlo per impedire che l'equità del collegamento scorra attraverso la pagina o per impedire a un crawler di seguire un collegamento al contenuto protetto.
Per aggiungere un valore nofollow, separalo dalla direttiva noindex con una virgola.
<meta name="robots" content="noindex, nofollow">Nota: prima di non indicizzare una pagina, controlla se ha traffico organico in entrata in Google Search Console. In tal caso, determina in che modo il tuo sito può continuare a catturare questo traffico prima di non indicizzare la pagina.
Come aggiungere un meta tag Robots al tuo codice HTML
- Apri il codice sorgente della pagina che vuoi noindex.
- Trova l'intestazione nella parte superiore della pagina. Inizia con <head> e finisce con </head>. Probabilmente ci sarà anche altro codice nell'intestazione.
- Aggiungi il meta tag robots su una nuova riga, assicurandoti che appaia tra i tag <head> e </head>.
Questo è tutto! Se la tua pagina è già indicizzata, puoi chiedere a Google di scansionarla di nuovo incollando il suo URL nello strumento di controllo URL.
Già indicizzato? Utilizza lo strumento di rimozione URL
Quando aggiungi un tag noindex a una nuova pagina di contenuti, Googlebot vedrà la direttiva durante la scansione della pagina e non la indicizzerà.
Tuttavia, se aggiungi il tag a una pagina che è già stata indicizzata , la pagina continuerà a essere visualizzata nei risultati di ricerca fino a quando non verrà ripetuta la scansione e i bot visualizzeranno le nuove istruzioni noindex. Puoi chiedere a Google di ripetere la scansione dell'URL in Google Search Console tramite lo strumento di ispezione degli URL, ma non rimuoverà immediatamente la pagina dalle SERP.
Se devi rimuovere immediatamente una pagina dalla SERP, utilizza lo strumento di rimozione in Google Search Console. Ciò manterrà le pagine fuori dai risultati di ricerca di Google per circa sei mesi. A quel punto, il meta tag noindex dovrebbe funzionare.
Come non indicizzare una pagina su WordPress
Ogni pagina in WordPress è indicizzata per impostazione predefinita. Puoi utilizzare il plug-in Yoast SEO per non indicizzare una pagina in WordPress senza scrivere codice. Ecco come.
Fai clic sulla scheda "Avanzate" nel meta box di Yoast SEO.
Sotto la domanda "Consentire ai motori di ricerca di mostrare questo post nei risultati di ricerca?" selezionare 'No' dalla casella a discesa.
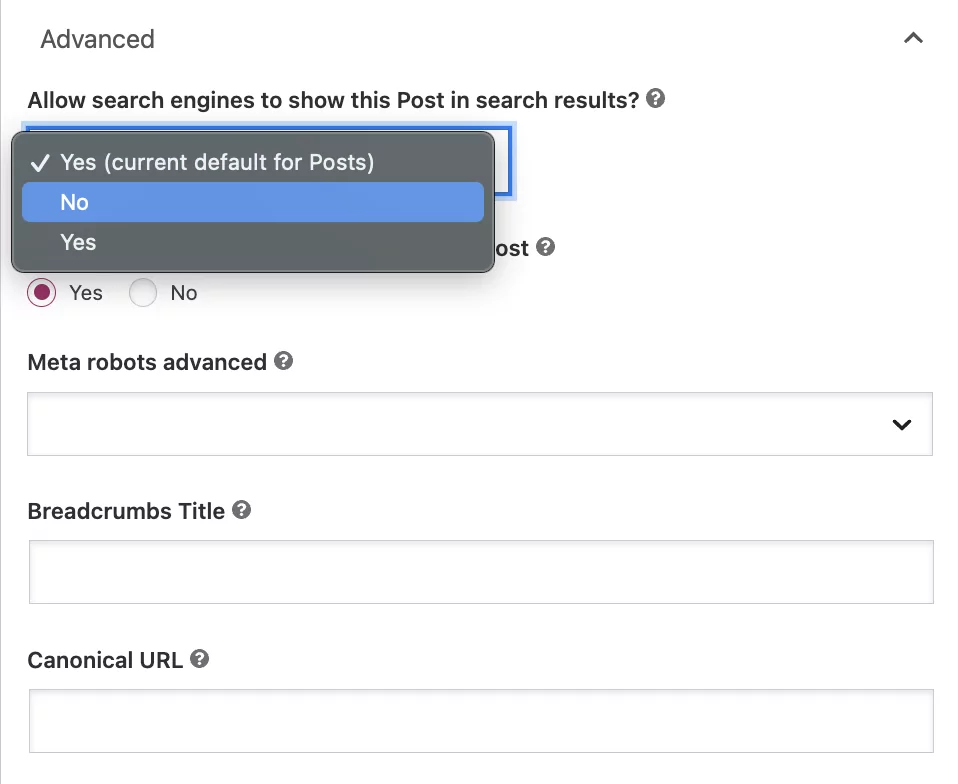
Sebbene questa impostazione indichi a Google di non indicizzare il post, i bot continueranno a seguire automaticamente i link sulla pagina per eseguire la scansione di altre pagine.
Se desideri aggiungere una direttiva nofollow, seleziona il pulsante "No" sotto la domanda: "I motori di ricerca dovrebbero seguire i link in questo post?"
Domande frequenti sui meta tag dei robot
Tutti i motori di ricerca obbediscono a una direttiva noindex?
Puoi aspettarti che Google, Bing e altri motori di ricerca legittimi rispettino un meta tag robots.
Posso collegarmi a pagine non indicizzate?
Sì. Il tag noindex indica ai robot di ricerca come trattare una pagina durante la scansione e l'indicizzazione. Non influisce sulla tua capacità di collegarti a una pagina. Questo può essere utile per le pagine di categoria su un blog, che non dovrebbero apparire nei risultati di ricerca ma possono fornire ai bot collegamenti a pagine preziose che dovrebbero.
Quando dovrei utilizzare un meta tag robots?
Se hai una pagina che non offre alcun valore agli utenti, come una pagina di ringraziamento o una pagina adatta alla stampa, non indicizzarla con un meta tag robots per evitare che appaia nelle SERP.
Quando non dovrei usare una direttiva noindex?
È possibile risolvere tecnicamente i problemi di contenuto duplicato e alcuni problemi di crawl budget con le direttive noindex, ma questo non è il modo migliore per farlo. Il contenuto duplicato viene gestito al meglio utilizzando tag canonici, che concentrano l'equità del collegamento dai duplicati sulla pagina canonica. Se stai cercando di risparmiare il crawl budget, dovresti utilizzare il file robots.txt per impedire la scansione di quella sezione del sito.
Le pagine noindex passano link equity?
Sì. Anche se una pagina non è indicizzata, può comunque condividere qualsiasi autorità di ranking accumulata. Tuttavia, i crawler di ricerca devono avere la possibilità di seguire i collegamenti sulla pagina affinché l'equità dei collegamenti possa fluire. Se una pagina è impostata su noindex e nofollow, non può trasmettere link equity.
Il noindexing di una pagina la rimuove automaticamente dalle SERP di Google?
Se la tua pagina è già indicizzata, l'aggiunta di un meta tag robots non la eliminerà automaticamente dai risultati di ricerca. Ci vuole un po' di tempo prima che le pagine già indicizzate scompaiano dalle SERP. I robot di ricerca devono ripetere la scansione delle pagine per vedere il tag noindex. Per risultati più rapidi, richiedi a Google di ripetere la scansione della pagina e di utilizzare lo strumento di rimozione degli URL.
Scopri le pagine problematiche con un audit SEO
Non lasciare che contenuti sottili o duplicati influiscano sulla tua visibilità nella ricerca. Assicurati di dare alle tue pagine le migliori possibilità di posizionarsi. Il nostro audit SEO di oltre 200 punti segnala problemi come contenuti duplicati, un file robots.txt mancante, meta tag robots applicati in modo errato, indice gonfio e altro ancora. Iscriviti per una consulenza SEO gratuita per vedere come il nostro servizio di audit SEO può massimizzare la tua visibilità online e aiutare la tua attività a crescere.