
Come ottimizzare il tuo sito web per i crawler dei motori di ricerca?
Pubblicato: 2023-04-27I web crawler passano costantemente attraverso i siti Web per determinare di cosa tratta ogni pagina. I dati possono essere indicizzati e modificati e trovati quando l'utente invia la richiesta. Alcuni siti Web utilizzano robot di scansione Web per aggiornare il contenuto del proprio sito Web.
I motori di ricerca come Google o Bing utilizzano un motore di ricerca insieme alla raccolta di informazioni da parte dei web crawler per visualizzare siti Web pertinenti e informazioni pertinenti come risultato delle ricerche degli utenti.
Se un web design un'azienda o il proprietario del sito desidera visualizzare il proprio sito Web nei risultati di ricerca, deve essere scansionato e indicizzato. Se i siti non vengono scansionati o indicizzati, i motori di ricerca non saranno in grado di individuarli in modo organico.
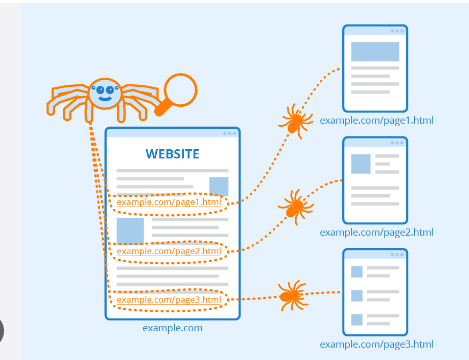
I web crawler iniziano eseguendo la scansione di determinate pagine e quindi seguendo i collegamenti ipertestuali sulle pagine a quelle nuove.
I siti Web che non desiderano essere scansionati o scoperti dai motori di ricerca possono utilizzare strumenti come quelli trovati nel file robots.txt per istruire i robot a non indicizzare un sito Web o solo a indicizzarne una piccola parte.
L'esecuzione di ispezioni del sito con strumenti di scansione può aiutare i proprietari di siti Web a identificare collegamenti ipertestuali interrotti o contenuti duplicati. Titoli assenti o troppo lunghi o corti di un titolo.
Sommario
Ruolo dei motori di ricerca nel Web Crawling:
1. Crunching: cercare informazioni su Internet e quindi il codice sorgente/contenuto per ogni URL che incontrano.
2. Indicizzazione: gestire e archiviare le informazioni raccolte durante il processo di scansione. Dopo che una pagina è stata inclusa nell'indice, mostrarla come risultato di ricerche pertinenti può essere un processo continuo.
3. Classifica: presenta le porzioni di informazioni che più probabilmente soddisfano i requisiti dell'utente.
Cos'è esattamente la scansione su Google?
Il crawling è il metodo di ricerca che i motori di ricerca impiegano per distribuire una serie di robot (spider e crawler) per trovare contenuti freschi e aggiornati.
Il contenuto potrebbe essere in diversi formati, come immagini, pagine Web o video, PDF, ecc. Qualunque sia il tipo di formato, il contenuto viene trovato tramite collegamenti ipertestuali.
Googlebot inizia cercando in determinati siti web; successivamente, esegue la scansione dei collegamenti ipertestuali delle pagine per trovare nuovi URL.
Mentre attraversa i collegamenti ipertestuali, il crawler può scoprire nuovi contenuti che può includere nel suo indice chiamato Caffeine.
È un enorme database di URL scoperti di recente che possono essere recuperati quando qualcuno sta cercando informazioni su un sito il cui contenuto URL corrisponde perfettamente.
Posizionamento sui motori di ricerca:
Quando qualcuno esegue una ricerca su Google, i motori di ricerca scansionano i propri indici per trovare contenuti pertinenti e quindi organizzano il contenuto per risolvere la domanda.
L'ordine in cui i risultati della ricerca sono disposti in base alla pertinenza è noto come ranking.
Puoi impedire ai crawler dei motori di ricerca di eseguire la scansione di una parte specifica o addirittura di tutto il tuo sito o istruire i motori di ricerca a non includere determinati siti Web nel loro indice.
Se vuoi vedere il tuo sito web indicizzato attraverso i risultati dei motori di ricerca, devi assicurarti che sia accessibile ai crawler e indicizzabile.
Motori di ricerca a scansione:
Come hai visto, assicurarti che il tuo sito venga scansionato, indicizzato e sottoposto a scansione è fondamentale affinché appaia nei risultati di ricerca. Se la tua azienda è site è nell'indice del sito che stai guardando, è una buona idea iniziare guardando il numero di pagine all'interno dei risultati di ricerca.

Questo può darti un'idea eccellente di come Google ha scansionato il tuo sito web per trovare ogni pagina a cui desideri collegarti ma non scoprire pagine che non sei.
Risultati: il numero di risultati visualizzati da Google non è esatto. Tuttavia, ti fornisce una comprensione delle pagine trovate sul tuo sito e del modo in cui vengono mostrate nelle pagine dei risultati di ricerca.
Lo strumento consente alle tendenze del web design di caricare mappe del sito sul tuo sito e tenere traccia del numero di pagine inviate da aggiungere all'indice di Google e altri aspetti.
Se il tuo sito non viene visualizzato nella pagina dei risultati, ci sono molti motivi per controllare:
- Il tuo sito è nuovo e deve ancora essere sottoposto a scansione.
- La navigazione del tuo sito rende difficile per i crawler navigare in modo efficiente.
- Il tuo sito web ha un codice elementare chiamato direttive del crawler che blocca le istruzioni del crawler dai motori di ricerca.
- Il tuo sito è stato rimosso dall'elenco da Google perché utilizzava metodi di spam.
Fai sapere ai motori di ricerca come possono accedere al tuo sito :
Se hai provato Google Search Console o il motore di ricerca avanzato "site: domain.com" e hai scoperto che alcune delle tue pagine importanti non sono elencate nell'indice o che alcune pagine meno importanti non sono state indicizzate correttamente , allora ci sono alcuni modi per gestire Googlebot nel modo in cui vorresti eseguire la scansione dei contenuti del tuo sito web.
Molti si concentrano sull'assicurarsi che Google trovi i loro siti Web più importanti, ma è facile trascurare quelle che molto probabilmente sono alcune pagine che si desidera evitare di trovare da parte di Googlebot.
Questi potrebbero essere URL precedenti senza informazioni e numerosi URL (come filtri e parametri di ordinamento per l'e-commerce), codici promozionali, pagine di staging o test e molti altri.
Conclusione:
Google fa un ottimo lavoro nel determinare l'URL corretto per il tuo sito web.
Tuttavia, puoi anche utilizzare questa funzione all'interno della Search Console per dire a Google esattamente come vorresti che gestissero i tuoi siti web.
Se utilizzi questa funzione per dire a Googlebot "scansiona per trovare gli URL che non contengono il parametro ____", sta cercando di convincere Google a mantenere queste informazioni fuori da Googlebot e quindi rimuovere queste pagine dai risultati per la ricerca.
Questo è ciò che stai cercando quando questi parametri portano a pagine duplicate. Ci sono, tuttavia, alternative migliori a questo se desideri che queste pagine siano incluse.
FAQ:
Trovi che il contenuto del tuo sito web scompaia quando utilizzi il modulo di accesso?
I motori di ricerca non saranno in grado di accedere alle pagine protette quando richiedi agli utenti di registrarsi e completare moduli o sondaggi prima di accedere a determinati siti web. Un crawler è tenuto a richiedere assistenza per l'accesso.
Dovresti usare la pagina di ricerca di Google?
I moduli di ricerca non sono accessibili ai robot. Alcune persone credono che se includono opzioni di ricerca sul proprio sito, i motori di ricerca possono trovare ciò che gli utenti stanno cercando.
I motori di ricerca possono seguire la direzione del tuo sito?
Un crawler deve trovare il tuo sito Web tramite collegamenti ipertestuali ad altri siti Web e richiedere un elenco di collegamenti che indirizzano l'utente da una pagina all'altra. Se hai una pagina che vorresti che i motori di ricerca trovassero, ma non è collegata a un'altra pagina, è molto più efficace che passare inosservato.